- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标:
1. 决策树算法是一种在机器学习和数据挖掘领域广泛应用的强大工具,它模拟人类决策过程,通过对数据集进行逐步的分析和判定,最终生成一颗树状结构,每个节点代表一个决策或一个特征。决策树的核心思想是通过一系列问题将数据集划分成不同的类别或值,从而实现对未知数据的预测和分类。这一算法的开发灵感源自人类在解决问题时的思考方式,我们往往通过一系列简单而直观的问题逐步缩小解决方案的范围。决策树的构建过程也是类似的,它通过对数据的特征进行提问,选择最能区分不同类别的特征,逐渐生成树状结构,最终形成一个可用于预测的模型。
2. 通过通过鸢尾花数据,训练一个决策树模型,之后应用该模型,可以根据鸢尾花的四个特征去预测它的类别。
具体实现:
(一)环境:
语言环境:Python 3.10
编 译 器: PyCharm
**(二)具体步骤:
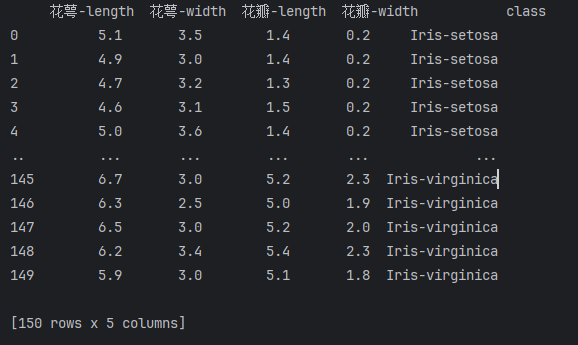
- 导入数据:
# 导入数据
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
names = ['花萼-length', '花萼-width', '花瓣-length', '花瓣-width', 'class']
dataset = pd.read_csv(url, names=names)
print(dataset)
2. 数据划分:
# 数据划分
X = dataset.iloc[:, [0, 1, 2, 3]].values # 数据集第1-4列为X
Y = dataset.iloc[:, 4].values # 数据集第5列为Y
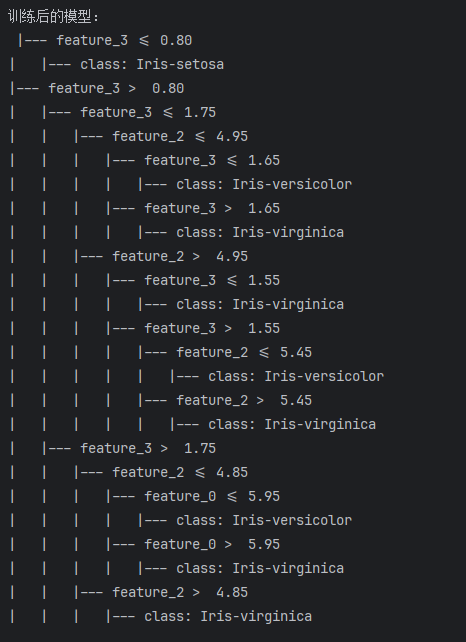
- 模型训练:
from sklearn import tree
clf = tree.DecisionTreeClassifier() # 决策树模型
clf = clf.fit(X, Y) # 用数据训练决策树模型
r = tree.export_text(clf)
print("训练后的模型:", r)
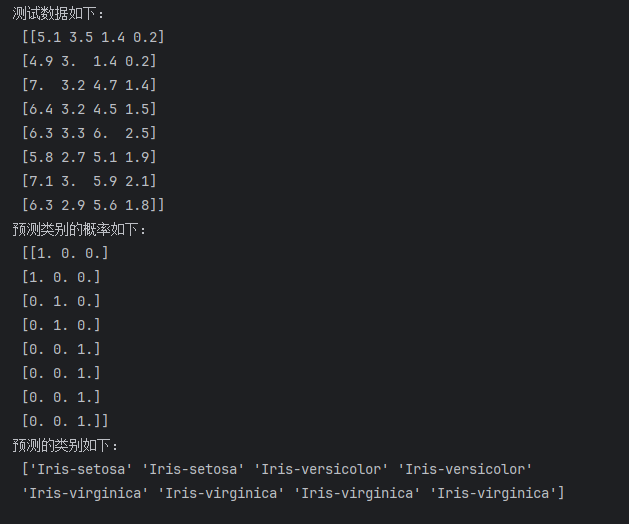
4. 用训练后的模型来预测一下结果:
# 用训练后的模型来预测一下结果
test_data = X[[0, 1, 50, 51, 100, 101, 102, 103], :] # 抽出数据集中指定第0、1、50...103行的所有数据
print("测试数据如下:\n", test_data)
pred_target_prob = clf.predict_proba(test_data) # 预测类别的概率
print("预测类别的概率如下:\n", pred_target_prob)
pred_target = clf.predict(test_data) # 预测类别
print("预测的类别如下:\n", pred_target)