目录
1.散列表
散列表也称为哈希表,是一种数据结构,其特点是:数据元素的关键字与其存储地址(散列地址或者哈希地址)直接相关。
(1) 哈希函数是一个映像,所以哈希函数的设定是非常的灵活的,只要使得任何关键字由此所得的哈希函数值都落表长允许的范围之内即可。
(2)对不同的关键字可能得到同一哈希地址,也就是key1不等于key2,但是f(key1)=f(key2),这种称为冲突。具有相同的函数的关键字对该哈希函数来说称为同义词。
2.哈希函数的构造方法
(1)直接地址法
H(key)=key或者H(key)=a*key+b;其中a和b为常数。
(2)数字分析法
(3)平方取中法
(4)折叠法
(5)除留余数法
H(key)=key MOD p,p<=m.
其中:取关键字被某个不大于哈希表长度m的数p除后所得余数为哈希地址(也就是所取得p不大于表长m)。
3.处理哈希表中冲突的方法
(1)开放定址法
Hi=( H(key) + di ) MOD m i=1,2,3,…….
其中H(key)为哈希函数;m为哈希表的长度,di为增量序列,而增量序列的选择有以下三种:
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
#define MAXSIZE 11
typedef int ElemType;
struct linearTable{
int addr;//散列地址
int num;//比较的次数
int key;//输入的关键字
};
//线性表
linearTable table[MAXSIZE];
void DisplayTable(int m){
//输出散列地址
printf("散列地址 ");
for(int i=0;i<m;i++){
printf("%d\t",table[i].addr);
}
printf("\n");
printf("关键字 ");
for(int i=0;i<m;i++){
printf("%d\t",table[i].key);
}
printf("\n");
printf("比较次数 ");
for(int i=0;i<m;i++){
printf("%d\t",table[i].num);
}
printf("\n");
}第一种线性探测再散列:di=1,2,3,……,m-1。
//线性探测法
void LinearExplore(){
for(int i=0;i<MAXSIZE;i++){
table[i].addr=i;
table[i].num=0;
table[i].key=0;
}
int m,p;
printf("请输入表的长度: ");
scanf("%d",&m);
printf("请输入模数p: ");
scanf("%d",&p);
ElemType e;
printf("请输入关键字(end_-1): ");
scanf("%d",&e);
while(e!=-1){
int index=e%p;
//判断是否冲突
if(table[index].key!=0){
//采用线性探测法寻找空位置
bool flag=false;//标记是否存在空位置
for(int i=1;i<=m-1;i++){
int idx=(index+i)%p;
if(table[idx].key==0){
table[idx].key=e;
table[idx].num=i+1;
flag=true;
break;
}
}
if(!flag){
printf("不存在空位置\n");
break;
}
}else{
table[e%p].key=e;
table[e%p].num=1;
}
printf("请输入关键字(end_-1): ");
scanf("%d",&e);
}
//打印输出表的情况
DisplayTable(m);
}
int main(){
LinearExplore();
return 0;
}假设散列表的长度为8,散列函数为H(key)=key%7,用线性探测法解决冲突,则根据第一组初始关键字序列(8,15,16,22,30,32)构造出的散列表。
| 散列地址 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 关键字 | 8 | 15 | 16 | 22 | 30 | 32 | ||
| 比较次数 | 1 | 2 | 2 | 4 | 4 | 3 |
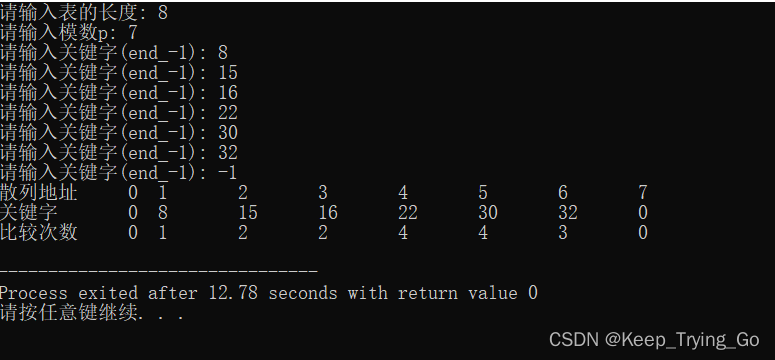
查找成功的平均长度:ASL=(1+2+2+4+4+3)/6=8/3.
查找失败的平均长度:ASL=(1+7+6+5+4+3+2+1)/8=29/8.
第二种二次探测再散列:di=1^2, -1^2, 2^2, -2^,……,±k^2,(k<=m/2)。
| 散列地址 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 关键字 | 22 | 8 | 15 | 16 | 32 | 30 | ||
| 比较次数 | 2 | 1 | 2 | 2 | 1 | 4 |
void SquExplore(){
for(int i=0;i<MAXSIZE;i++){
table[i].addr=i;
table[i].num=0;
table[i].key=0;
}
int m,p;
printf("请输入表的长度: ");
scanf("%d",&m);
printf("请输入模数p: ");
scanf("%d",&p);
ElemType e;
printf("请输入关键字(end_-1): ");
scanf("%d",&e);
while(e!=-1){
int index=e%p;
//判断是否冲突
if(table[index].key!=0){
//采用线性探测法寻找空位置
bool flag=false;//标记是否存在空位置
for(int i=1;i<=m/2;i++){
for(int j=1;j<=2;j++){
int idx=0;
if(j==2){
idx=(index-(i*i))%p;
}else{
idx=(index+(i*i))%p;
}
if(idx<0){
idx=(idx+m)%p;
}
if(table[idx].key==0){
table[idx].key=e;
table[idx].num=i+1;
flag=true;
break;
}
}
if(flag)break;
}
if(!flag){
printf("不存在空位置\n");
break;
}
}else{
table[e%p].key=e;
table[e%p].num=1;
}
printf("请输入关键字(end_-1): ");
scanf("%d",&e);
}
//打印输出表的情况
DisplayTable(m);
}
int main(){
// LinearExplore();
SquExplore();
return 0;
}
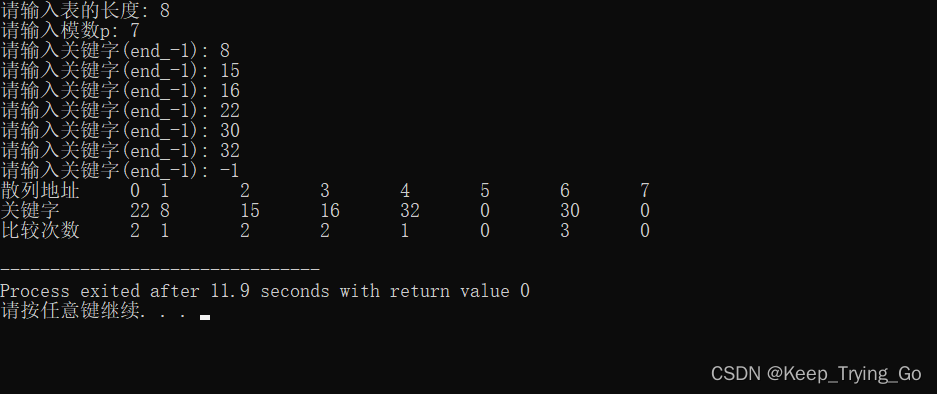
查找成功的平均长度:ASL=(2+1+2+2+1+4)/6=2.
查找失败的平均长度:ASL=(6+5+4+3+2+1+4+1)/8=13/4.
第三种伪随机探测再散列: di=伪随机数序列。
(2)再哈希法
Hi=RHi(key),i=1,2,3,……,k。
RHi均是不同的哈希函数,即在同义词地址冲突时计算另一个哈希函数地址,直到不发生冲突为止,而且这种方法不容易产生“聚集”,但是增加了计算的时间。
(3)链地址法
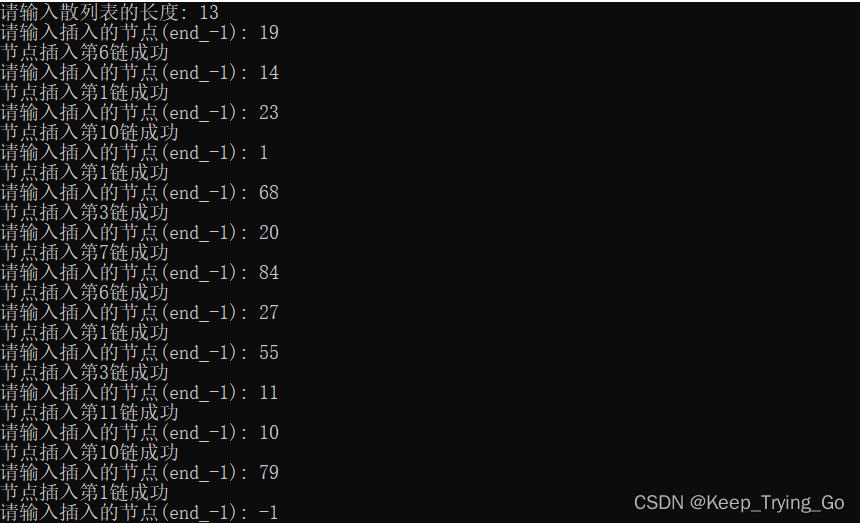
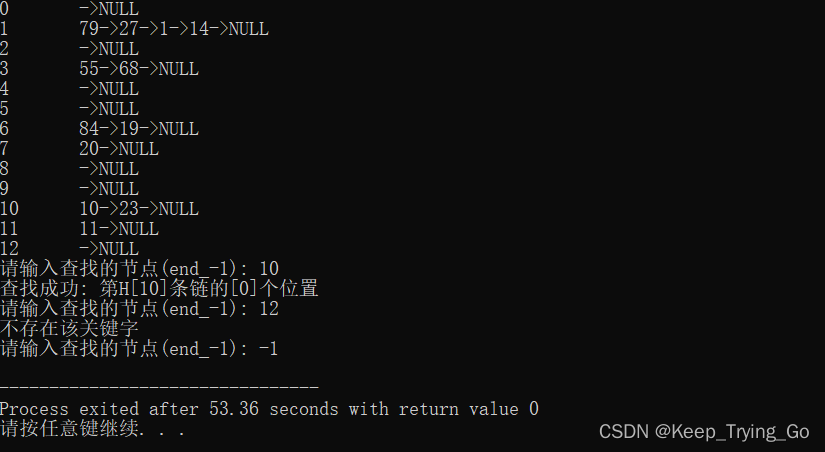
已知一组关键字为(19,14,23,01,68,20,84,27,55,11,10,79) ,这按哈希函数H(key)=key MOD 13和链地址法处理冲突构造所得的哈希表。
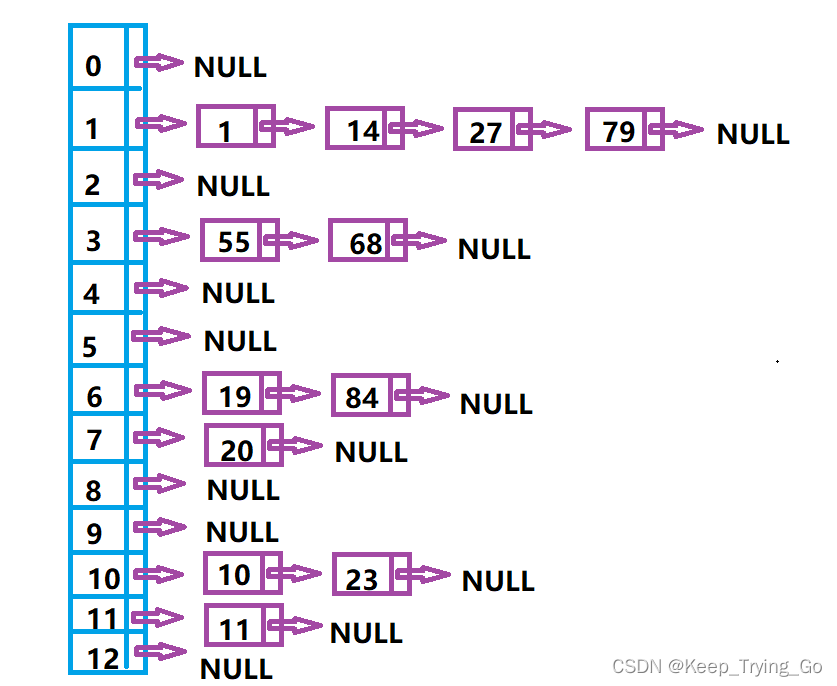
查找成功的平均长度:ASL=(1x6+2x4+3x1+4x1)/12=7/4.
查找失败的平均查找长度:ASL=(4+2+2+1+2+1)/13=12/13.
建立数据结构:
#include<stdio.h>
#include<stdlib.h>
#define MAXSIZE 15
typedef int ElemType;
typedef struct LNode{
ElemType data;
struct LNode*next;
}LNode,*LinkList;
typedef struct Hash{
ElemType MaxSize;
LinkList table;
}*HashTable;初始化和销毁操作:
//散列表的长度
ElemType size=0;
//散列表
HashTable H[MAXSIZE];
//初始化
void InitLinkList(){
for(int i=0;i<MAXSIZE;i++){
H[i]=(HashTable)malloc(sizeof(HashTable));
//注意这里需要给HashTable申请空间才能使用后面的操作
if(H[i]==NULL){
printf("分配内存失败!\n");
exit(0);
}
H[i]->table=(LNode*)malloc(sizeof(LNode));
if(H[i]->table==NULL){
printf("分配内存失败!\n");
exit(0);
}
H[i]->table->next=NULL;
H[i]->MaxSize=0;
}
}
//销毁表(和单链表一样)
void DestryHashTable(){
for(int i=0;i<size;i++){
//这里不删除头节点
LNode*p=H[i]->table;
while(p->next!=NULL){
LNode*s=p->next;
p->next=s->next;
free(s);
}
}
}
插入关键字操作:
//插入数据元素
void InsertHashTable(ElemType e){
//计算插入的第几条链
int index=e%size;
LNode*p=H[index]->table;
H[index]->MaxSize++;
LNode*s=(LNode*)malloc(sizeof(LNode));
s->data=e;
s->next=p->next;
p->next=s;
printf("节点插入第%d链成功\n",index);
} 查找关键字:
//散列查找
bool FindKey(ElemType e){
int index=e%size;
if(H[index]->table->next==NULL){
printf("不存在该关键字\n");
return false;
}else{
LNode*p=H[index]->table->next;
int loc=0;
while(p!=NULL&&p->data!=e){
p=p->next;
loc++;
}
if(p!=NULL){
printf("查找成功: 第H[%d]条链的[%d]个位置\n",index,loc);
}else{
printf("不存在该关键字\n");
return false;
}
}
}
打印操作和主函数:
//打印
void DisplayHashTable(){
for(int i=0;i<size;i++){
LNode*p=H[i]->table->next;
printf("%d\t",i);
if(p==NULL){
printf("->NULL");
}else{
while(p!=NULL){
printf("%d->",p->data);
p=p->next;
}
printf("NULL");
}
printf("\n");
}
}
int main(){
printf("请输入散列表的长度: ");
scanf("%d",&size);
InitLinkList();
printf("请输入插入的节点(end_-1): ");
ElemType e;
scanf("%d",&e);
while(e!=-1){
InsertHashTable(e);
printf("请输入插入的节点(end_-1): ");
scanf("%d",&e);
}
//销毁表
DisplayHashTable();
//查找关键字
ElemType key;
printf("请输入查找的节点(end_-1): ");
scanf("%d",&key);
while(key!=-1){
FindKey(key);
printf("请输入查找的节点(end_-1): ");
scanf("%d",&key);
}
//销毁表
DestryHashTable();
return 0;
}