本文是基于刘启林老师的知乎文章所进行的学习笔记。
XGBoost(eXtreme Gradient Boosting)极致梯度提升,是一种基于GBDT的算法或者说工程实现。
XGBoost基础
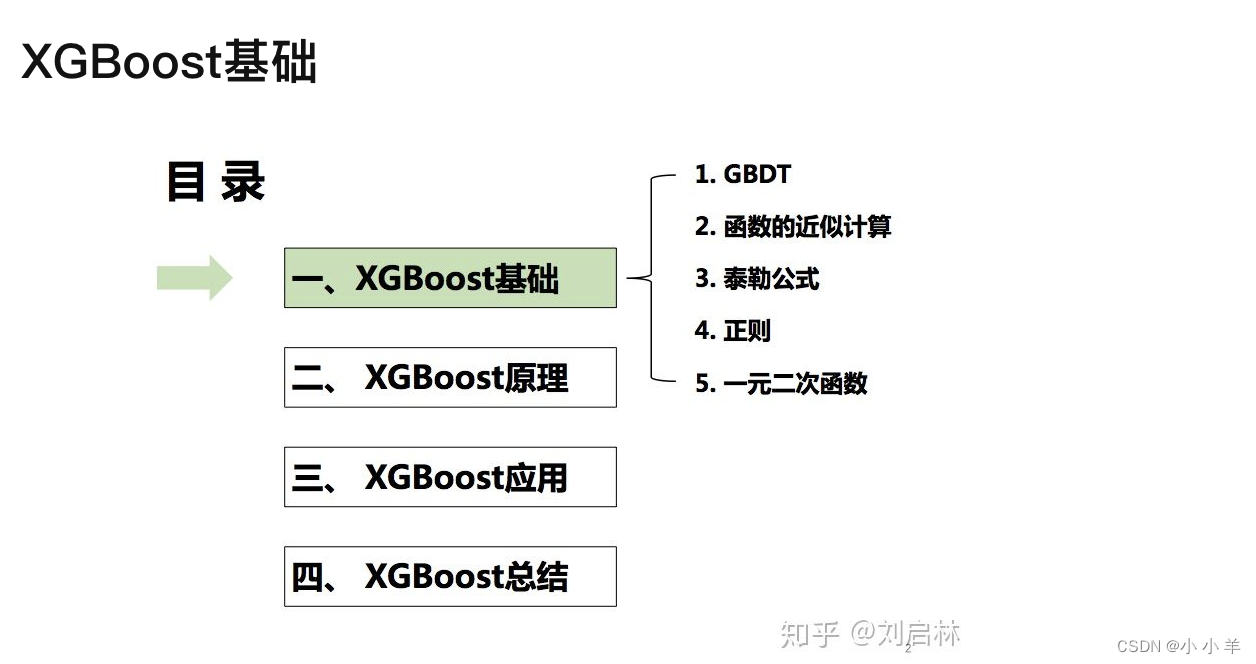
1、GBDT基础
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是一种基于boosting集成思想的加法模型,训练时采用前向分布算法进行贪婪的学习,每次迭代都学习一棵CART树来拟合之前 t-1 棵树的预测结果与训练样本真实值的残差。这也导致GBDT是串行的,无法并行计算。
boosting集成策略:

预备知识:提升树的训练例子


第一棵树:

第二棵树:

第三棵树:

以此类推

提升树使用的残差是真实值与预测值的差。而GBDT使用的是负梯度

GBDT高度概括:
- 使用基于提升树的算法
- 负梯度来模拟残差
- 针对上一轮的残差,使用一棵树来“拟合”
- 最终会得到M课树,每棵树有J个节点,那么最终GBDT的表达式如下所示:
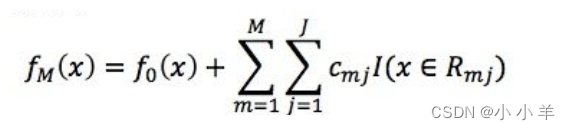
XGBoost原理
1、概述
XGBoost的基本思想和GBDT相同,但XGBoost进行许多优化,如下所示

2 XGBoost目标函数推导
XGBoost目标函数由两块组成:损失函数和正则项


二阶泰勒展开
由于t-1棵树已经结构已经被确定(提升树的概念)、所以可以去掉不含有x的部分,即去掉二阶泰勒展开的常数项。

正则化项展开
这里就是留下了当前t的这棵树的结构参数

合并一次项、二次项系数
首先重新定义一棵树,其核心就是这种权重w,根据映射关系q和权重w可以“检索”到树上的每一个节点
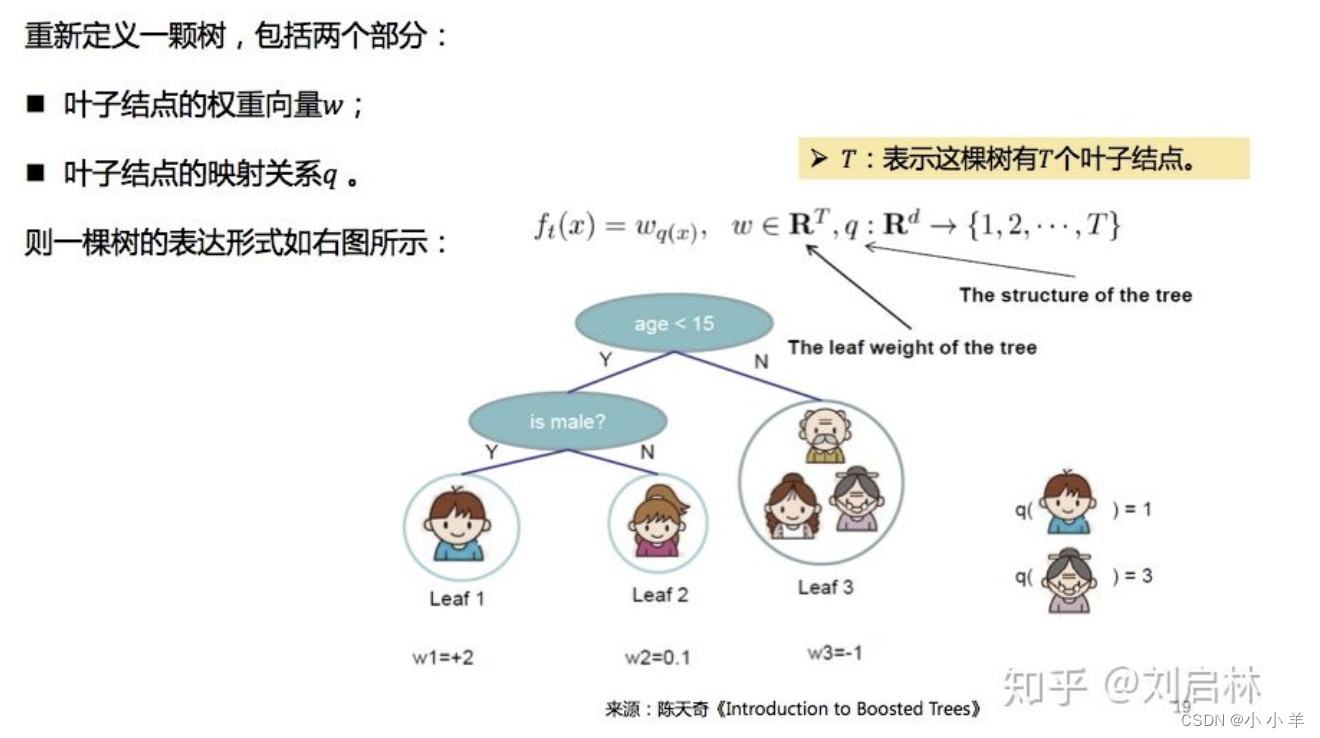
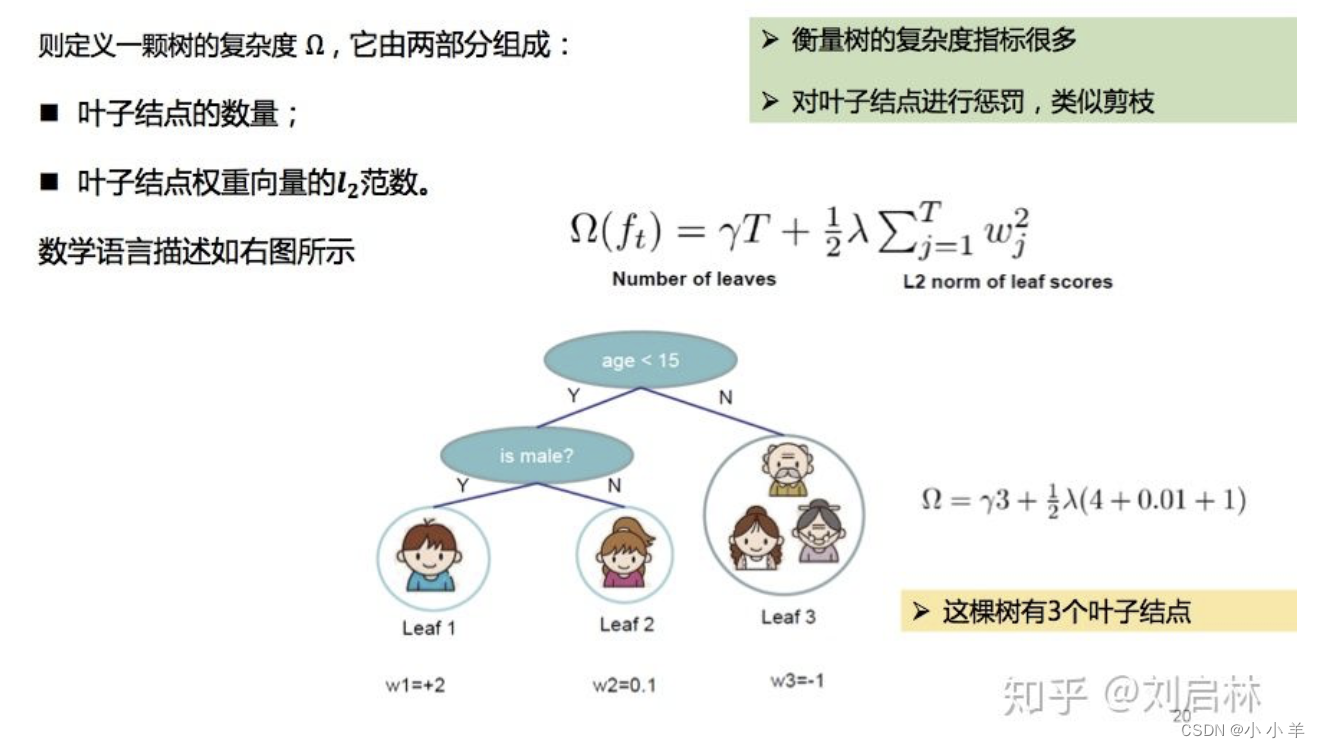
然后,定义树的复杂度。其实就是算正则项。由叶子结点和权重w的l2范数决定。
最后合并系数


XGBoost目标函数解求解
这里其实就是用的是一元二次方程的最优解求解公式。

每个节点都是独立的,所以当每个节点取得最优解时,全局最优解也诞生了。
本文含有隐藏内容,请 开通VIP 后查看