文章目录
隐私、安全和伦理相关
从部署拓扑结构而言,知识图谱技术以数据为核心、数据库为载体的方式来存储,有单机、云平台、集群及其组合的部署方式,结合大数据平台、云平台、业务系统、灾备、网络系统及其与知识图谱之间的通信接口。知识图谱的安全问题,是为了保护其数据内容、存储载体、能够访问知识图谱的系统、平台、网络及之间的接口安全。
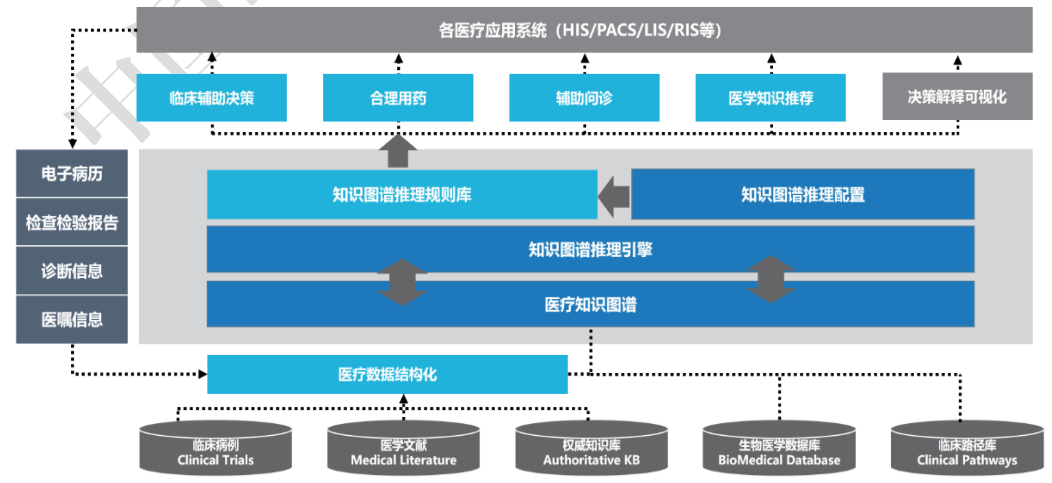
内部业务人员、外部合作伙伴、第三方合作业务系统通过利用相应的系统权限违规窃取/滥用数据。一般来说,内部业务人员拥有比外部、第三方更高的系统访问权限,内部人员对数据的访问和使用虽然经过了账号授权,但没有对其访问和传输内容进行审查容易造成数据流失和敏感信息泄露的问题。外部合作伙伴虽然拥有较低的系统权限,但是通过漏洞或钓鱼进行渗透网络和系统渗透、数据库注入、账号提权、病毒植入等方式也可以访问到数据库中的核心信息,从而产生数据丢失、窃取甚至拖库等风险。第三方系统一般通过接口访问知识图谱存储的数据库,在接口本身安全性、三方系统安全性方面无法做到有效管理。其次,敏感应用/接口缺少监控管理手段,容易造成数据泄露和资源占用。对于这类场景,需要从流量中知识图谱相关的协议解析开始,审查各个账号、接口获取的数据内容,防止数据泄露和未授权流量的产生。
根据国家《数据安全管理办法(征求意见稿)》第六条,数据安全的风险评估势在必行。在风险评估之前,必要的一步就是对当前的数据进行梳理,分类分级、打标签,并识别敏感数据。然后,对已识别数据的驻留和流转风险进行评估。梳理数据的一种手段就是资产扫描,通过对数据库、数据内容及相应的大数据平台组件进行扫描,识别其中的敏感组件和数据并分类。其次,还要扫描数据传输路径和驻留节点,对流程可视化之后更便于识别风险。
行为异常一般包含的场景:内部业务人员违规访问内部系统造成数据泄露/滥用事件;运维人员违规访问数据库/服务器,造成数据泄露事件;第三方通过接口违规提取截留敏感数据,造成数据泄露。从安全运营和运维角度来说,希望能够主动发现潜在的风险,但无奈系统节点繁多、流量庞杂、日志种类多数量大。因此,该类场景下需要从用户行为分析和日志审计的角度来切入,以可视化的方式呈现安全隐患。
网络攻击的纵深防御,可以分为事前、事中、事后三个阶段,事前感知与预防,事中拦截并阻断,事后加固和溯源。在进行攻击溯源时,安全或IT部门在遇到数据安全事件时由于攻击手段的多样性经常会缺少有效溯源手段;而各种设备、系统、数据库日志各自独立,无法关联分析,无法定位事件源头;并且对于海量日志的搜索,传统安全产品检索分析性能无法满足需要。因此在溯源取证环节,对日志关联分析、攻击者画像、发现攻击链条等方面,由于知识图谱的数据结构、日志以及系统拓扑有别于传统业务系统,都将对安全系统的构建提出挑战。
知识图谱作为底层的数据服务,为多种应用(如各类搜索引擎、对话系统)和各类接口提供服务或数据。在认证、账号、权限和审计方面均需统一管理,也就是4A安全管理,其中审计管理(Audit)全面记录用户在知识图谱相关系统与接口的登录行为和操作行为。基于图谱的异常行为定义和规则,实现知识内容获取、数据库操作、相关组件使用的有效审计。
知识图谱构建技术中最重要的一个环节就是知识获取,包括实体抽取和关系抽取等,而且最终提供服务的知识图谱也高度依赖于这两个技术要素,这两类技术决定了知识图谱内容质量的好坏。为了保证输出高质量的图谱,并且维持这一质量要求,不仅需要从系统、平台、数据库、网络维度保护模型本身的安全性,防止训练好的模型文件被破坏,而且还需要保证输入数据的安全性,从模型的训练数据到抽取好待入库的知识结构,避免如恶意代码或原有数据、关系的替换,以免篡改行为导致知识图谱的质量下降。
数据时代的安全架构:以数据为中心的审计与保护(Data-Centric Audit and Protection,简称“DCAP”)是由Gartner提出的术语。它强调特定数据本身的安全性,弱化了周边环境的安全考虑。DCAP主要的优点之一是将数据安全应用于待保护的特定数据片段但不影响正常业务,数据保护与企业战略保持一致。而目前的安全系统与建设方案都是全方位的重型防护体系,势必对业务流畅性产生一定影响,其中包括数据的分类发现与安全策略、审计和行为分析与告警、数据的保护等。
测试认证相关
知识图谱相关技术及系统的测试评估作为知识图谱发展中的重要环节,国内外不同机构正在推动该方面的研究工作,其中全国知识图谱与语义计算大会作为中国中文信息学会语言与知识计算专委会定期举办的全国年度学术会议每年发布主题测评任务,促进国内知识图谱领域的技术发展,以及学术成果与产业需求的融合和对接。此外,美国伦斯勒理工学院Tetherless World Constellation研究所围绕知识图谱质量评估正在研制知识图谱测评系统,以检测和评估大规模异构知识图谱中存在的不连续性及潜藏错误标签。目前,该测评系统架构图如图6.1所示,并在一项大规模生物学知识图谱上完成了测试。整体而言,知识图谱的测试认证相关研究仍处于起步阶段,面临以下挑战:
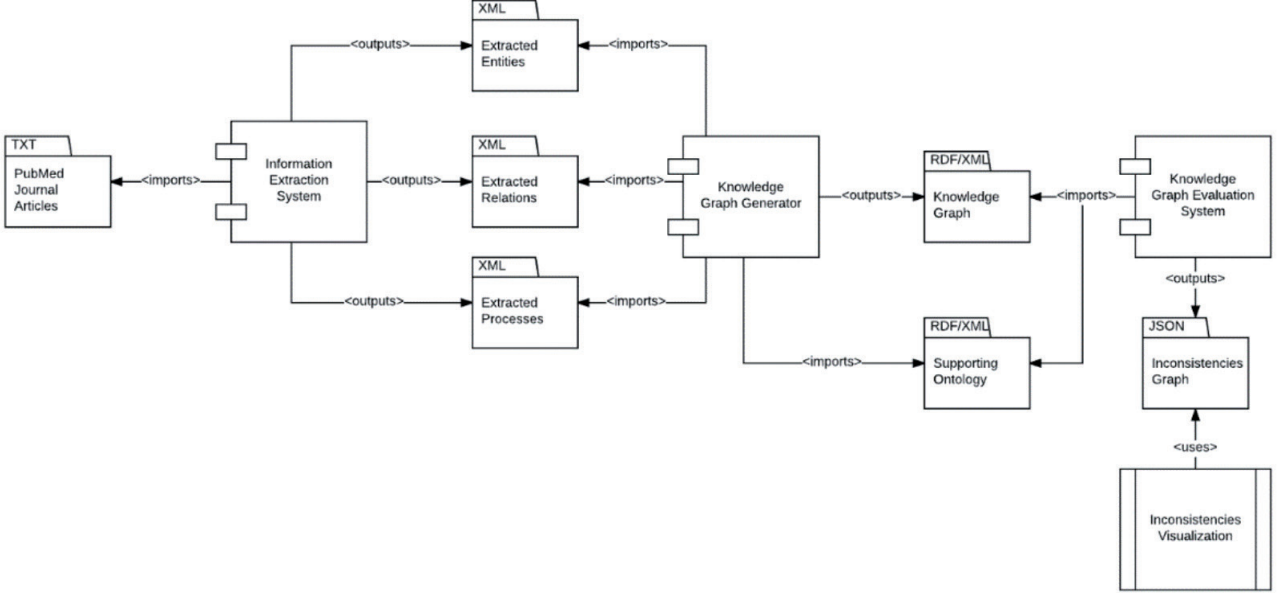
知识图谱测试与评估不仅涉及知识图谱输入数据、整体性能、平台功能等,还涉及知识图谱构建过程中知识获取、知识表示、知识存储、知识融合、知识建模、知识计算等各环节。其中,知识获取与知识融合环节测试评估获得的关注度较高,知识融合环节中的质量评估主要是对知识的可信度进行量化,保留置信度较高的并舍弃置信度较低的,有效确保知识的质量。此外,2019年全国知识图谱与语义计算大会就面向中文短文本的实体链指任务、人物关系抽取、面向金融领域的事件主体抽取、公众公司公告信息抽取等多个方面发布了评测任务。
知识图谱测试与评估方法较少,且集中在知识图谱构建的特定环节或特定问题,尚未形成完整测评体系,无法指导当前各企业及相关用户的使用。美国伦斯勒理工学院发布的研究报告中针对实体类型不匹配、事件类型不匹配、实体事件二元性、上下文约束等知识图谱不一致性测评进行了探讨;德国Philipp Cimiano等专家针对知识图谱优化的现有评估方法从回顾性评估、计算性能等方面进行了总结,但数量有限;针对知识融合中质量评估问题,Mendes等人在LDIF框架基础上提出了一种新的质量评估方法(Sieve方法),支持用户根据自身业务需求灵 活定义质量评估函数,也可以对多种评估方法的结果进行综合考评以确定知识的最终质量评分。
当前知识图谱相关标准较少,且尚无测试与评估标准发布,缺少获得业内一致认可的共性测评指标与方法。德国Philipp Cimiano等专家在文献中对知识图谱相关优化算法性能基于DBpedia、Zhishi.me、Open Cyc等数据库从精度、召回率、准确性、精度与召回率曲线下面积、ROC曲线下面积、均方根误差等指标进行了比较。在全国知识图谱与语义计算大会组织的评测任务中,增加了F1-Measure相关指标,并给出了具体的计算公式。但各项指标是否能够覆盖知识图谱测评需求还有待论证,而且知识图谱构建过程中各环节指标也待明确。
标准测试数据集作为知识图谱测评的重要基础,高质量的测试数据集不仅有利于降低知识图谱相关系统的开发成本,也有利于多知识图谱产品间的横向对比,提升测评结果的公平性。DBpedia、Open Cyc、NELL等国外开源数据库及Zhishi.me、PKU-PIE、THUOCL、CN-DBpedia等国内开源数据库对知识图谱的发展起到了重要支撑作用。此外,TAC-KBP、MUC、全国知识图谱与语义计算大会等发布的测评任务中也会附相应的测评数据集。同时,OpenKG作为中国中文信息学会语言与知识计算专业委员会所倡导的开放知识图谱项目目前也已公布92项开源数据集。但各项数据集多是相关公司或组织独立开发所得,而且并非面向知识图谱测试而开发,有待进一步融合与发展。而且随着知识图谱相关产品在各领域的逐步落地与应用,未来面向特定领域的测试数据集需求将不断提升,如何在现有基础上构建相应领域的标准测试数据集也将是一大挑战。
知识图谱测试人员需要同时掌握良好的知识图谱构建相关知识及软件测试相关能力。对于第三方测试机构而言,在具备相应测试人员基础上,还需要配备良好的测试环境和检测设备、完备的管理机制,而且测试实验室及测试人员需获得检测认证相关资质,才能够确保出具有公信力的检测报告。目前,由于知识图谱测评相关测试床及测试用例匮乏,而且现有测试人员及机构资质和测试环境多针对其他技术领域,其能否完全覆盖知识图谱测试中的特殊需求缺乏验证基础,未来有待进一步加强该方面技术突破及研究。