一、为什么需要使用动态IP代理
1.网站反爬虫机制
现在很多网站都有反爬虫机制,一旦发现某个IP地址频繁访问某个网站,该IP地址就会被网站封掉。这样就会导致我们无法正常访问该网站,从而无法进行数据爬取。
2.突破本地IP限制
如果我们只使用本地IP地址进行爬取,可能会受到本地IP地址的限制。比如,我们在国内使用本地IP地址爬取国外的网站,可能会受到国外网站的限制。
3.获取更多数据
使用动态IP代理可以获取更多的数据,因为每个IP地址都会有不同的数据,这样可以避免数据重复。
二、Python爬虫动态IP代理的实现方法
Python爬虫动态IP代理的实现方法有很多,这里我们介绍两种常见的方法:
1.使用第三方库
Python中有很多第三方库可以实现动态IP代理,其中比较常用的有requests和urllib库。这里我们以requests库为例进行介绍。
使用requests库时,需要安装requests和bs4两个库,可以使用pip进行安装,命令如下:

安装完成后,我们可以使用如下代码来实现动态IP代理:
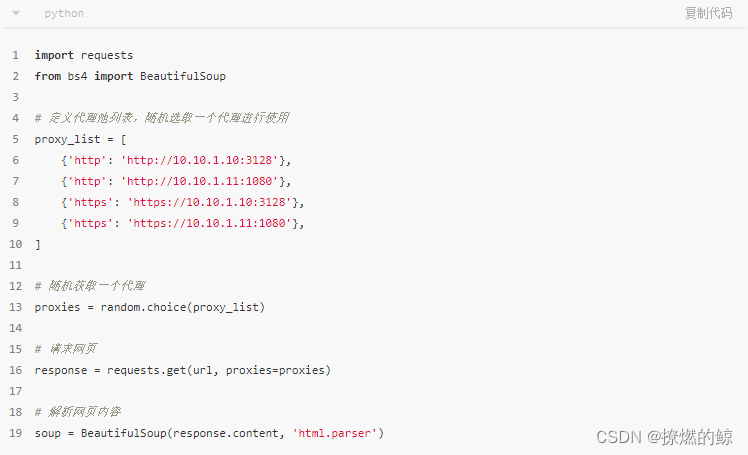
以上代码中,我们定义了一个代理池列表,其中包含多个代理。每次请求网页时,会随机选取一个代理进行使用,这样就可以避免被网站封掉IP地址。
2.使用爬虫框架
除了使用第三方库,我们还可以使用爬虫框架来实现动态IP代理。爬虫框架中已经内置了动态IP代理的功能,比如Scrapy框架。
在Scrapy框架中,使用动态IP代理时,需要在settings.py中添加如下代码:

在middlewares.py文件中定义ProxyMiddleware中间件,代码如下:
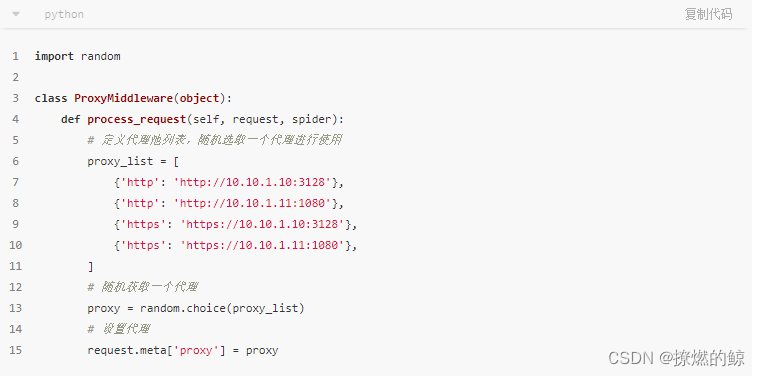
以上代码中,我们在middlewares.py文件中定义了ProxyMiddleware中间件,每次请求时会从代理池列表中随机选择一个代理,来进行IP代理操作。
三、预防被封的方法
使用动态IP代理可以有效地避免被封,在实际操作中,还需要注意以下几点:
1.代理池管理
代理池管理非常重要,我们需要及时更换代理池中的代理,以免被网站发现并封掉IP地址。我们可以使用一些第三方库来管理代理池,比如redis、mongo等。
2.请求间隔设置
在进行网站爬取时,不宜过于频繁地访问同一个网站,否则可能会被认为是恶意爬取,从而被网站封掉IP地址。我们可以设置一个请求间隔的时间,比如每隔1秒钟发送一个请求。
3.使用多个代理
为了提高爬取数据的效率,我们可以使用多个代理,从而进行多线程爬取。这就需要我们对代理池进行充分的管理,避免重复访问同一个代理。
四、总结
本文介绍了Python爬虫动态IP代理防止被封的方法,主要包括使用第三方库和爬虫框架两种实现方式,同时还介绍了预防被封的方法。
在实际操作中,我们需要对代理池进行管理,设置请求间隔时间,使用多个代理等,以确保能够顺利地完成网站爬取任务。