1.1 简介
R-CNN,全称为Regions with Convolutional Neural Network features,是由Ross Girshick等人在2014年提出的一种用于目标检测的深度学习方法。它是将卷积神经网络(CNN)应用于目标检测任务的先驱工作,对后续的目标检测技术发展产生了深远的影响,比如催生了Fast R-CNN、Faster R-CNN以及Mask R-CNN等改进模型。
R-CNN(Region-based Convolutional Neural Network)是一种早期的深度学习目标检测技术,它通过结合选择性搜索产生的区域提议、卷积神经网络的特征提取能力、支持向量机(SVM)进行分类以及边界框回归来精确定位图像中的目标物体。尽管这种方法在2014年提出时显著提高了检测精度,但因其多阶段处理流程导致的计算效率低下而逐渐被其后续更快的变体如Fast R-CNN和Faster R-CNN所取代。R-CNN的核心贡献在于证明了CNN在特征提取上的强大潜力,为后续目标检测算法的快速发展奠定了基础。
该模型出自《Rich feature hierarchies for accurate object detection and semantic segmentation》
下面让我们来学习一下这篇论文。
1.2 R-CNN基本原理
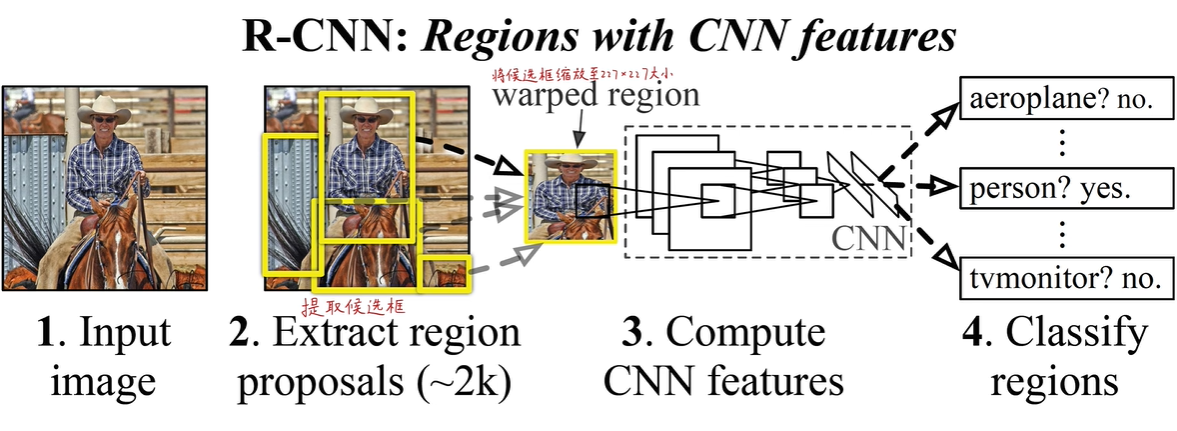
首先输入图像,RCNN用selective search的方法从图像中生成2000个候选框,这些候选框可能是最终的目标也可能不是,把每个候选框不管长宽比例大小统一强制缩放成227x227的正方形,然后把每个正方形逐一喂到CNN中,提取一个4096层的全连接层的输出特征,获得特征后一边用线性支持向量机来进行分类,一边用于回归,得到最终的目标检测结果。
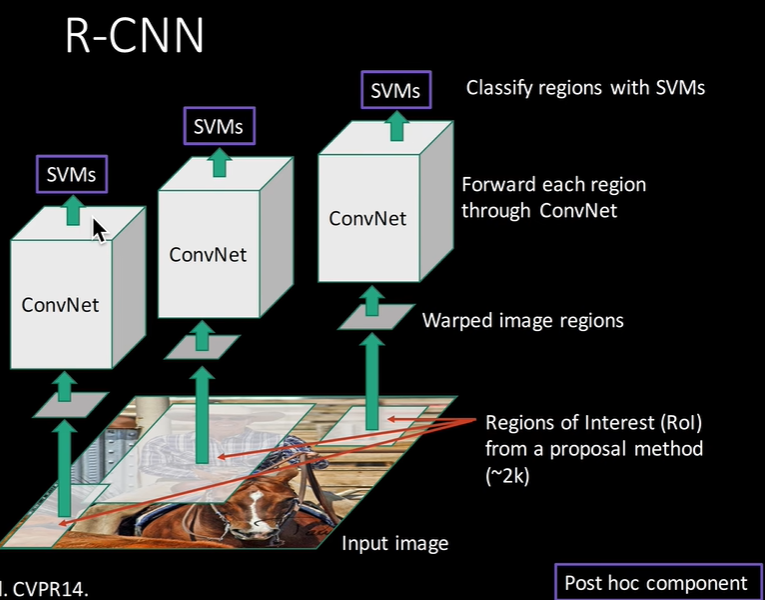
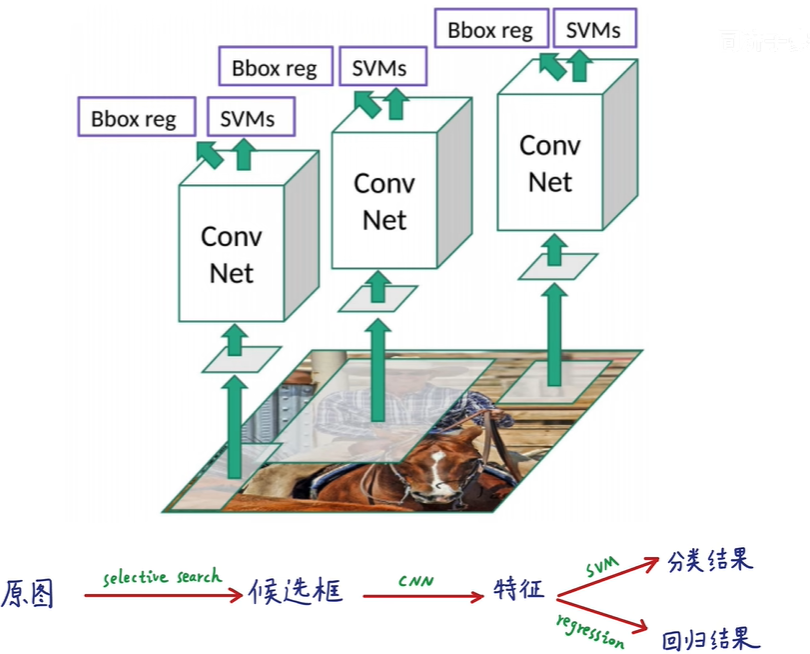
(但凡有一个步骤出现问题,整个R-CNN就毁了)
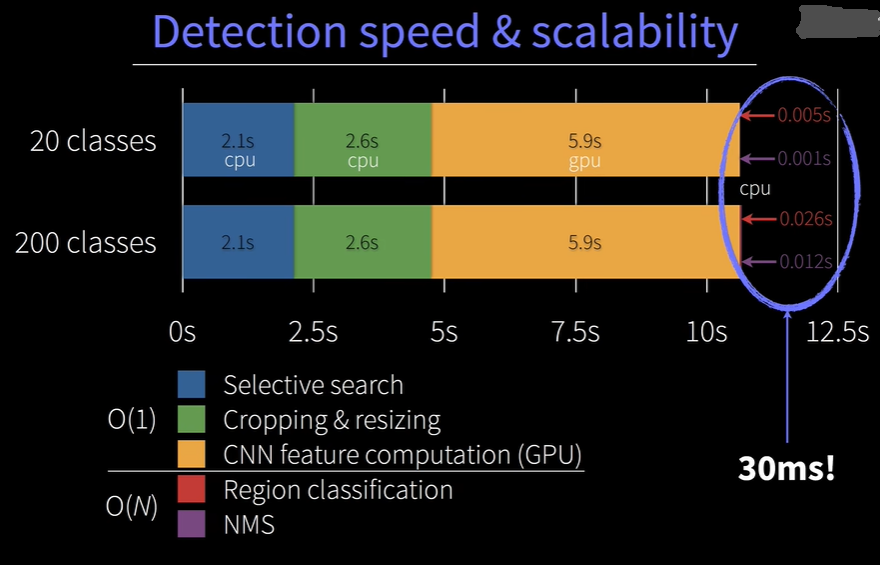
通过步骤和耗时我们就可以看出来,R-CNN是一个很臃肿、耗时,非端到端,低效的算法。所以后来有了对R-CNN的改进:

1.3 产生候选框-Selective Search
通过一种类似聚类的方法,在图像中找到一些初始的分割区域(颜色纹理形状大小一致的比较相似的区域)对这些区域进行加权合并,以产生不同层次的2000个候选框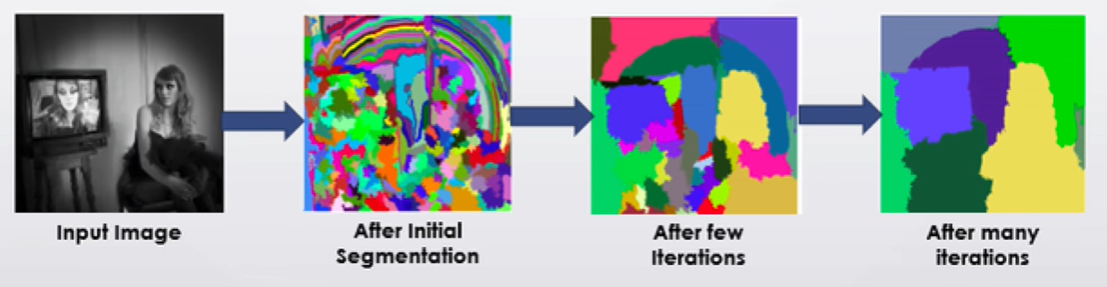


1.4 将候选框缩放至227x227固定大小

R-CNN采用连带邻近像素的非等比例缩放的方法,连带像素P=16。多出来的像素全部填为图像的平均值,再喂到卷积神经网络之前每个像素要减去平均值。
Dilate Proposal:再原有候选框的基础上往外扩充16个像素


上图为扩充为227x227的候选框,虽然产生了很大的变形,但是该有的东西还是有的。
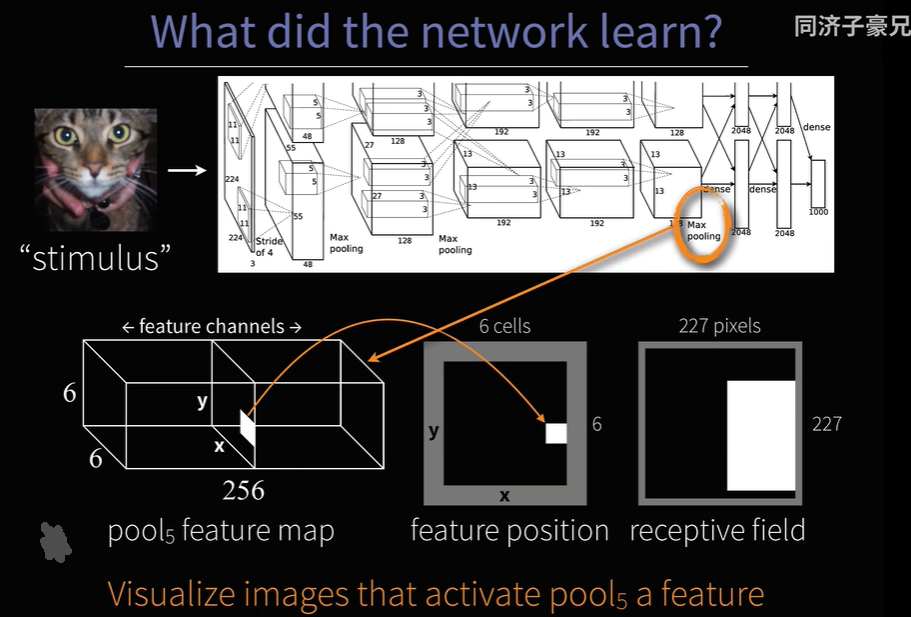
1.5 可视化能够使得“某个feature map的某个值”最大化的原始候选框
可视化某一个channel的某一个值,找到能使这个值最大化的原始候选框长什么样。这个值代表了原图的某个感受野区域。

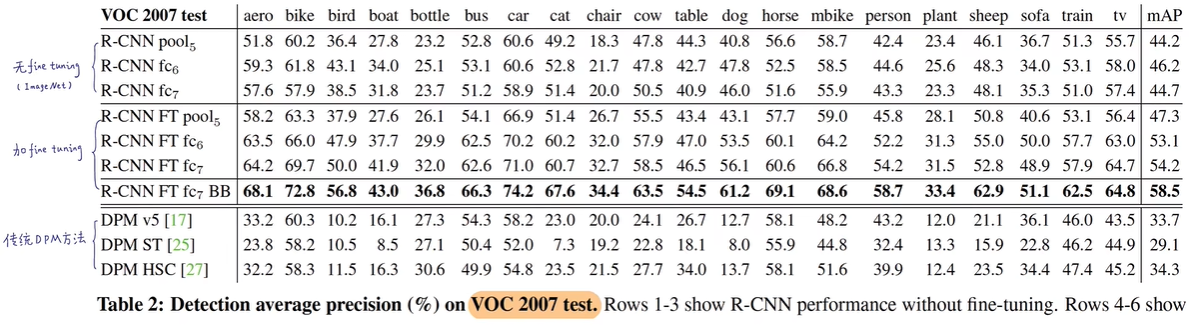
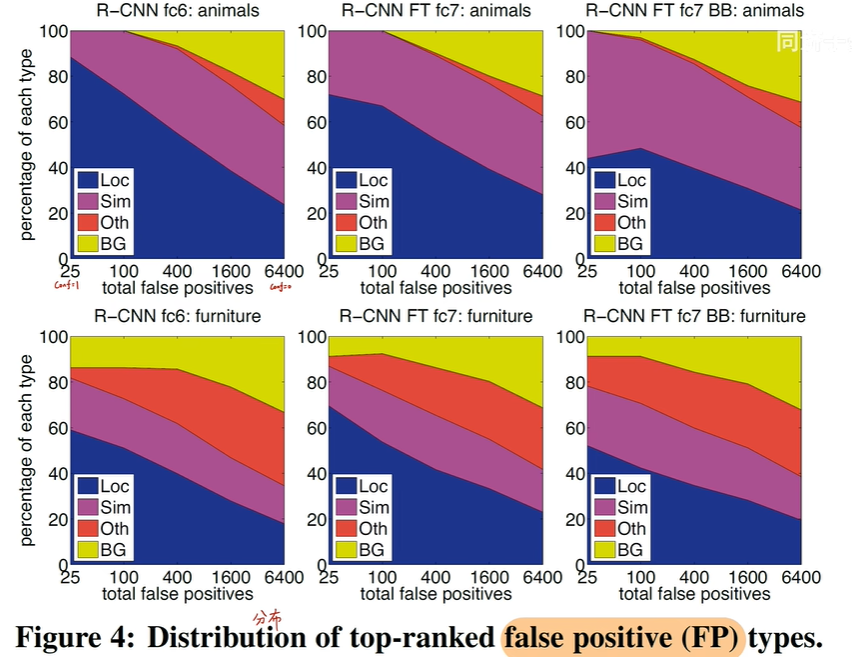
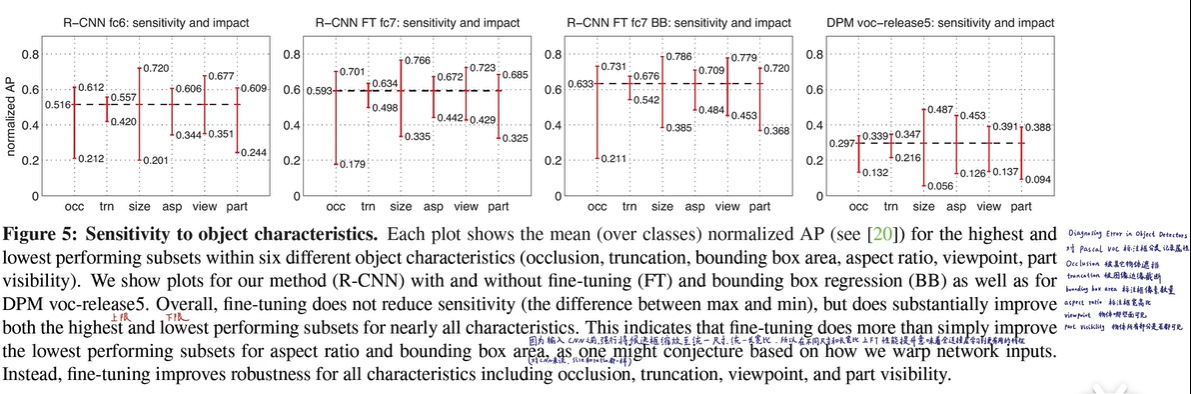
1.6 对比试验
fine tuning即微调,可以发现加了 bounding box 和fine tuning 是非常有效的。
R-CNN在语义分割领域也取得了不错的成绩
 1.7 为什么不直接用softmax分类而要用SVM分类
1.7 为什么不直接用softmax分类而要用SVM分类

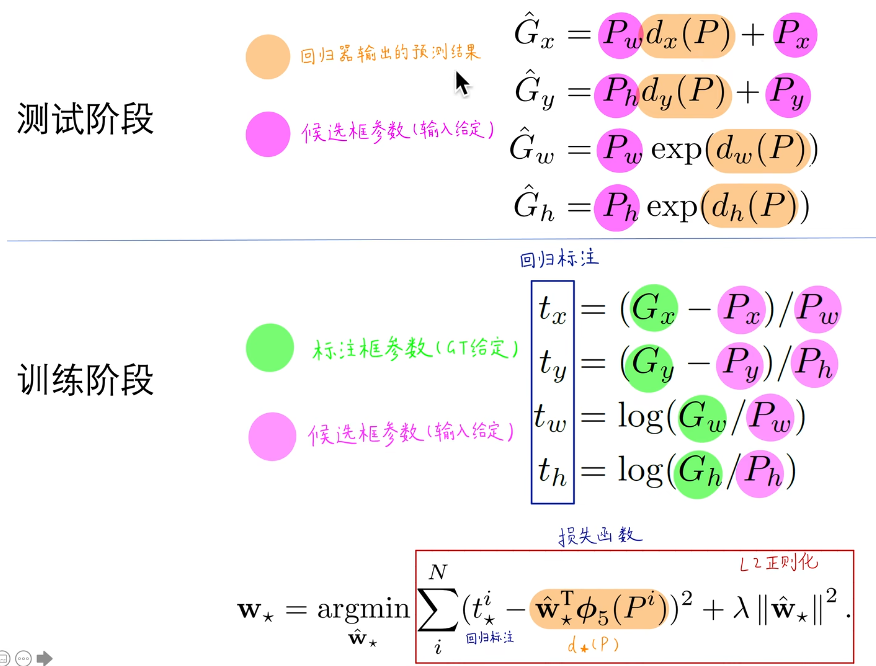
1.8 Bounding Box Regression
对候选框进行精调,得到一系列的偏移量,对候选框施加偏移量得到最终的预测框
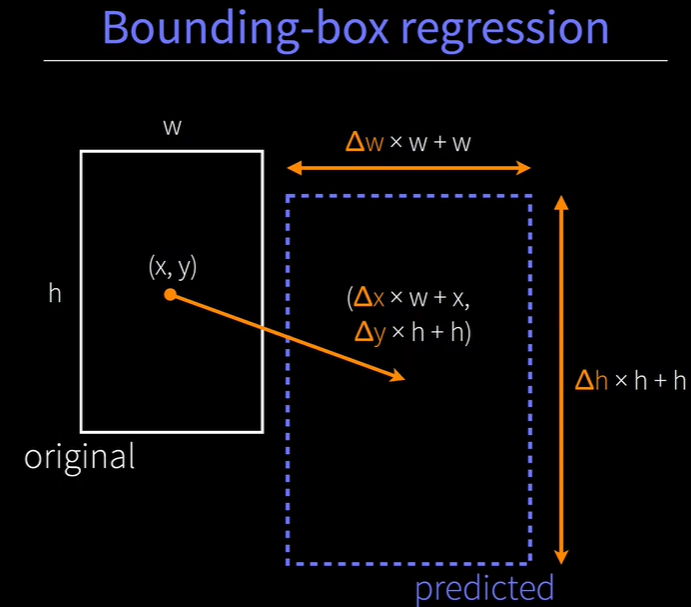
测试阶段:
把原始候选框的中心点(x,y)加上原始候选框的宽w高h乘以比例因子得到预测框的中心点。
在原始候选框的宽高乘以e^(比例因子)就得到了最终预测框的宽高。
训练阶段:
通过标注好的标注框,以及候选框,拟合出比例因子t。
让“黄色”去拟合“蓝色”的比例因子