上期视频我们分享了一个AI算法,本期我们就分享一下实现代码

此AI算法称之为CoNR,该技术通过基于多个动画指定姿势来创建舞蹈视频。
——1——
什么是CoNR?
下面是CoNR的示意图。将目标姿势 ( Itar ) 转换为由紧凑地标数字表示的 UDP 表示 ( Ptar)
另一方面,几个动画(Sref)输入到 U-Net 格式网络,由Encoder 编码,并由 Decoder 与 UPD 表示(Ptar)一起解码。此时,通过共享多个解码器 D1 到 D3的权重来创建目标姿势动画。
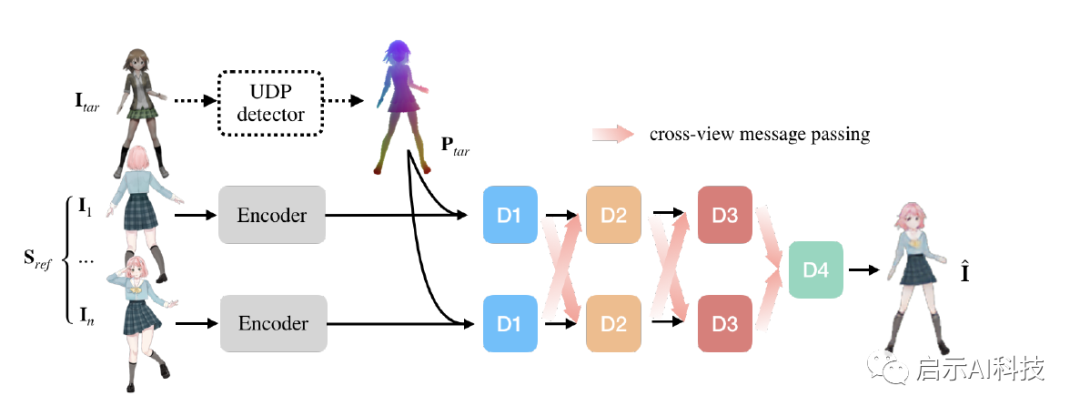
CoNR
源代码 https://github.com/megvii-research/CONR
CoNR
——2——
代码实现
#@title Repo 初始化#@markdown 克隆github上的项目repo,并安装相应的依赖。!git clone https://github.com/megvii-research/CoNR.git%cd CoNR!pip install -r requirements.txt#下载权重/content/CoNR/weightsFrom: https://drive.google.com/uc?id=1M1LEpx70tJ72AIV2TQKr6NE_7mJ7tLYxTo: /content/CoNR/weights/rgbadecodernet.pthFrom: https://drive.google.com/uc?id=1YvZy3NHkJ6gC3pq_j8agcbEJymHCwJy0To: /content/CoNR/weights/shader.pthFrom: https://drive.google.com/uc?id=1AOWZxBvTo9nUf2_9Y7Xe27ZFQuPrnx9iTo: /content/CoNR/weights/target_pose_encoder.pthFrom: https://drive.google.com/uc?id=19jM1-GcqgGoE1bjmQycQw_vqD9C5e-JmTo: /content/CoNR/weights/udpparsernet.pth

Step1:首先是copy github的源代码,并安装需要的第三方包与预训练权重,这样,我们就初始化完成了整个项目。
UDP = 'double_ponytail' #@param ['double_ponytail', 'short_hair', 'self_defined']#@markdown 下载示例超密集姿势序列if UDP == 'short_hair':%cd ..!gdown https://drive.google.com/uc?id=11HMSaEkN__QiAZSnCuaM6GI143xo62KO!unzip short_hair.zip!mv short_hair/ poses/!lselif UDP == 'double_ponytail':%cd ..!gdown https://drive.google.com/uc?id=1WNnGVuU0ZLyEn04HzRKzITXqib1wwM4Q!unzip double_ponytail.zip!mv double_ponytail/ poses/!lselse:print("Please upload your UDP sequences or poses images to /content/CoNR/poses/ .")character = 'double_ponytail' #@param ['double_ponytail', 'short_hair', 'self_defined']From: https://drive.google.com/uc?id=1XMrJf9Lk_dWgXyTJhbEK2LZIXL9G3MWcTo: /content/CoNR/double_ponytail_images.zip

Step2:代码需要选择一个超密集姿势,这里官方提供两个示例序列:`双马尾:double_ponytail`和`短发:short_hair`。当然,我们自己也可以制作自己的动漫图片,并上传自己的超密集姿势序列或者姿势图像到路径`/content/CoNR/poses/`下.
Step3:选择人物设定表,人物设定表指的是某一个人物多角度/姿势下的手绘图片。官方提供两种示例人物设定表:`双马尾:double_ponytail`和`短发:short_hair`。当然我们也可以选择`自定义:self_defined`并上传自己绘制的人物设定表到路径`/content/CoNR/character_sheet/`下。人物设定表中的人应当是同一个人,且应当和超密集姿势序列尽可能相似,否则生成结果将不可控。例如,对于短发的超密集姿势序列,推荐您使用短发的人物设定表作为输入。

import cv2import numpy as npimport ospath ='/content/CoNR/character_sheet/'files= os.listdir(path)imgs = []for file in files:if not os.path.isdir(file):img = cv2.imread(path+"/"+file, cv2.IMREAD_UNCHANGED);imgs.append(img)print("Num of character sheets:", len(imgs))imgs = np.concatenate(imgs, 1)cv2.imwrite('character_sheet.png', imgs)from IPython.display import ImageImage(filename='character_sheet.png')!mkdir results!python3 -m torch.distributed.launch \--nproc_per_node=1 train.py --mode=test \--world_size=1 --dataloaders=2 \--test_input_poses_images=./poses/ \--test_input_person_images=./character_sheet/ \--test_output_dir=./results/ \--test_checkpoint_dir=./weights/
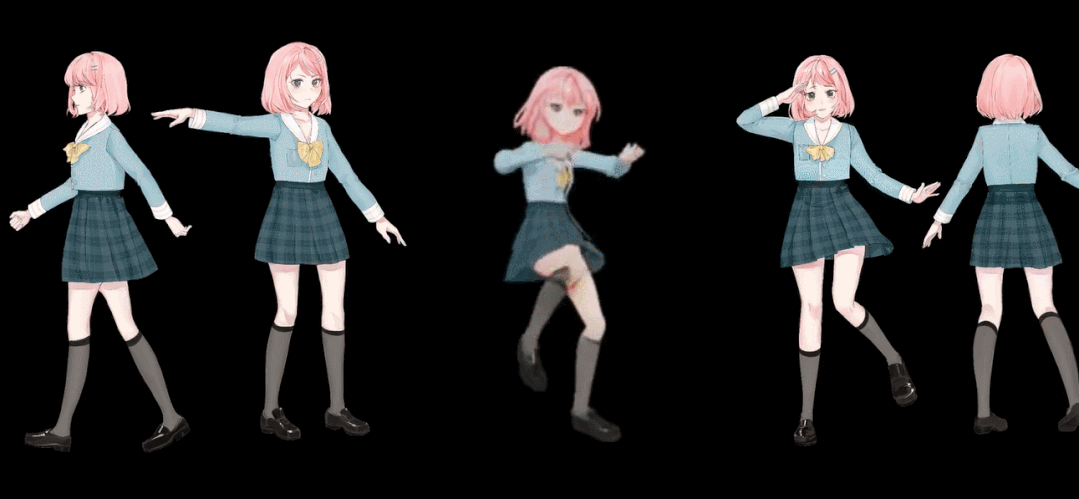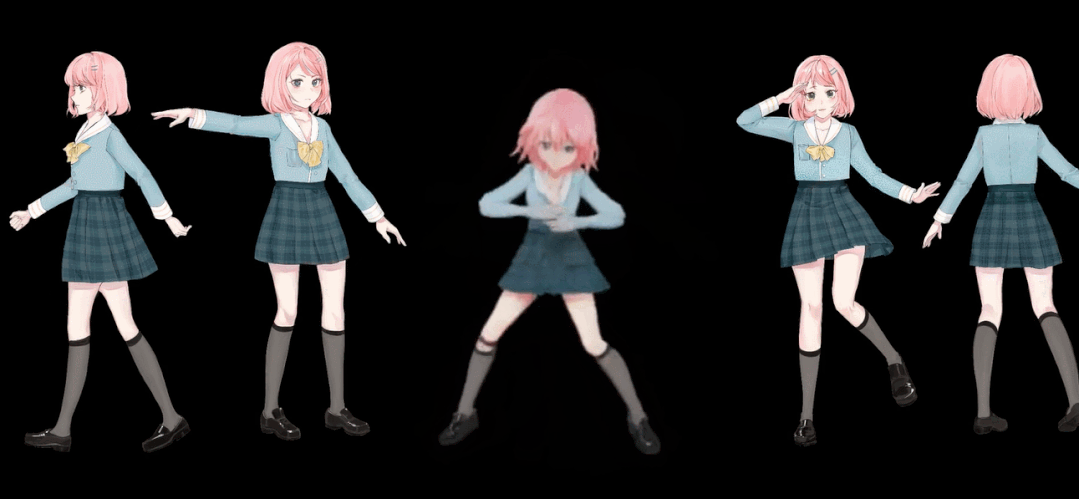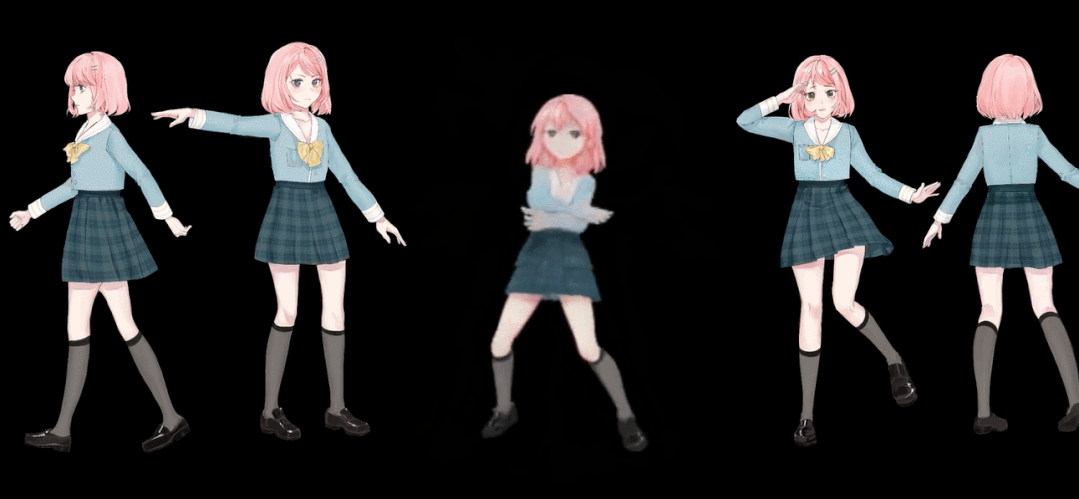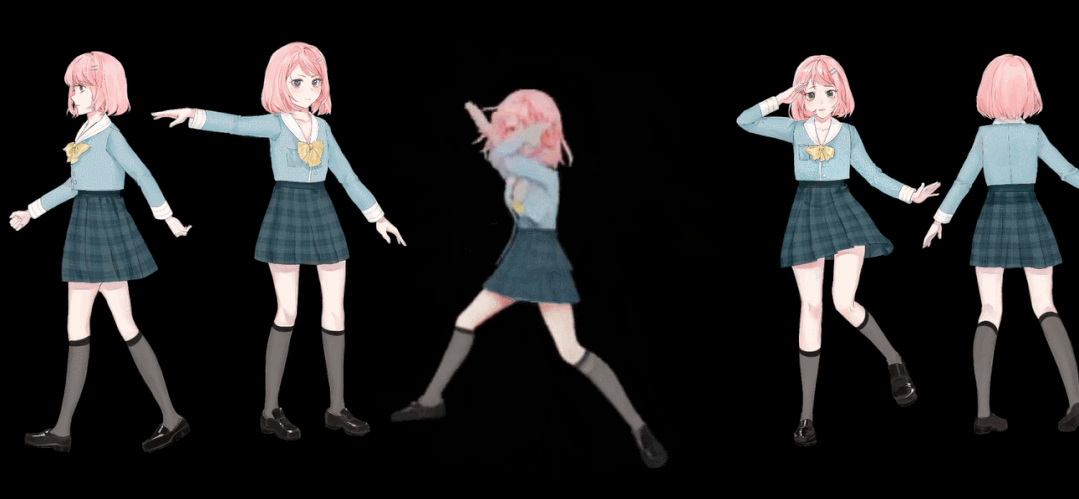
Step4:图片,模型设置完成后,我们就可以进行模型的推理计算了,此模型根据输入的图片生成一系列动漫舞蹈图片,当然这些图片都是连贯的,我们只需要把这些图片使用ffmpeg来制作成视频即可,此模型运行需要很长时间,当然根据个人的电脑配置,本例程运行在Google colab上面,根据你的运行条件,每个人的运行时间不一样,当然你随时可以中断模型运行,使用模型中断前已经生成的图片,便可以制作舞蹈视频了,只是视频长度较短
!ffmpeg -r 30 -y -i ./results/%d.png -r 30 -c:v libx264 output.mp4 -r 30from IPython.display import HTMLfrom base64 import b64encodedef show_video(video_path, video_width = 600):video_file = open(video_path, "r+b").read()video_url = f"data:video/mp4;base64,{b64encode(video_file).decode()}"return HTML(f"""<video width={video_width} controls><source src="{video_url}"></video>""")show_video('output.mp4')

Step5:最后,我们使用ffmpeg把模型生成的系列图片来制作成动漫视频,最后,我们预览一下生成的视频即可,当然,生成的视频,可以下载到本地,方便后期进行处理

当然也有在线版本,把人物舞蹈的视频,实时转换成动漫视频,这个可以自行尝试
Transormer模型重点介绍了encoder与decoder,有6个编码器与6个解码器组成,其Transormer模型主要应用在NLP领域,但是随着Transormer模型的大火,其模型成功应用在了CV计算机视觉领域,其Transormer模型,Vision Transormer模型,SWIN Transormer模型都会在如下专栏进行详细动画分享
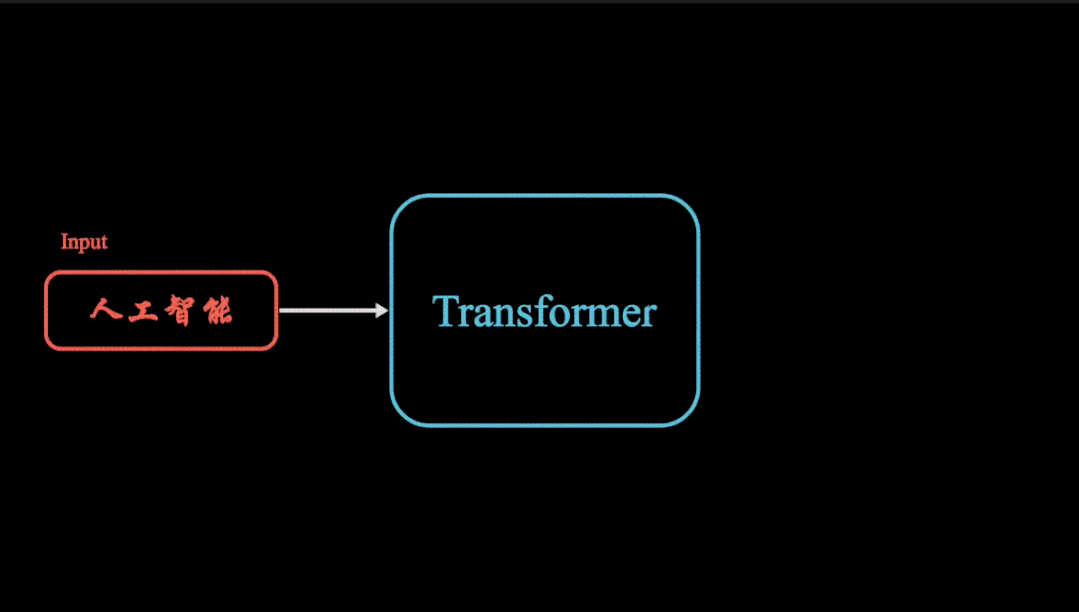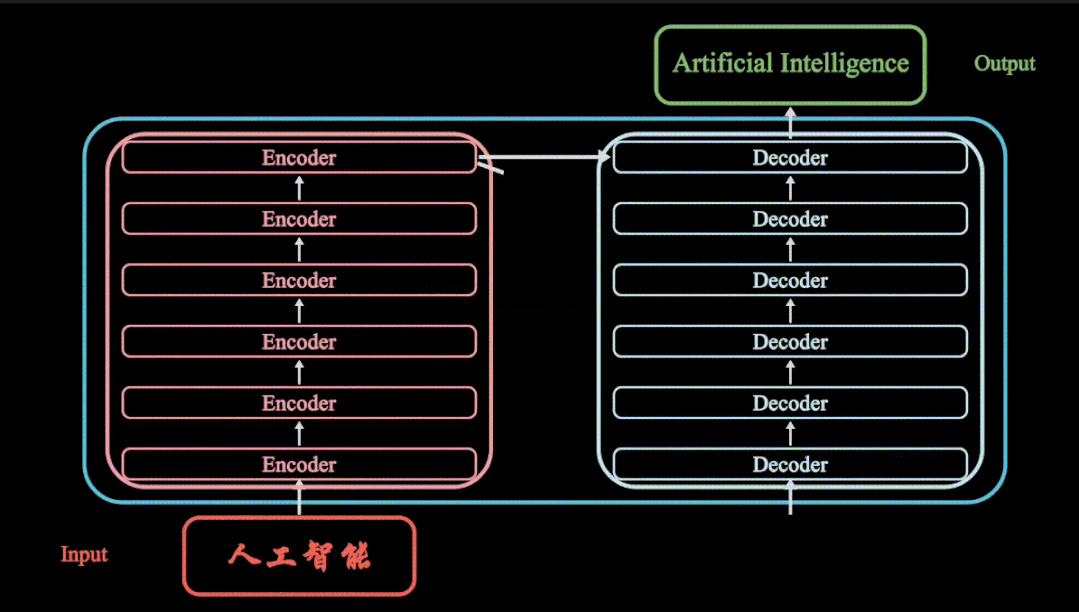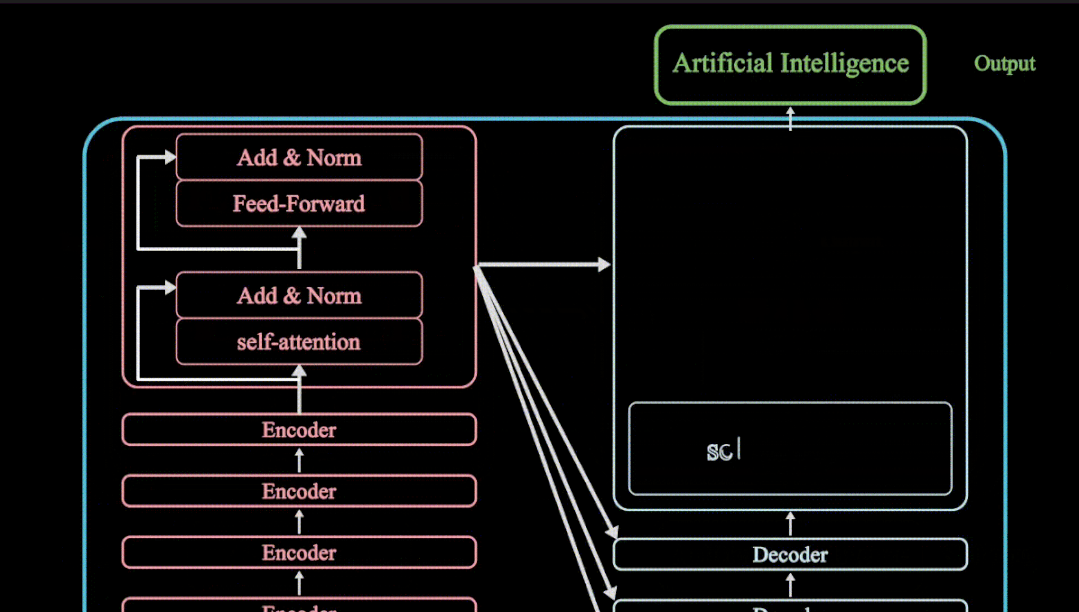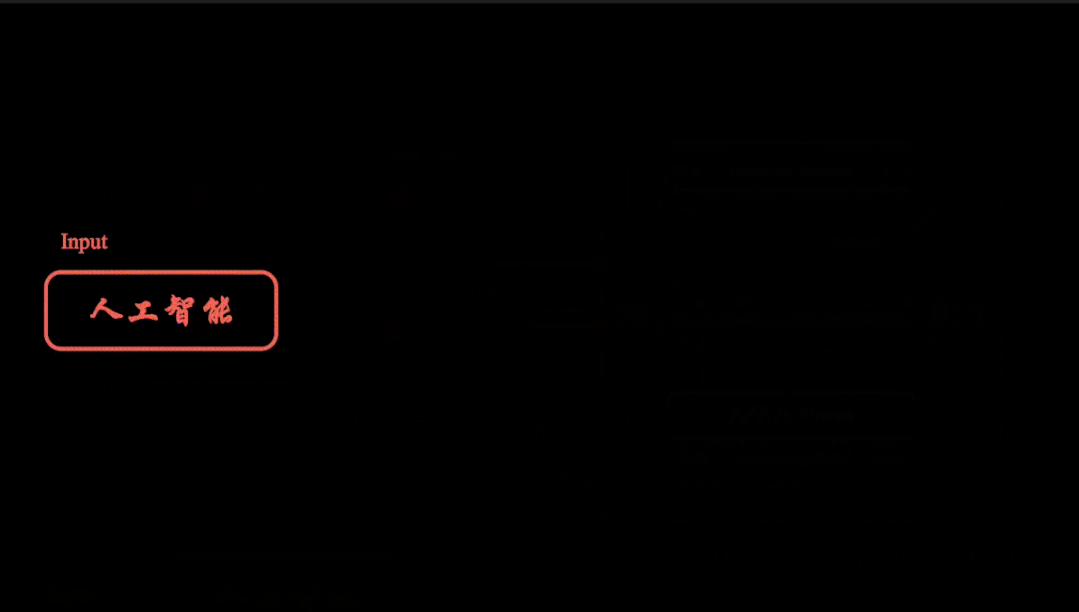
更多Transformer 视频动画教程
请参考头条号:人工智能研究所VX搜索小程序:AI人工智能工具,体验不一样的AI工具
