1.项目背景
随着智能手机的快速发展,消费者对智能手机的使用行为和习惯也日趋多样化。特别是在5G时代的到来和各类应用的丰富发展背景下,智能手机使用模式呈现出新的特点,本项目使用模拟生成的700位用户智能手机使用数据进行深入分析,探索不同用户群体的使用行为特征,了解影响用户行为分类的关键因素,这不仅有助于理解用户的使用习惯,还可以为手机制造商优化产品设计、运营商制定更智能的流量套餐方案提供数据支持。同时,通过建立预测模型,可以更好地预判用户的行为类别和数据流量需求,为提供个性化服务奠定基础。需要说明的是,本项目使用的是模拟数据集,主要用于数据分析方法的实践和演示,分析结果仅供参考。
2.数据说明
| 字段 | 说明 |
|---|---|
| User ID | 每个用户的唯一标识符 |
| Device Model | 用户智能手机的型号 |
| Operating System | 设备的操作系统(iOS 或 Android) |
| App Usage Time (min/day) | 每天在移动应用上花费的时间(单位:分钟) |
| Screen On Time (hours/day) | 屏幕每天平均活跃时间(单位:小时) |
| Battery Drain (mAh/day) | 每日电池消耗量(单位:毫安时) |
| Number of Apps Installed | 设备上安装的应用程序总数 |
| Data Usage (MB/day) | 每日移动数据消耗量(单位:兆字节) |
| Age | 用户年龄 |
| Gender | 用户性别(男或女) |
| User Behavior Class | 基于使用模式对用户行为进行分类(1 至 5) |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import chi2_contingency,spearmanr,kruskal
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import classification_report,mean_squared_error, r2_score,mean_absolute_error
data = pd.read_csv("/home/mw/input/10241726/user_behavior_dataset.csv")
4.数据预览
查看重复值:0

数据特别干净,不存在缺失值、异常值,并且使用的手机型号只有5类,每类都是不同的品牌,这里就不提取手机品牌了。
5.描述性分析

样本量:总共有700个用户记录。
用户年龄:平均年龄为38.48岁,范围从18岁到59岁。
性别分布:男性占364人,女性占336人,性别分布相对均衡。
应用使用时间:用户平均每天在移动应用上花费271.13分钟,最低30分钟,最高598分钟。
屏幕开启时间:平均每天屏幕开启时间为5.27小时,最低1小时,最高12小时。
电池消耗:平均每日电池消耗为1525.16毫安时,最低302毫安时,最高2993毫安时。
安装应用数量:平均每台设备安装50.68个应用,范围从10个到99个。
每日数据消耗:用户平均每日移动数据消耗为929.74 MB,最低102 MB,最高2497 MB。
用户行为分类:用户行为根据使用模式被分类为1到5,分布相对均匀,2类最多,1类和5类最少,但是也与最多类仅相差10人。
设备型号:共有5种设备型号,分布比较均匀,小米11和iPhone 12最多。
操作系统:以Android系统为主,占554次。
6.划分用户的影响因素分析
6.1可视化分析
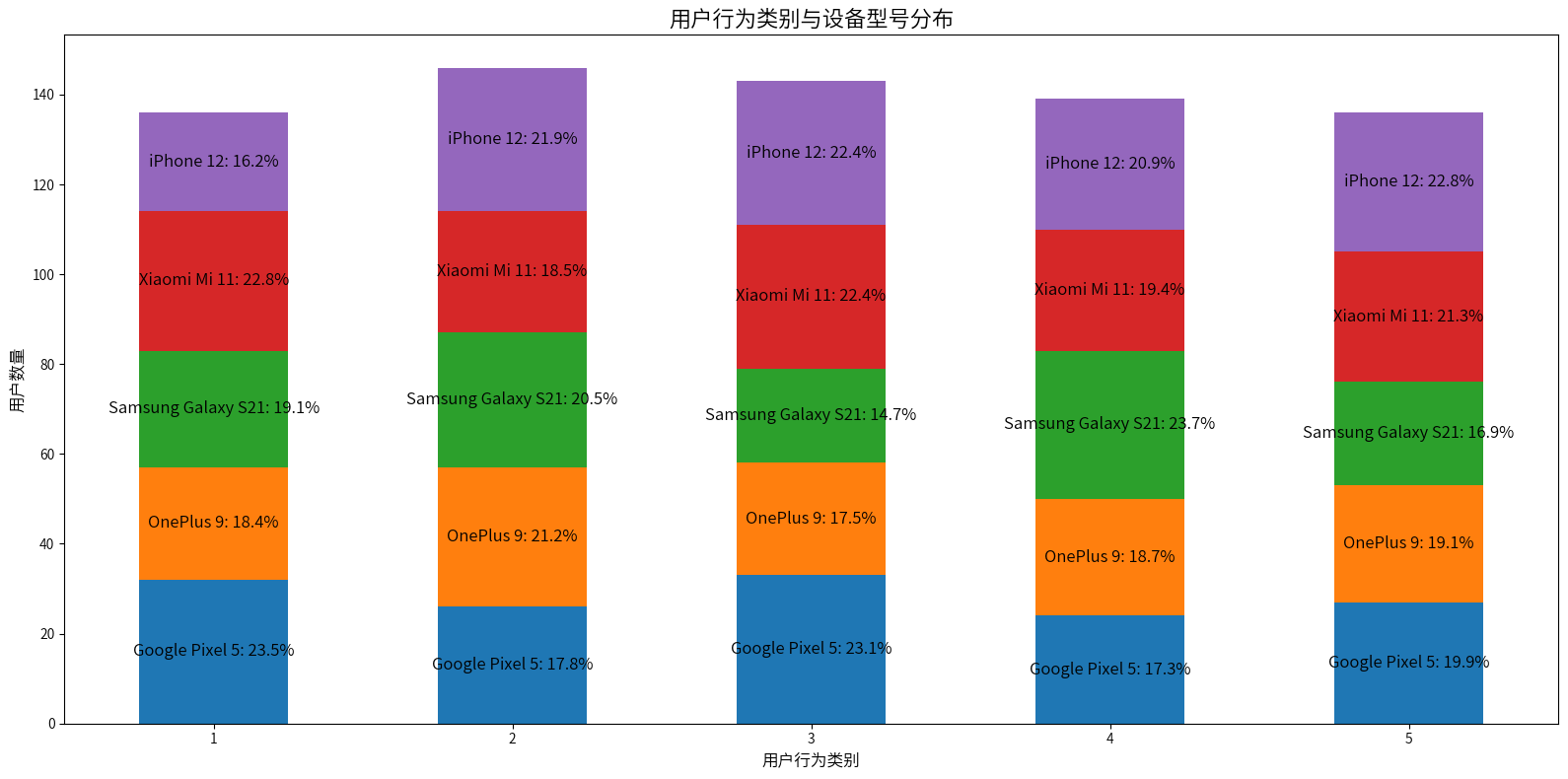
1类用户使用谷歌和小米的比较多,2类用户使用三星、苹果和一加的比较多,3类用户使用苹果、小米、谷歌的比较多,4类用户使用三星的占比最大,5类用户使用苹果占比最大,三星占比最小,其他三类相差不大,总的来说,设备型号可能是划分用户类别的因素之一,但是并不明显,需要通过后续的统计检验,才能更有力的说明是否真的是影响因素之一。
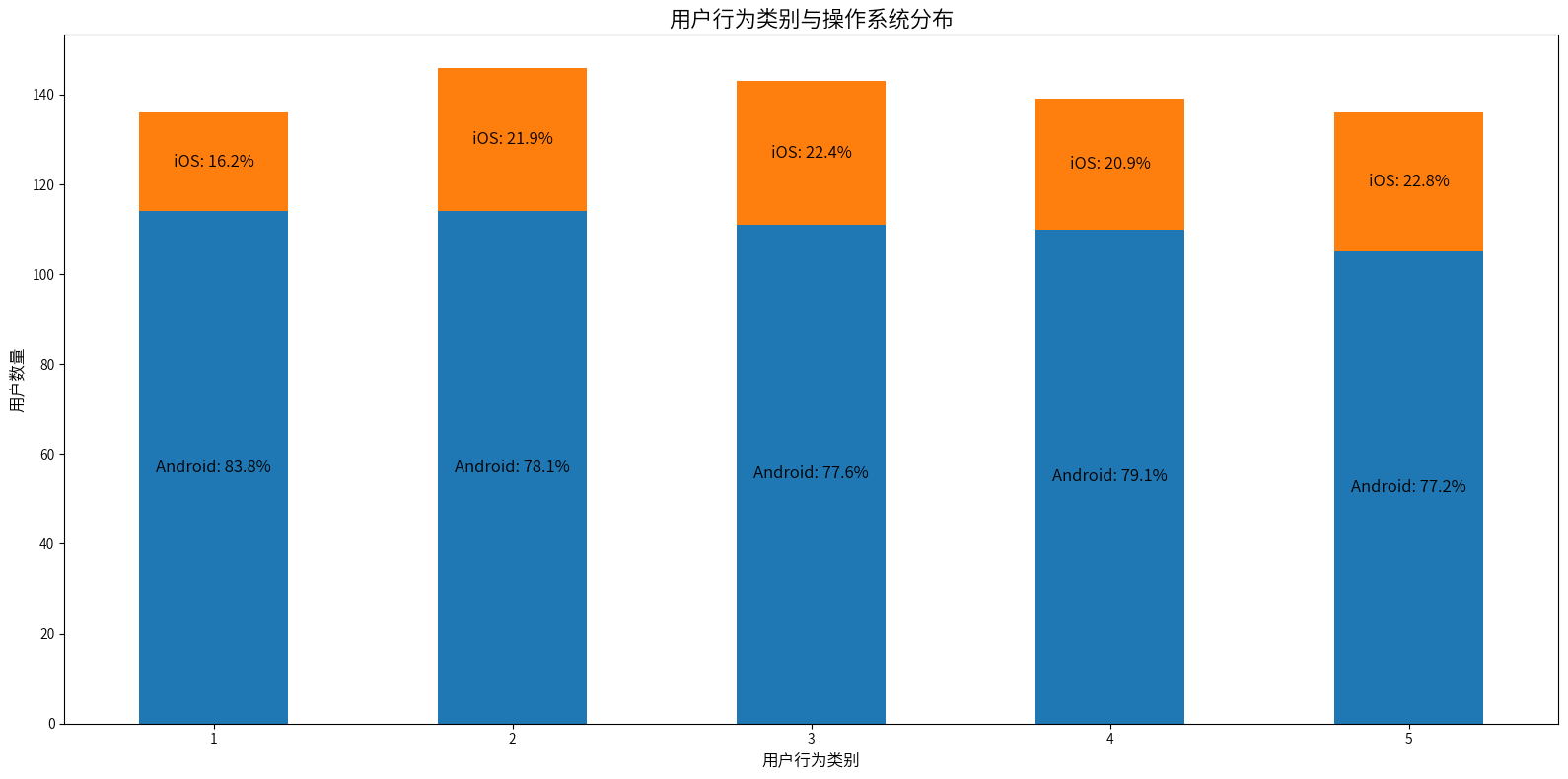
由于数据中,5类品牌手机,有4类是安卓系统的,导致每一类都是安卓使用的最多,但是也符合之前的分析,当使用苹果手机的用户占比比较大的时候,对应的iOS系统占比也比较大,所以1类用户的iOS系统占比最小,其他4类用户占比相差不算很大,同样的无法明确得出手机系统是否是划分用户行为类别的因素之一,还需要通过统计检验来证明。
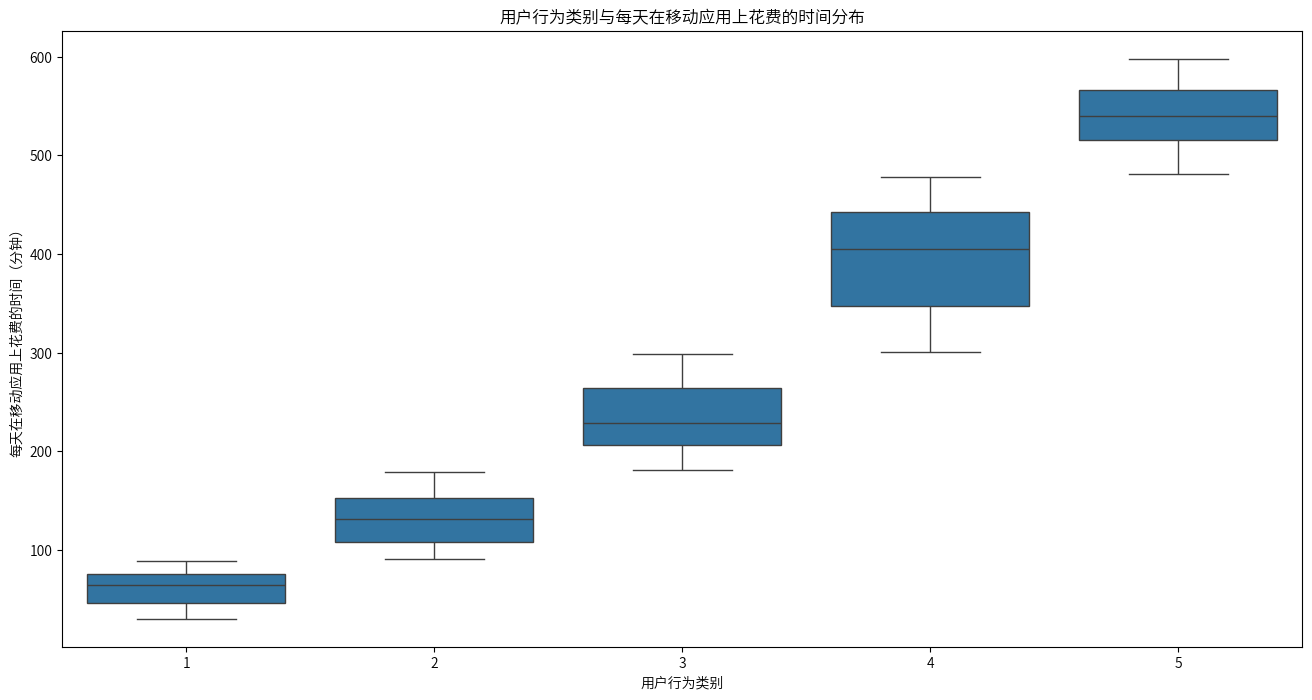
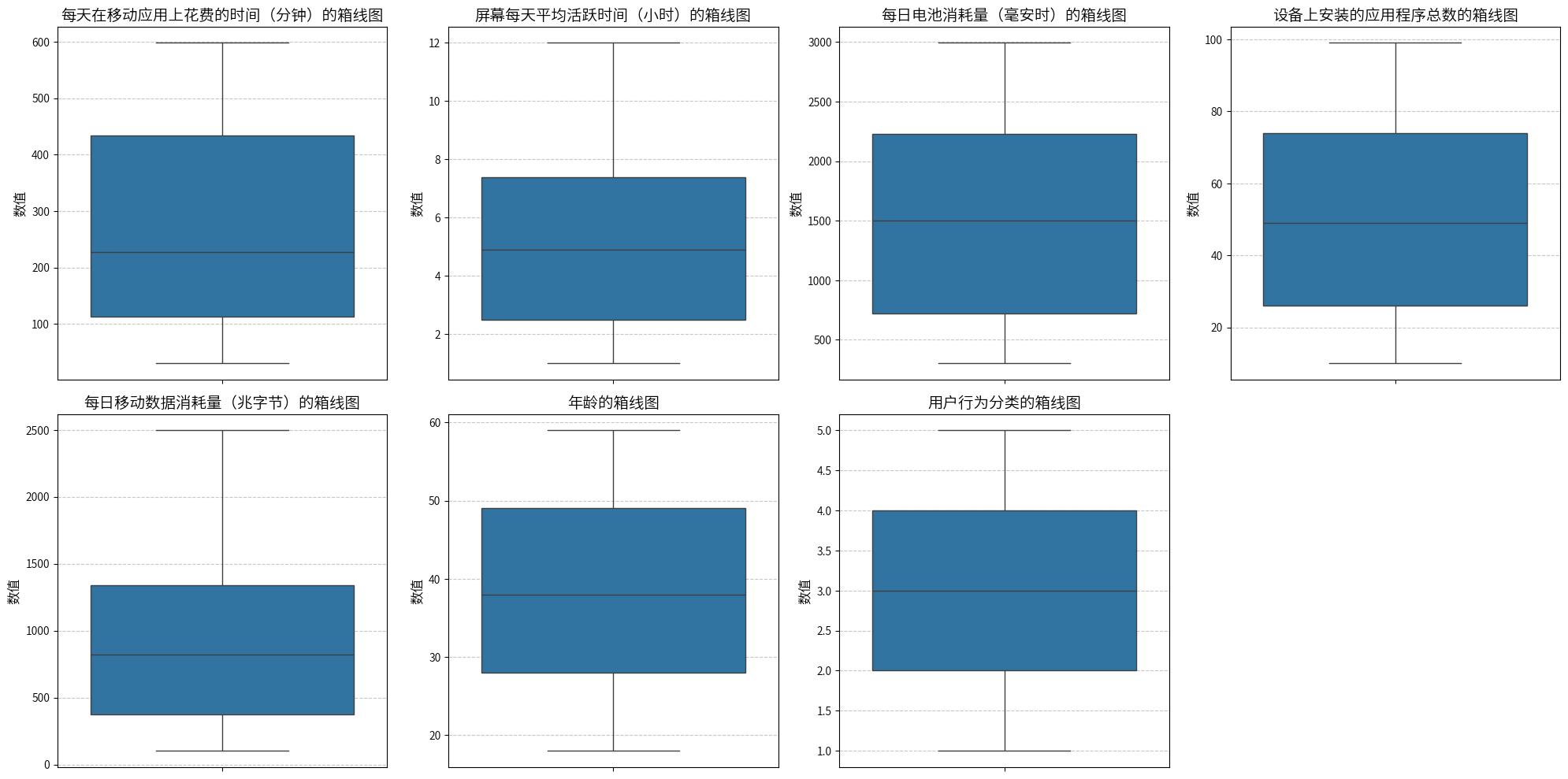
可以看到,1类用户到5类用户,每天在移动应用上花费的时间是显著增多的,可以确定每天在移动应用上花费的时间是划分用户类别的主要因素之一。
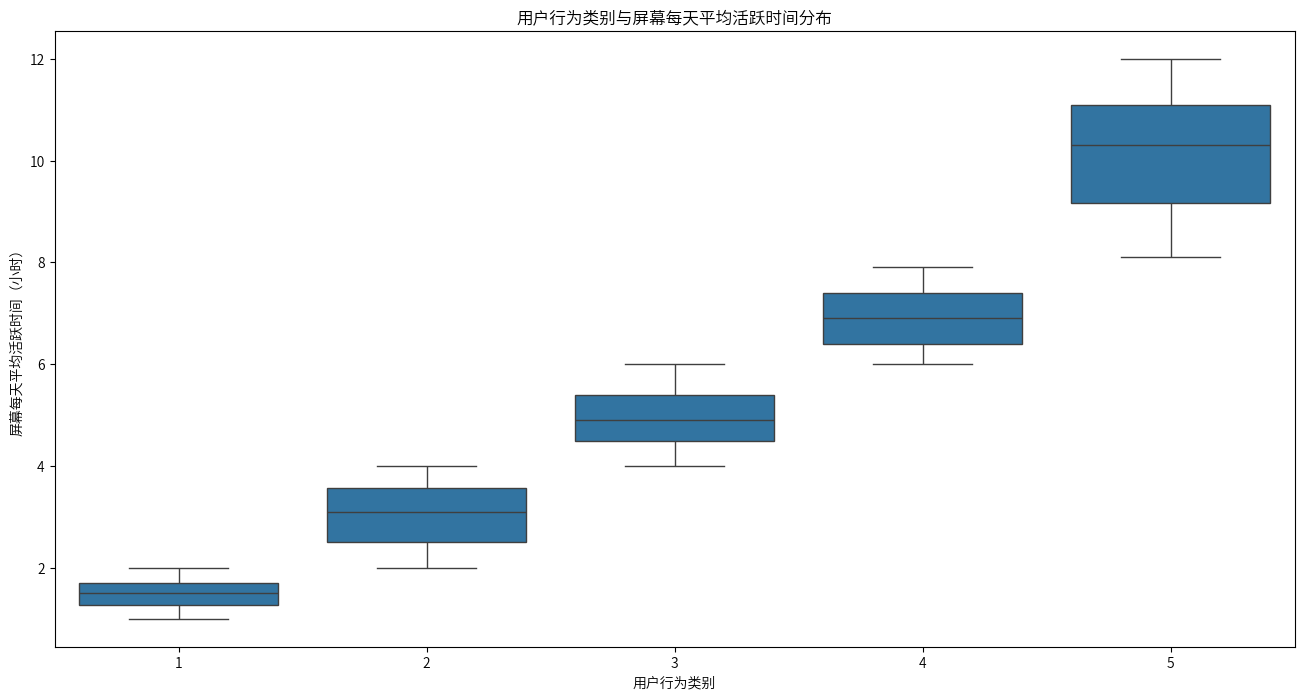
同样的,1类用户到5类用户,屏幕每天平均活跃时间也是显著增多的,可以确定屏幕每天平均活跃时间是划分用户类别的主要因素之一。
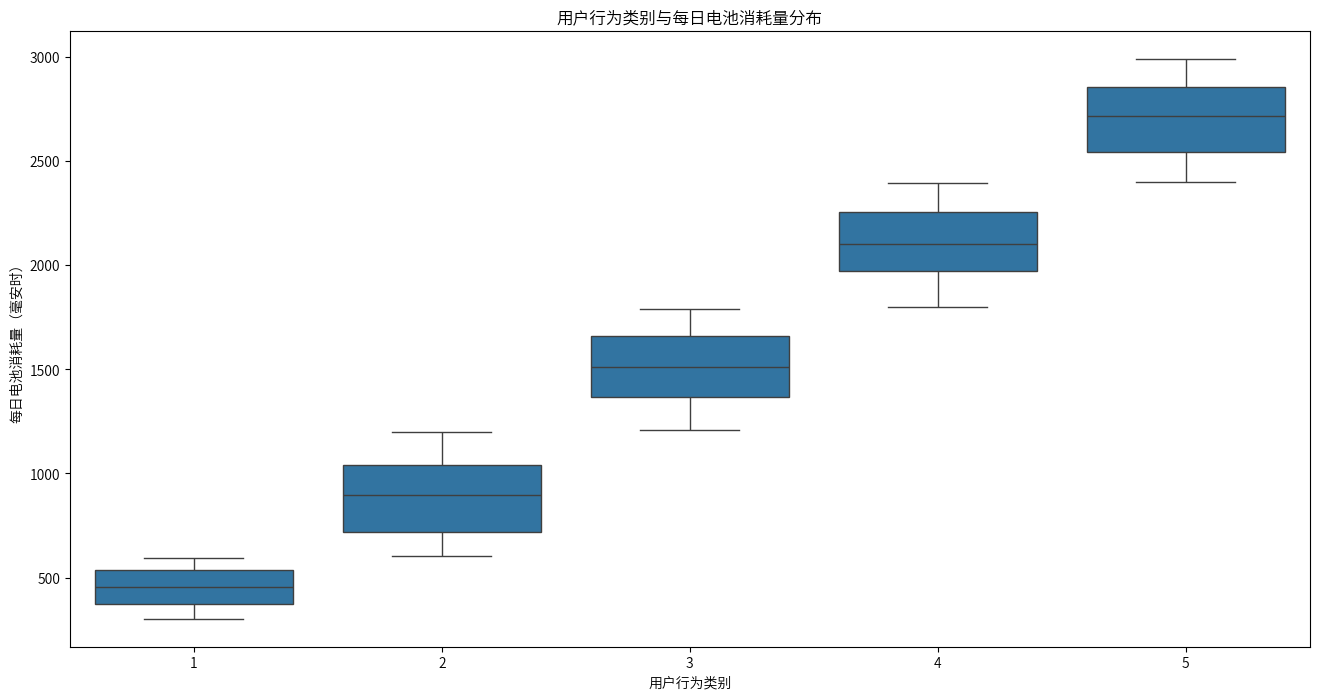
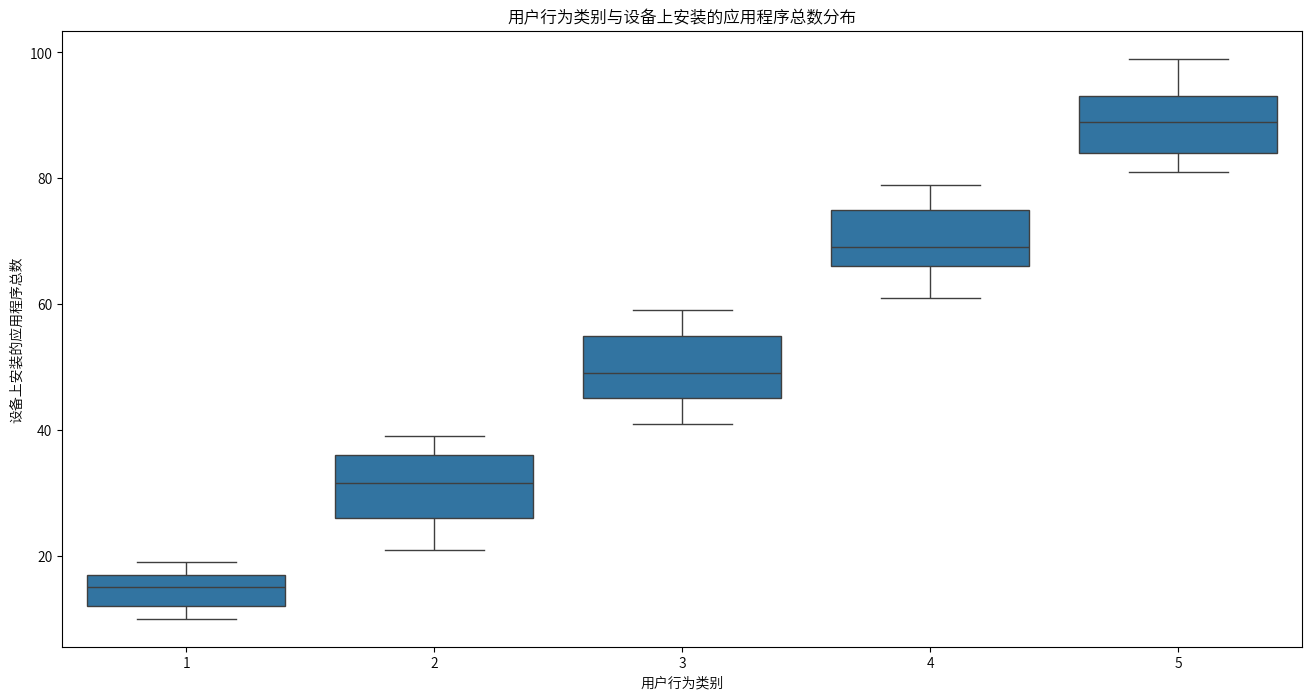
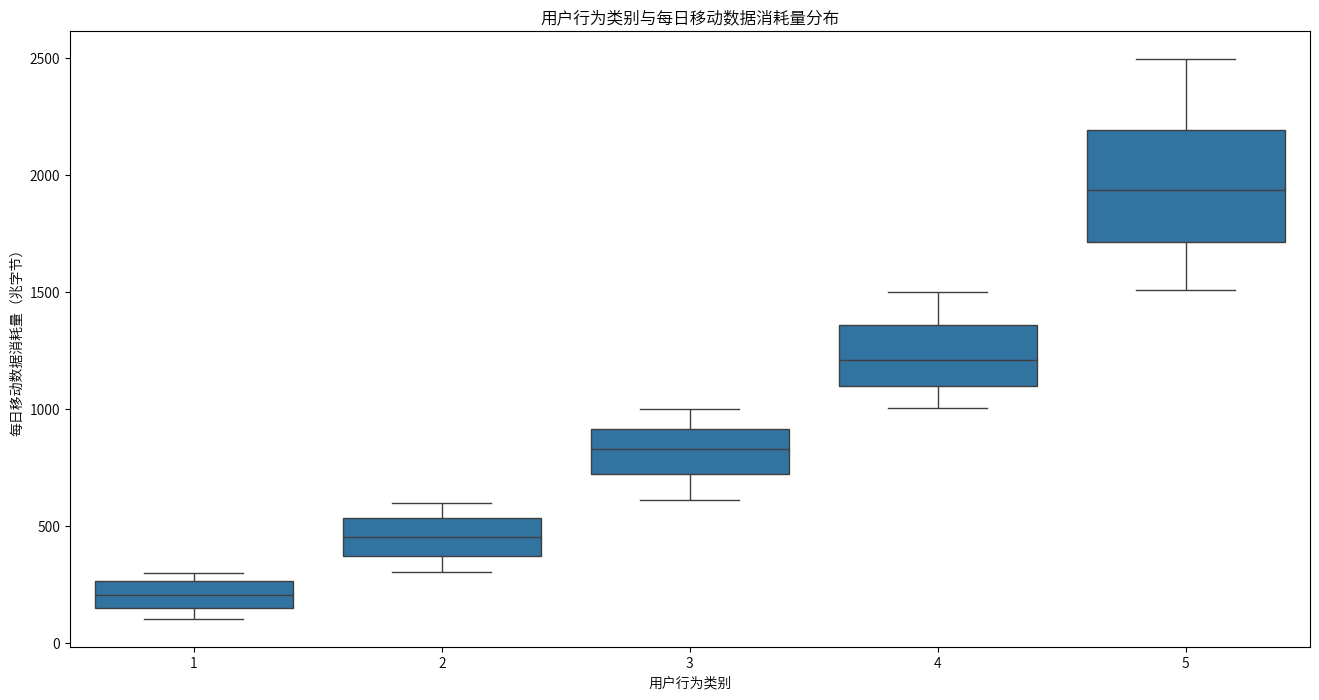
同理,每日电池消耗量、设备上安装的应用程序总数、每日移动数据消耗量都是划分用户行为类别的主要因素之一。
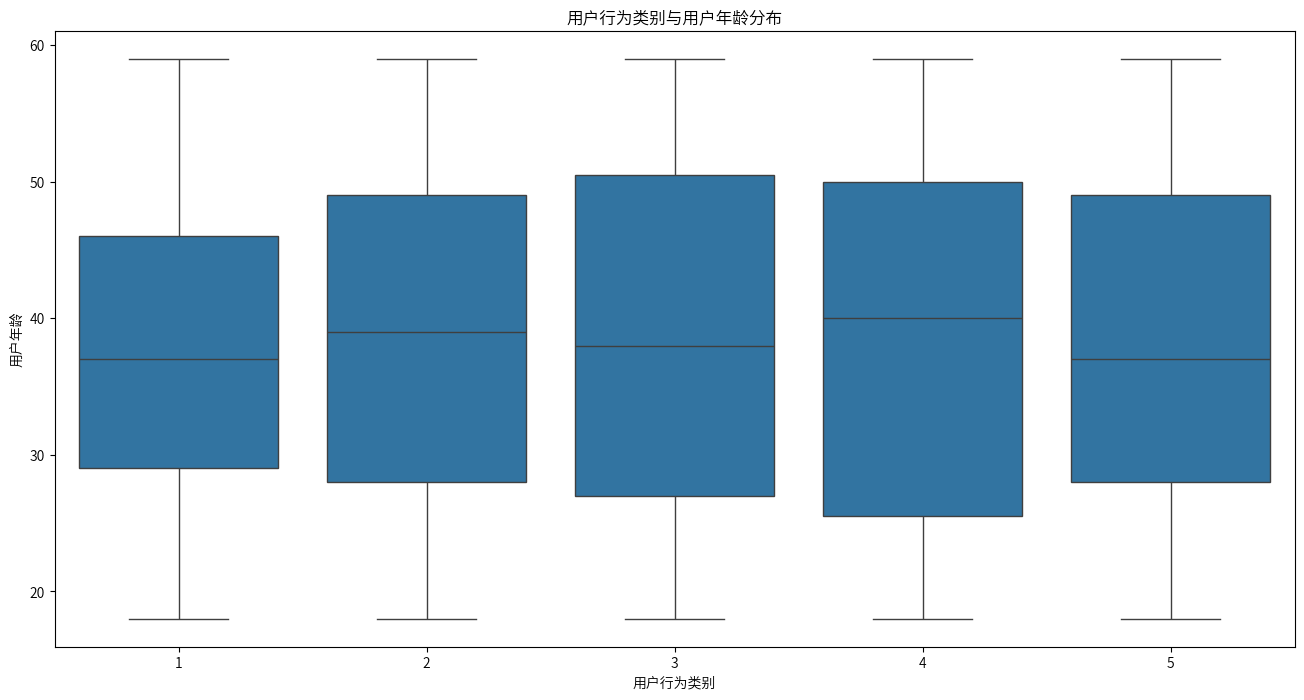
1类和5类的年龄中位数比其他类低,4类的年龄中位数是最高的,但是仍然无法肯定年龄是划分用户行为类别的主要因素,需要进一步通过统计检验来验证。
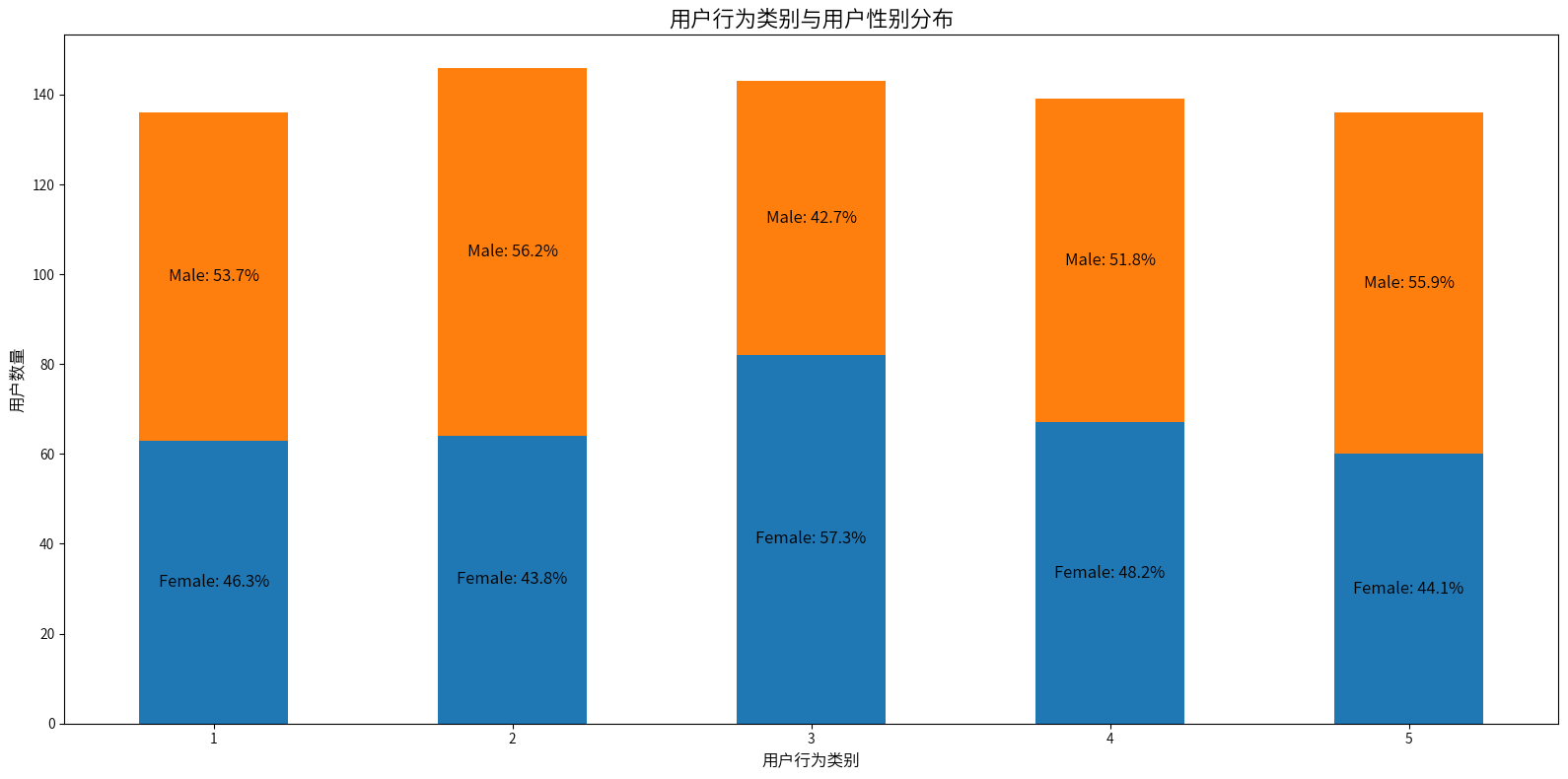
3类女性占比最大,2类和4类女性占比比其他类小,可能性别也是划分用户行为类别的主要因素之一。
6.2相关性分析
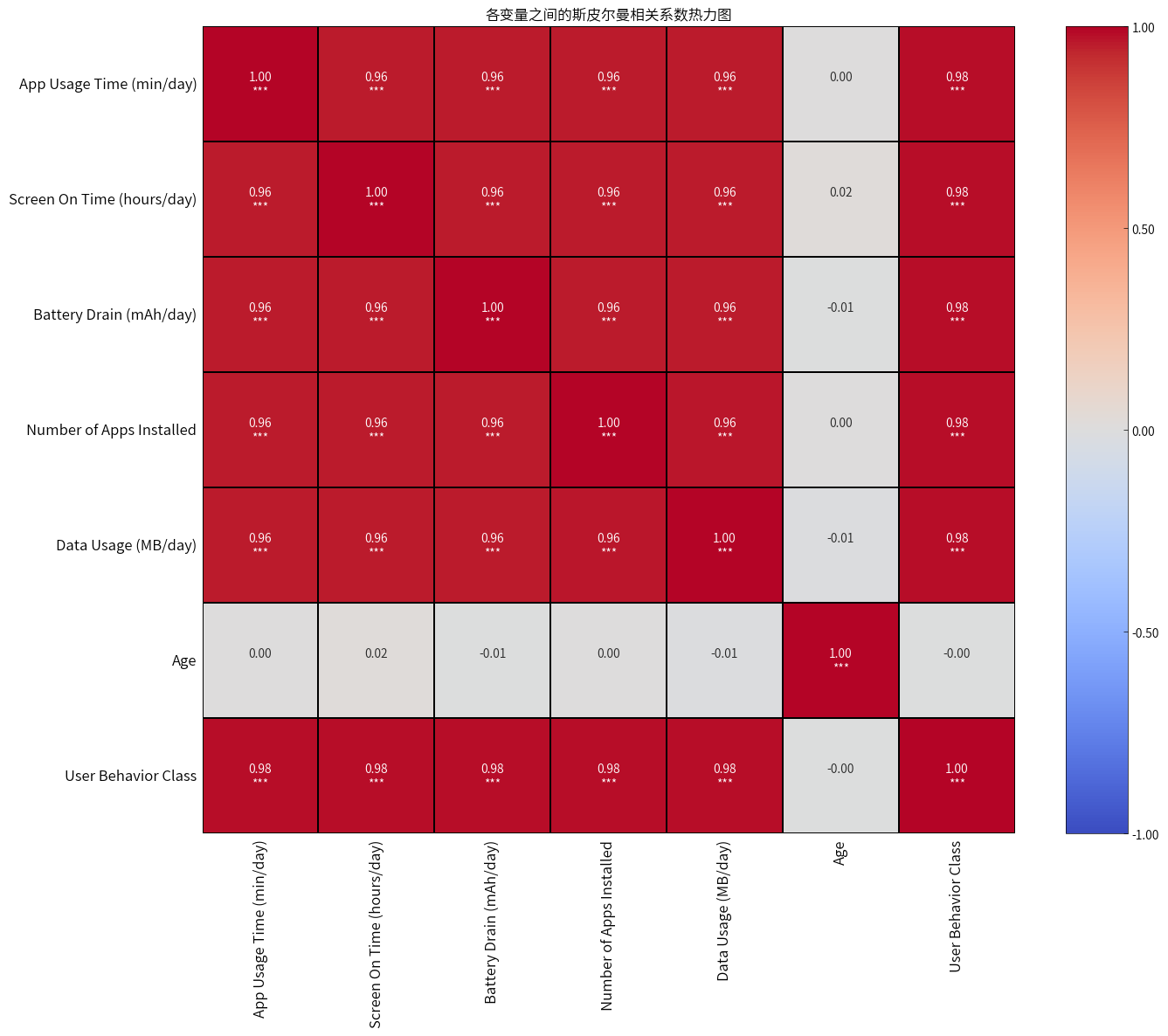
通过斯皮尔曼相关性分析,在把用户行为类别当成有序变量后,发现每天在移动应用上花费的时间、屏幕每天平均活跃时间、每日电池消耗量、设备上安装的应用程序总数、每日移动数据消耗量和用户行为类别之间存在特别强烈的正相关关系,但是它们与年龄之间无关。
6.3Kruskal-Wallis H检验
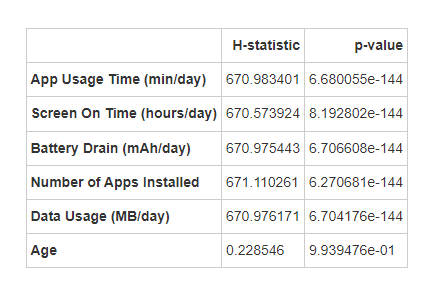
这里把用户行为类别当成无序变量,发现每天在移动应用上花费的时间、屏幕每天平均活跃时间、每日电池消耗量、设备上安装的应用程序总数、每日移动数据消耗量这些变量的p值都极其显著(远小于0.05),且H统计量都非常接近(约670-671),说明它们与用户行为类别都有非常强的关联,但是年龄与用户行为类别没有显著关系,这个与斯皮尔曼相关性分析得到的结论一致。
6.4卡方检验
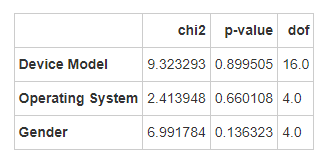
手机型号、操作系统、性别与用户行为类别无显著关联。
7.预测用户行为类别
7.1数据预处理
根据之前的分析,剔除不显著特征,只保留显著特征,这里采用随机森林模型,不需要处理多重共线性的情况,然后划分数据集。
7.2随机森林模型
通过之前的分析发现不同类型的用户使用手机的程度是不同的,从1到5级,依次增加,可以作为回归模型处理,然后再通过设定阈值将连续值转换为类别。
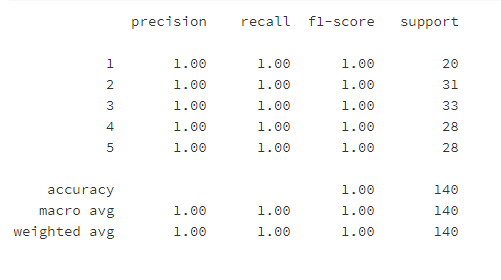
准确率高达百分百,说明这个分类本身很可能就是基于“每天在移动应用上花费的时间、屏幕每天平均活跃时间、每日电池消耗量、设备上安装的应用程序总数、每日移动数据消耗量”来划分的,而且各个类别之间没有重叠区域,也就是各个类别之间界限非常明显,所以才会有这样的效果。
8.预测每日移动数据消耗量
8.1数据预处理
这里还是只选择“每天在移动应用上花费的时间、屏幕每天平均活跃时间、每日电池消耗量、设备上安装的应用程序总数”这四个显著特征,不考虑用户类别了。
8.2随机森林模型
模型评估指标:
R2 score: 0.9280
MSE: 28491.4337
RMSE: 168.7941
MAE: 124.6272
9.总结
本项目通过对模拟生成的700位用户智能手机使用数据进行统计分析和建模,得出以下主要结论:
用户行为分类主要受以下五个因素的显著影响:
每天在移动应用上花费的时间(均值271分钟)
屏幕每天平均活跃时间(均值5.27小时)
每日电池消耗量(均值1525毫安时)
设备上安装的应用程序总数(均值51个)
每日移动数据消耗量(均值930MB)
这五个指标从1类用户到5类用户呈现明显的递增趋势。
用户的人口统计特征(年龄、性别)和设备特征(手机型号、操作系统)与用户行为分类无显著关联,说明用户的使用行为主要由其实际使用习惯决定,而非其基本属性。
使用随机森林模型对用户行为类别进行预测,模型准确率达到100%,这表明用户行为类别的划分很可能就是基于上述五个关键指标设定的,且各类别之间界限明显。
基于用户的应用使用时间、屏幕开启时间、电池消耗量和安装应用数量四个指标,使用随机森林回归模型预测每日移动数据消耗量,取得了较好的效果:
R²达到0.928,说明模型具有很强的预测能力
RMSE为168.79MB,MAE为124.63MB,预测误差相对较小
本研究的实践意义:
可以帮助运营商根据用户的使用特征推荐更合适的流量套餐
为手机制造商优化设备性能和电池续航提供参考
有助于理解不同类型用户的使用习惯和需求特点
需要说明的是,由于使用的是模拟数据集,上述结论主要用于展示数据分析方法的应用,不宜用于实际的商业决策。但这些分析方法和思路可以应用于真实数据的分析中。