目录
记住这个网址:https://newspace.ai0.cn
注册一个账号,用qq邮箱,然后登录
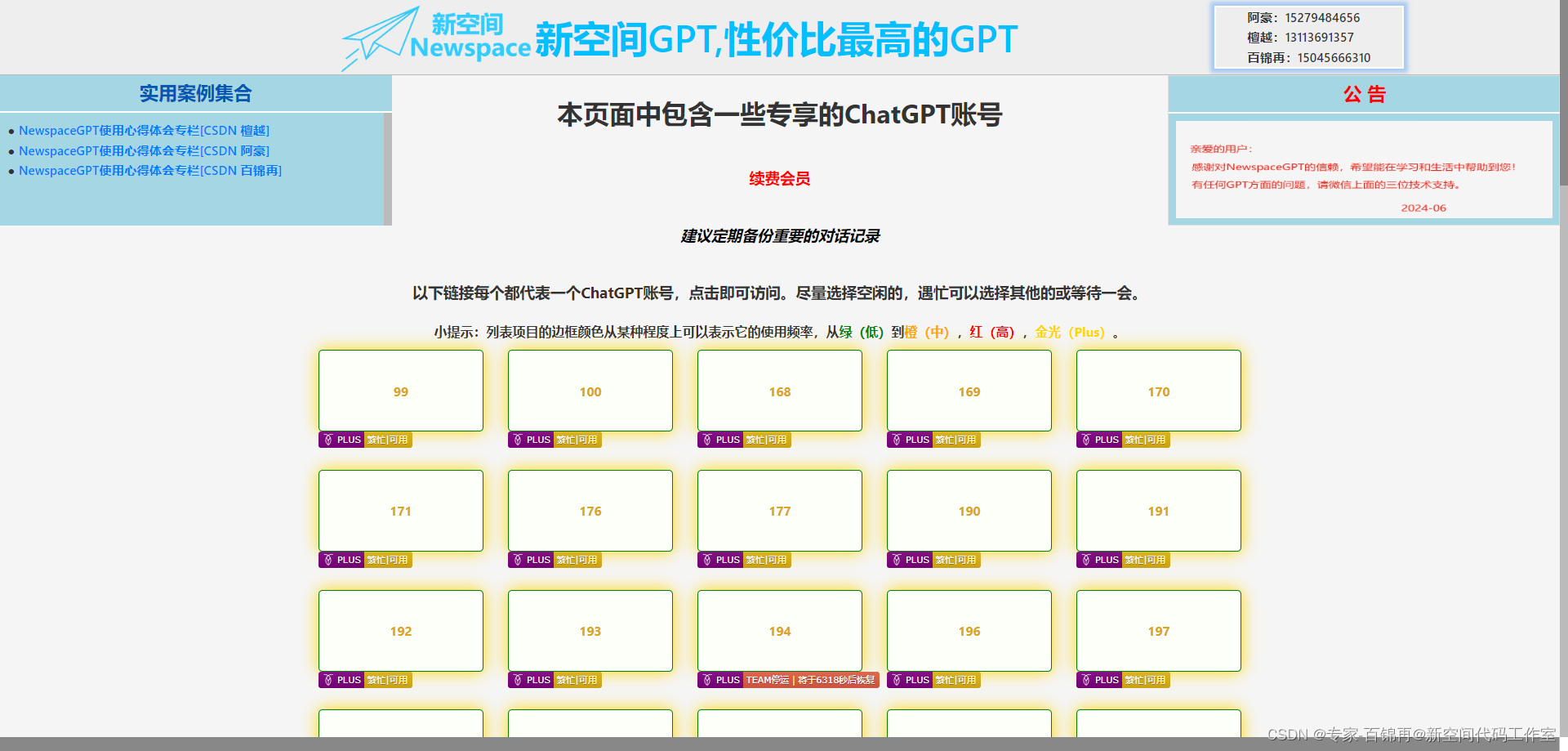
选一个可用的Plus,不要选3.5
探索GPT
今天的主角是
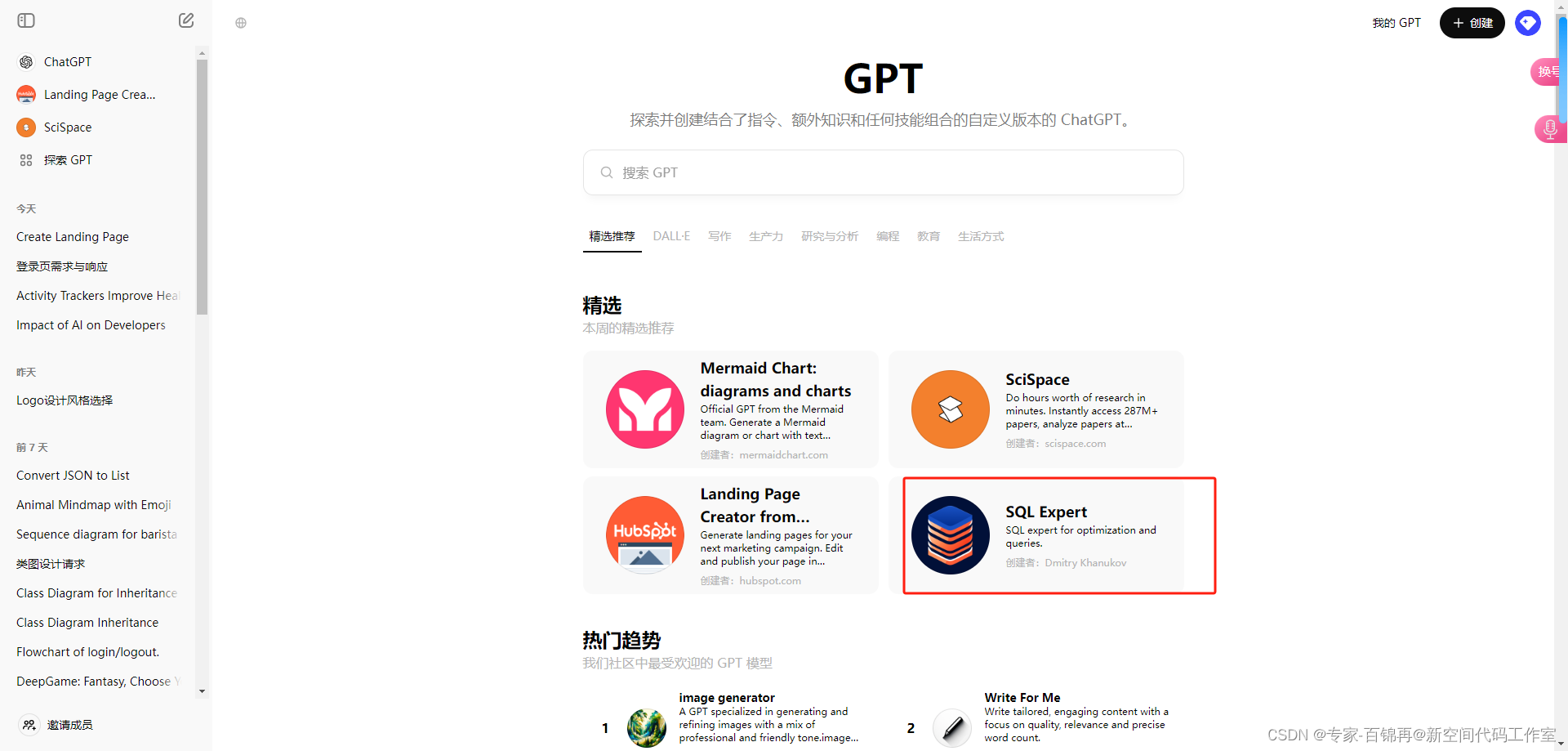
SQL Expert(SQL 专家)
SQL expert for optimization and queries.
SQL优化和查询专家。
How do I optimize this SQL query?
Suggest a database structure for my app.
Explain this SQL error message.
Help me to optimize this request.
如何优化此SQL查询?
建议我的应用程序的数据库结构。
解释此SQL错误消息。
帮助我优化此请求。
问题1:
影响SQL查询效率的因素有哪些,应该怎么做针对性的优化,请详细举例回答:
答
影响SQL查询效率的因素有很多,下面是一些主要因素及相应的优化措施:
1. 索引
原因:
索引可以大幅提高数据检索速度,但错误的索引或缺乏索引可能导致查询变慢。
优化措施:
- 创建适当的索引:在经常用作查询条件的列上创建索引。
- 使用复合索引:对多个列一起使用的查询条件,创建复合索引。
- 避免不必要的索引:虽然索引有助于查询,但过多的索引会影响写入性能。
示例:
-- 在`users`表的`username`列上创建索引
CREATE INDEX idx_username ON users(username);
2. 查询设计
原因:
不良的查询设计会导致不必要的全表扫描或复杂的计算,从而降低查询效率。
优化措施:
- **避免SELECT ***:仅选择需要的列。
- 拆分复杂查询:将复杂的查询拆分成多个简单的查询。
- 使用合适的连接类型:INNER JOIN 通常比 LEFT JOIN 更高效。
示例:
-- 避免使用SELECT *,改为选择具体的列
SELECT id, username, email FROM users WHERE status = 'active';
3. 数据库设计
原因:
不良的数据库设计,如不规范化的表结构,会导致数据冗余和查询复杂度增加。
优化措施:
- 规范化数据库:确保数据库设计符合规范化标准。
- 合理的表分区:对大型表进行分区,以减少每次查询的数据量。
示例:
-- 将一个大表分成多个分区表
CREATE TABLE users (
id INT,
username VARCHAR(50),
created_date DATE
)
PARTITION BY RANGE (created_date) (
PARTITION p0 VALUES LESS THAN ('2020-01-01'),
PARTITION p1 VALUES LESS THAN ('2021-01-01')
);
4. 缓存
原因:
频繁查询相同数据时,未使用缓存会导致性能低下。
优化措施:
- 使用查询缓存:对频繁执行的查询结果进行缓存。
- 应用层缓存:在应用层使用缓存机制,如Redis或Memcached。
示例:
-- 在MySQL中启用查询缓存
SET GLOBAL query_cache_size = 1048576;
SET GLOBAL query_cache_type = 1;
5. 并行查询和分布式系统
原因:
对于大规模数据集,单一的查询处理能力可能不足。
优化措施:
- 使用并行查询:在支持并行处理的数据库中,启用并行查询。
- 分布式数据库系统:使用分布式数据库系统如Apache Cassandra或Google Bigtable。
示例:
-- 在PostgreSQL中设置并行度
SET max_parallel_workers_per_gather = 4;
6. 分析和优化工具
原因:
没有使用合适的工具进行性能分析,可能会忽视一些潜在的问题。
优化措施:
- 使用EXPLAIN:分析查询执行计划,找出性能瓶颈。
- 数据库自带的优化工具:利用数据库管理系统提供的性能分析工具。
示例:
-- 使用EXPLAIN分析查询
EXPLAIN SELECT id, username FROM users WHERE status = 'active';
通过以上措施,可以有效地优化SQL查询性能,提高数据库的整体运行效率。
问题2
SELECT
`t`.`supervision_id` AS `zjid`,
`c`.`dwbh` AS `bdcdwbh`,
`c`.`dwmc` AS `bdcdwmc`,
`d`.`context` AS `dclb`,
`e`.`context` AS `dcsx`,
`t`.`detected_time` AS `fxsj`,
`t`.`content` AS `wtms`,
`g`.`sxjmc` AS `jkdwmc`,
group_concat( `b`.`url` SEPARATOR ',' ) AS `dcwttplj`
FROM
((((((
`supervision` `t`
LEFT JOIN `annex` `b` ON ((
`t`.`supervision_id` = `b`.`gbzj_id`
)))
LEFT JOIN `jc_dwxx` `c` ON ((
`t`.`target_dept` = `c`.`dwbh`
)))
LEFT JOIN `gzzd_zdbt` `d` ON (((
`t`.`type1` = `d`.`id`
)
AND ( `d`.`lb` = 3 ))))
LEFT JOIN `gzzd_zdbt` `e` ON (((
`t`.`type2` = `e`.`id`
)
AND ( `e`.`lb` = 3 ))))
LEFT JOIN `supervision_vedio` `f` ON ((
`t`.`supervision_id` = `f`.`supervisionid`
)))
LEFT JOIN `sjwh_video` `g` ON ((
`f`.`sjwhvideoid` = `g`.`id`
)))
WHERE
((
`t`.`ISDEL` = 0
)
AND ( `t`.`super_dept` = '004' )
AND ( `t`.`target_dept` <> '004001' )
AND ( `b`.`check_value` = '1' )
AND ( `t`.`addtype` = 0 )
AND ( `c`.`sczt` = 0 )
AND ( `t`.`sp_status` = 2 ))
GROUP BY
`t`.`supervision_id`,
`c`.`dwbh`,
`c`.`dwmc`,
`d`.`context`,
`e`.`context`,
`t`.`detected_time`,
`t`.`content`,
`g`.`sxjmc`
ORDER BY
`t`.`detected_time` DESC
优化这个SQL
答:
优化这条SQL查询的主要目标是提高其执行效率。以下是一些优化建议和改进后的SQL示例:
1. 索引优化
确保在连接列和筛选条件列上创建合适的索引:
supervision表:supervision_id,target_dept,ISDEL,super_dept,addtype,sp_status,detected_timeannex表:gbzj_id,check_valuejc_dwxx表:dwbh,scztgzzd_zdbt表:id,lbsupervision_vedio表:supervisionidsjwh_video表:id
2. 连接优化
检查连接条件,确保不会导致笛卡尔积,并且可以利用索引。
3. 子查询和临时表
考虑使用子查询或临时表来减少主查询的复杂度和数据量。
4. GROUP BY 和 ORDER BY
确保 GROUP BY 和 ORDER BY 结合索引使用,避免全表扫描。
优化后的SQL示例
SELECT
t.supervision_id AS zjid,
c.dwbh AS bdcdwbh,
c.dwmc AS bdcdwmc,
d.context AS dclb,
e.context AS dcsx,
t.detected_time AS fxsj,
t.content AS wtms,
g.sxjmc AS jkdwmc,
group_concat(b.url SEPARATOR ',') AS dcwttplj
FROM
supervision t
LEFT JOIN annex b ON t.supervision_id = b.gbzj_id AND b.check_value = '1'
LEFT JOIN jc_dwxx c ON t.target_dept = c.dwbh AND c.sczt = 0
LEFT JOIN gzzd_zdbt d ON t.type1 = d.id AND d.lb = 3
LEFT JOIN gzzd_zdbt e ON t.type2 = e.id AND e.lb = 3
LEFT JOIN supervision_vedio f ON t.supervision_id = f.supervisionid
LEFT JOIN sjwh_video g ON f.sjwhvideoid = g.id
WHERE
t.ISDEL = 0
AND t.super_dept = '004'
AND t.target_dept <> '004001'
AND t.addtype = 0
AND t.sp_status = 2
GROUP BY
t.supervision_id,
c.dwbh,
c.dwmc,
d.context,
e.context,
t.detected_time,
t.content,
g.sxjmc
ORDER BY
t.detected_time DESC;
具体优化措施说明
索引:
- 创建必要的索引以支持
WHERE和JOIN条件。例如:CREATE INDEX idx_supervision ON supervision(supervision_id, target_dept, ISDEL, super_dept, addtype, sp_status, detected_time); CREATE INDEX idx_annex ON annex(gbzj_id, check_value); CREATE INDEX idx_jc_dwxx ON jc_dwxx(dwbh, sczt); CREATE INDEX idx_gzzd_zdbt ON gzzd_zdbt(id, lb); CREATE INDEX idx_supervision_vedio ON supervision_vedio(supervisionid); CREATE INDEX idx_sjwh_video ON sjwh_video(id);
- 创建必要的索引以支持
连接顺序:
- 将过滤条件尽量前置,减少连接的数据量。
组合索引:
- 考虑在
supervision表上创建组合索引以覆盖WHERE子句中的多列条件。
- 考虑在
通过这些优化措施,可以显著提高这条复杂查询的执行效率,尤其是在大数据量情况下。具体效果可以通过执行计划(EXPLAIN)来验证。
//python 因为爱,所以学
print("Hello, Python!")
