数据库中的引擎
常用的引擎有InnoDB、MyIsam、Memory三种。
MyIsam:组织形式分为三种:
frm文件存储表结构、MyData文件存储表中的数据、MyIndex文件存储表的索引数据。是分开存储的。
Memory:基于内存的,访问速度快,但是后面可能用的都是Redis。
重点来说说InnoDB存储引擎吧:
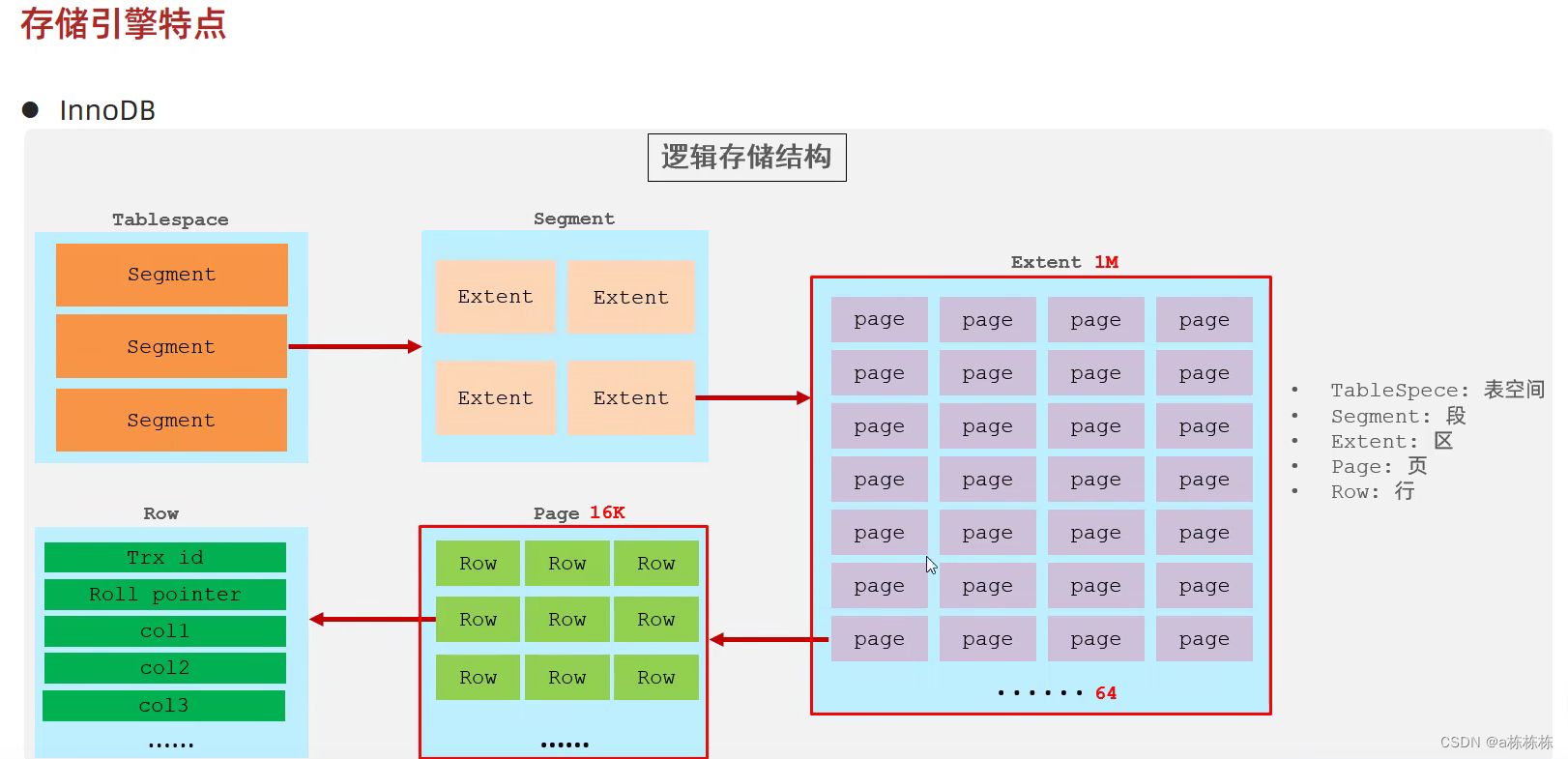
MySQL默认的存储引擎,DML操作支持事务。一个ibd文件对应一张表嘛。它在一个TableSpace的表空间这样一个逻辑结构中,按大小分为段、区、页这样的。一个段有四个区,一个区有连续64隔数据页,这个数据页就是InnoDB下最基本的数据单位嘛,然后数据页的大小是16K,数据页里面才是你存的这种行记录,它都是往数据页里面放的。
InnoDB有三个特点嘛:支持外键、还有事务、还有行级锁,这是它的几个特点。
它也是一个组织索引表,这一块就跟索引挂钩了嘛,它每个节点就是一个数据页。然后根据组织形式又能分为聚集索引和二级索引嘛,根据不同的这种索引,字段进行组织,排放。
它不仅存放表结构、数据。还会存放该表对应的索引信息。
索引
一种用于提高数据库查询性能的有序的数据结构。通过它呢,数据库引擎可以快速定位到存储表中的特定数据,而不必逐行遍历整个表。
聚集索引和二级索引
在InnoDB存储引擎中,根据索引的存储形式,分为聚集索引(指针)和二级索引(二级指针)
索引结构中,叶子结点存放的是整行的行数据。必须有,且只有一个。
索引结构中,叶子结点存放的是对应的主键。可以有多个。除了聚集索引以外的索引都是二级索引
B+树和B树的结点:
B+树非叶子节点只存储key,不存储值,直到叶子节点才存储值,非叶子节点主要起到索引作用,叶子节点包含了所有插入的元素。
B树每个结点即存值又存key,我们知道,一个数据页大小是16K固定的嘛,如果又存节点又存Key,就会导致每个节点存储的key的个数少,进而导致树的层数很深。这也是不用B树去存储索引的原因。
不用Hash存储索引的原因:
不用Hash,因为我们数据库查询经常会涉及到范围查询嘛,而Hash索引只能做到精确查找,不能进行范围查找,同时Hash不能对数据进行排序操作。
聚集索引选取规则
如果存在主键,主键就是聚集索引。
如果没有设置主键,默认第一个唯一索引就是聚集索引。
如果又没有主键,又没有唯一索引,那么InnoDB会自动生成一个rowid作为隐藏的聚集索引。
对于叶子节点:聚集索引存放的是一行的全部信息,而二级索引存放的是主键值,通常会涉及到回表查询嘛。(然后通过主键值,再回表)
回表查询
先介绍一下聚集索引和二级索引的区别;
就是我们查询条件一般是通过二级索引,这样拿到了主键值,再拿到该主键值,再进行一次回表查询。
覆盖索引
查询使用了索引,同时返回的列,不需要回表查询,即一次查询就能全部找到了。如select id,name from a where name = jack ,这里id是主键值,name是二级索引,通过二级索引查到了id,也就是主键值,不需要回表查询,所以叫做覆盖索引。因此尽量不要使用select *,因为这样往往会做到回表查询,影响查询性能。
索引失效的场景
用到复合(联合)索引的时候,违反最左前缀法则
【查询的时候必须从索引的最左列开始,如果跳过了中间某一列,则跳过之后的索引都失效】
当查询条件有范围查询的时候,其右边的条件,如where id > 1 and xxx 【and后面的索引都会失效】
在索引列上进行运算操作
以%开头的模糊查询
隐式类型转换(如表中数据是字符串类型,而你给他一个int类型,即不加单引号,索引会失效)
索引设计原则
①数据量大,且查询比较频繁的表建立索引,如果一个表全是增删改的操作,就没必要加索引了
②常作为查询条件where、order by、group by操作的字段建立索引,如果一次查询条件的字段为多个,也可以考虑设置联合索引,但记住它们的顺序不能改变,要遵守最左配对原则
③选择区分度高的列作为索引,像性别男女就没必要。
④如果是字符串类型的字段,且长度较长,可以针对字段的特点,建立前缀索引。
⑤尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,避免回表,提高查询效率。
⑥控制索引的数量,索引越多,维护索引结构的代价也越大,会影响增删改的效率
事务
对于单独的DQL(数据查询语句)我们一般不会说去考虑事务,如果是设计到DDL、DML比如insert、update、delete,为了保证操作的原子性,即同时成功或同时失败。因为事务是一个不可分割的单元嘛,并且如果有的成功执行,有的没成功,那就会造成很大的问题,也因此引入了事务的机制。
四大特性:
原子性:保证一个事务中的多条操作语句,要不同时成功,要不同时失败。不会处于中间状态。
一致性:事务执行的结果是使数据库从一个状态变到另一个一致性状态。
隔离性:涉及到不同的隔离机制,数据库中有四种隔离机制,读未提交、读已提交、可重复读、串行化。使得每个事务都独立执行嘛。
持久性:因为数据最终是要落盘的,持久化保存数据嘛。