题目
V2X-ViT: Vehicle-to-Everything Cooperative Perception with Vision Transformer(ECCV2022)
链接:https://arxiv.org/pdf/2203.10638v1.pdf
仓库链接:https://github.com/DerrickXuNu/v2x-vit
简介
V2V:vehicle to vehicle
V2X:vehicle to everything
论文主要针对的是3D目标检测问题(自动驾驶领域)
Heterogeneous agent:所谓异构,就是不光接收车的信息,还要接受infrastracture的信息。不同agent之间就形成了异构性,怎么有效融合就成了问题。
Infrastructure(比如说交叉路口的固定传感器)提供的信息具有a broader sight-of-view and potentially less occlusion. 而且更稳定, 应该被利用起来。
这一篇的亮点:
- 新结构: 针对V2X任务提出了统一的Transformer架构(V2X-ViT),可以在异构系统中、多种噪声条件下保持strong robustness。
- 新模块1: heterogeneous multi-agent attention module (HMSA)解决异构问题。
- 新模块2: multi-scale window attention module (MSWin)同时捕获局部和全局信息交互。
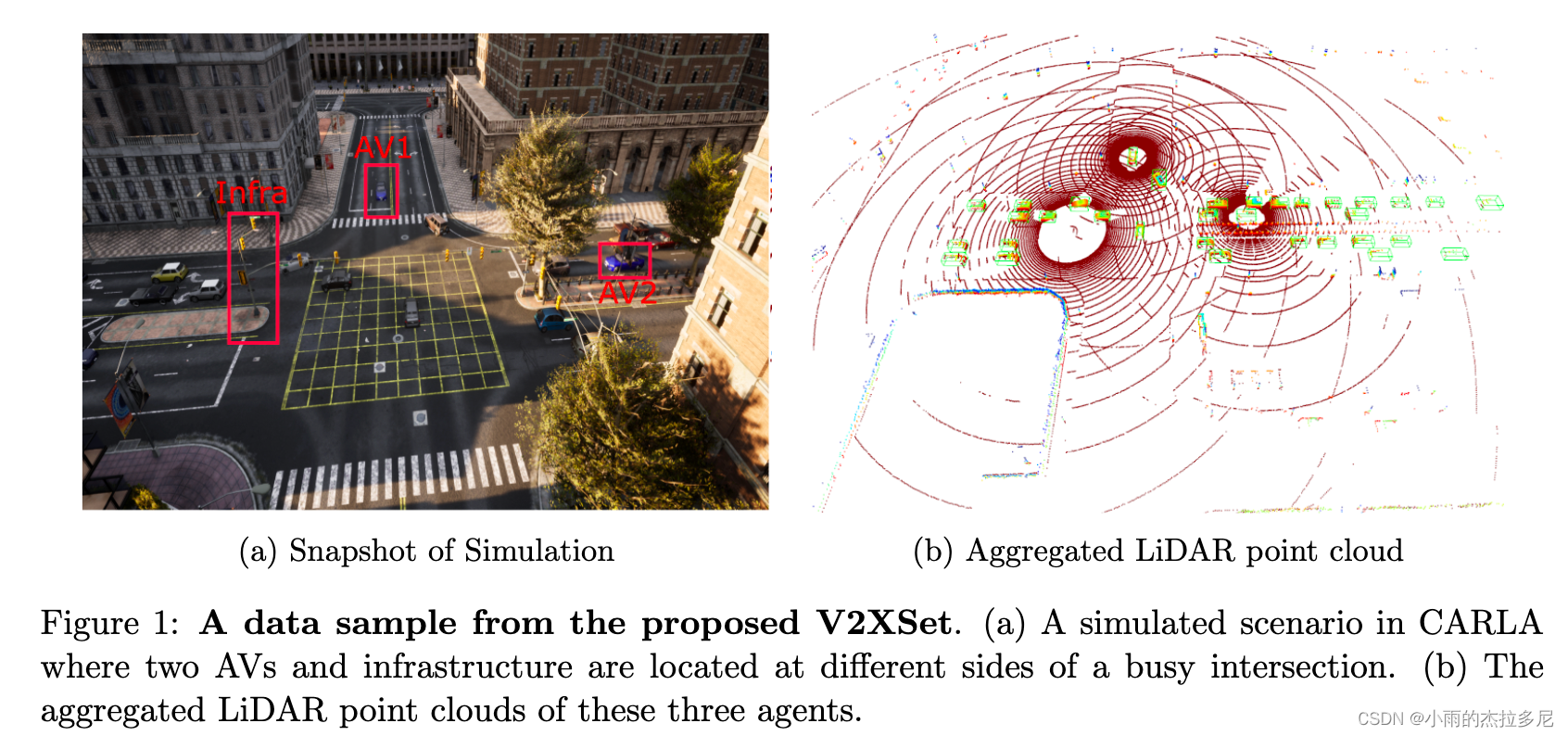
- 新数据集: V2XSet,包含了车端和infra端的数据,更加贴近现实条件。
关于具体的Collaborative感知的必要性,以及比Individual感知强在哪,见上一篇综述文章。
HMSA 和 MSWin 两个模块以迭代的方式自适应融合视觉特征,捕捉个体间的交互和个体间的空间关系,纠正定位错误和时间延迟导致的 feature misalignment。
流程框架
这篇文章在这部分的解释非常清晰,特别是作为一个刚入门的小白,看完后会对整个流程的了解清晰了很多。
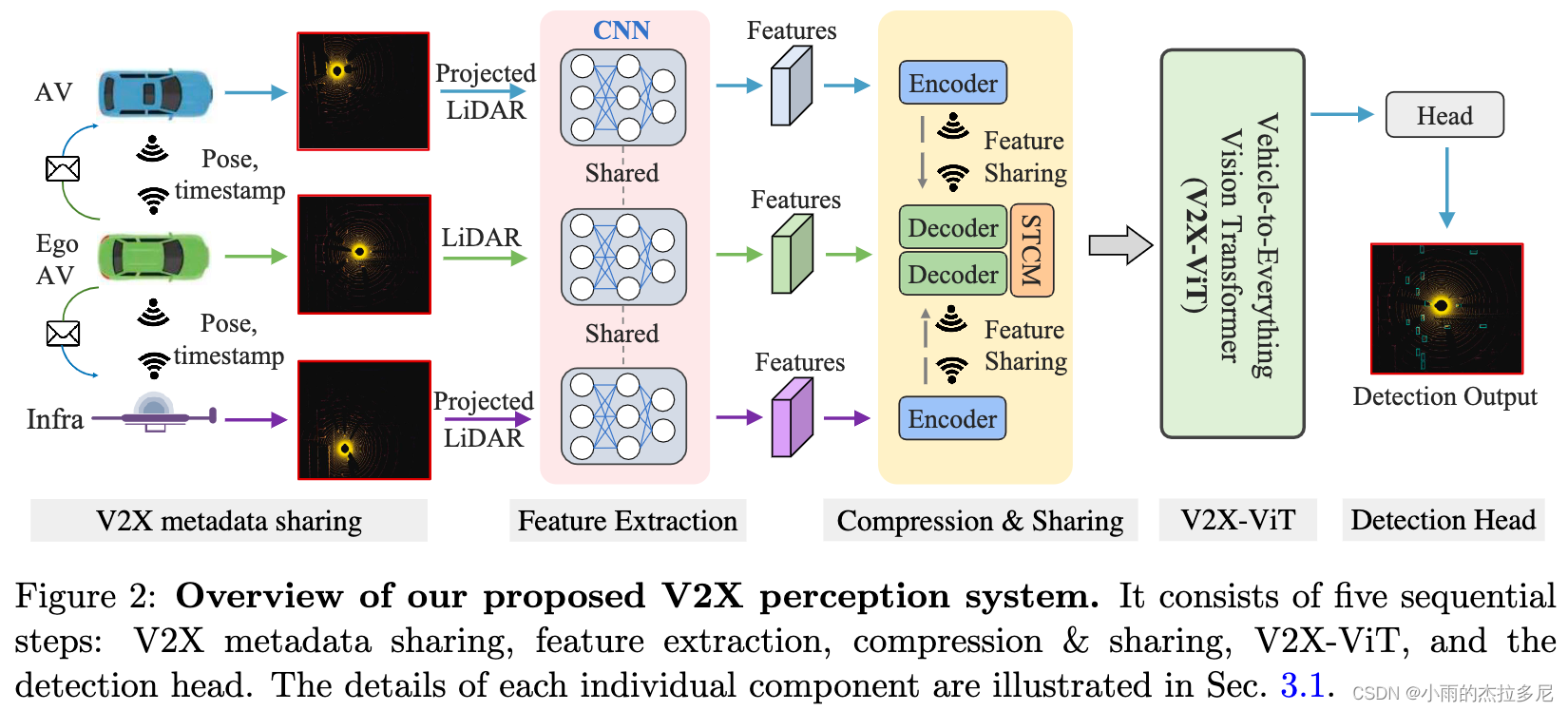
1. V2X metadata sharing
选择一个车作为ego vehicle(可以理解成中心车辆),将其与周围的agent(vehicle & infra)构建V2X图(边界是communication、节点是 v or infra)
忽略ego v把自己的pose发给各个agent的时间。在各个agent收到ego的pose的时候,就把自己获取的点云project到ego的pose坐标系下。
2. Feature extraction
因为PointPillar模型的低推断延迟和优化的内存使用,因此选择其作为backbone提取特征信息。
得到 H*W*C 的Feature Map
3. Compression and sharing
为了减少带宽,利用一系列 11 conv将其压缩,传到ego后再用 11 conv变回 H*W*C 尺寸。
但是再减带宽,也会有个inevitable的时间延迟,导致other agents获取到的projected 3D data传到ego这里的时候会对不齐。(不是同一个时间了)
采用spatial-temporal correction module(STCM)模块给他transform回来
4. V2X-ViT
后边具体说。
值得注意的是:在整个Transformer中,我们将特征图保持在相同的高分辨率级别。
5. Detection Head
这就是为了做具体的下游任务(3D Detection)而定的。
- box regression( Smooth L1 Loss)
(x, y, z, w, l, h, θ)
position: x y z
size: w l h
yaw angle: θ - classification(Focal Loss)
对于每一个anchor,输出为对象还是背景的confidence score
V2X-ViT
对这一块暂时理解比较浅,这个论文的数据集分为车端和路侧两个部分,暂时搁置。

1. HMSA
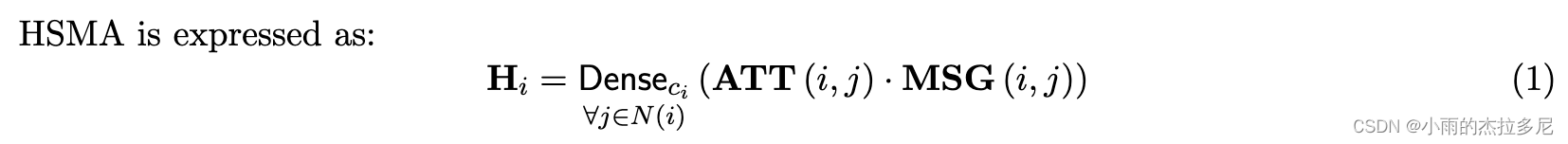
Contains 3 operators: a linear aggregator Dense , attention weights estimator ATT, and message aggregator MSG.


‖代表concat,m is the current head number and h is the total number of heads.

2. MSWA

在较大的窗口内执行的注意力可以捕捉远距离的视觉线索,以补偿较大的定位错误,而较小的窗口分支执行更细的尺度的注意力,以保留局部上下文。
3. Delay-aware positional encoding
使用这个encoding来消除由于时间延迟而导致的运动位置变化。
实验部分
1. 数据对比
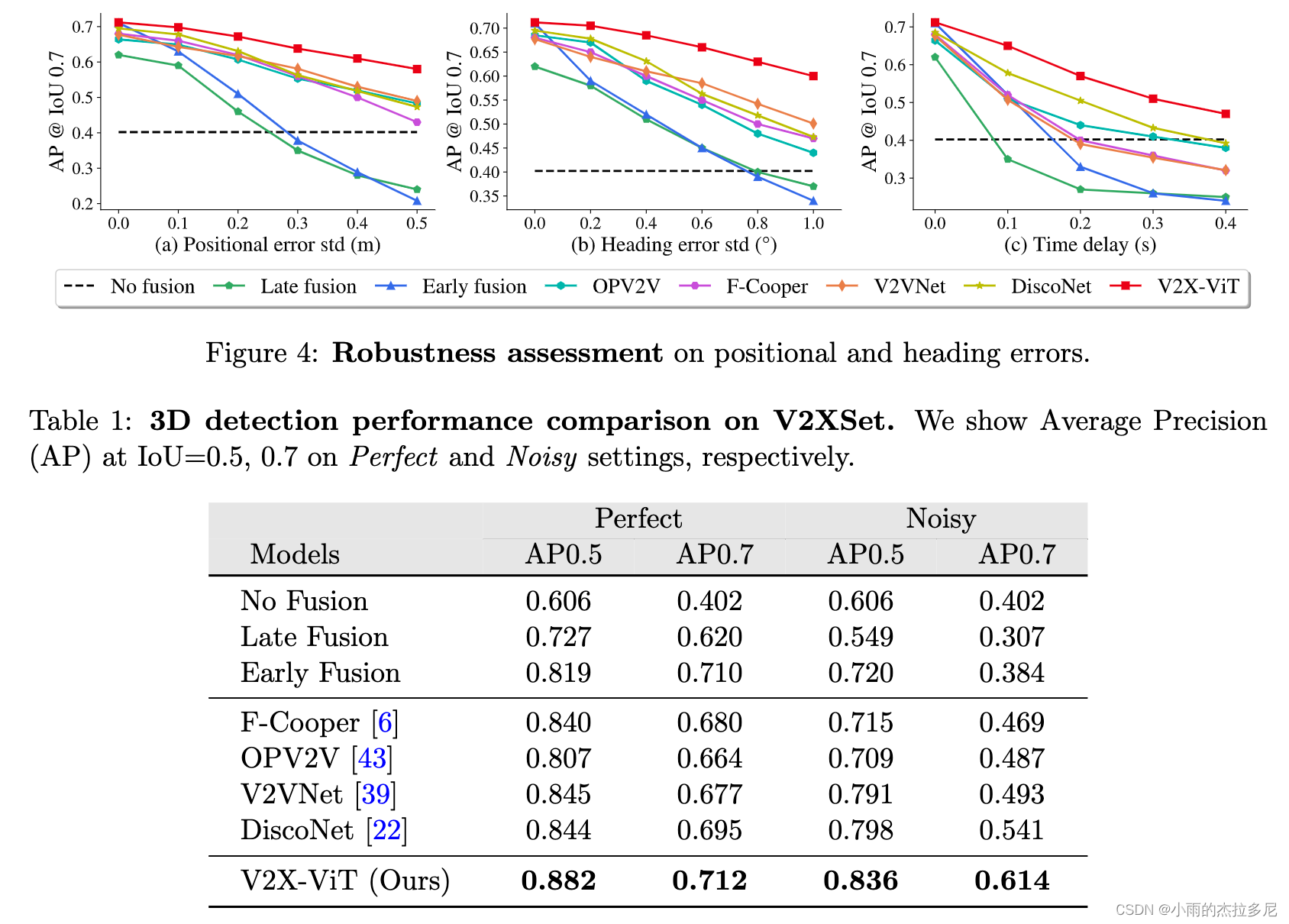
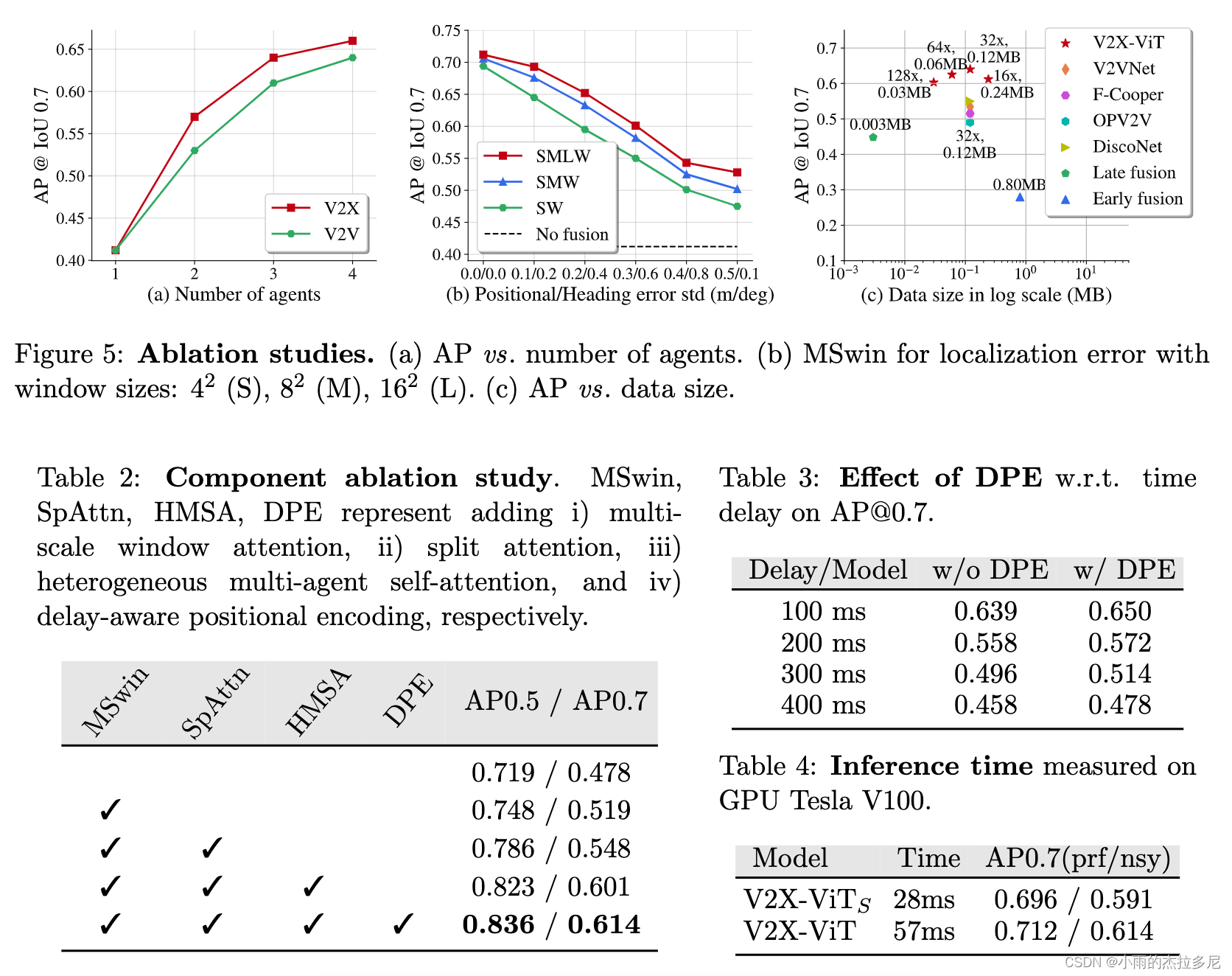
消融实验
2. 图片结果对比
直观检测结果⬇️

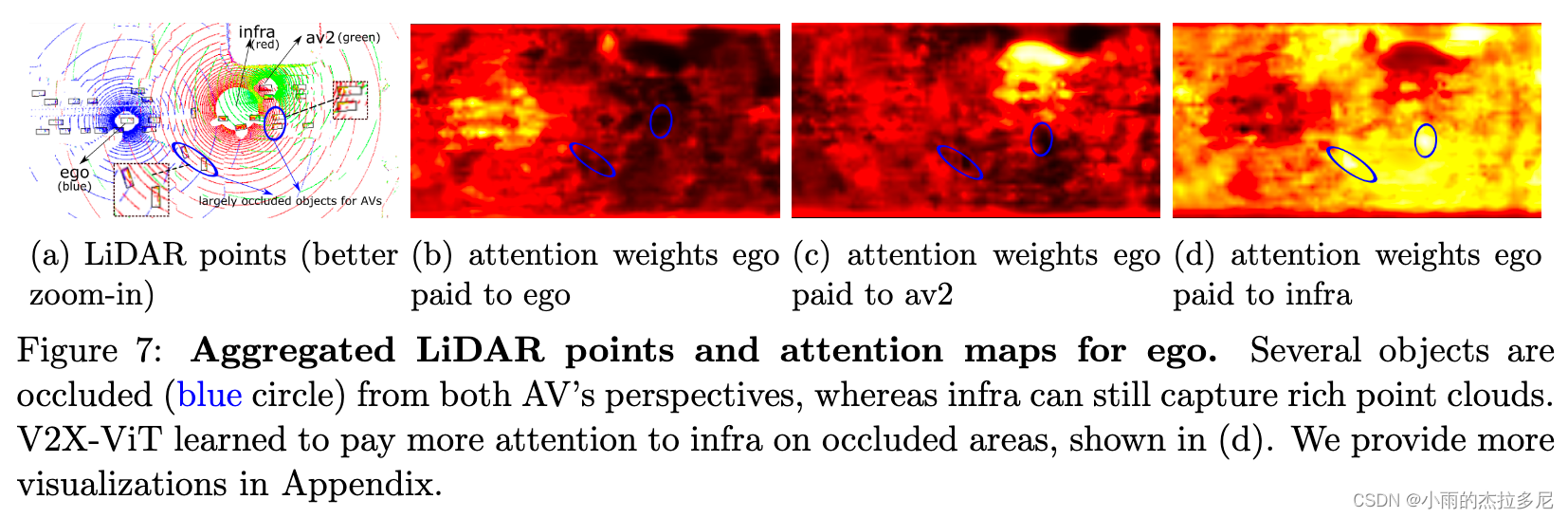
实验证明加入infra信息对于遮挡问题的改善效果⬇️
越亮表示关注度越高,最右侧为infra给提供的信息。