Phi-3 模型系列是Microsoft 小型语言模型 (SLM) 系列中的最新产品。
它们旨在具有高性能和高性价比,在语言、推理、编码和数学等各种基准测试中的表现均优于同类和更大规模的模型。Phi-3 模型的推出扩大了 Azure 客户的高质量模型选择范围,为他们编写和构建生成式 AI 应用程序时提供了更多实用的选择。
参考链接:
微软 Azure AI 、Phi-3等免费试用申请
自 2024 年 4 月推出以来,我们收到了许多来自客户和社区成员的宝贵反馈,他们就 Phi-3 模型的改进领域提出了宝贵意见。今天,我们很自豪地宣布推出Phi-3.5-mini、Phi-3.5-vision以及 Phi 系列的新成员Phi-3.5-MoE,这是一种混合专家 (MoE) 模型。Phi-3.5-mini 通过 128K 上下文长度增强了多语言支持。 Phi-3.5-vision 改进了多帧图像理解和推理,提升了单图像基准测试的性能。Phi-3.5-MoE 拥有 16 位专家和 6.6B 个活动参数,可提供高性能、低延迟、多语言支持和强大的安全措施,在保持 Phi 模型功效的同时,优于大型模型。
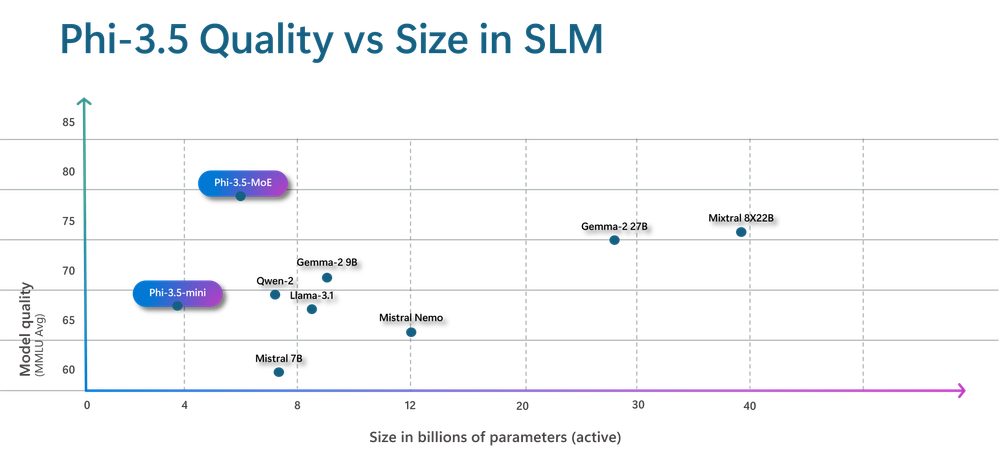
Phi- 3.5 SLM 中的质量与尺寸图
Phi-3.5-MoE:专家混合
Phi-3.5-MoE 是 Phi 模型系列的最新成员。它由 16 位专家组成,每位专家包含 38 亿个参数。总模型大小为 420 亿个参数,使用两位专家时可激活 66 亿个参数。在质量和性能方面,此 MoE 模型优于类似大小的密集模型。它支持 20 多种语言。与 Phi-3 同类模型一样,MoE 模型采用了强大的安全后训练策略,使用开源和专有合成指令和偏好数据集的组合。此后训练过程结合了监督微调 (SFT) 和直接偏好优化 (DPO),同时利用人工标记和合成数据集。这些数据集包括专注于有用性和无害性的数据集,以及多个安全类别。Phi-3.5-MoE 还支持高达 128K 的上下文长度,使其能够处理大量长上下文任务。
为了了解模型质量,我们将 Phi-3.5-MoE 与一系列基准上的模型进行了比较,如表 1 所示:
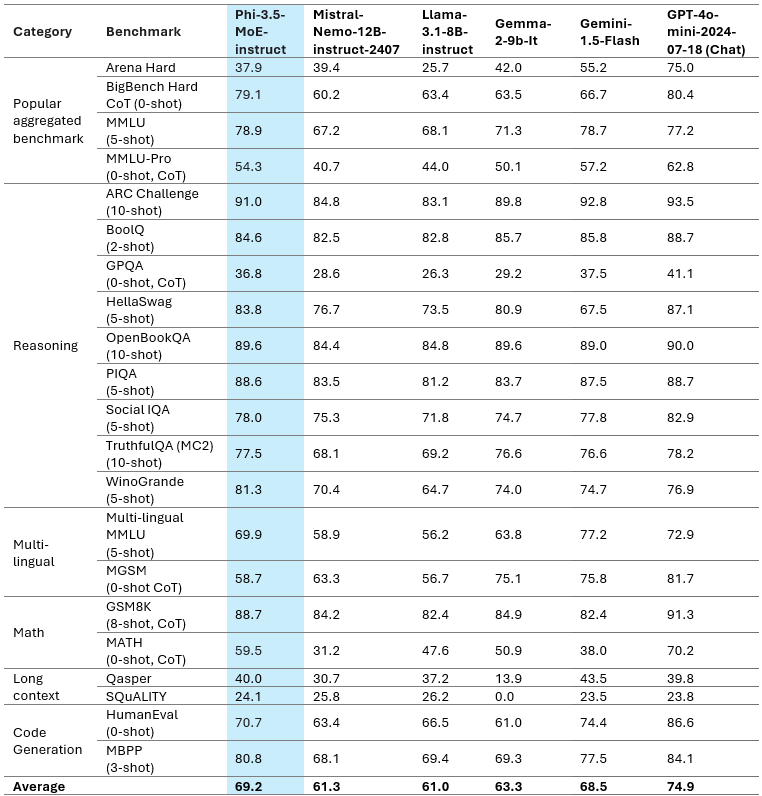
表 1:Phi-3.5-MoE 模型质量
我们在下表中仔细研究了不同类别的公共基准数据集:
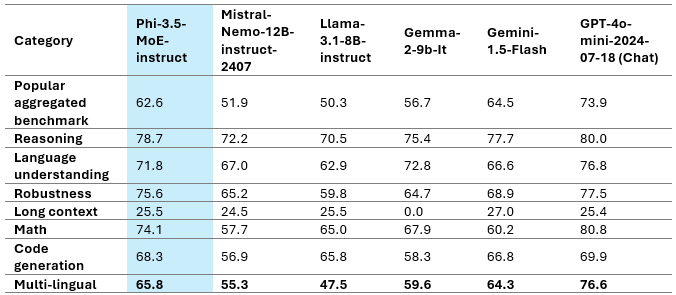
表 2:Phi-3.5-MoE 模型在各种功能上的质量
仅具有 6.6B 活动参数的 Phi-3.5-MoE 实现了与更大规模模型类似的语言理解和数学水平。此外,该模型在推理能力方面优于更大的模型。该模型为各种任务提供了良好的微调能力。表 3 突出显示了 Phi-3.5-MoE 在多语言 MMLU、MEGA 和多语言 MMLU-pro 数据集上的多语言能力。总体而言,我们观察到,即使只有 6.6B 活动参数,与其他具有更大活动参数的模型相比,该模型在多语言任务上也非常具有竞争力。
多语言能力
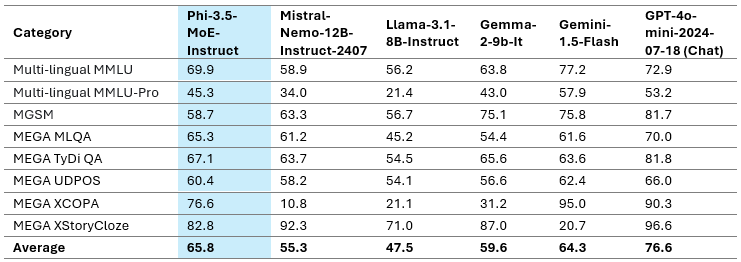
表 3:Phi-3.5-MoE 多语言基准
下表显示了一些受支持语言的多语言 MMLU 分数。
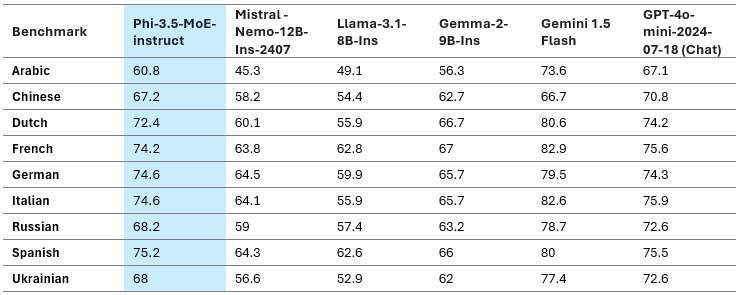
表 4:Phi-3.5-MoE 多语言 MMLU 基准
Phi-3.5-迷你
Phi-3.5-mini 模型已使用多语言合成和高质量过滤数据进行了进一步的预训练。随后进行了一系列后训练步骤,包括监督微调 (SFT)、近端策略优化 (PPO) 和直接偏好优化 (DPO)。这些过程利用了人工标记、合成和翻译数据集的组合。
模型质量
在深入研究语言模型的功能时,了解它们之间的比较至关重要。这就是为什么我们利用我们的内部基准测试平台对 Phi-3.5-mini 以及最近表现最佳的大型模型进行测试。在高层次概述中,表 1 提供了关键基准测试中模型质量的快照。尽管其紧凑尺寸仅为 3.8B 个参数,但这种高效模型不仅能与其他大型模型的性能相媲美,而且往往能超越它们。
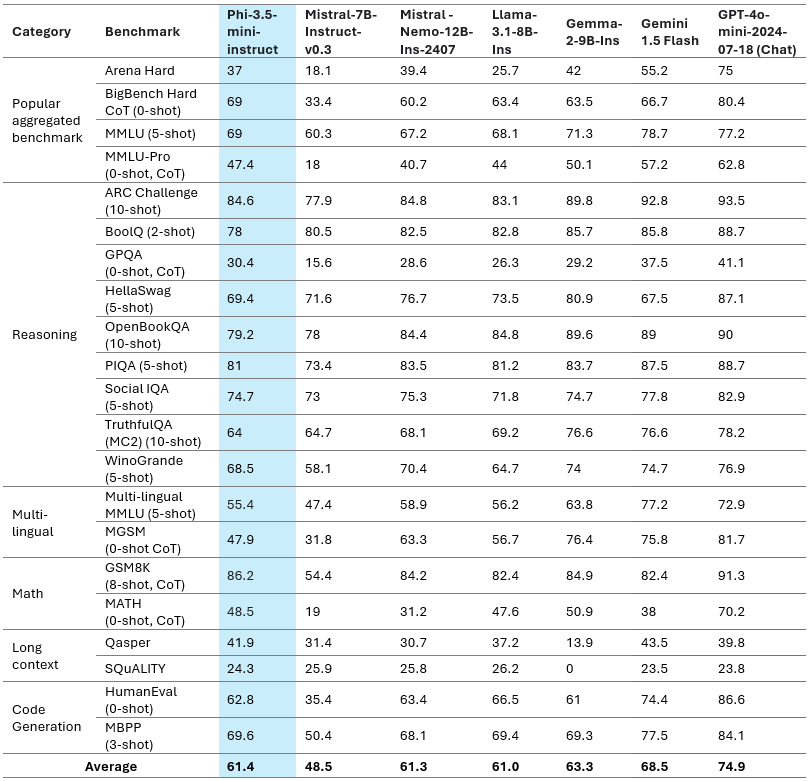
表 5:Phi-3.5-mini 模型质量
多语言能力
Phi-3.5-mini 是我们最新的 3.8B 模型更新。该模型使用了额外的持续预训练和后训练数据,从而显著提高了多语言、多轮对话质量和推理能力。该模型已针对以下列出的精选语言进行了训练:阿拉伯语、中文、捷克语、丹麦语、荷兰语、英语、芬兰语、法语、德语、希伯来语、匈牙利语、意大利语、日语、韩语、挪威语、波兰语、葡萄牙语、俄语、西班牙语、瑞典语、泰语、土耳其语和乌克兰语。
下表 6 重点介绍了 Phi-3.5-mini 在多语言 MMLU、MGSM、MEGA 和多语言 MMLU-pro 数据集的平均语言特定分数上的多语言能力。
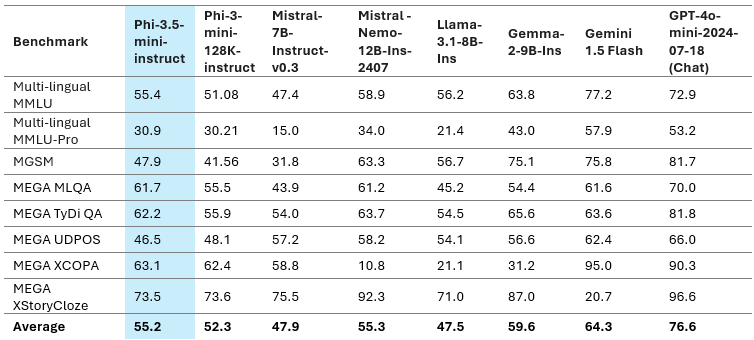
表 6:Phi-3.5-mini 多语言质量
下表 7 显示了一些受支持语言的多语言 MMLU 分数。
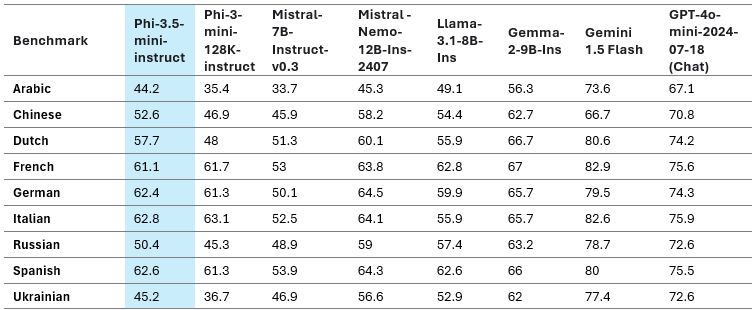
表 7:Phi-3.5-mini 多语言 MMLU 在选定语言集上的质量
Phi-3.5-mini 在多语言支持方面比 Phi-3-mini 有了显著的改进。阿拉伯语、荷兰语、芬兰语、波兰语、泰语和乌克兰语在新 Phi 版本中得到了最大的提升,性能提高了 25-50%。从更广泛的角度来看,Phi-3.5-mini 在任何 8B 以下模型中都表现出最佳性能,包括英语以及多种语言。值得注意的是,该模型使用 32K 词汇表并针对上述资源较高的语言进行了优化,不建议在未进一步微调的情况下将其用于资源较少的语言。
长上下文
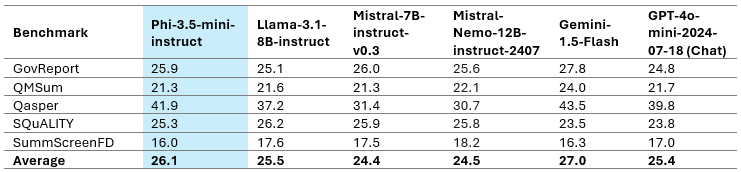
Phi-3.5-mini 支持 128K 上下文长度,在总结长文档或会议记录、基于长文档的 QA 和信息检索等任务中表现出色。Phi-3.5 的表现优于仅支持 8K 上下文长度的 Gemma-2 系列。此外,Phi-3.5-mini 与更大的开放权重模型(如 Llama-3.1-8B-instruct、Mistral-7B-instruct-v0.3 和 Mistral-Nemo-12B-instruct-2407)相比具有很强的竞争力。表 8 列出了各种长上下文基准。
Ruler:基于检索的长上下文理解基准

RepoQA:长上下文代码理解的基准

表 8:Phi-3.5-mini 长上下文基准
Phi-3.5-mini-instruct 仅具有 3.8B 参数、128K 上下文长度和多语言支持,是此类别中唯一的模型。值得注意的是,我们选择支持更多语言,同时在各种任务上保持英语性能。由于模型容量有限,这可能导致模型上的英语知识优于其他语言。对于多语言知识密集型任务,我们建议在 RAG 设置中使用该模型。
具有多帧输入的Phi-3.5视觉
Phi-3.5-vision 引入了基于宝贵客户反馈开发的多帧图像理解和推理的尖端功能。这项创新支持详细图像比较、多图像摘要/故事讲述和视频摘要,可在各种场景中提供广泛的应用。
例如,查看多张幻灯片的总结模型输出:


Phi-3.5-vison 模型输出用于幻灯片摘要
值得注意的是,Phi-3.5-vision 在众多单图像基准测试中表现出了显著的性能提升。例如,它将 MMMU 性能从 40.4 提升到了 43.0,将 MMBench 性能从 80.5 提升到了 81.9。此外,文档理解基准测试 TextVQA 也从 70.9 提升到了 72.0。
下表显示了两个著名多图像/视频基准的详细比较结果,展示了增强的性能指标。值得注意的是,Phi-3.5-Vision 并未针对多语言用例进行优化。建议不要在未进一步微调的情况下将其用于多语言场景。
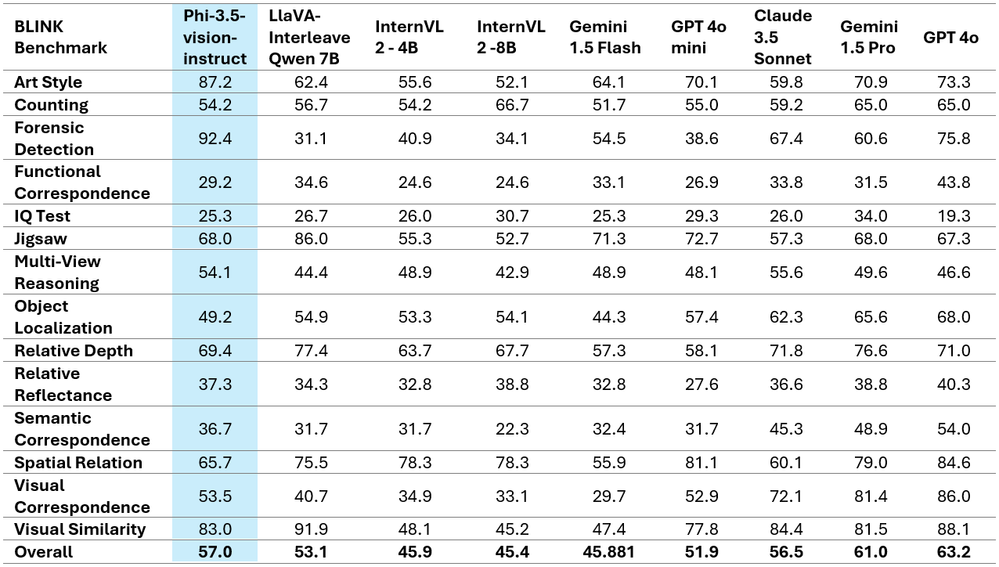
表 9:Phi-3.5-vision 任务基准
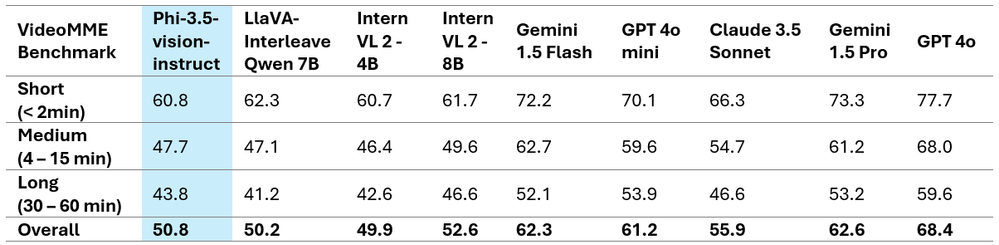
表 10:Phi-3.5-vision VideoMME 基准
安全
Phi-3 系列模型是根据Microsoft 负责任的 AI 标准开发的,该标准是一套基于以下六项原则的全公司范围的要求:问责制、透明度、公平性、可靠性和安全性、隐私和安全以及包容性。与之前的 Phi-3 模型一样,也采用了多方面的安全评估和安全后训练方法,并采取了额外措施来考虑此版本的多语言功能。我们的安全训练和评估方法(包括跨多种语言和风险类别的测试)概述在Phi-3 安全后训练论文中。虽然 Phi-3 模型受益于这种方法,但开发人员应该应用负责任的 AI 最佳实践,包括映射、衡量和减轻与其特定用例以及文化和语言环境相关的风险。
优化版本
ONNX Runtime为 Phi 系列模型提供优化的推理。您可以使用此 示例在各种硬件目标上优化 Phi-3.5-mini 。请继续关注未来几周内最新 Phi-3.5 模型的更新 ONNX 变体。
更可预测的输出
我们将Guidance引入 Azure AI Studio 中的 Phi-3.5-mini 无服务器端点产品,通过定义针对应用程序量身定制的结构,使输出更加可预测。借助 Guidance,您可以消除昂贵的重试,并且可以例如限制模型从预定义列表(例如医疗代码)中进行选择,将输出限制为来自所提供上下文的直接引语,或遵循任何正则表达式。Guidance 在推理堆栈中逐个引导模型令牌,将成本和延迟降低 30-50%,这使其成为Phi-3-mini 无服务器端点的独特且有价值的附加组件。
结束语
Phi-3.5-mini 已成为 LLM 领域中独一无二的产品,仅拥有 3.8B 参数、128K 上下文长度和多语言支持。Phi-3.5-mini 是创建高效多语言模型的里程碑,在广泛的语言支持和专注于英语的性能之间取得了微妙的平衡。鉴于模型容量较小,用户可能会发现模型中英语知识的密度超过了其他语言。在处理多语言、知识密集型任务时,建议在检索增强生成 (RAG)设置中使用Phi-3.5-mini。此配置可以通过利用外部数据源显著提高模型在不同语言中的性能,从而减轻其紧凑架构所带来的语言特定限制。
Phi-3.5-MoE具有 16 个小型专家,可提供高质量的性能和降低的延迟,支持 128k 上下文长度和多种语言,并具有强大的安全措施。它超越了更大的模型,可以通过微调针对各种应用进行定制,同时保持 6.6B 活动参数的效率。
Phi-3.5-vision在多帧图像理解和推理方面取得了进展,提高了单图像基准测试性能。
Phi -3.5模型系列为开源社区和 Azure 客户提供了经济高效、功能强大的选项,突破了小型语言模型和生成式 AI 的界限。