GAN生成对抗网络
GAN,顾名思义,gan……咳咳,就是干仗嘛(听子豪兄的课讲说这个名字还真的源于中文这个字),对应的就有两方,放在这里就是有两个网络互相对抗互相学习。类比武林高手切磋,都是高手惺惺相惜,打架只分胜负,不决生死,今天你打赢了,我回去总结一下复盘一下,想想怎么应对,明天我打赢了,你又回去总结经验,然后继续打下去。
GAN其实是两个网络的组合,一个是生成器(Generator,后文简称G),一个是判别器(Discriminator,后文简称D),生成器负责生成模拟数据,判别器要保证自己判断的准确。在不断的对抗学习中,生成器要不断优化自己生成的数据让判别器判断不出来,判别器也要优化自己让自己判断的更准确。
在原论文中,作者将生成器比作生产假币的犯罪分子,把判别器比作警察,犯罪分子努力让钞票变得更逼真,警察努力辨别假币,二者不断博弈优化,最终结果是生成器生成的数据判别器根本分不清。
对抗流程
博弈对抗的流程如下所示:
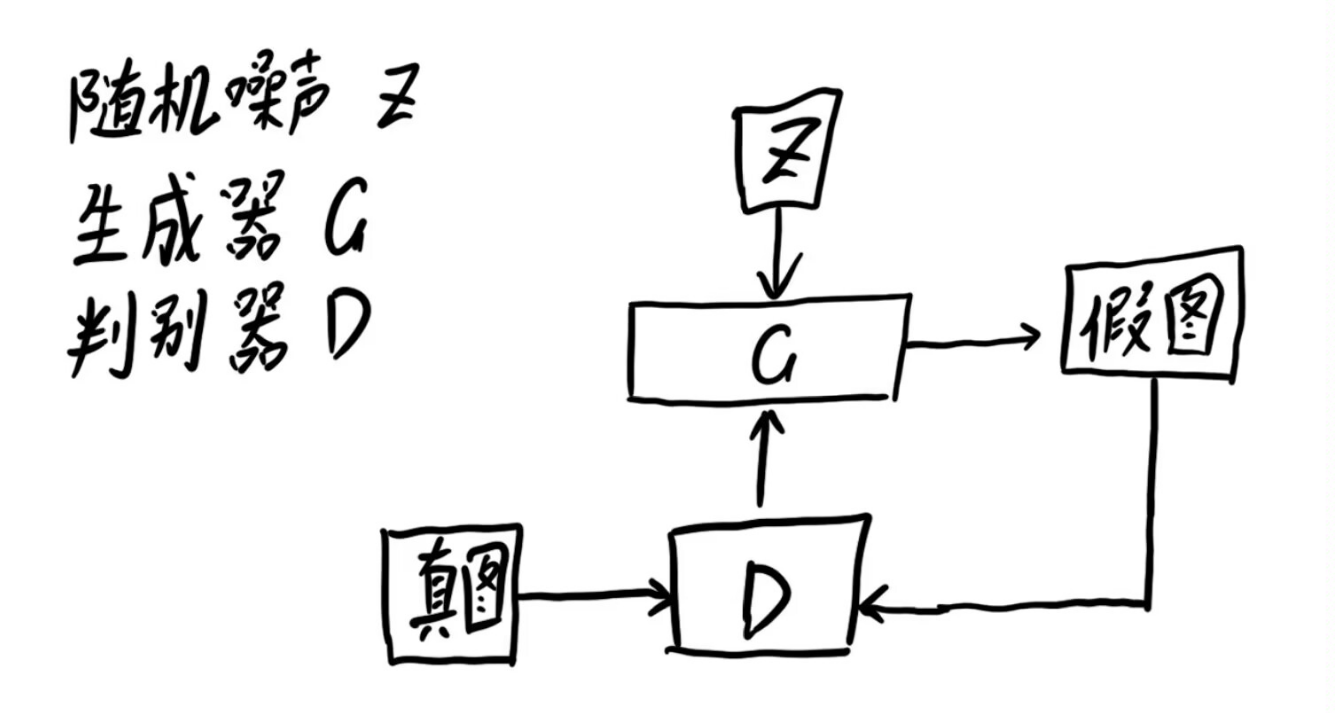
首先生成一组随机噪声,把这组随机噪声传入G,G生成一组假数据,这组假数据和真数据作为输入传入D,然后根据误差来优化判别器,判别器优化完成后,评估真假数据就变得很容易,此时就要反过来优化生成器,之后生成器水平提高了,又要反过来优化判别器,就这样循环往复竞争对抗,直到达到一个动态的均衡(纳什均衡),判别模型再也判断不出结果,准确率为50%,约等于乱猜。
纳什均衡。即存在一组策略(g, d),如果Generator不选择策略g,那么对于Discriminator来说,总存在一种策略使得Generator输得更惨;同样地,将Generator换成Discriminator也成立。
GAN的思想是一种二人零和博弈思想,博弈双方的利益是一个人常数,比如两个部落抢占地盘,总的地盘数就那些,你强一点,你占领的山头就多一些,相应的我的地盘就少一些,相反我的兵马强壮一些,我占领的就更多,但是无论我们抢来抢去,总的山头数就那些。在GAN中,这两方也就是生成器和判别器。
生成器:输入随机噪音生成数据,最终目的是骗过判别器。
判别器:判断这个图像是生成的还是真实的,目的是找出假数据。
全程生成器没有直接使用数据集进行训练,不会产生过拟合风险
损失函数
但生成器如果没有直接使用数据集训练的话,又是如何进行学习的呢,这就涉及了一个优化原理问题。原理是使用独立的损失函数,生成网络和判别网络有了独立的损失函数之后,就可以基于各自的损失函数,利用误差反向传播,实现性能的优化。具体是使用交叉熵损失函数。
生成网络的损失函数:
L G = H ( 1 , D ( G ( z ) ) ) L_G=H(1,D(G(z))) LG=H(1,D(G(z)))
z是随机噪声,H代表交叉熵,G(z)是生成器根据随机噪声生成的数据,D(G(z))是对生成数据的判断概率,1代表绝对真实,0代表绝对虚假。 H ( 1 , D ( G ( z ) ) ) H(1,D(G(z))) H(1,D(G(z))) 代表判断结果与1的距离,很显然,生成器的目的是骗过判别器,即需要让这个判断结果与1的距离啊越小越好。
判别网络的损失函数:
L D = H ( 1 , D ( x ) ) + H ( 0 , D ( G ( z ) ) ) L_D=H(1,D(x))+H(0,D(G(z))) LD=H(1,D(x))+H(0,D(G(z)))
x是真实数据, H ( 1 , D ( x ) ) H(1,D(x)) H(1,D(x))是代表真实数据与1的距离, H ( 0 , D ( G ( z ) ) ) H(0,D(G(z))) H(0,D(G(z))) 代表判断结果与1的距离。判别网络效果要好,意思就是在他眼里,真实数据就是真实数据,假数据就是假数据。进一步说就是真实数据与1的距离尽可能小,假数据与0的距离尽可能小。这就是判别器的损失函数。
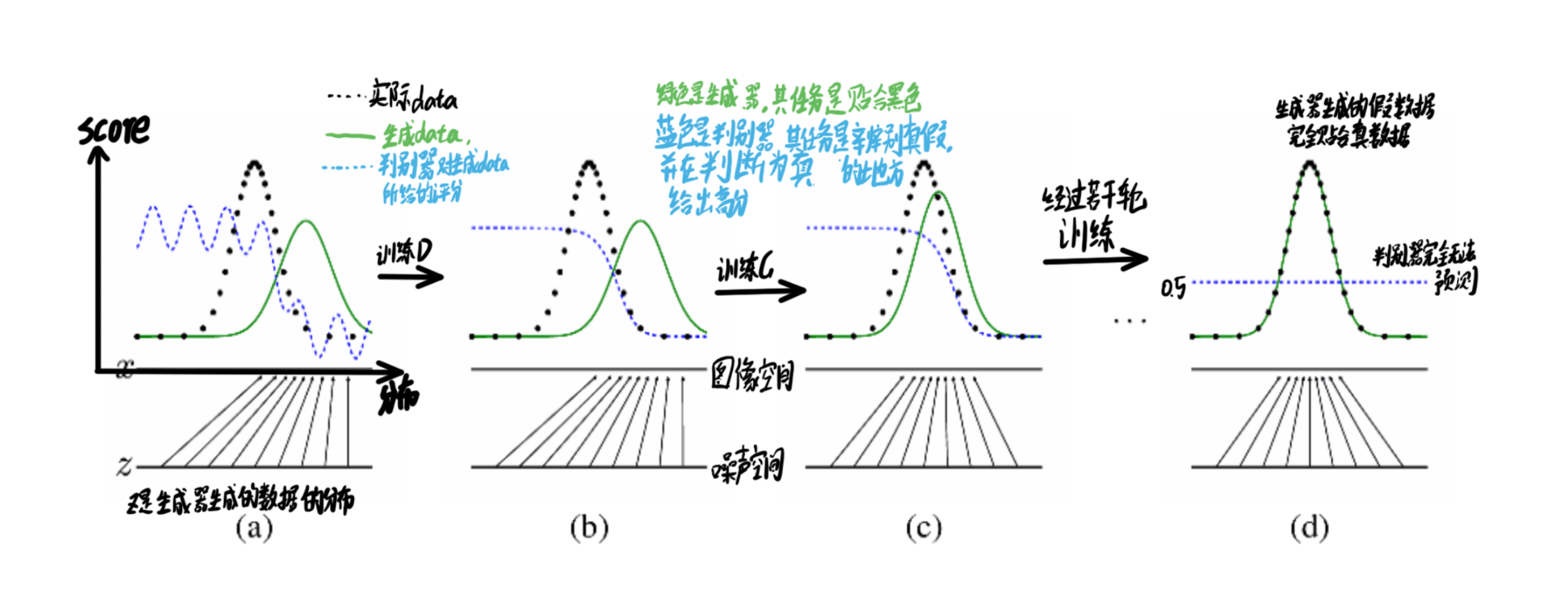
下图是实际博弈对抗的一个过程
公式讲解
直接看一团公式会很头疼,我们拆分开来看

项目实战
下面简单看一下基于MindSpore框架下实现的图像生成项目的代码,文末附出处:
该项目使用MNIST手写数字集,共有70000张手写数字图片,包含60000张训练样本和10000张测试样本,数字图片为二进制文件,图片大小为28*28,单通道。图片已经预先进行了尺寸归一化和中心化处理。
首先我们进行数据集的下载
使用download接口下载数据集,并将下载后的数据集自动解压到当前目录下。数据下载之前需要使用pip install download安装download包。
下载解压后的数据集目录结构如下:
./MNIST_Data/
├─ train
│ ├─ train-images-idx3-ubyte
│ └─ train-labels-idx1-ubyte
└─ test
├─ t10k-images-idx3-ubyte
└─ t10k-labels-idx1-ubyte
数据下载的代码如下:
%%capture captured_output
# 实验环境已经预装了mindspore==2.3.0,如需更换mindspore版本,可更改下面 MINDSPORE_VERSION 变量
!pip uninstall mindspore -y
%env MINDSPORE_VERSION=2.3.0
!pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/${MINDSPORE_VERSION}/MindSpore/unified/aarch64/mindspore-${MINDSPORE_VERSION}-cp39-cp39-linux_aarch64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.mirrors.ustc.edu.cn/simple
# 数据下载
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip"
download(url, ".", kind="zip", replace=True)
数据加载
使用MindSpore自己的MnistDatase接口,读入和解析数据集,并进行一定前处理。
import numpy as np
import mindspore.dataset as ds
# 设置批处理大小和隐码长度
batch_size = 64
latent_size = 100 # 隐码的长度
# 加载MNIST数据集的训练集和测试集
train_dataset = ds.MnistDataset(dataset_dir='./MNIST_Data/train')
test_dataset = ds.MnistDataset(dataset_dir='./MNIST_Data/test')
def data_load(dataset):
"""
加载并预处理数据集。
对输入的数据集进行以下预处理步骤:
1. 使用GeneratorDataset将数据集包装成MindSpore可处理的形式,并设置数据集的列、是否打乱数据顺序、是否使用多进程处理以及采样数量。
2. 对数据集中的图像数据进行类型转换,并为每条数据生成一个随机的隐码。
3. 仅保留处理后的图像和生成的隐码列。
4. 将数据集进行批处理。
参数:
- dataset: 数据集对象,可以是训练集或测试集。
返回:
- mnist_ds: 预处理后的数据集。
"""
# 创建GeneratorDataset对象,指定输出列,设置数据打乱和采样数量
dataset1 = ds.GeneratorDataset(dataset, ["image", "label"], shuffle=True, python_multiprocessing=False, num_samples=10000)
# 数据增强
mnist_ds = dataset1.map(
operations=lambda x: (x.astype("float32"), np.random.normal(size=latent_size).astype("float32")),
output_columns=["image", "latent_code"])
mnist_ds = mnist_ds.project(["image", "latent_code"])
# 批量操作
mnist_ds = mnist_ds.batch(batch_size, True)
return mnist_ds
# 使用训练集加载并预处理数据
mnist_ds = data_load(train_dataset)
# 获取迭代器的大小,即数据集的批次数
iter_size = mnist_ds.get_dataset_size()
print('Iter size: %d' % iter_size)
数据集读进来了之后,我们先拿一部分出来看看长什么样子,做一个可视化操作
通过create_dict_iterator函数将数据转换成字典迭代器,然后使用matplotlib模块可视化部分训练数据。
# 导入matplotlib库的绘图功能
import matplotlib.pyplot as plt
# 获取MNIST数据集的第一个批次的数据
data_iter = next(mnist_ds.create_dict_iterator(output_numpy=True))
# 创建一个3x3英寸的图形对象,用于后续绘制图像
figure = plt.figure(figsize=(3, 3))
# 定义图像网格的行数和列数
cols, rows = 5, 5
# 遍历每个图像,最多绘制25个图像
for idx in range(1, cols * rows + 1):
# 提取当前图像数据,并去除批次维度
image = data_iter['image'][idx]
# 将当前图像添加到图形对象的子图中
figure.add_subplot(rows, cols, idx)
# 关闭图像的坐标轴显示
plt.axis("off")
# 显示图像,使用灰度色彩图
plt.imshow(image.squeeze(), cmap="gray")
# 显示所有图像
plt.show()
我们可以看到这样的结果

为了跟踪生成器的学习进度,我们在训练的过程中的每轮迭代结束后,将一组固定的遵循高斯分布的隐码test_noise输入到生成器中,通过固定隐码所生成的图像效果来评估生成器的好坏。
import random
import numpy as np
from mindspore import Tensor
from mindspore.common import dtype
# 利用随机种子创建一批隐码
np.random.seed(2323)
test_noise = Tensor(np.random.normal(size=(25, 100)), dtype.float32)
random.shuffle(test_noise)
模型构建
本案例实现中所搭建的 GAN 模型结构与原论文中提出的 GAN 结构大致相同,但由于所用数据集 MNIST 为单通道小尺寸图片,可识别参数少,便于训练,我们在判别器和生成器中采用全连接网络架构和 ReLU 激活函数即可达到令人满意的效果,且省略了原论文中用于减少参数的 Dropout 策略和可学习激活函数 Maxout。
生成器
生成器 Generator 的功能是将隐码映射到数据空间。由于数据是图像,这一过程也会创建与真实图像大小相同的灰度图像(或 RGB 彩色图像)。在本案例演示中,该功能通过五层 Dense 全连接层来完成的,每层都与 BatchNorm1d 批归一化层和 ReLU 激活层配对,输出数据会经过 Tanh 函数,使其返回 [-1,1] 的数据范围内。注意实例化生成器之后需要修改参数的名称,不然静态图模式下会报错。
from mindspore import nn
import mindspore.ops as ops
img_size = 28 # 训练图像长(宽)
class Generator(nn.Cell):
def __init__(self, latent_size, auto_prefix=True):
super(Generator, self).__init__(auto_prefix=auto_prefix)
self.model = nn.SequentialCell()
# [N, 100] -> [N, 128]
# 输入一个100维的0~1之间的高斯分布,然后通过第一层线性变换将其映射到256维
self.model.append(nn.Dense(latent_size, 128))
self.model.append(nn.ReLU())
# [N, 128] -> [N, 256]
self.model.append(nn.Dense(128, 256))
self.model.append(nn.BatchNorm1d(256))
self.model.append(nn.ReLU())
# [N, 256] -> [N, 512]
self.model.append(nn.Dense(256, 512))
self.model.append(nn.BatchNorm1d(512))
self.model.append(nn.ReLU())
# [N, 512] -> [N, 1024]
self.model.append(nn.Dense(512, 1024))
self.model.append(nn.BatchNorm1d(1024))
self.model.append(nn.ReLU())
# [N, 1024] -> [N, 784]
# 经过线性变换将其变成784维
self.model.append(nn.Dense(1024, img_size * img_size))
# 经过Tanh激活函数是希望生成的假的图片数据分布能够在-1~1之间
self.model.append(nn.Tanh())
def construct(self, x):
img = self.model(x)
return ops.reshape(img, (-1, 1, 28, 28))
net_g = Generator(latent_size)
net_g.update_parameters_name('generator')
判别器
判别器 Discriminator 是一个二分类网络模型,输出判定该图像为真实图的概率。主要通过一系列的 Dense 层和 LeakyReLU 层对其进行处理,最后通过 Sigmoid 激活函数,使其返回 [0, 1] 的数据范围内,得到最终概率。注意实例化判别器之后需要修改参数的名称,不然静态图模式下会报错。
# 判别器
class Discriminator(nn.Cell):
def __init__(self, auto_prefix=True):
super().__init__(auto_prefix=auto_prefix)
self.model = nn.SequentialCell()
# [N, 784] -> [N, 512]
self.model.append(nn.Dense(img_size * img_size, 512)) # 输入特征数为784,输出为512
self.model.append(nn.LeakyReLU()) # 默认斜率为0.2的非线性映射激活函数
# [N, 512] -> [N, 256]
self.model.append(nn.Dense(512, 256)) # 进行一个线性映射
self.model.append(nn.LeakyReLU())
# [N, 256] -> [N, 1]
self.model.append(nn.Dense(256, 1))
self.model.append(nn.Sigmoid()) # 二分类激活函数,将实数映射到[0,1]
def construct(self, x):
x_flat = ops.reshape(x, (-1, img_size * img_size))
return self.model(x_flat)
net_d = Discriminator()
net_d.update_parameters_name('discriminator')
损失函数
在开始的理论讲解中我们也说了, 主要采用交叉熵损失函数,,优化器都使用Adam,但是需要构建两个不同名称的优化器,用于分别更新两个模型的参数。
lr = 0.0002 # 学习率
# 损失函数
adversarial_loss = nn.BCELoss(reduction='mean')
# 优化器
optimizer_d = nn.Adam(net_d.trainable_params(), learning_rate=lr, beta1=0.5, beta2=0.999)
optimizer_g = nn.Adam(net_g.trainable_params(), learning_rate=lr, beta1=0.5, beta2=0.999)
optimizer_g.update_parameters_name('optim_g')
optimizer_d.update_parameters_name('optim_d')
模型训练
需要注意的是我们有两个模型,需要分别训练。
第一部分是训练判别器。训练判别器的目的是最大程度地提高判别图像真伪的概率。按照原论文的方法,通过提高其随机梯度来更新判别器,最大化 𝑙𝑜𝑔𝐷(𝑥)+𝑙𝑜𝑔(1−𝐷(𝐺(𝑧))logD(x)+log(1−D(G(z)) 的值。
第二部分是训练生成器。如论文所述,最小化 𝑙𝑜𝑔(1−𝐷(𝐺(𝑧)))log(1−D(G(z))) 来训练生成器,以产生更好的虚假图像。
在这两个部分中,分别获取训练过程中的损失,并在每轮迭代结束时进行测试,将隐码批量推送到生成器中,以直观地跟踪生成器 Generator 的训练效果。
import os
import time
import matplotlib.pyplot as plt
import mindspore as ms
from mindspore import Tensor, save_checkpoint
total_epoch = 12 # 训练周期数
batch_size = 64 # 用于训练的训练集批量大小
# 加载预训练模型的参数
pred_trained = False
pred_trained_g = './result/checkpoints/Generator99.ckpt'
pred_trained_d = './result/checkpoints/Discriminator99.ckpt'
checkpoints_path = "./result/checkpoints" # 结果保存路径
image_path = "./result/images" # 测试结果保存路径
# 使用时间魔术命令来测量代码的运行时间
%%time
# 定义生成器的损失计算函数
def generator_forward(test_noises):
"""
计算生成器的损失。
参数:
test_noises - 输入生成器的随机噪声。
返回:
loss_g - 生成器的损失。
"""
# 生成假数据
fake_data = net_g(test_noises)
# 计算假数据在判别器中的输出
fake_out = net_d(fake_data)
# 计算生成器的损失
loss_g = adversarial_loss(fake_out, ops.ones_like(fake_out))
return loss_g
# 定义判别器的损失计算函数
def discriminator_forward(real_data, test_noises):
"""
计算判别器的损失。
参数:
real_data - 真实的数据样本。
test_noises - 输入生成器的随机噪声。
返回:
loss_d - 判别器的损失。
"""
# 生成假数据
fake_data = net_g(test_noises)
# 计算假数据和真实数据在判别器中的输出
fake_out = net_d(fake_data)
real_out = net_d(real_data)
# 计算判别器对真实和假数据的损失,并求和
real_loss = adversarial_loss(real_out, ops.ones_like(real_out))
fake_loss = adversarial_loss(fake_out, ops.zeros_like(fake_out))
loss_d = real_loss + fake_loss
return loss_d
# 使用MindSpore的梯度方法,计算损失函数关于网络参数的梯度
grad_g = ms.value_and_grad(generator_forward, None, net_g.trainable_params())
grad_d = ms.value_and_grad(discriminator_forward, None, net_d.trainable_params())
# 定义训练步骤函数
def train_step(real_data, latent_code):
"""
执行一个训练步骤,更新生成器和判别器的参数。
参数:
real_data - 真实的数据样本。
latent_code - 输入生成器的潜伏向量。
返回:
loss_d - 判别器的损失。
loss_g - 生成器的损失。
"""
# 计算并应用判别器的梯度
loss_d, grads_d = grad_d(real_data, latent_code)
optimizer_d(grads_d)
# 计算并应用生成器的梯度
loss_g, grads_g = grad_g(latent_code)
optimizer_g(grads_g)
return loss_d, loss_g
# 定义保存生成图像的函数
def save_imgs(gen_imgs1, idx):
"""
保存生成的测试图像。
参数:
gen_imgs1 - 生成的图像数组。
idx - 图像的索引,用于命名文件。
"""
for i3 in range(gen_imgs1.shape[0]):
plt.subplot(5, 5, i3 + 1)
plt.imshow(gen_imgs1[i3, 0, :, :] / 2 + 0.5, cmap="gray")
plt.axis("off")
plt.savefig(image_path + "/test_{}.png".format(idx))
# 创建参数保存目录,如果不存在的话
os.makedirs(checkpoints_path, exist_ok=True)
# 创建生成图像保存目录,如果不存在的话
os.makedirs(image_path, exist_ok=True)
# 设置生成器和判别器为训练模式
net_g.set_train()
net_d.set_train()
# 初始化存储生成器和判别器损失的列表
losses_g, losses_d = [], []
# 开始训练循环
for epoch in range(total_epoch):
start = time.time()
for (iter, data) in enumerate(mnist_ds):
start1 = time.time()
image, latent_code = data
# 数据预处理:将像素值从[0, 255]归一化到[-1, 1]
image = (image - 127.5) / 127.5
image = image.reshape(image.shape[0], 1, image.shape[1], image.shape[2])
# 执行一个训练步骤
d_loss, g_loss = train_step(image, latent_code)
end1 = time.time()
# 每10个步骤打印一次训练信息
if iter % 10 == 10:
print(f"Epoch:[{int(epoch):>3d}/{int(total_epoch):>3d}], "
f"step:[{int(iter):>4d}/{int(iter_size):>4d}], "
f"loss_d:{d_loss.asnumpy():>4f} , "
f"loss_g:{g_loss.asnumpy():>4f} , "
f"time:{(end1 - start1):>3f}s, "
f"lr:{lr:>6f}")
end = time.time()
# 打印每个epoch的总时间
print("time of epoch {} is {:.2f}s".format(epoch + 1, end - start))
# 记录损失
losses_d.append(d_loss.asnumpy())
losses_g.append(g_loss.asnumpy())
# 每个epoch结束后生成并保存一组图像
gen_imgs = net_g(test_noise)
save_imgs(gen_imgs.asnumpy(), epoch)
# 每个epoch保存模型权重
if epoch % 1 == 0:
save_checkpoint(net_g, checkpoints_path + "/Generator%d.ckpt" % (epoch))
save_checkpoint(net_d, checkpoints_path + "/Discriminator%d.ckpt" % (epoch))
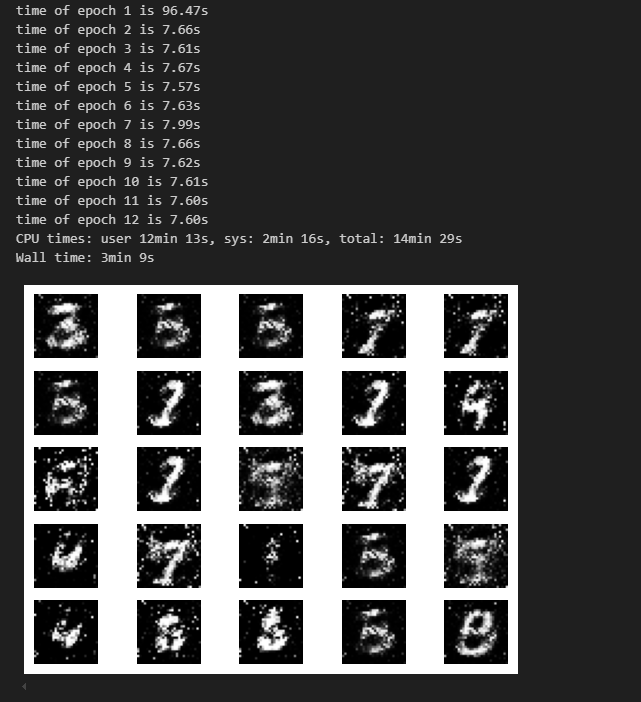
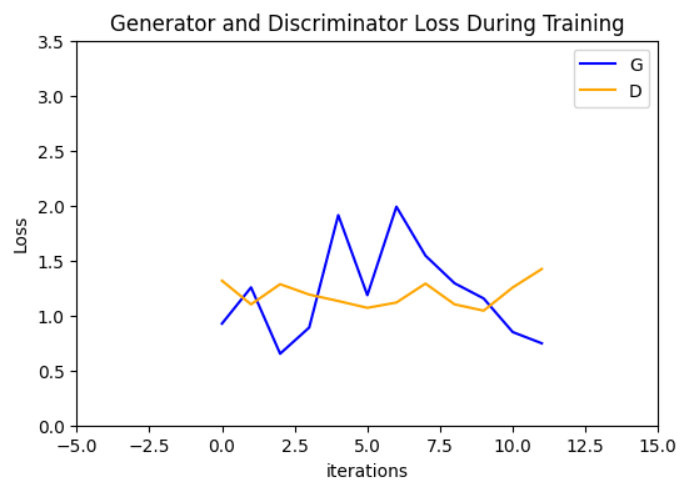
效果展示
plt.figure(figsize=(6, 4))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(losses_g, label="G", color='blue')
plt.plot(losses_d, label="D", color='orange')
plt.xlim(-5,15)
plt.ylim(0, 3.5)
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
可视化训练过程中通过隐向量生成的图像。
import cv2
import matplotlib.animation as animation
import matplotlib.pyplot as plt
# 将训练过程中生成的测试图转为动态图
image_list = []
# 读取每个训练周期生成的测试图像,假设每个周期都生成一个测试图像
for i in range(total_epoch):
# 使用opencv库读取图像,这里指定读取灰度图以符合特定需求
image_list.append(cv2.imread(image_path + "/test_{}.png".format(i), cv2.IMREAD_GRAYSCALE))
show_list = []
# 初始化Matplotlib的图形对象,设置分辨率以适应动态图的生成
fig = plt.figure(dpi=70)
# 遍历读取的图像列表,每隔5个epoch的图像添加到动态图的显示列表中
for epoch in range(0, len(image_list), 5):
# 关闭坐标轴显示,因为动态图中不需要显示坐标轴
plt.axis("off")
# 将图像添加到动态图显示列表,使用灰度图谱绘制
show_list.append([plt.imshow(image_list[epoch], cmap='gray')])
# 创建动态图对象,设置播放间隔和重复间隔,启用blit优化性能
ani = animation.ArtistAnimation(fig, show_list, interval=1000, repeat_delay=1000, blit=True)
# 保存动态图为GIF格式,使用'pillow'库作为writer,设置帧频为1fps
ani.save('train_test.gif', writer='pillow', fps=1)

模型推理
通过加载生成器网络模型参数文件来生成图像
import mindspore as ms
test_ckpt = './result/checkpoints/Generator11.ckpt'
parameter = ms.load_checkpoint(test_ckpt)
ms.load_param_into_net(net_g, parameter)
# 模型生成结果
test_data = Tensor(np.random.normal(0, 1, (25, 100)).astype(np.float32))
images = net_g(test_data).transpose(0, 2, 3, 1).asnumpy()
# 结果展示
fig = plt.figure(figsize=(3, 3), dpi=120)
for i in range(25):
fig.add_subplot(5, 5, i + 1)
plt.axis("off")
plt.imshow(images[i].squeeze(), cmap="gray")
plt.show()11

参考资料:生成对抗网络GAN开山之作论文精读_哔哩哔哩_bilibili
[图解 生成对抗网络GAN 原理 超详解_gan原理图-CSDN博客](https://blog.csdn.net/DFCED/article/details/105175097#:~:text=生成式对抗网络(GAN, Generative Adversarial Networks)
[GAN(生成对抗网络)的系统全面介绍(醍醐灌顶)-CSDN博客](https://blog.csdn.net/m0_61878383/article/details/122462196#:~:text=GAN 的全称是 G)
适合小白学习的GAN(生成对抗网络)算法超详细解读_gan网络-CSDN博客
万字详解什么是生成对抗网络GAN - 知乎 (zhihu.com)
GAN图像生成.ipynb - JupyterLab (mindspore.cn)
络)的系统全面介绍(醍醐灌顶)-CSDN博客](https://blog.csdn.net/m0_61878383/article/details/122462196#:~:text=GAN 的全称是 G)
适合小白学习的GAN(生成对抗网络)算法超详细解读_gan网络-CSDN博客
万字详解什么是生成对抗网络GAN - 知乎 (zhihu.com)