一张图像中能够匹配到目标的候选框(正样本)个数一般只有十几个活几十个。而没有匹配到的候选框(负样本)大概有10000 - 100000个。在这10000 - 100000个未匹配的候选框中大部分都是简单易分的负样本(对训练网络起不到什么作用,但由于数量太多淹没掉少量但有助于训练的样本)focal loss 的设计是为了去应对one stage目标检测里面正负样本极度不平衡的情况(前景和背景极度不平衡的情况)。因此,focal loss具有两个重要的特点: 1、控制正负样本的权重 2、控制容易分类和难分类样本的权重。
公式(1)交叉熵loss:
公式(2):
对于二分类而言计算公式如(1)所示。y=1表示正样本。公式里的log = ln。将公式(2)带入公式(1)中可简化为 -log(pt)。为了控制各部分的权重引入参数α。此时公式如(3)所示。当为正样本时αt = α ,当为负样本时αt = 1 - α。α本质上是超参数,不是正负样本的比例。作者实验得出α为0.75时效果最好。
公式(3):
为了降低简单样本的权重,聚焦于困难样本的训练。作者引入新因子。公式如(4)所示,其中p代表样本为1类的概率,因此对于正样本而言p值越小也就是1-p越大越难分类,对于负样本而言p值越大越难分类,所以利用1-Pt就可以计算出每个样本属于容易分类或者难分类。 当样本为正时我们希望p越大越好,当样本为负时我们希望p越小越好。因此无论正负样本我们都希望pt越大越好。α是平衡正负样本的权重,但是它并不能区分样本是容易区分还是困难区分。
其中:
就是每个样本容易区分的程度,为调制系数。当Pt趋于0时调制系数趋于1,对于总的loss的贡献很大,当Pt趋于1的时候,调制系数趋于0,对总的loss贡献很小。当
=0时。focal loss就是传统的交叉熵损失,可以通过调整
实现调制系数的改变。
Focal loss最终的表达式
作者经过实验得出当α = 0.25 γ = 2时效果最好 。
例子
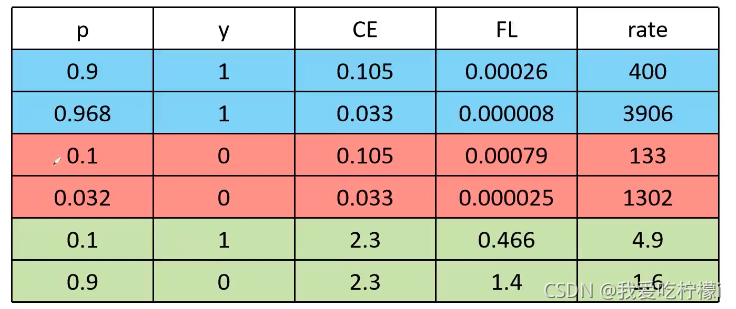
此图的γ=2,α=0.25。
其中:p表示预测的目标概率, y表示真实的标签 (1为正样本0为负样本),CE是采用二分类获得的损失, FL 为采用Focal loss得到的损失, rate为CE和FL之间的倍数。
首先看前两行两个都是正样本,而且他们的p都很大,在正样本中属于易分的正样本。求得他们的CE 分别为0.105 ,0.033。可以看到使用FL会使易分的样本loss占比下降很多。同理第三四行也是一样。最后两行可以看出他们都是相对难区分的样本,FL对其的倍数相较于易分的样本差距很大。从而可以看出FL能够降低易分样本的损失贡献。
Focal loss的缺点:容易受到噪音的干扰。因为你一旦正负样本标注错了,就会一直针对训练你标错的样本。因此使用Focal loss一定要把样本标注正确。