最近发现了一篇效果很好的ICCV新论文,讲的是一种基于GAN的Transformer模型ActFormer,该模型不仅实现了SOTA性能,也拥有较强的适应性,在单人动作生成任务中达到了99.9%的动作识别准确率。
这类模型采用了Transformer+GAN的组合策略,利用了Transformer的序列建模能力来增强GAN的生成能力,可以给我们提供更加高质量、多样化的数据样本,实现更高的计算效率以及更好的解释性。
也正因这些优势,这种强大的技术组合如今已经被广泛应用于多种场景,比如图像生成、文本生成、语音合成等。本文整理了10种Transformer结合GAN的创新方案供各位参考,开源代码基本都有,方便大家复现。
论文原文+开源代码需要的同学看文末
ActFormer: A GAN-based Transformer towards General Action-Conditioned 3D Human Motion Generation
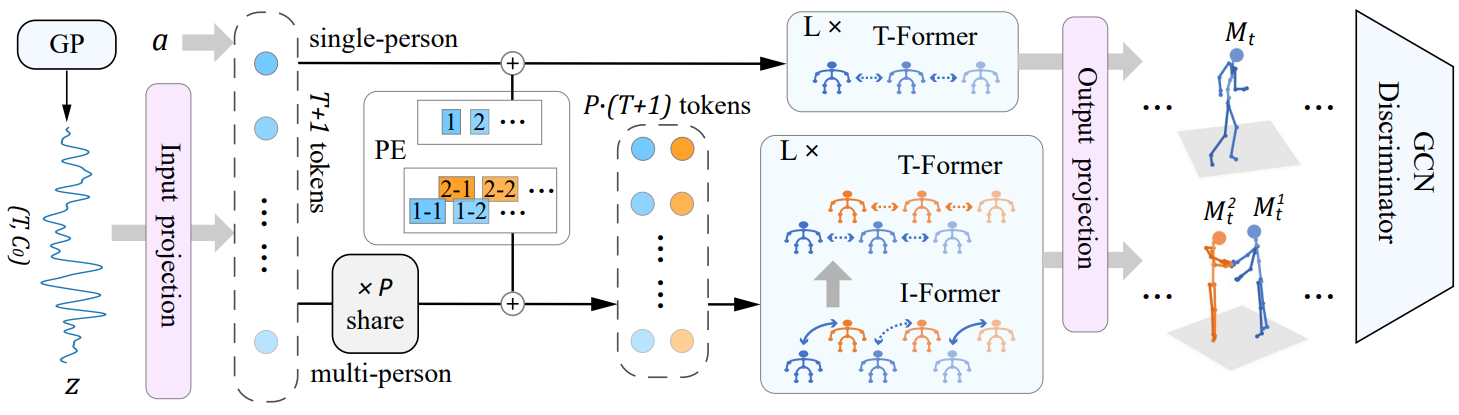
方法:论文提出了一种基于GAN的Transformer框架——Act-Former,用于生成单人和多人互动的动作。方法结合了Transformer的时空表示能力、GAN的生成建模优势以及高斯过程潜在先验的时间相关性。多个基准数据集上的实验证明Act-Former在动作生成任务中表现优异。
创新点:
提出了一个基于GAN和Transformer的模型,能够根据动作标签生成3D人体动作。
模型能够处理多人动作生成,包括交互动作,这是通过共享潜在向量序列和位置编码来实现的。
为了更好地研究多人动作生成,作者贡献了一个包含复杂多人交互动作的新数据集。

Integrated visual transformer and fash attention for lip‑to‑speech generation GAN
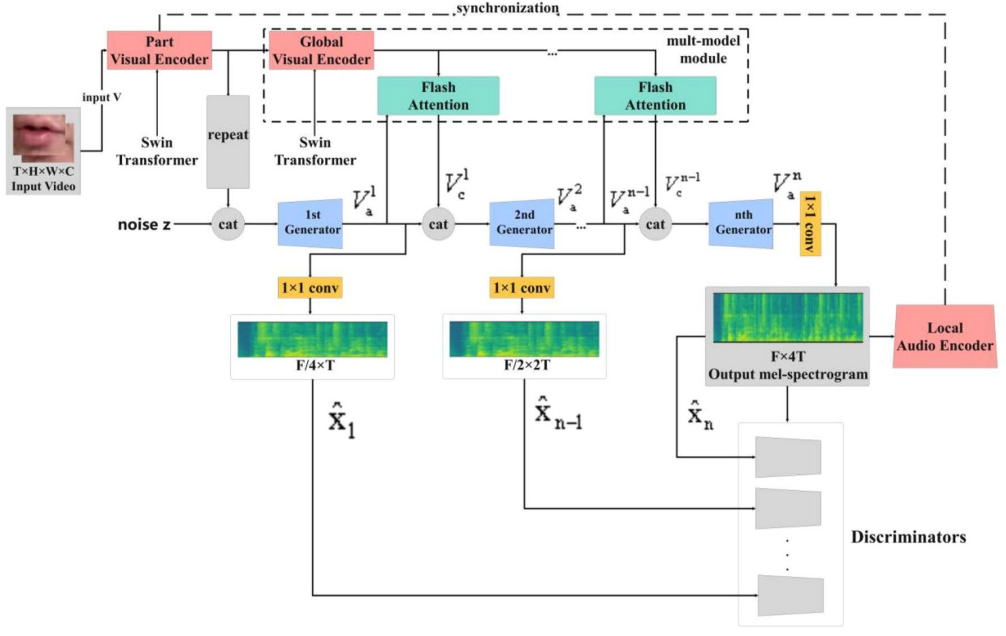
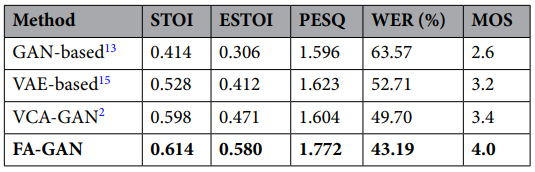
方法:作者设计了一个名为FA-GAN的深度架构,它结合了视觉Transformer和闪存注意力机制,用于唇语到语音生成。该方法通过引入Swin Transformer提升图像表示质量,使用分层迭代生成器优化语音合成过程,并通过闪存注意力机制减少计算负担。
创新点:
FA-GAN通过分别编码视觉和音频信息,并联合建模唇部运动,以提高语音识别的准确性。
为了改善图像表示,引入了多级Swin Transformer来提取图像特征,并采用Flash Attention机制来提高计算效率。
FA-GAN使用层次迭代生成器来优化语音生成过程,使模型能够更专注于不同音频阶段的特征,从而提高识别率。
TOR-GAN: A Transformer-Based OFDM Signals Reconstruction GAN
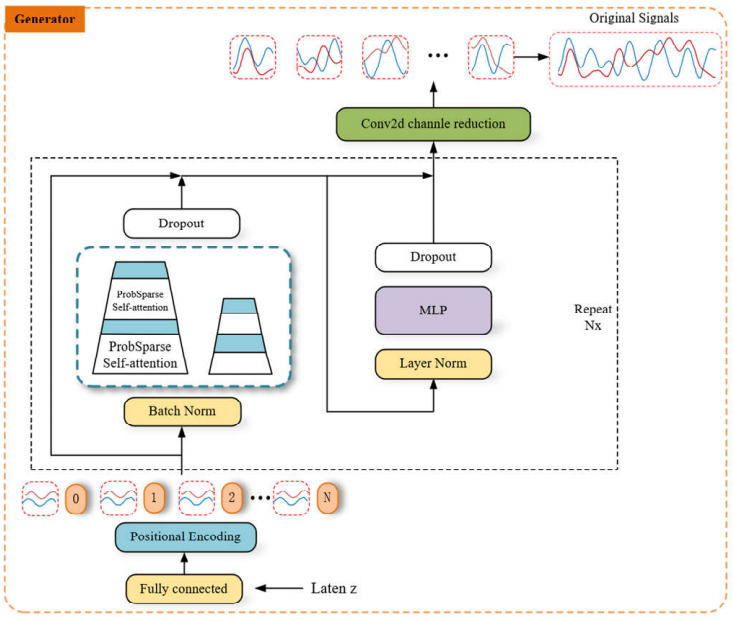
方法:文章提出了一种基于Transformer的生成对抗网络(GAN),名为TOR-GAN,用于重建OFDM(正交频分复用)信号,通过将IQ序列视为二维图像进行处理,采用概率稀疏注意力机制替代多头注意力,优化生成器和判别器的参数及时间复杂度。
创新点:
首次将Transformer模型用于OFDM信号的重建,提高了信号重建的准确性。
在模型中引入概率稀疏自注意力机制,降低了模型的计算复杂度。
构建了一套信号重建质量的评估体系,能够更全面地评价重建信号的性能。

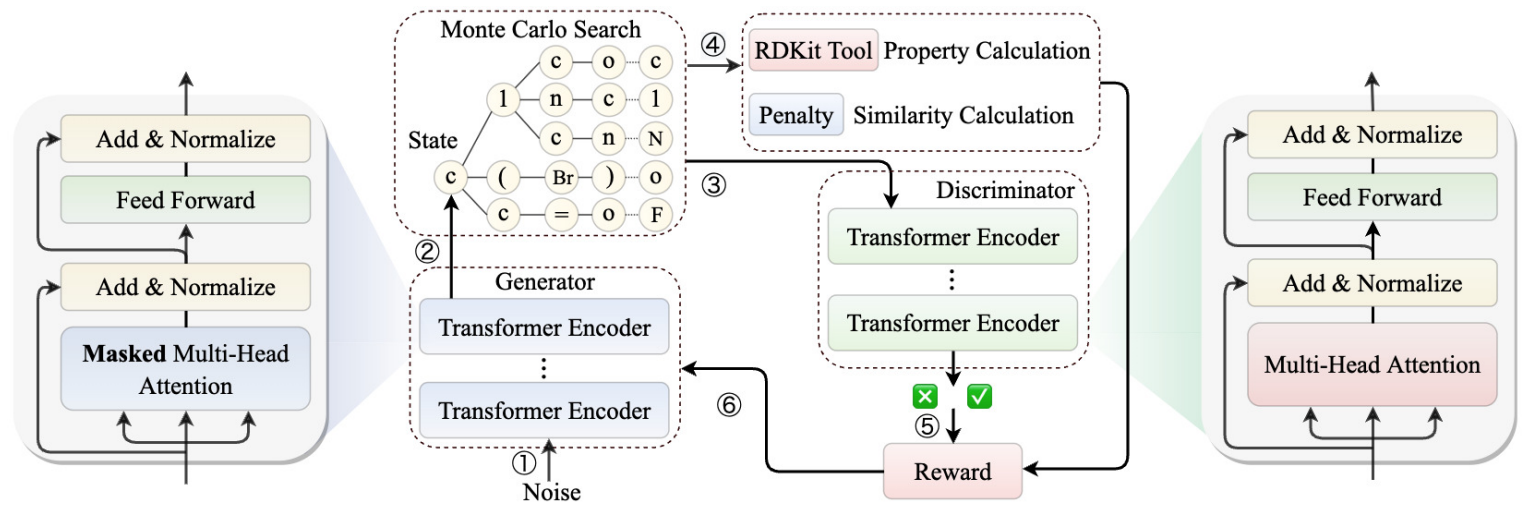
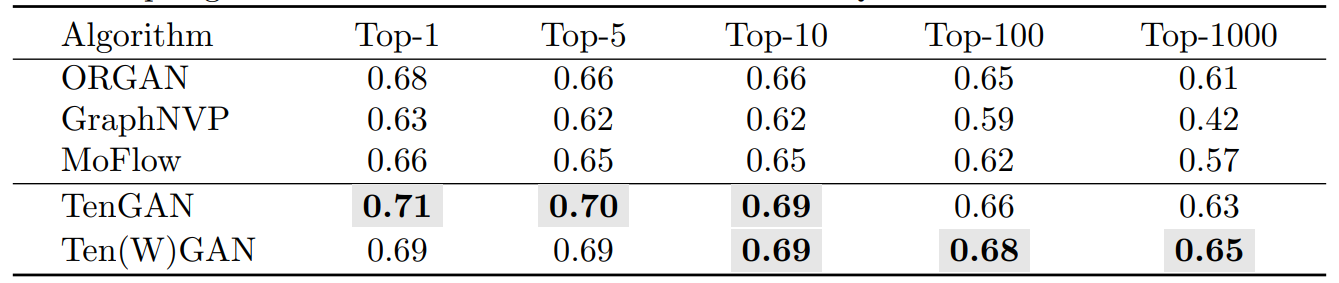
TenGAN: Pure Transformer Encoders Make an Efficient Discrete GAN for De Novo Molecular Generation
方法:论文提出了一种基于纯Transformer编码器的生成对抗网络(GAN),名为TenGAN,用于从头开始生成具有所需化学属性的新分子。此外,作者还介绍了TenGAN的增强版本Ten(W)GAN,它结合了小批量歧视和Wasserstein GAN来提高生成分子的能力。
创新点:
首次将Transformer编码器与GAN结合用于分子生成,提出了TenGAN和Ten(W)GAN模型。
通过引入变体SMILES和小批量歧视,有效提高生成器学习语义和句法特征的能力。此外,WGAN的使用解决了生成器和判别器之间的训练不平衡问题,显著缓解了训练不稳定性。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“GAN创新”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏