本文来源公众号“程序员学长”,仅用于学术分享,侵权删,干货满满。
原文链接:当 LSTM 遇上 Attention
今天我们一起来聊一下深度学习中的注意力(Attention)机制
注意力机制是深度学习中引入的一种技术,特别适用于序列到序列的任务(Sequence to Sequence,Seq2Seq)。通过引入注意力机制,Seq2Seq 模型能够在解码每个时间步时,动态地选择和关注输入序列中的不同部分,从而更好地捕捉输入序列的全局信息。
在讨论注意力机制之前,我们先来了解一下 Seq2Seq 模型。
Seq2Seq
序列到序列(Seq2Seq)模型是一种深度学习架构,广泛应用于将一个序列数据转换为另一个序列数据的任务中,例如机器翻译、自动问答、语音识别等。这种模型特别适用于输入序列和输出序列长度不固定的情况。

基本结构
序列到序列模型通常由两部分组成:编码器(Encoder)和解码器(Decoder)。
编码器
编码器的作用是接受输入序列,并将其转换成一个固定大小的状态向量(通常称为上下文向量)。这个向量旨在捕捉输入序列的关键信息。
在实现上,编码器通常是一个循环神经网络(RNN)或其变体,如长短期记忆网络(LSTM)或门控循环单元(GRU)。
关于 RNN、LSTM 以及 GRU 可以参考如下文章:程序员学长 | 快速学会一个算法,RNN-CSDN博客和程序员学长 | 快速学会一个算法模型,LSTM-CSDN博客。
解码器
解码器的任务是将编码器生成的状态向量转换为输出序列。它从编码器传递的上下文向量开始生成输出,并逐步生成输出序列中的每个元素。
解码器通常也是基于RNN、LSTM或GRU构建的,它在生成每个输出元素时会参考前一个元素的输出,以及编码器的上下文向量。
工作流程
序列到序列模型的工作流程可以概括为以下几步:
输入处理
将输入序列(如文本、语音等)转化为模型能够处理的格式,通常是一系列编码向量。
序列编码
通过编码器处理输入向量,逐步更新内部状态,最终生成一个紧凑的上下文向量。
状态传递
上下文向量被传递给解码器,作为其初始化状态。
序列解码
解码器根据上下文向量逐步生成输出序列的每个元素。在生成每个新元素时,解码器会考虑已生成的序列和从编码器接收到的上下文。
输出生成
解码器输出的序列经过后处理(如解码或转换)后形成最终的输出序列。
Seq2Seq 模型的缺点
固定大小的上下文向量
在传统的 Seq2Seq 模型中,无论输入序列的长度如何,编码器都必须将所有的信息压缩到一个固定大小的上下文向量中。这可能导致信息丢失,特别是在处理长序列时。
长距离依赖问题
尽管LSTM和GRU设计用来缓解梯度消失问题,并能在一定程度上处理长距离依赖,但在实际应用中,当序列非常长时,模型仍然难以捕捉序列中的远距离依赖关系。
在 Seq2Seq 中引入 Attention
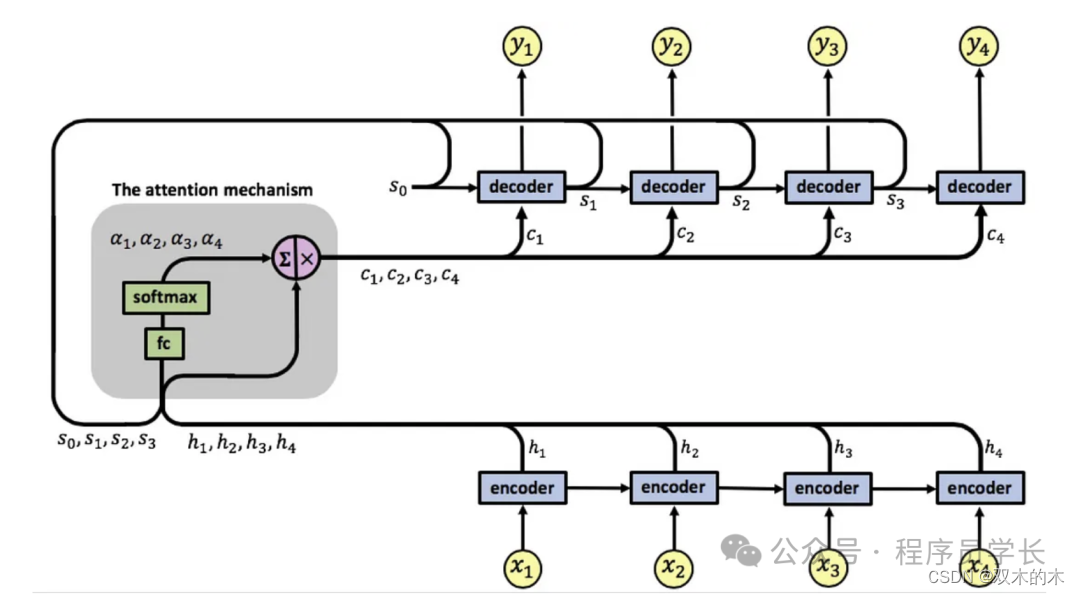
如上图所示,在编码器和解码器中加入了注意力机制。
注意力权重的计算


案例说明
我们使用的示例是一个将句子从英语翻译成意大利语的网络。
该网络由两部分组成:
编码器,它对英语句子的含义进行编码;
解码器,它将编码的信息解码为句子到意大利语的翻译。
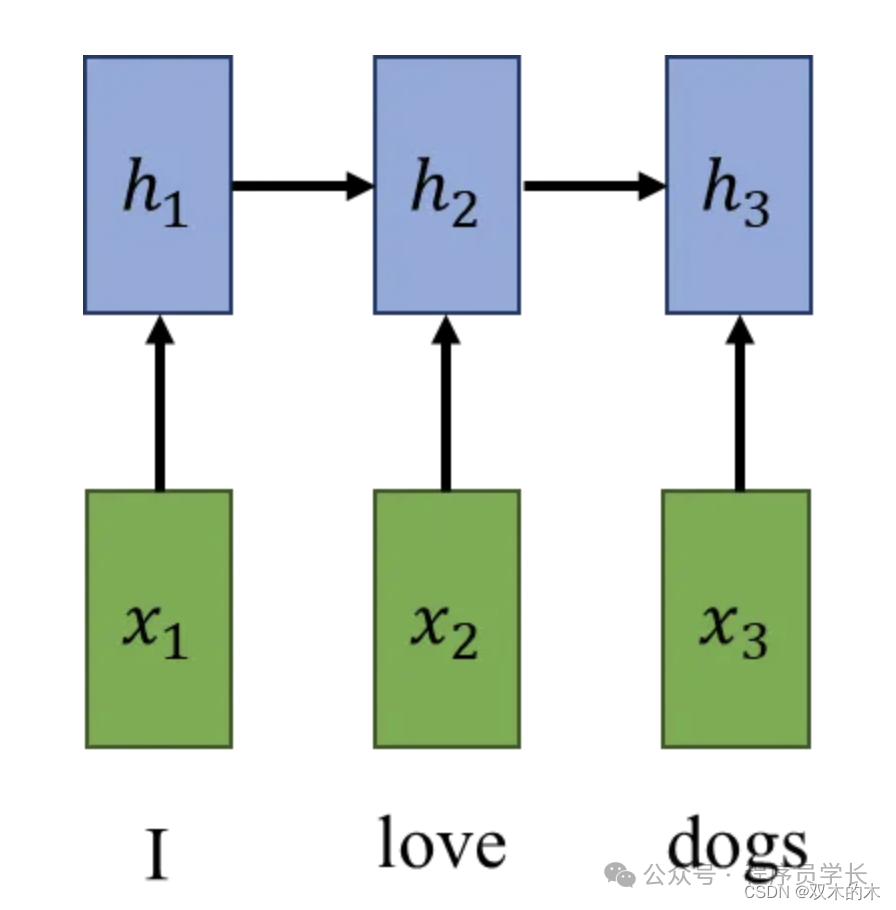
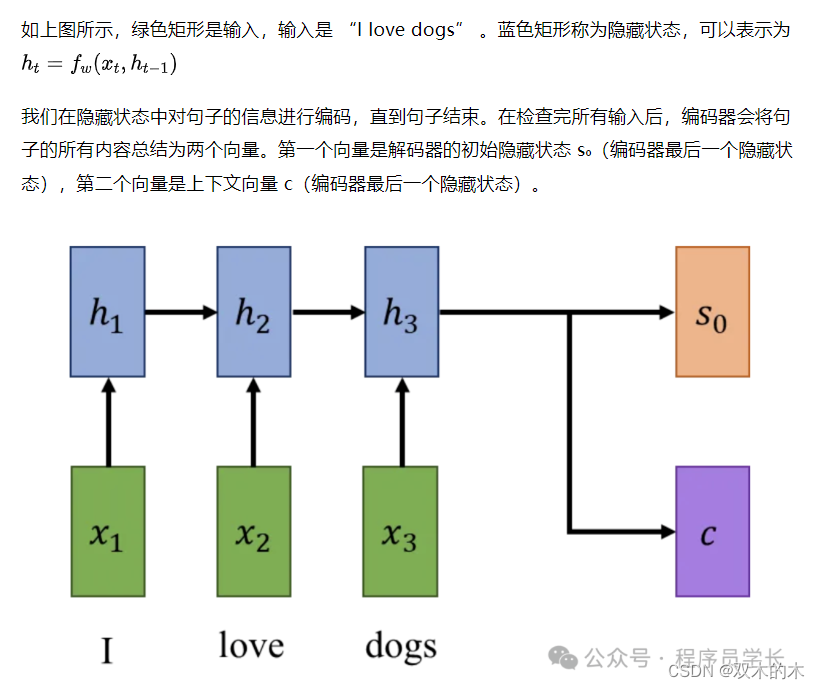
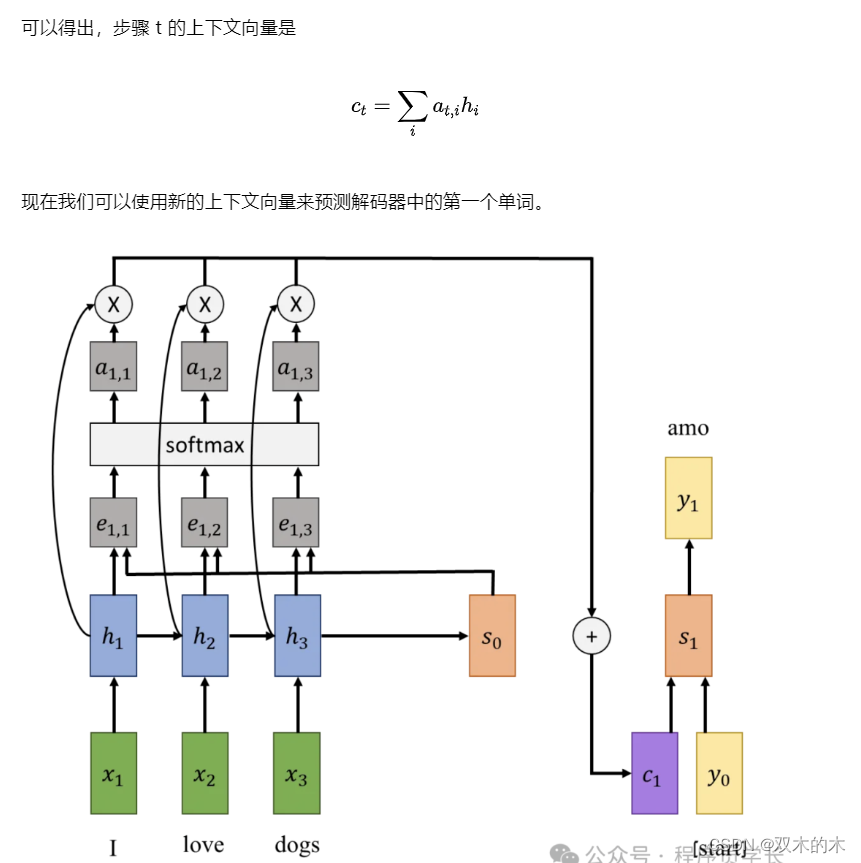
现在,当我们在编码器部分完成对句子信息的提取后,我们就可以开始解码信息并使用解码器将句子翻译成意大利语了。
解码器的第一个输入是一个起始标记,以及初始隐藏状态和上下文向量,它们构成了第一个隐藏状态。对于该隐藏状态,我们可以得到新句子的第一个输出。
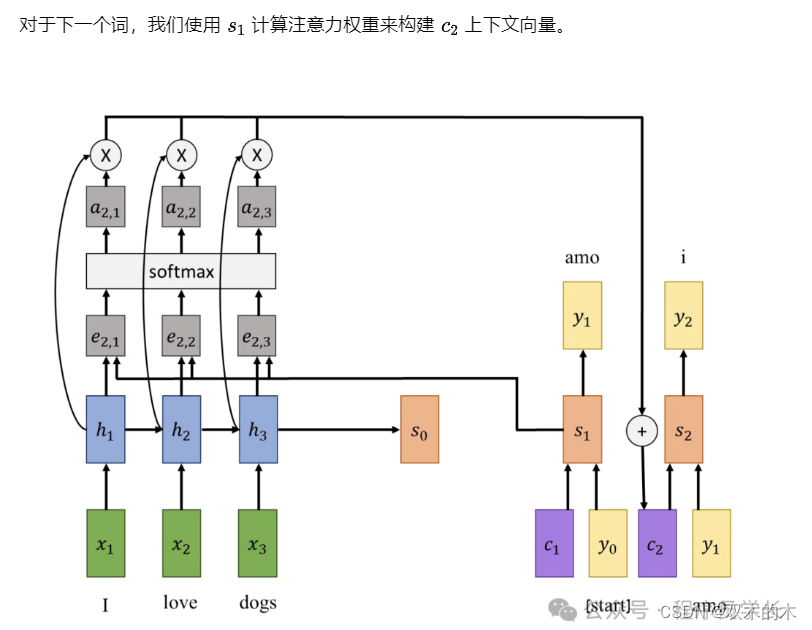
我们将该输出用作下一步的输入,与前一个隐藏状态和上下文向量一起构建新的隐藏状态的输出。

该过程持续,直到我们获得停止标记作为输出。

这个过程对于短句很有效,但当句子变长时可能会失败。原因是解码器在所有步骤中使用上下文向量,并且需要它包含有关原始句子的所有信息。对于长句,将全部信息保存在一个固定大小的向量中可能非常困难。
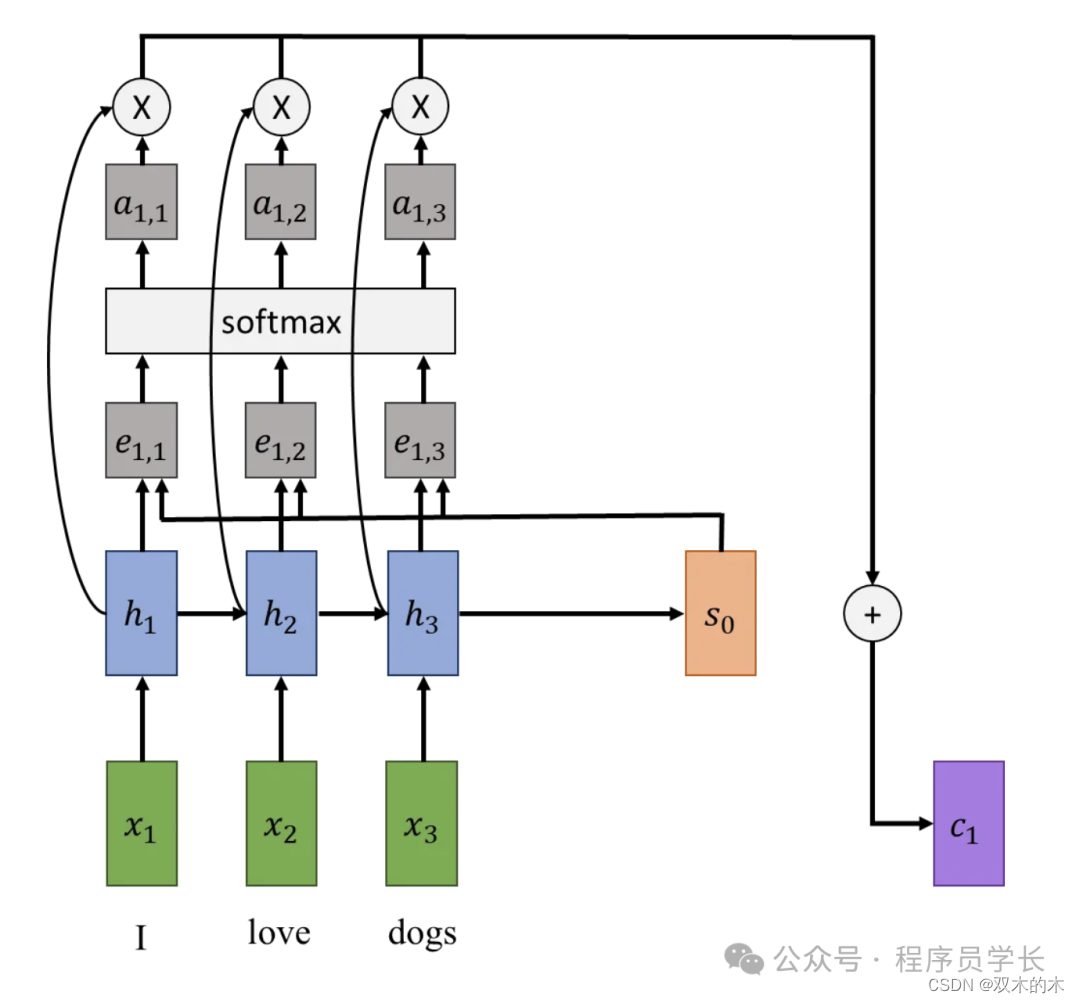
在 seq2seq 模型添加 Attention
我们将保留以前的编码器-解码器架构,但这次我们在网络中添加了另一种机制,为解码器的每个步骤构建一个新的上下文向量。
我们的编码器仍然像以前一样遍历输入序列并创建隐藏状态,最后为解码器创建初始隐藏状态。
现在,我们不再使用编码器的最终隐藏状态来制作上下文向量,而是使用解码器的初始隐藏状态和所有其他隐藏状态来构建它。
为此,我们将实现一个对齐函数,它是对编码器的隐藏状态和解码器的隐藏状态进行操作。此函数计算编码器每个隐藏状态的对齐分数(标量)。

这些分数表明,在给定解码器当前隐藏状态的情况下,我们应该在多大程度上关注编码器的每个隐藏状态。
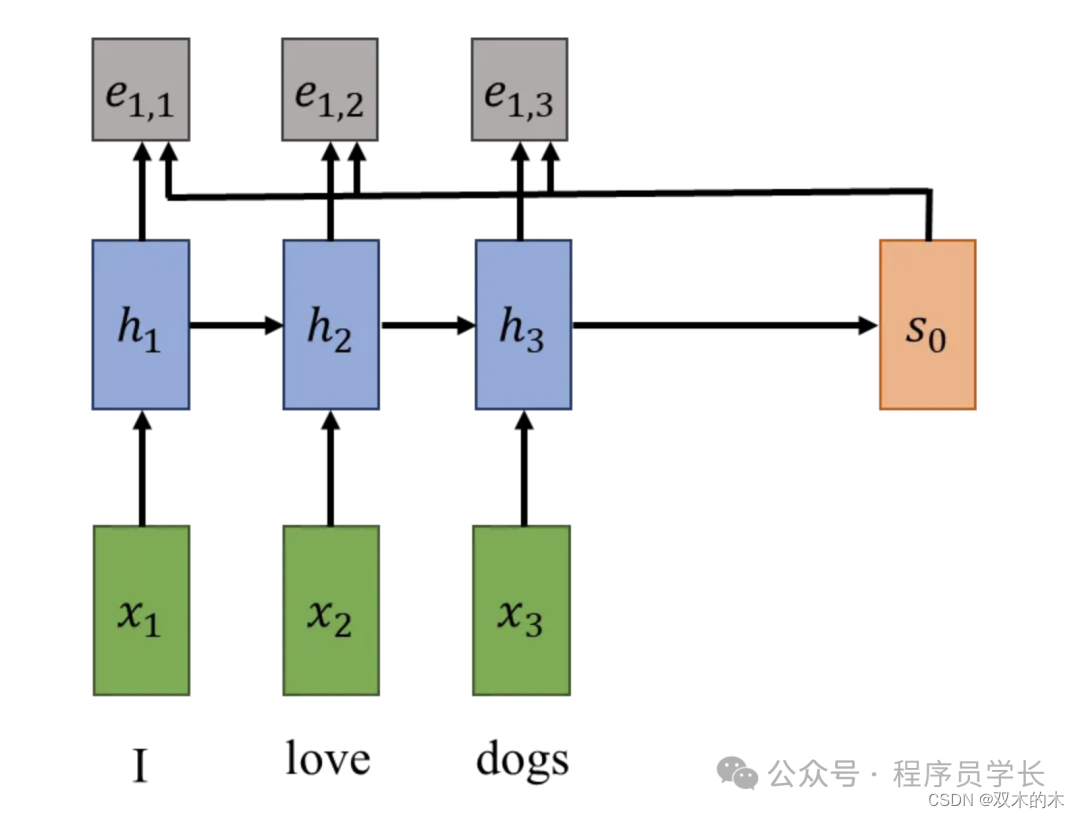

这些概率是标准化的对齐分数,它们将用作编码器隐藏状态的注意力权重。新的上下文向量将是编码器隐藏状态乘以注意力权重的加权和。
下面是如何在 PyTorch 中实现 LSTM 注意力机制的基本示例。
import torch
import torch.nn as nn
import torch.nn.functional as F
class EncoderLSTM(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim, n_layers):
super(EncoderLSTM, self).__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hidden_dim, n_layers, batch_first=True)
def forward(self, src):
embedded = self.embedding(src)
outputs, (hidden, cell) = self.rnn(embedded)
return outputs, hidden, cell
class Attention(nn.Module):
def __init__(self):
super(Attention, self).__init__()
def forward(self, encoder_outputs, decoder_hidden):
# encoder_outputs: (batch_size, seq_len, hidden_dim)
# decoder_hidden: (batch_size, hidden_dim)
# Calculate the attention scores.
scores = torch.bmm(encoder_outputs, decoder_hidden.unsqueeze(2)).squeeze(2) # (batch_size, seq_len)
attn_weights = F.softmax(scores, dim=1) # (batch_size, seq_len)
context_vector = torch.bmm(attn_weights.unsqueeze(1), encoder_outputs).squeeze(1) # (batch_size, hidden_dim)
return context_vector, attn_weights
class DecoderLSTMWithAttention(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim, n_layers):
super(DecoderLSTMWithAttention, self).__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim + hidden_dim, hidden_dim, n_layers, batch_first=True)
self.out = nn.Linear(hidden_dim, output_dim)
self.attention = Attention()
def forward(self, input, encoder_outputs, hidden, cell):
input = input.unsqueeze(1) # (batch_size, 1)
embedded = self.embedding(input) # (batch_size, 1, emb_dim)
context_vector, attn_weights = self.attention(encoder_outputs, hidden[-1]) # using the last layer's hidden state
rnn_input = torch.cat([embedded, context_vector.unsqueeze(1)], dim=2) # (batch_size, 1, emb_dim + hidden_dim)
output, (hidden, cell) = self.rnn(rnn_input, (hidden, cell))
prediction = self.out(output.squeeze(1))
return prediction, hidden, cell
# Example usage
INPUT_DIM = 1000 # e.g., size of the source language vocabulary
OUTPUT_DIM = 1000 # e.g., size of the target language vocabulary
EMB_DIM = 256
HIDDEN_DIM = 512
N_LAYERS = 2
encoder = EncoderLSTM(INPUT_DIM, EMB_DIM, HIDDEN_DIM, N_LAYERS)
decoder = DecoderLSTMWithAttention(OUTPUT_DIM, EMB_DIM, HIDDEN_DIM, N_LAYERS)
src_seq = torch.randint(0, INPUT_DIM, (32, 10)) # batch of 32, sequence length 10
encoder_outputs, hidden, cell = encoder(src_seq)
input = torch.randint(0, OUTPUT_DIM, (32,)) # batch of 32, single time step
output, hidden, cell = decoder(input, encoder_outputs, hidden, cell)THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。