文章目录
AI(学习笔记第八课) 使用langchain的embedding models
- 为什么需要使用
embedding models - 如何使用
embedding models
学习内容:
embedding model的基本概念- 为什么使用
embedding model - 如何使用
embedding model
1.embedding model的基本概念
1.1 学习embedding model url
1.2 为什么学习embedding model
embedding model能将文本转换成固定长度(fixed length)的有语义的数组,这样以来,不光能基于文件检索,而是能通过语义检索,对文本进行检索。
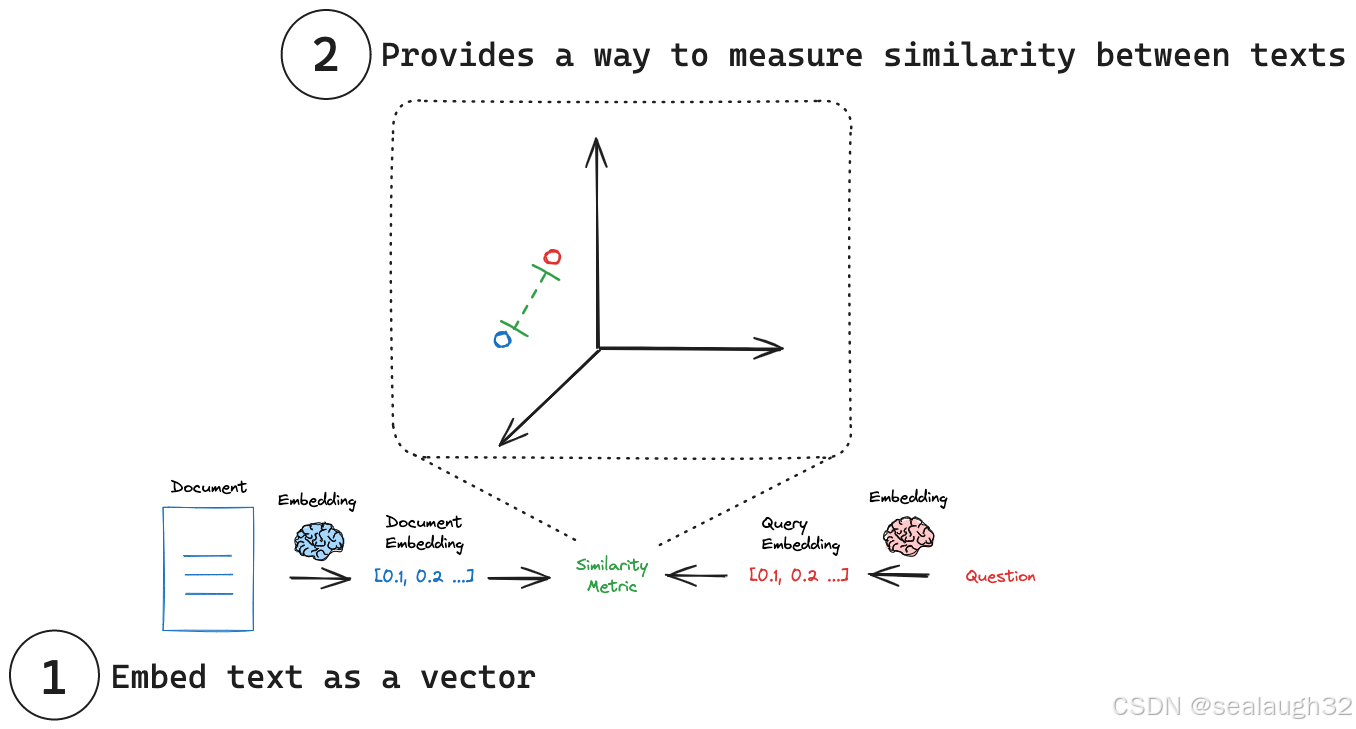
- 左面蓝字将文本文档
document经过embedding model转换成长度相等的数字向量(numerical vector representation) - 右面的红字将问题(
question)也转换成数字向量(numerical vector representation) - 最后对两个数字向量(
numerical vector representation)可以进行相似度比较(similarity metric)。
1.3 使用embedding model将文本转换成数字向量
1.3.1 最初的代码
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
from langchain_ollama import OllamaEmbeddings
from langchain.chains import RetrievalQA
try:
# 使用Ollama的嵌入模型
embeddings_model = OllamaEmbeddings(
base_url='http://192.168.2.208:11434',
model="nomic-embed-text")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"O