之前是做的yolov3手势物体识别,最近几天我将该项目进行了重新的整理和升级,实现了yolov5手势物体识别,同时为了方便更多的人直接拿来应用,我生成了支持windows系统的应用小程序,即便你电脑上没有安装pytorch,没有安装cuda、python,都可以使用~!
相关资料:
应用程序效果如下:
yolov5手势物体识别
环境说明
torch 1.7.0
tensorboard 1.15.0
protobuf 3.20.0
Pillow 9.5.0
opencv-python 4.4.0.44
技术说明
本项目使用了三个算法模型进行的功能实现。yolov5做手部目标检测,ReXNet(支持Resnet系列)做手部21关键点回归检测,Resnet50做物体分类识别。(其实就是三个算法做的级联)
yolov5手部目标检测
使用yolov5s进行训练,数据集共有3W+,因本地训练环境受限,我只训练到mAP 64%左右,因此准确率并不是很高,大家有需要的可以自行再去训练~
数据集说明
数据集链接:
(ps:这里的数据集采用的公共数据集,没有做过数据清洗)
链接:https://pan.baidu.com/s/1jnXH3yBuGJ8_DRXu-gKtNg
提取码:yypn
数据集格式:
images:存放所有的数据集
labels:已经归一化后的label信息
train.txt:训练集划分,25934张
val.txt:验证集划分,3241张
test.txt:测试集划分,3242张图
训练实验记录
采用马赛克数据增强,如下图:
 |
 |
评价指标:
(我这里只训练了大该十多个epoch,没服务器训练太慢了~(T^T)~,所以准确率比较低,有需要的可以自己训练一下)
(训练好的权重见文末项目链接)
| P | R | mAP 0.5 | mAP 0.5:0.95 |
| 0.75396 | 0.59075 | 0.64671 | 0.27652 |
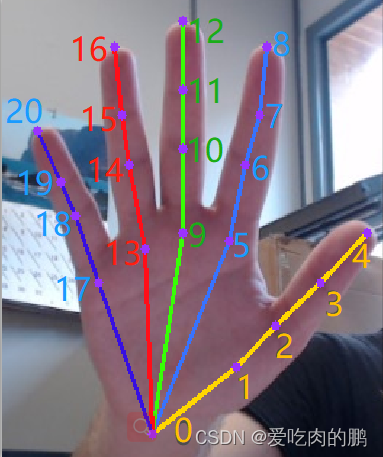
手部21关键点检测
手部关键点识别采用的网络为ReXNet(支持Resnet系列),这里需要说明的是关键点预测并没有采用openpose网络!而是采用的坐标回归方法,这个问题需要强调一下,不然总有小伙伴问我,而且还很质疑~ 在本任务中,由于有yolo作为前置滤波器算法将手部和背景进行分离,分离后的图像前景和背景相对平衡,而且前景(手部)占主要部分,因此任务其实相对简单,可以采用坐标回归方法。
网络的定义在yolov5_hand_pose/components/hand_keypoints/models/。
21个关键点,那就是有42个坐标(x,y坐标)。因此代码中num_classes=42,代码:
class handpose_x_model(object):
def __init__(self,
model_path = '',
img_size= 256,
num_classes = 42,# 手部关键点个数 * 2 : 21*2
model_arch = "rexnetv1"
):再看下网络最终的输出:
这里输出的通道数为num_classes!所以和openpose是有一定区别的!这里必须要说明一下,不然老有人不信哈哈~
features.append(nn.AdaptiveAvgPool2d(1))
self.features = nn.Sequential(*features)
self.output = nn.Sequential(
nn.Dropout(dropout_factor),
nn.Conv2d(pen_channels, num_classes, 1, bias=True))
def forward(self, x):
x = self.features(x)
x = self.output(x).squeeze()
return x言归正传,21关键点识别效果如下,首先是通过yolov5提取手部box信息,再把手分离出来,将手部图像resize为256x256大小,用关键点网络进行关键点回归。
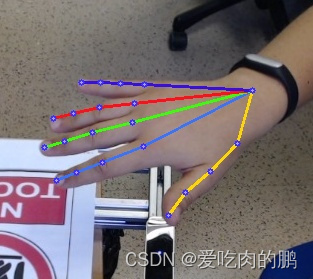
数据集说明
(ps:这里的数据集采用的公共数据集,没有做过数据清洗)
数据集链接:
链接:https://pan.baidu.com/s/129aFPmhHq3lWmAFkuBI3BA
提取码:yypn
整个数据集共有49062张图像。标注可视化:
训练
训练代码在train.py中。
(训练好的权重见文末项目链接)
可采用提供的预权重进行fine tune训练。
输入以下命令开始训练:
python train.py --model resnet_50 --train_path [数据集路径] --fintune_model 【fine tune模型路径】--batch_size 16如果是fine tune训练,建议初始学习率(init_lr)设置为5e-4,否则建议设置为1e-3。
损失函数此次采用的是MSE,还可支持wing loss。
训练好的权重会保存在model_exp中,对应的tensorboard会存储在logs中,tensorboard图:
 |
 |
分类网络
这里的分类网络采用是resnet50网络,权重为ImageNet数据集上的(1000个类),可以根据自己任务需求去训练。(权重见文末项目链接)
网络定义在yolov5_hand_pose/components/classify_imagenet/models。
那具体是如何分类的呢?
首先触发分类模型的手势是食指和大拇指捏合。主要是计算两个关键点的欧式距离,当距离小于阈值则为触发状态click_state=True:
# 计算食指大拇指的距离
dst = np.sqrt(np.square(thumb_[0]-index_[0]) +np.square(thumb_[1]-index_[1]))
# 计算大拇指和手指相对手掌根部的角度:
angle_ = vector_2d_angle((thumb_[0]-hand_root_[0],thumb_[1]-hand_root_[1]),(index_[0]-hand_root_[0],index_[1]-hand_root_[1]))
# 判断手的点击click状态,即大拇指和食指是否捏合
click_state = False
if dst<dst_thr and angle_<angle_thr: # 食指和大拇指的坐标欧氏距离,以及相对手掌根部的相对角度,两个约束关系判断是否点击
click_state = True那么又有个问题了,总不能我两个手指一捏合就触发,这带来了很大的误触,这里解决的方法是判断触发状态(可以理解为时间长短)。代码如下:
'''
判断各手的click状态是否稳定(点击稳定充电环),即click是否持续一定阈值
注意:charge_cycle_step 充电步长越大,触发时间越短
'''
def judge_click_stabel(img,handpose_list,charge_cycle_step = 32):
flag_click_stable = True
for i in range(len(handpose_list)):
_,_,_,dict_ = handpose_list[i]
id_ = dict_["id"]
click_cnt_ = dict_["click_cnt"]
pt_ = dict_["choose_pt"]
if click_cnt_ > 0:
# print("double_en_pts --->>> id : {}, click_cnt : <{}> , pt : {}".format(id_,click_cnt_,pt_))
# 绘制稳定充电环
# 充电环时间控制
charge_cycle_step = charge_cycle_step # 充电步长越大,触发时间越短
fill_cnt = int(click_cnt_*charge_cycle_step)
if fill_cnt < 360:
cv2.ellipse(img,pt_,(16,16),0,0,fill_cnt,(255,255,0),2)
else:
cv2.ellipse(img,pt_,(16,16),0,0,fill_cnt,(0,150,255),4)
# 充电环未充满,置为 False
if fill_cnt<360:
flag_click_stable = False
else:
flag_click_stable = False
return flag_click_stable当两个手都触发捏合动作,那么判断是有效动作,同时将左右手选定的区域截出来(和yolo的操作类似),送入分类网络进行分类识别。
语音播报
当手势动作触发成功后会触发语音播报函数,此时会自动语音播放"正在识别物体请等待",如果成功识别,并且也有该物体的语音包(需要自己录制),那么会说“您识别的物体为。。。”
如果需要自己录制语音(mp3格式),可以将录制好的语音放在materials/audio/imagenet_2012/
语音播报函数:
'''
启动识别语音进程 该项目中主要用到下面的自定义函数
'''
def audio_process_recognize_up_edge(info_dict):
while (info_dict["handpose_procss_ready"] == False): # 等待 模型加载
time.sleep(2)
gesture_names = ["double_en_pts"] # 姿态列表,
gesture_dict = {}
for k_ in gesture_names:#k_= double_en_pts
gesture_dict[k_] = None #gesture_dict[double_en_pts]=None
while True:
time.sleep(0.01)
# print(" --->>> audio_process")
try:
for g_ in gesture_names: # 输出 double_en_pts ,因为gesture_name列表内容为str,所以g_也是str,输出的g_=double_en_pts
if gesture_dict[g_] is None: # gesture_dict[double_en_pts] 为真
gesture_dict[g_] = info_dict[g_] #info_dict[g_]为False
else:
if ("double_en_pts"==g_):
if (info_dict[g_]^gesture_dict[g_]) and info_dict[g_]==True:# 判断Click手势信号为上升沿,Click动作开始
playsound("./materials/audio/sentences/IdentifyingObjectsWait.mp3")
playsound("./materials/audio/sentences/ObjectMayBeIdentified.mp3")
if info_dict["reco_msg"] is not None:
print("process - (audio_process_recognize_up_edge) reco_msg : {} ".format(info_dict["reco_msg"]))
doc_name = info_dict["reco_msg"]["label_msg"]["doc_name"]
reco_audio_file = "./materials/audio/imagenet_2012/{}.mp3".format(doc_name)
if os.access(reco_audio_file,os.F_OK):# 判断语音文件是否存在
playsound(reco_audio_file)
info_dict["reco_msg"] = None
gesture_dict[g_] = info_dict[g_]
except Exception as inst:
print(type(inst),inst) # exception instance
if info_dict["break"] == True:
break整个项目,也就是三个算法、语音播报等是采用多进程显现的,四个功能之间的通信是利用的共享字典进行的数据共享。
多进程代码如下:
其中handpose_x_process是手势物体识别进程(三个算法的调度),audio_process_recognize_up_edge是语音识别进程。
g_info_dict是共享字典,用来做两个进程之间的数据通信与数据共享。
#-------------------------------------------------- 初始化各进程
process_list = []
t = Process(target=handpose_x_process, args=(g_info_dict, cfg,))
process_list.append(t)
t = Process(target=audio_process_recognize_up_edge,args=(g_info_dict,)) # 上升沿播放
process_list.append(t)
for i in range(len(process_list)):
process_list[i].start()
for i in range(len(process_list)):
process_list[i].join()# 设置主线程等待子线程结束
del process_list如何使用本项目
使用方法很简单,clone本项目到本地后,只需要运行predict.py并搭配参数即可。
(提前下载好权重~)
你可能会用到如下参数:
--hand_weight 【yolov5权重路径】,默认为best.pt
--handpose_model_path 【关键点权重】,默认components/hand_keypoints/weights/ReXNetV1-size-256-wingloss102-0.122.pth
--handpose_name 【关键点模型】,默认rexnetv1
--classify_model_path 【分类网络权重】,默认components/classify_imagenet/weights/imagenet_size-256_20210409.pth
--classify_model_name 【分类网络模型名称】,默认resnet_50
--conf 【yolo置信度阈值】,默认0.5
--video_path 【视频路径】,默认本机摄像头
--device 【推理设备】,默认GPU
例如:
python predict.py --conf 0.3 --video_path 0 --hand_weight best.pt --device cuda手势物体识别应用程序
为了可以让更多的进行使用,花费了两天的时间导出了exe应用程序,即便你的电脑没有安装pytorch和cuda都可以直接运行(暂时只支持windows系统,linux应该是需要wine来帮助运行)。
ps:博主只是在一些电脑上进行了测试还是可以成功运行的~
应用程序链接:
链接:https://pan.baidu.com/s/1wPpg2v4h2Zlkr5SgzCGgVw
提取码:yypn
运行方式:
1.直接双击predict.exe可直接运行程序
2.在cmd运行predict.exe可直接运行程序,推荐这种方式,因为可以搭配命令使用,同时有报错可以看到。
可搭配的命令如下:
--hand_weight 【yolov5权重路径】,默认为best.pt
--handpose_model_path 【关键点权重】,默认components/hand_keypoints/weights/ReXNetV1-size-256-wingloss102-0.122.pth
--handpose_name 【关键点模型】,默认rexnetv1
--classify_model_path 【分类网络权重】,默认components/classify_imagenet/weights/imagenet_size-256_20210409.pth
--classify_model_name 【分类网络模型名称】,默认resnet_50
--conf 【yolo置信度阈值】,默认0.5
--video_path 【视频路径】,默认本机摄像头
--device 【推理设备】,默认GPU输入命令样例:
predict.exe --conf 0.3 --video 0如果想自己尝试导出exe,那可以继续往下看~
这里使用pyinstaller工具进行导出,版本为:
pyinstaller 4.10
方法很简单,直接输入命令(在torch环境下输入):
pyinstaller predict.py但是我在导出exe的遇到了很多问题,报错和对应解决方式如下:
问题1:
报错:error中出现torch._C
解决方法:
在导出exe的命令的时候,显示导入
导出exe:pyinstaller --onefile --hidden-import torch._C --hidden-import torch.nn.functional predict.py问题2:
File "torch\jit\frontend.py", line 197, in get_jit_def
File "torch\_utils_internal.py", line 56, in get_source_lines_and_file
OSError: Can't get source for <function swish_fwd at 0x0000020D1E6093A8>. TorchScript requires source access in order to carry out compilation, make sure original .py files are available.
[13456] Failed to execute script 'predict' due to unhandled exception!
解决办法:
看了一下报错是torchscript的问题,又找到了源码的swish_fwd函数,修改如下:
显示导入import torch.jit发现不起作用
于是找到swish函数,函数上面有@torch.jit.script的修饰器。
注释掉该函数后,重新写一个swish函数即可。
def swish(x, inplace=False):
return x.mul_(x.sigmoid()) if inplace else x.mul(x.sigmoid())问题3:
File "torch\serialization.py", line 853, in _load
result = unpickler.load()
ModuleNotFoundError: No module named 'models'解决办法:
这是由于yolov5 torch.save导致的问题。
而这通常是修改了文件目录,没有将models文件作为二级目录导致的。解决方法有两种:
1.使用torch.save(model.state_dict())保存模型,并且修改模型加载代码
2.将models作为二级目录。(这里采用的该方法)
问题4:
因为我项目采用的是多进程,在导出exe并执行的时候出现问题,问题如下:
执行exe的时候报错:yolov5 hand pose: error: unrecognized arguments: --multiprocessing-fork parent_pid=14128 pipe_handle=784
解决办法:
解决方法:
if __name__ == '__main__':
multiprocessing.freeze_support()
# args = parse.parse_args()
args, unparsed = parse.parse_known_args()项目链接
项目代码:
权重链接:
链接:https://pan.baidu.com/s/1WS3Nb5MkqMGhCKjM7DYsgg
提取码:yypn
云盘中有三个权重:
best.pt是yolov5训练的权重
ReXNetV1-size-256-wingloss102-0.122.pth是21关键点权重
imagenet_size-256_20210409.pth是分类网络权重