Day5:多线程(3)
多线程在整个编程中都是非常核心非常重要的话题
- 多核CPU客观的主流的需求
- 多线程这里还是有一定难度/不少注意事项的
回顾
Thread创建的写法
继承Thread,重写run
实现Runnable,重写run
继承Thread,重写run,使用匿名内部类
实现Runnable,重写run,使用匿名内部类
使用lambda(推荐写法)
Thread中的一些核心属性和方法
- id
- name
- daemon:后台线程
- isAlive:判定系统内核中的线程是否存在
- start:启动线程(和run进行区分)
- 线程终止的写法
- 自己定义变量控制线程结束
- 使用Thread提供的标志位
isInterrupted/interrupt,即使线程中出现sleep等阻塞操作,也能被提前唤醒(sleep被唤醒之后会清空刚才设置的标志位)
1. join
线程等待(join):多个线程,调度顺序,在系统中,是无序的(抢占式执行),程序员希望在随机的体系上,加入一些控制,让结果变得不那么随机
package thread;
public class Demo12 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() ->{
for (int i = 0; i < 3; i++) {
System.out.println("hello Thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
System.out.println("thread end");
});
t.start();
for (int i = 0; i < 5; i++) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
t.join();
System.out.println("main end");
}
}
由于上述代码中,main和t线程之间的结束顺序是不确定的,如果希望t线程先结束,main后结束,就可以在main中使用线程等待(join)
- main线程中调用
t.join()就是让main等待t,也就是t先结束,main后结束 - 系统原生api就叫做pthread_join(linux)
- join要抛出的异常和sleep一样:
throws InterruptedException - main线程调用上述join方法,有以下两种可能
- 如果t线程此时已经结束了,此时join就会立即返回,没涉及到任何阻塞(阻塞:该线程暂时不参与cpu调度执行,解除阻塞继续执行,线程重新参与到cpu调度了)操作,直接往下执行了
- 如果t线程此时还没结束,此时join就会阻塞等待(确保了main线程一定是后结束的),一直等待到t线程结束之后,join才能解除阻塞,继续执行
package thread;
public class Demo13 {
public static void main(String[] args) throws InterruptedException {
Thread t2 = new Thread(() ->{
for (int i = 0; i < 4; i++) {
System.out.println("t2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
Thread t1 = new Thread(()->{
//t1一进来先等待t2结束
try {
Thread.sleep(500);
t2.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
for (int i = 0; i < 3; i++) {
System.out.println("t1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t1.start();
t2.start();
t1.join();
System.out.println("main end");
}
}
- 调用
main.join()
package thread;
public class Demo14 {
public static void main(String[] args) throws InterruptedException {
Thread t = Thread.currentThread();
System.out.println(t.getName());
Thread t2 = new Thread(()->{
try {
t.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("t2 end");
});
t2.start();
for (int i = 0; i < 5; i++) {
Thread.sleep(1000);
}
System.out.println("main end");
}
}
join的各个版本
| 返回值 | 参数 |
|---|---|
| void | join() |
| void | join(long millis) |
| void | join(long millis, int nanos) |
join(long millis)等待N毫秒int nanos等待M纳秒- 传入的时间,就是等待的最大时间,比如写了等待10ms,如果10ms之内,t线程结束了,直接返回,如果10ms到了,t还没结束,不等了,直接继续往下走了
- 实际开发中,一般很少会使用死等的策略,死等的话,整个程序容错能力比较低
- 纳秒这个级别的时间,对于主流系统来说,都是太精细了,Windows/linux这个的系统,无法精确到ns级别的时间,甚至说到了ms级别都容易出现误差,这类系统,线程调度开销很大,搞不好线程调度开销就要上ms级
package thread;
public class Demo15 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() ->{
for (int i = 0; i < 5; i++) {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
System.out.println("thread end");
});
t.start();
t.join(2000);
System.out.println("main end");
}
}
2. 再谈sleep
(1)使用sleep控制的是“线程休眠时间”而不是“两个代码执行的间隔时间”
package thread;
public class Demo16 {
public static void main(String[] args) throws InterruptedException {
System.out.println("start: " + System.currentTimeMillis());
Thread.sleep(1000);
System.out.println("end: " + System.currentTimeMillis());
}
}
此处设置sleep的时间,是线程阻塞的时间,1000ms之内,线程是一定不会去cpu上执行的(阻塞),当时间到了之后,线程从阻塞状态恢复到就绪状态,不代表线程就能立刻去cpu上执行的,从恢复就绪到真正去cpu上执行,还是需要一定时间的(具体是多少,看机器配置,系统繁忙程度了)
(2)sleep内部的实现,做了哪些事情,java代码中看不到
- 方法上带着native字样的,叫做“本地方法”,方法的实现,就是在JVM内部,通过cpp代码来实现
- JVM也有开源版本的实现(OpenJDK),Oracle官方的JDK不是开源的
3. 线程的状态
之前提到的“进程的状态”,更准确的说是**“线程的状态”或者叫做“PCB的状态”**
- Linux系统原生给PCB状态提供了很多不同的选项
- Windows系统也给状态提供了很多选项
这些都被JVM封装好了,只需要关心JVM提供的几种状态即可
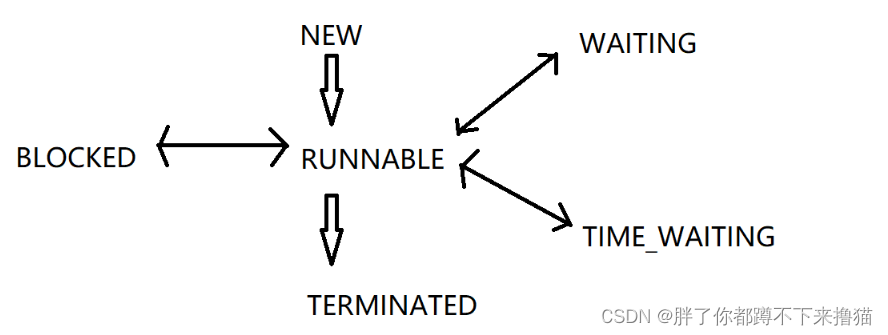
(1)NEW:Thread对象有了,还没调用start系统内部的线程还未创建
(2)TERMINATED:线程已经终止了,内核中的线程已经销毁了,Thread对象还在
package thread;
public class Demo17 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() ->{
System.out.println("hello");
});
System.out.println(t.getState());//NEW
t.start();
t.join();
System.out.println(t.getState());//TERMINATED
}
}
(3)RUNNABLE就绪状态:指的是,这个线程“随叫随到”
- 这个线程正在CPU上执行
- 这个线程虽然没有在CPU上执行,但是随时可以调度到CPU上执行
接下来三种状态都是阻塞
(4)WAITING:死等进入的阻塞,例如t.join();
(5)TIMED_WAITING:带有超时时间的等待,例如t.join(3600 * 1000);
(6)BLOCK:进入锁竞争的时候产生的阻塞
package thread;
public class Demo18 {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() ->{
while (true){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t.start();
t.join();
}
}
后续发现某个线程卡死了,这个时候,就需要关注线程的状态,通过状态就能看到线程是在哪一行代码卡住了(阻塞),原因大概是什么
4.线程安全问题
线程是随即调度的抢占式执行,这样的随机性,就会使程序的执行顺序,产生变数/不同的结果,但是有的时候,遇到不同的结果,认为是不可接受的,认为是bug,多线程代码,引起了bug这样的问题就是“线程安全问题”,存在线程安全问题的代码,就称为“线程不安全”
package thread;
public class Demo19 {
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() ->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
Thread t2 = new Thread(() ->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("count = " + count);
}
}
上述代码是典型的多线程并发导致的问题,如果让两个线程串行执行,没有任何问题
原因在于
对于count++;,这一行代码,实际上是3个CPU指令
- 把内存count中的数值,读取到CPU寄存器中 = > load
- 把寄存器中的值+1,保存在寄存器中 = > add
- 把寄存器上述计算后的值,写回到内存count里 = > save
举个例子
如果时间轴执行顺序:t1_load -> t2_load -> t1_add -> t2_ add -> t1_save -> t2_save
1)t1_load:读取到count值为0
2)t2_load:读取到count值为0
3)t1_add:寄存器中的值+1
4)t2_ add:寄存器中的值+1
5)t1_save:写回内存count中,count值为1
6)t2_save:写回内存count中,count值为1
最终结果count = 1,后一次计算把前一次计算的结果覆盖掉了,由于当前线程执行的顺序不确定,有些执行顺序加两次,结果是正确的,有些执行顺序加两次,最后只增加1,具体有多少次正确,多少次不正确,是随机的,因此最后的计算结果并不准确