stream流式计算
在Java1.8之前还没有stream流式算法的时候,我们要是在一个放有多个User对象的list集合中,将每个User对象的主键ID取出,组合成一个新的集合,首先想到的肯定是遍历,如下:
List<Long> userIdList = new ArrayList<>();
for (User user: list) {
userIdList.add(user.id);
}
或者在1.8有了lambda表达式以后,我们会这样写:
List<Long> userIdList = new ArrayList<>();
list.forEach(user -> list.add(user.id));
List<Integer> userIdList = new ArrayList<>(Arrays.asList(0,1,2,3));
userIdList.forEach(item -> {
//也可以做一些业务逻辑
if(item.equals(1)){
System.out.println("nihao");
}
});
在有了stream之后,我们还可以这样写:
List<Long> userIdList = list.stream().map(User::getId).collect(Collectors.toList());
一行代码直接搞定,是不是很方便呢。那么接下来。我们就一起看一下stream这个流式算法的新特性吧。
由上面的例子可以看出,java8的流式处理极大的简化了对于集合的操作,实际上不光是集合,包括数组、文件等,只要是可以转换成流,我们都可以借助流式处理,类似于我们写SQL语句一样对其进行操作。java8通过内部迭代来实现对流的处理,一个流式处理可以分为三个部分:转换成流、中间操作、终端操作。如下图:

以集合为例,一个流式处理的操作我们首先需要调用stream()函数将其转换成流,然后再调用相应的中间操作达到我们需要对集合进行的操作,比如筛选、转换等,最后通过终端操作对前面的结果进行封装,返回我们需要的形式。
public class Demo {
public static void main(String[] args) {
User u1 = new User(1,"a",21);
User u2 = new User(2,"b",22);
User u3 = new User(3,"c",23);
User u4 = new User(4,"d",24);
User u5 = new User(5,"e",25);
User u6 = new User(6,"f",26);
//集合用来存储数据
List<User> users = Arrays.asList(u1, u2, u3, u4, u5,u6);
//stream流用来计算
lambda表达式 链式编程 函数式接口 stream流式计算全都用到了
users.stream()
.filter(u->{return u.getId()%2==0;}) //ID必须是偶数
.filter(u->{return u.getAge()>23;}) //年龄大于23岁
.map(u->{return u.getName().toUpperCase();}) //用户名首字母大写
.sorted((uu1,uu2)->{return uu2.compareTo(uu1);}) //用户名字母倒着排序
.limit(1) //只输出一个用户
.forEach(System.out::println);
}
}
class User{
int id;
String name;
int age;
public User(){}
public User(int id,String name,int age){
this.id=id;
this.name=name;
this.age=age;
}
public int getId() {
return id;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "user = " + "{" + id +","+ name +"," + age + "}";
}
}下面讲对Stream进行详解
一、什么是stream
Java 8 是一个非常成功的版本,这个版本新增的Stream,配合同版本出现的Lambda ,给我们操作集合(Collection)提供了极大的便利。stream流实际上就是一个高级迭代器,可以对集合执行非常复杂的查找/筛选/过滤、排序、聚合和映射数据等操作。
Java8 Stream 使用的是函数式编程模式,所以大部分流操作都支持 lambda 表达式作为参数,正确理解,应该说是接受一个函数式接口的实现作为参数。例如:
filter(s -> s.startsWith("c"));
以上面代码为例,可以对流进行中间操作或者终端操作
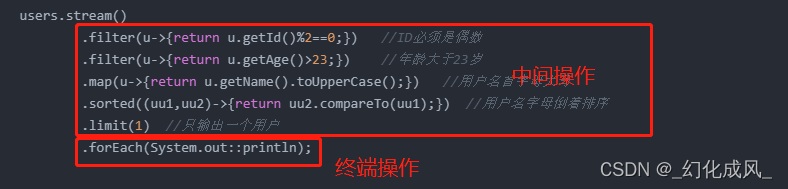
- 中间操作:会再次返回一个流,所以,我们可以链接多个中间操作,注意这里是不用加分号的。上图中的filter 过滤,map 对象转换,sorted 排序等就属于中间操作。
- 终端操作是对流操作的一个结束动作,一般返回 void 或者一个非流的结果。上图中的 forEach循环 就是一个终止操作。
Stream流有一些特性:
- Stream流不是一种数据结构,不保存数据,它只是在原数据集上定义了一组操作。
- 这些操作是惰性的,即每当访问到流中的一个元素,才会在此元素上执行这一系列操作。
- Stream不保存数据,故每个Stream流只能使用一次
二、不同类型的stream流
可以从各种数据源中创建 Stream 流,其中以 Collection 集合最为常见。如 List 和 Set 均支持 stream() 方法来创建顺序流(又称为串行流)或者是并行流。
先介绍串行流:
Arrays.asList("a1", "a2", "a3") //asList源码就是一个ArrayList集合
.stream() // 创建流
.findFirst() // 找到第一个元素
.ifPresent(System.out::println); // 如果存在,即输出
在集合上调用stream()方法会返回一个普通的 Stream 流。但是, 大可不必刻意地创建一个集合,再通过集合来获取 Stream 流,这种方式效率远远比上方的写法高,如下:
Stream.of("a1", "a2", "a3")
.findFirst()
.ifPresent(System.out::println);
可以通过 Stream.of() 从一堆对象中创建 Stream 流,除了常规对象流之外,Java 8还附带了一些特殊类型的流,用于处理原始数据类型int,long以及double,它们就是IntStream,LongStream还有DoubleStream。其中,IntStreams.range()方法还可以被用来取代常规的 for 循环,
IntStream.range(1, 4) // 相当于 for (int i = 1; i < 4; i++) {}
.mapToObj(i -> + i*i)
.forEach(System.out::println);
将常规对象流转换为原始类型流,这个时候,中间操作 mapToInt(),mapToLong() 以及mapToDouble,
Stream.of("3", "2", "5")
.mapToInt(Integer::parseInt) // 转成 int 基础类型类型流
.forEach(System.out::println);
System.out.println("==============");
Stream.of(1.0, 2.0, 3.0)
.mapToInt(Double::intValue) // double 类型转 int
.forEach(System.out::println); // for 循环打印
将原始类型流装换成对象流,可以使用 mapToObj(),
IntStream.range(1, 4)
.mapToObj(i -> "a" + i) // for 循环 1->4, 拼接前缀 a
.forEach(System.out::println);
三、Stream 流的处理顺序
中间操作的有个重要特性 —— 延迟性
java的Stream以延迟性著称。他们被刻意设计成这样,即延迟操作,有其独特的原因:Stream就像一个黑盒,它接收请求生成结果。当我们向一个Stream发起一系列的操作请求时,这些请求只是被一一保存起来。只有当我们向Stream发起一个终端操作是,才会实际地进行计算。
举个例子:
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return true;
});
上面这个代码没有终端操作,根本不会执行任何代码,不会有任何输出,于是添加 一行forEach终端操作如下就可以输出了
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return true;
})
.forEach(s -> System.out.println("forEach: " + s));
输出内容如下,filter和forEach的内容都能正常输出:
filter: d2
forEach: d2
filter: a2
forEach: a2
filter: b1
forEach: b1
filter: b3
forEach: b3
filter: c
forEach: c
这里很有趣,输出的结果却是随着链条垂直移动的,当 Stream 开始处理 d2 元素时,它实际上会在执行完 filter 操作后,再紧接着执行 forEach 操作,接着才会处理第二个元素。
注意有个方法是水平执行的,例如sorted,题外话:平常开发中对于这些中间操作方法的位置顺序也要注意下,正确放置也能大大提高性能,就像sql语句一样,where条件放置顺序也会影响查询速度。
为什么要设计成这样呢?
原因是出于性能的考虑。这样设计可以减少对每个元素的实际操作数,举个更清楚的例子,
Stream.of("d2", "a2", "b1", "b3", "c")
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase(); // 转大写
})
.anyMatch(s -> {
System.out.println("anyMatch: " + s);
return s.startsWith("A"); // 过滤出以 A 为前缀的元素
});
/*
map: d2
anyMatch: D2
map: a2
anyMatch: A2
*/方法依旧是先执行map,再anyMatch,终端操作 anyMatch()表示任何一个元素以 A 为前缀,返回为 true,就停止循环。从 d2 开始匹配,接着循环到 a2 的时候,返回为 true ,于是停止循环。所以这里只输出了4次,如果是水平移动呢,需要把map全部执行,5次,再执行anyMatch方法2次,一共7次,所以很明显减少了不必要的操作次数。
四、数据流复用问题
Stream 流是不能被复用的,一旦你调用任何终端操作,流就会关闭,再调用 noneMatch 就会抛出异常。
Stream<String> stream =
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> s.startsWith("a"));
stream.anyMatch(s -> true); // ok
stream.noneMatch(s -> true); // exception当我们对 stream 调用了 anyMatch 终端操作以后,流即关闭了,再调用 noneMatch 就会抛出异常:
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:229)
at java.util.stream.ReferencePipeline.noneMatch(ReferencePipeline.java:459)
at test.Demo.main(Demo.java:13)
所以可以通过 Supplier 来包装一下流,通过 get() 方法来构建一个新的 Stream 流,通过构造一个新的流,来避开流不能被复用的限制,如下所示:
Supplier<Stream<String>> streamSupplier =
() -> Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> s.startsWith("a"));
streamSupplier.get().anyMatch(s -> true); // ok
streamSupplier.get().noneMatch(s -> true); // ok五、工作实践
实际工作中,stream经常用到,列举一些实际工作的业务场景:
场景一:计算两个集合的重复数据有多少
long a = sourceMpList.stream().filter(mpList::contains).count();
场景二:获取一个集合中的某个属性
集合:List<TestDTO> testVo,获取其中的某属性值存入一个专门的集合
List<String> sourList = testVo.stream().map(TestDTO::getName).collect(Collectors.toList());
当然,另一种普通写法为:
List<String> sourList = new ArrayList<>();
for (String s : testVo) {
sourList.add(s.toUpperCase());
}
场景三:过滤掉为null的字段值以及去重
集合:List<Integer> commPortList;
List<Integer> portList = commPortList.stream().distinct().filter(Objects::nonNull).collect(Collectors.toList());
场景四:从一个集合中剔除多个其他集合的值
List<String> listAll = Stream.of("value1", "value2", "value3").collect(Collectors.toList());
List<String> list1 = Stream.of("value1").collect(Collectors.toList());
List<String> list2 = Stream.of("value2").collect(Collectors.toList());
//从listAll剔除掉list1与list2的数据,找出未使用的
List<String> list3 = listAll.stream().filter(item -> !list1.contains(item) && !list2.contains(item)).collect(Collectors.toList());
System.out.println(list3); //[value3]场景五: 判断集合会否存在重复以及空值
List<Integer> list1 = new ArrayList<>(Arrays.asList(1,1,2,3,4,5,null));
long list2 = list1.stream().distinct().count(); //6
//判断设备编号会否存在重复以及空值
if(list1.size()>list2 || list1.contains(null) || list1.contains("")){
}场景六:关于boxed用法
首先boxed的源码如下:
@Override
public final Stream<Integer> boxed() {
return mapToObj(Integer::valueOf);
}
@Override
public final Stream<Double> boxed() {
return mapToObj(Double::valueOf);
}boxed的作用就是将int等类型的stream转成了Integer等类型的Stream,
也就是基本类型流转换位对象流,需要使用boxed方法
流库中有直接存储基本类型值的类型IntStream、LongStream和DoubleStream,比如
IntStream是int类型的流。stream<Integer 是Integer类型的流
现在定义一个Integer类型的数据流,用来存IntStream的流,必须使用boxed
IntStream stream = IntStream.of(1,1,2,3,5);
List<Integer> integers = stream.boxed().collect(Collectors.toList());比如double转Double
List<Double> list = Arrays.stream(new double[]{-1.0, -0.5, 0,0.5})
.boxed().collect(Collectors.toList());
场景七:合并两个集合值
List<Integer> list1 = new ArrayList<>(Arrays.asList(1,1,2));
List<Integer> list2 = new ArrayList<>(Arrays.asList(3,4,5,null));
List<Integer> list3 = Stream.of(list1,list2).flatMap(Collection::stream).distinct().collect(Collectors.toList());
System.out.println(list3); //[1, 2, 3, 4, 5, null]
场景八: 如果一个流的集合数据过大,根据需要进行拆分,进而通过循环或者多线程来处理数据
List<Integer> list1 = new ArrayList<>(Arrays.asList(0,1,2,3)); System.out.println(Lists.partition(list1,2)); //[[0, 1], [2, 3]]
场景九: 根据equals过滤出想要的value值或者集合
User user = new User(1,"mac");
List<User> list = new ArrayList<>();
list.add(user);
//根据需要输出想要的value值
Integer value = list.stream().filter(p->p.getName().equals("mac"))
.collect(Collectors.toList()).get(0).getAge();
System.out.println(value); // 1
或者这样写
List<Integer> list = new ArrayList<>(Arrays.asList(1,2)); List<User> userList = new ArrayList<>(); userList.add(new User(1,"mac1")); userList.add(new User(2,"mac2")); userList.add(new User(3,"mac3")); List<User> list1 = userList.stream().filter( user -> Objects.equals(list.get(1),user.getAge())) .collect(Collectors.toList()); System.out.println(list1); // [User(age=2, name=mac2)]
场景十: 声明一个带对象的集合并对该对象的属性进行封装
List<Integer> list = new ArrayList<>(Arrays.asList(1,2));
List<User> userList = list.stream().map(id->{
//对userList属性进行封装
User user = new User();
user.setAge(id);
user.setName("mac");
return user;
}).collect(Collectors.toList());
System.out.println(userList);
//[User(age=1, name=mac), User(age=2, name=mac)]
场景十一: noneMatch、anyMatch、allMatch
anyMatch:判断的条件里,任意一个元素成功,返回true
allMatch:判断条件里的元素,所有的都是,返回true
noneMatch:与allMatch相反,判断条件里的元素,所有的都不是,返回true
List<Integer> list = new ArrayList<>(Arrays.asList(1,2));
System.out.println(list.stream().noneMatch(x->1==x)); //false
Stream<String> stream = Stream.of("aaa", "bbb", "ccc");
// 判断stream中其中任何一个元素中只要有包含b字符串或者l字符串就返回true
boolean isMatch = stream.anyMatch(str -> str.contains("b") || str.contains("l"));
System.out.println(isMatch); // true
场景十二:findFirst,查找集合中符合条件的第一个对象
Optional<A> firstA= AList.stream()
.filter(a -> "小明".equals(a.getUserName()))
.findFirst();
关于Optional,java API中给了解释,一个容器对象,它可能包含也可能不包含非空值。如果存在一个值,isPresent()将返回true;
List<Integer> list = new ArrayList<>(Arrays.asList(1,2));
Optional<Integer> a = list.stream().filter(p->p==1).findFirst();
if (a.isPresent()){ //true
System.out.println("true");
}场景十三:sorted,comparator
java8的lambda表达式排序,理应用comparing,多字段 后面增加thenComparing,默认排序规则为正序
现在有个排序需求:
a-倒序
b-当a相同时,正序
c-当b相同时,倒序List<UserCouponVo> newList = list.stream().sorted(Comparator
.comparing(UserCouponVo::getA,Comparator.reverseOrder())
.thenComparing(UserCouponVo::getB)
.thenComparing(UserCouponVo::getC,Comparator.reverseOrder())
).collect(Collectors.toList());
List<Yue> yueList = new ArrayList<>();
yueList.add(new Yue(4,1));
yueList.add(new Yue(2,2));
yueList.add(new Yue(6,3));
List<Yue> list1 = yueList.stream().sorted(Comparator.comparing(Yue::getA))
.collect(Collectors.toList());
System.out.println(list1);
//[Yue(a=2, b=2), Yue(a=4, b=1), Yue(a=6, b=3)]
List<Yue> list = yueList.stream().sorted(Comparator.comparing(Yue::getA,
Comparator.reverseOrder()))
.collect(Collectors.toList());
System.out.println(list);
//[Yue(a=6, b=3), Yue(a=4, b=1), Yue(a=2, b=2)]如何a值分别为正序246,倒序642
场景十四:Collectors.groupingBy
List<User> userList = new ArrayList<>();
userList.add(new User(1,"mac1"));
userList.add(new User(2,"mac2"));
userList.add(new User(3,"mac3"));
userList.add(new User(3,"mac3"));
System.out.println(userList.stream().collect(Collectors.groupingBy(User::getAge)));
//{
// 1=[User(age=1, name=mac1)],
// 2=[User(age=2, name=mac2)],
// 3=[User(age=3, name=mac3), User(age=3, name=mac3)]
// }
场景十五: 批量修改某个集合的属性
List<User> userList = new ArrayList<>();
userList.add(new User(1,"mac1"));
userList.add(new User(2,"mac2"));
userList.stream().map(p->{p.setAge(2+p.getAge());return p;}).collect(Collectors.toList());
System.out.println(userList);
//[User(age=3, name=mac1), User(age=4, name=mac2)]