核心:

- 开放词汇的实时的yolo检测器。
- 重参数化的视觉语言聚合路径模块Re-parameterizable VisionLanguage Path Aggregation Network (RepVL-PAN)
- 实时核心:轻量化的检测器+离线词汇推理过程重参数化
方法
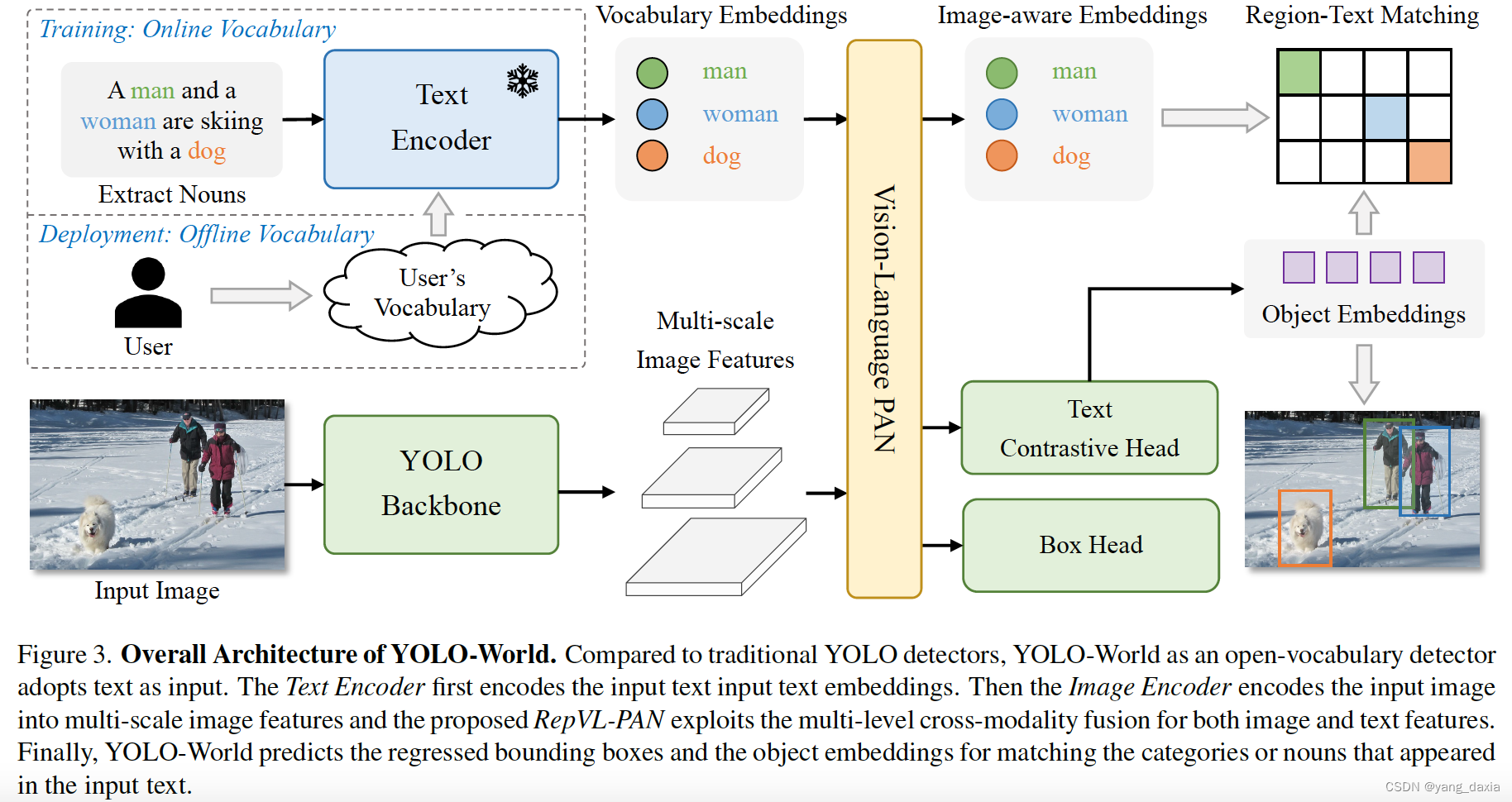
预训练方案:将实例注释重新定义为区域-文本对,通过大规模检测、定位和图像-文本数据进行预训练。
模型架构:YOLO-World由YOLO检测器、文本编码器和RepVL-PAN组成,利用跨模态融合增强文本和图像表示
基础结构
- Yolo detectorV8, darknet+PAN+head
- Text Encoder. CLIP+n-gram
- Text Contrastive Head.两个3x3回归bbox框以及object embedding。object embedding与文本embedding计算相似度求对比loss
- Inference with Offline Vocabulary.prompt提前确定好,提前计算好embedding。再重参数化到PAN模块。
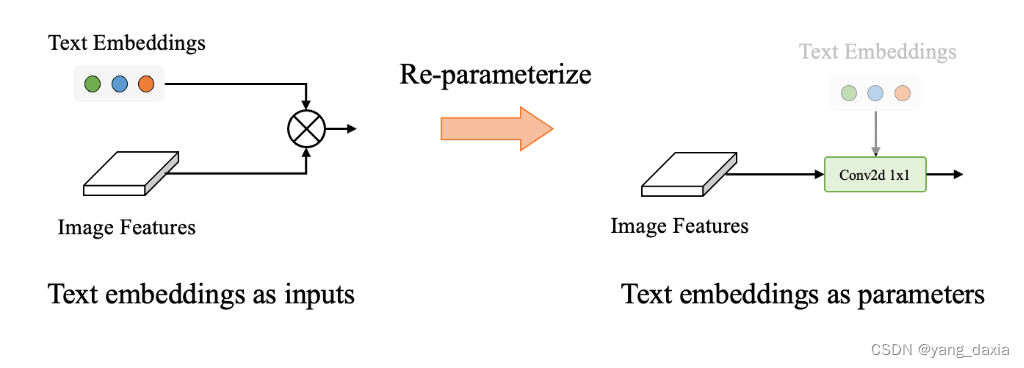
3.3. Re-parameterizable Vision-Language PAN
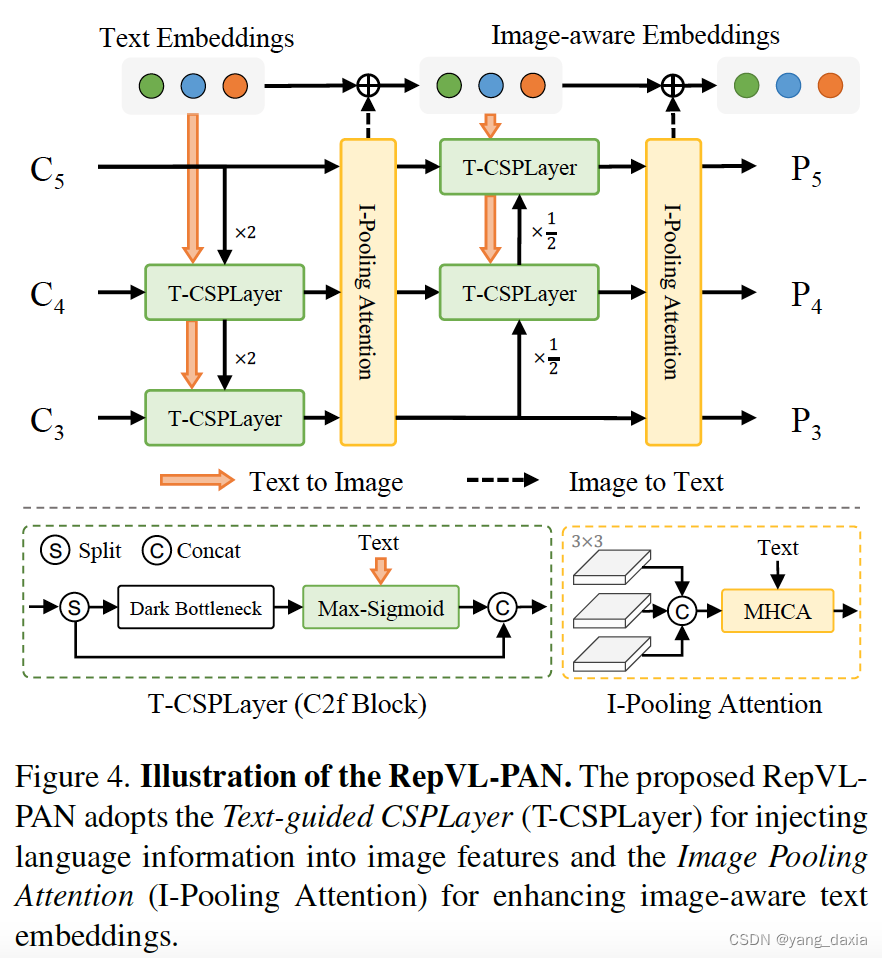
RepVL-PAN由多尺度图像特征{C3, C4, C5}形成,利用了自顶向下和自底向上的路径来加强图像特征和文本特征之间的交互。
- Text-guided CSPLayer(文本->图像).文本embedding经过max-sigmoid加权到neck特征后与原始特征concat。
- Image-Pooling Attention.(图像->文本)。多层图像特征和文本attention再加到文本embedding中
结果
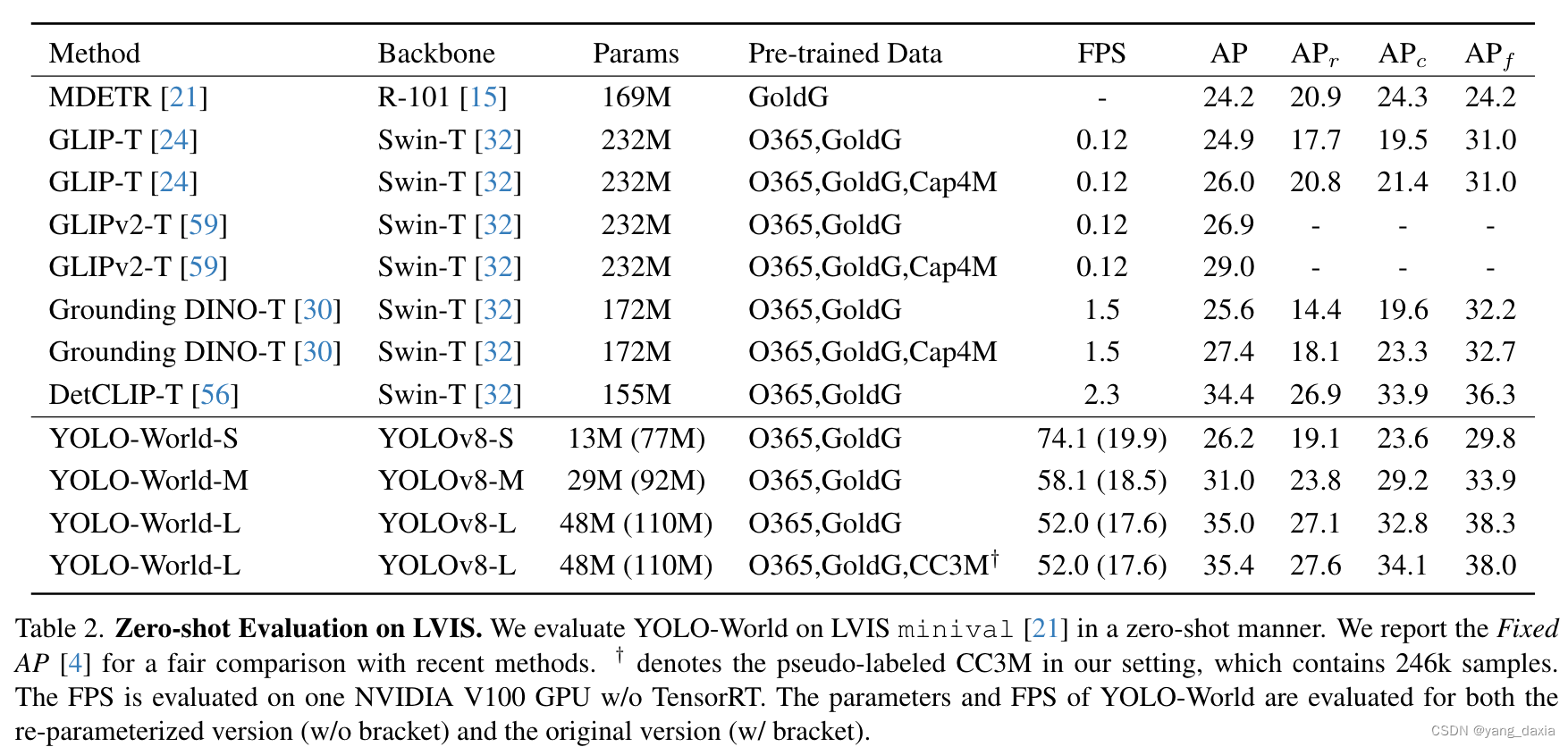
又快又好!V100上达到了52FPS!!!

核心代码:
class RepConvMaxSigmoidAttnBlock(BaseModule):
"""Max Sigmoid attention block."""
def __init__(self,
in_channels: int,
out_channels: int,
embed_channels: int,
guide_channels: int,
kernel_size: int = 3,
padding: int = 1,
num_heads: int = 1,
use_depthwise: bool = False,
with_scale: bool = False,
conv_cfg: OptConfigType = None,
norm_cfg: ConfigType = dict(type='BN',
momentum=0.03,
eps=0.001),
init_cfg: OptMultiConfig = None,
use_einsum: bool = True) -> None:
super().__init__(init_cfg=init_cfg)
conv = DepthwiseSeparableConvModule if use_depthwise else ConvModule
assert (out_channels % num_heads == 0 and
embed_channels % num_heads == 0), \
'out_channels and embed_channels should be divisible by num_heads.'
self.num_heads = num_heads
self.head_channels = out_channels // num_heads
self.use_einsum = use_einsum
self.embed_conv = ConvModule(
in_channels,
embed_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=None) if embed_channels != in_channels else None
self.bias = nn.Parameter(torch.zeros(num_heads))
self.num_heads = num_heads
self.split_channels = embed_channels // num_heads
self.guide_convs = nn.ModuleList(
nn.Conv2d(self.split_channels, guide_channels, 1, bias=False)
for _ in range(num_heads))
self.project_conv = conv(in_channels,
out_channels,
kernel_size,
stride=1,
padding=padding,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=None)
def forward(self, x: Tensor, txt_feats: Tensor = None) -> Tensor:
"""Forward process."""
B, C, H, W = x.shape
embed = self.embed_conv(x) if self.embed_conv is not None else x
embed = list(embed.split(self.split_channels, 1))
# Bx(MxN)xHxW (H*c=C, H: heads)
attn_weight = torch.cat(
[conv(x) for conv, x in zip(self.guide_convs, embed)], dim=1)
# BxMxNxHxW
attn_weight = attn_weight.view(B, self.num_heads, -1, H, W)
# attn_weight = torch.stack(
# [conv(x) for conv, x in zip(self.guide_convs, embed)])
# BxMxNxHxW -> BxMxHxW
attn_weight = attn_weight.max(dim=2)[0] / (self.head_channels**0.5)
attn_weight = (attn_weight + self.bias.view(1, -1, 1, 1)).sigmoid()
# .transpose(0, 1)
# BxMx1xHxW
attn_weight = attn_weight[:, :, None]
x = self.project_conv(x)
# BxHxCxHxW
x = x.view(B, self.num_heads, -1, H, W)
x = x * attn_weight
x = x.view(B, -1, H, W)
return x
ImagePoolingAttentionModule
class ImagePoolingAttentionModule(nn.Module):
def __init__(self,
image_channels: List[int],
text_channels: int,
embed_channels: int,
with_scale: bool = False,
num_feats: int = 3,
num_heads: int = 8,
pool_size: int = 3,
use_einsum: bool = True):
super().__init__()
self.text_channels = text_channels
self.embed_channels = embed_channels
self.num_heads = num_heads
self.num_feats = num_feats
self.head_channels = embed_channels // num_heads
self.pool_size = pool_size
self.use_einsum = use_einsum
if with_scale:
self.scale = nn.Parameter(torch.tensor([0.]), requires_grad=True)
else:
self.scale = 1.0
self.projections = nn.ModuleList([
ConvModule(in_channels, embed_channels, 1, act_cfg=None)
for in_channels in image_channels
])
self.query = nn.Sequential(nn.LayerNorm(text_channels),
Linear(text_channels, embed_channels))
self.key = nn.Sequential(nn.LayerNorm(embed_channels),
Linear(embed_channels, embed_channels))
self.value = nn.Sequential(nn.LayerNorm(embed_channels),
Linear(embed_channels, embed_channels))
self.proj = Linear(embed_channels, text_channels)
self.image_pools = nn.ModuleList([
nn.AdaptiveMaxPool2d((pool_size, pool_size))
for _ in range(num_feats)
])
def forward(self, text_features, image_features):
B = image_features[0].shape[0]
assert len(image_features) == self.num_feats
num_patches = self.pool_size**2
mlvl_image_features = [
pool(proj(x)).view(B, -1, num_patches)
for (x, proj, pool
) in zip(image_features, self.projections, self.image_pools)
]
mlvl_image_features = torch.cat(mlvl_image_features,
dim=-1).transpose(1, 2)
q = self.query(text_features)
k = self.key(mlvl_image_features)
v = self.value(mlvl_image_features)
q = q.reshape(B, -1, self.num_heads, self.head_channels)
k = k.reshape(B, -1, self.num_heads, self.head_channels)
v = v.reshape(B, -1, self.num_heads, self.head_channels)
if self.use_einsum:
attn_weight = torch.einsum('bnmc,bkmc->bmnk', q, k)
else:
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 3, 1)
attn_weight = torch.matmul(q, k)
attn_weight = attn_weight / (self.head_channels**0.5)
attn_weight = F.softmax(attn_weight, dim=-1)
if self.use_einsum:
x = torch.einsum('bmnk,bkmc->bnmc', attn_weight, v)
else:
v = v.permute(0, 2, 1, 3)
x = torch.matmul(attn_weight, v)
x = x.permute(0, 2, 1, 3)
x = self.proj(x.reshape(B, -1, self.embed_channels))
return x * self.scale + text_features
参考:https://github.com/AILab-CVC/YOLO-World/blob/master/yolo_world/models/layers/yolo_bricks.py