参考资料和分析注意事项
全流程的分析指导视频

演示数据集网盘文件
分析参数文件路径格式的特别提示
大家给要分析用到的文件路径或目录路径的时候,以D:/omics_tools/demo_data/scrnaseq/GSE189125/GSE189125_5prime_scRNAseq_seqbatchA_counts.txt.gz 这个文件为例,具体的标准规范写法如下:
路径首先应该是一个完整的路径,从D盘的盘符D:/根目录一直到最后的文件名用斜杠连接起来的一个完整的文件路径,这些的文件基本上都是可以被识别和读取的,不要只给一个简单的文件名,这样就不知道这个具体是你电脑上哪个磁盘哪个目录的文件
通过拓展虚拟内存来解决在单细胞分析时候运行内存不够的问题
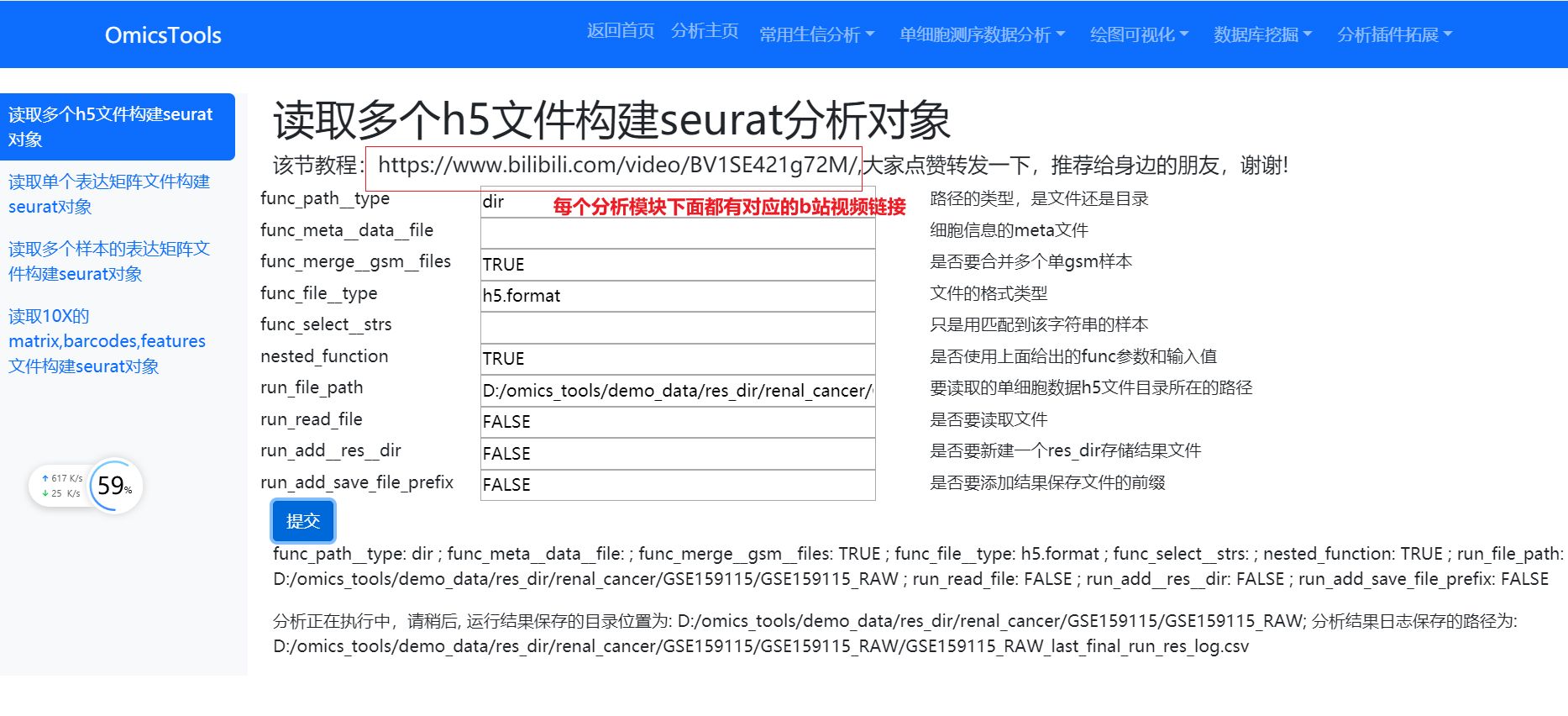
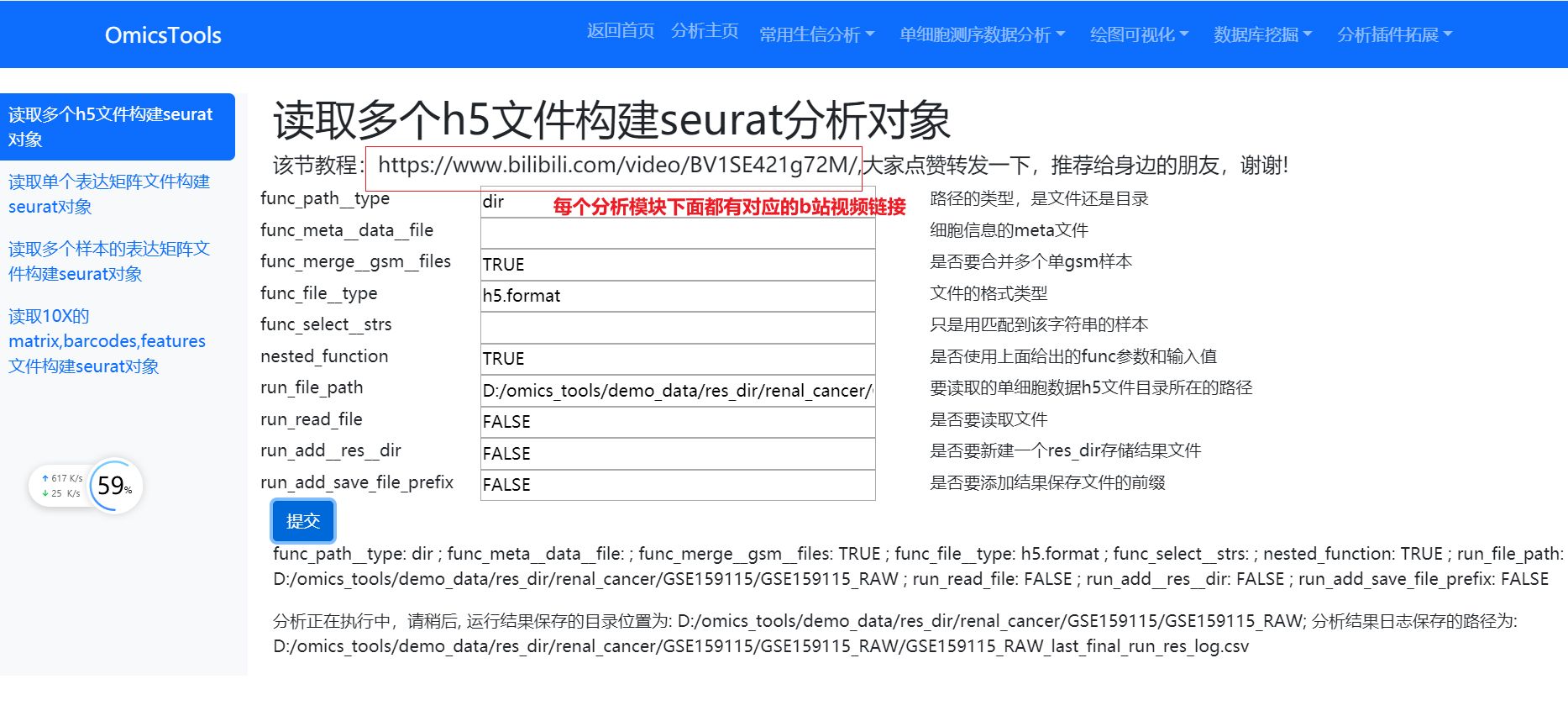
读取数据构建seurat对象
样本名称的特别重要的注意事项:
不管是GEO的单细胞数据,还是自己的单细胞数据或其他来源的数据的时候,大家在对文件名可能也需要做一定的修改,就是文件名开头在第1个下划线_之前的那个文件名的名字就要把它变成是唯一的,一般GEO的数据开头就用GSM编号开头,每个样本的gsm编号就是唯一的。
如果是自己的数据也要让他前面的那个名字变成唯一的,再用一个下划线_跟后面的文件名的部分进行分隔开,然后软件只会提取出第1个下划线前面的这个名字作为样本的 id和创建出这个样本的目录.
大家注意,如果你第1个下划线前面的这个名字跟其他样本不是唯一的,那么就会造成样本的一个重复,所以的话每个样本在第1个下划线之前的名字编号都要把它变成是唯一的跟其他的样本的地名字不重复的,这是在文件名字修改和读取的时候特别重要的注意事项。
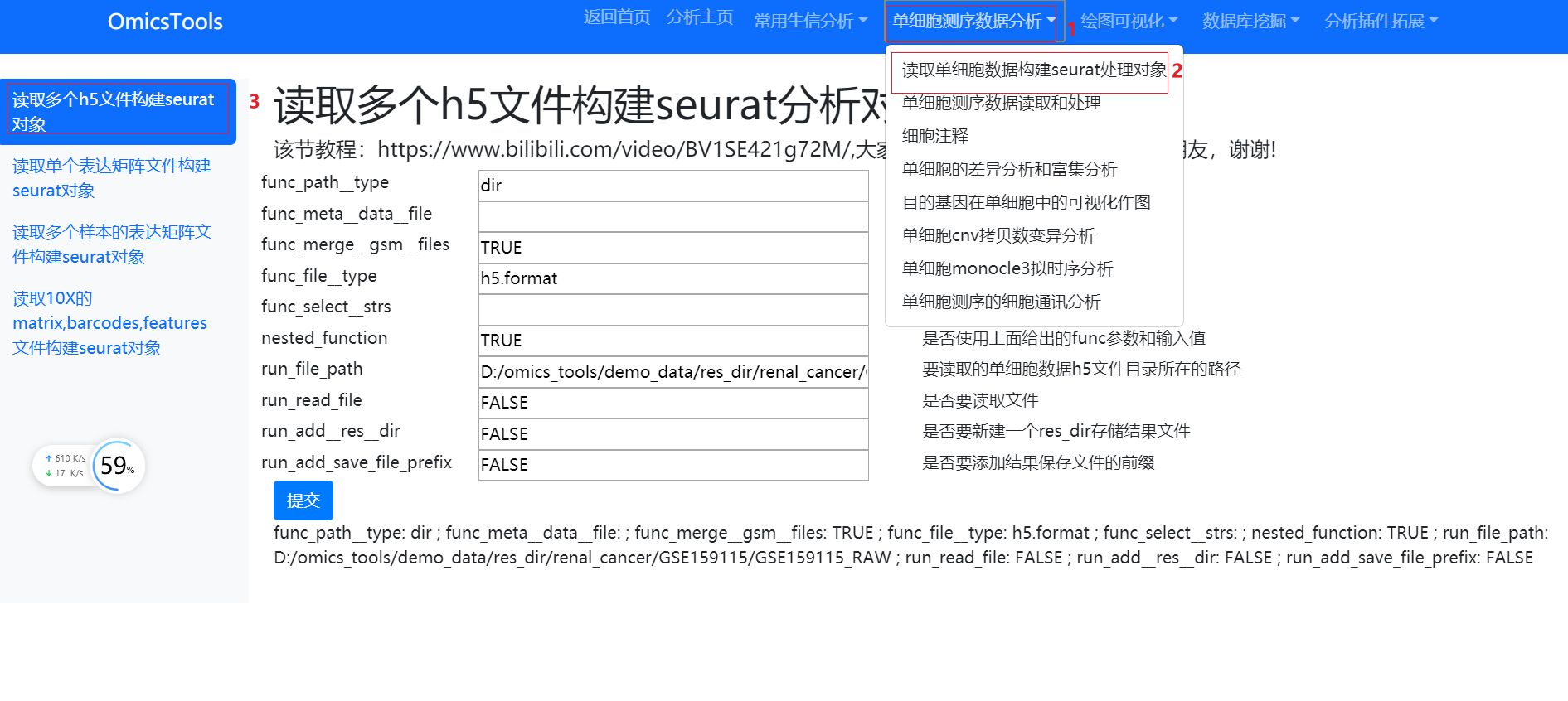
读取h5格式的单细胞测序数据文件构建Seurat分析对象
软件运行窗口
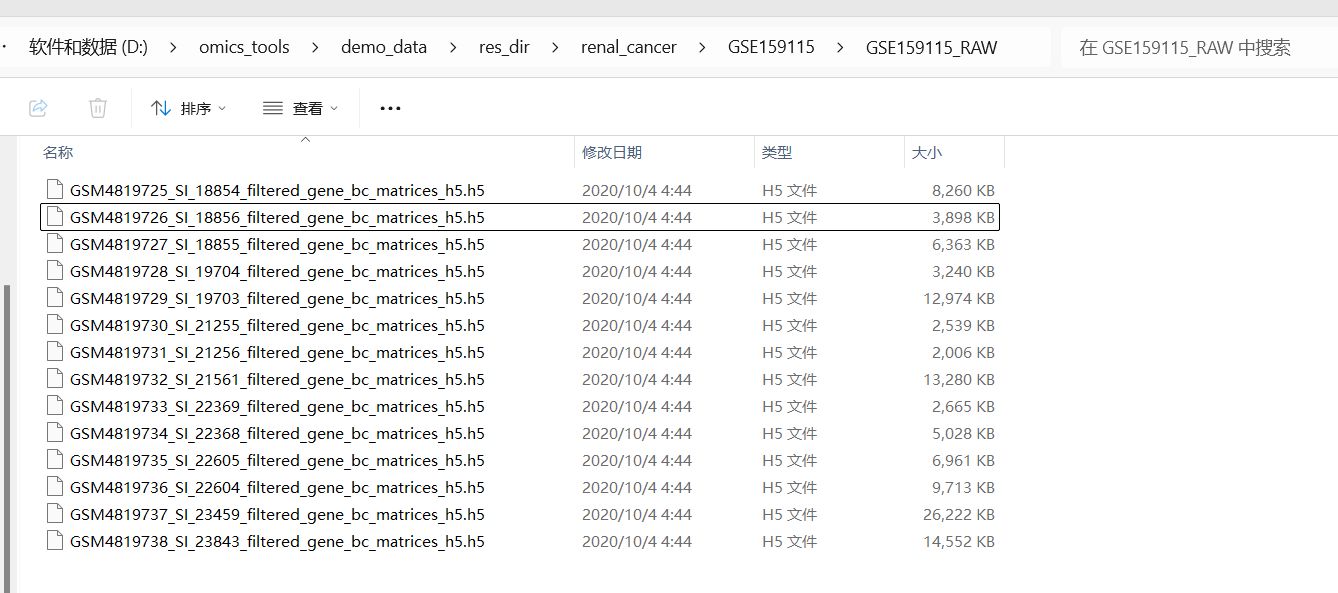
要读取的单细胞多个h5文件
不管是GEO的单细胞数据,还是自己的单细胞数据或其他来源的数据的时候,大家在对文件名可能也需要做一定的修改,就是文件名开头在第1个下划线_之前的那个文件名的名字就要把它变成是唯一的,一般GEO的数据开头就用GSM编号开头,每个样本的gsm编号就是唯一的。
如果是自己的数据也要让他前面的那个名字变成唯一的,再用一个下划线_跟后面的文件名的部分进行分隔开,然后软件只会提取出第1个下划线前面的这个名字作为样本的 id和创建出这个样本的目录.
大家注意,如果你第1个下划线前面的这个名字跟其他样本不是唯一的,那么就会造成样本的一个重复,所以的话每个样本在第1个下划线之前的名字编号都要把它变成是唯一的跟其他的样本的地名字不重复的,这是在文件名字修改和读取的时候特别重要的注意事项。
软件运行结果文件得到构建好的seurat对象的rds文件和metadata文件
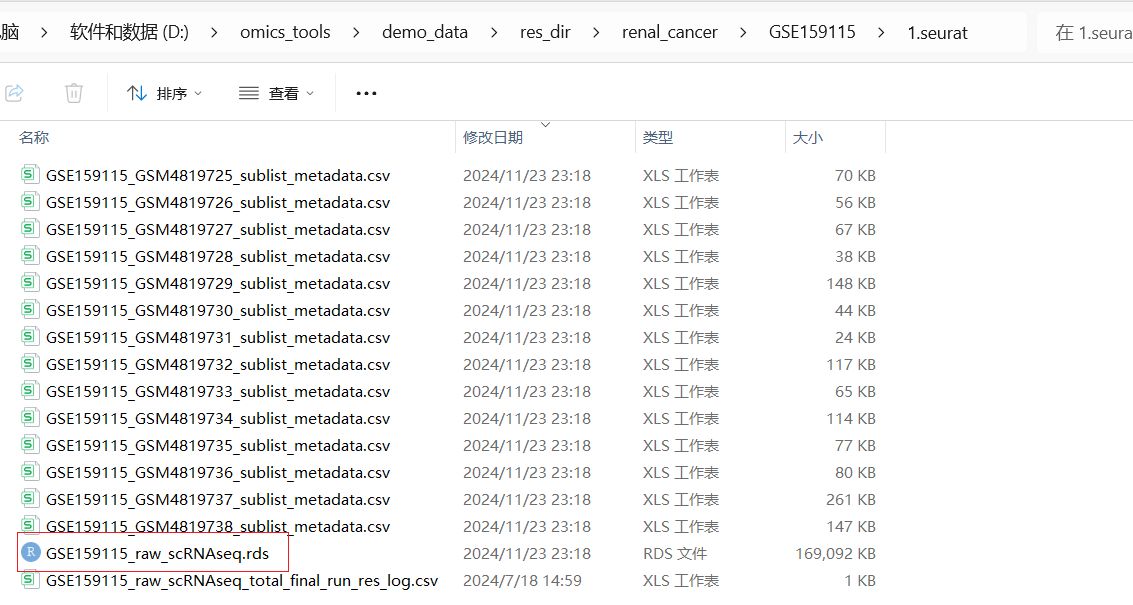
单个表达矩阵的单细胞测序数据下载读取和构建Seurat分析对象
注意事项
如果是读取的单个表达矩阵文件来构建seurat分析对象的话, 这个表达矩阵文件可以是CSV,TXT, TSV或者csv.gz,txt.gz, tsv.gz 等格式的表格文件
如果这单个表达矩阵文件里面含有多个样本,比如说多个GSM编号的样本,那么就必须要提供一个meta.data文件 ,这个meta data文件里面含有了每个样本的几千个细胞的细胞标签ID,这样的话就能够知道每个样本大概是由哪些单细胞数据。
如果是该项目只有一个样本的话,那么就可以不用提供meta data文件。
软件运行窗口
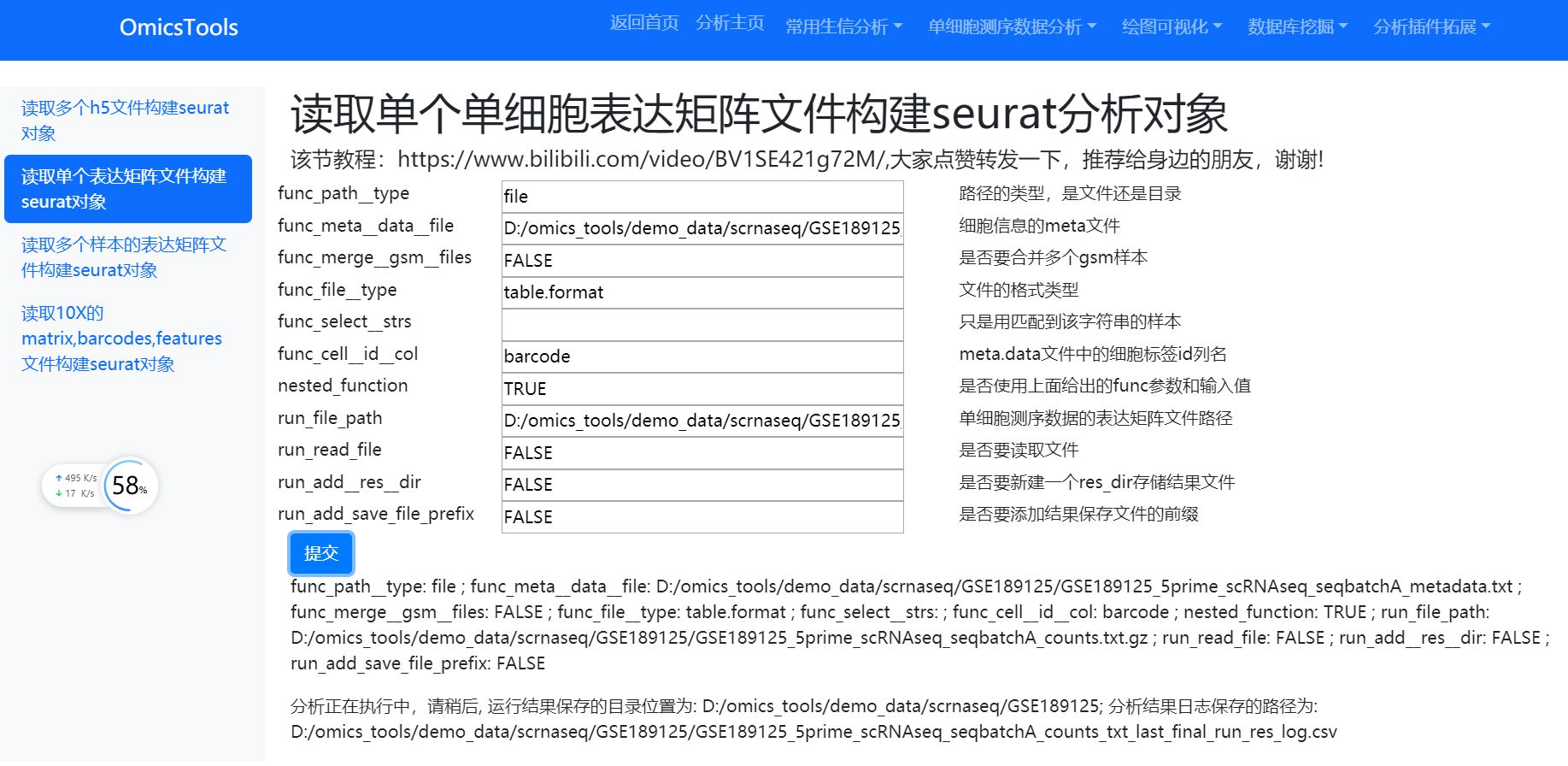
演示数据
运行结果
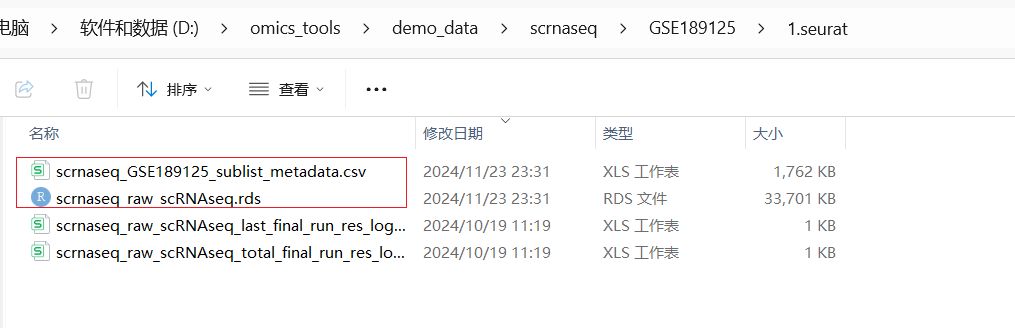
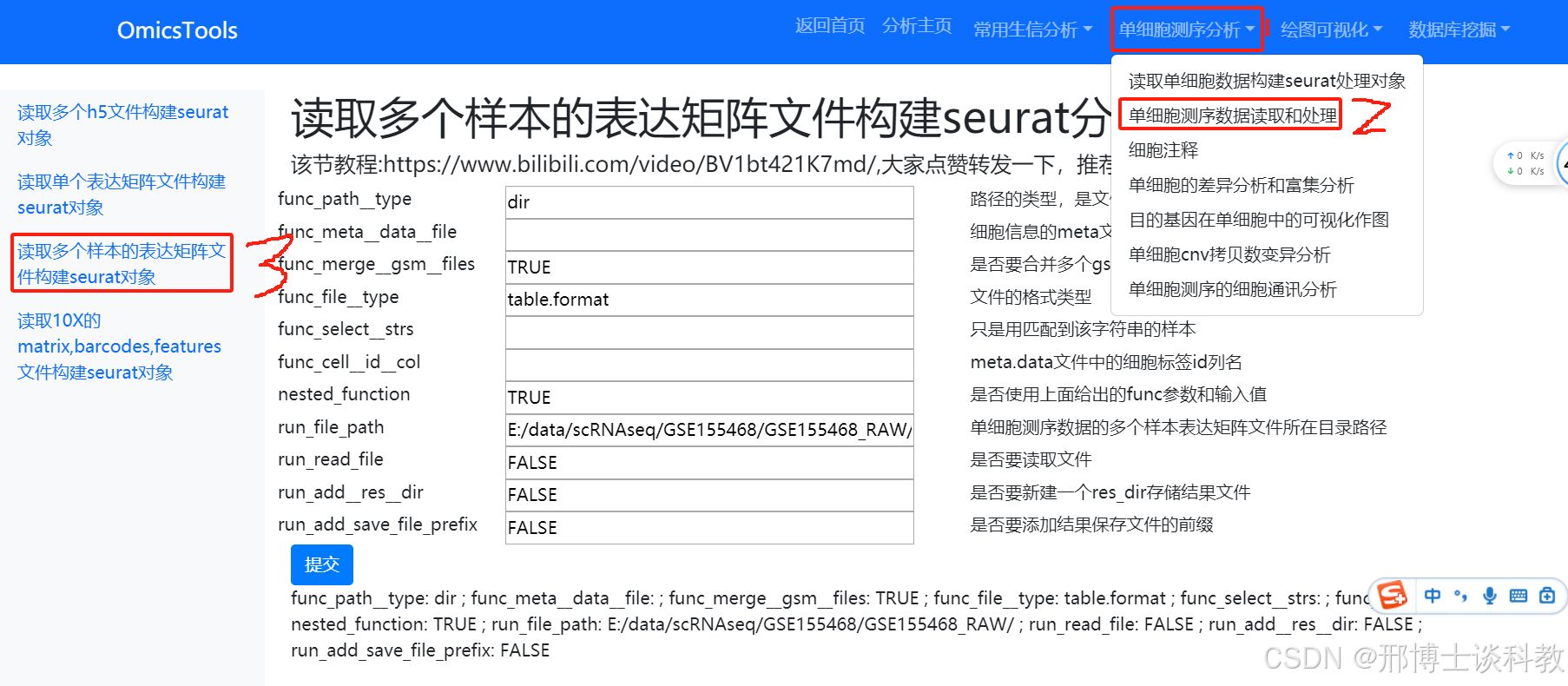
读取一个目录下多个样本的表达矩阵文件构建seurat分析对象
表达矩阵文件可以是CSV,TXT, TSV或者csv.gz,txt.gz, tsv.gz 等格式的表格文件
教学视频
软件运行窗口
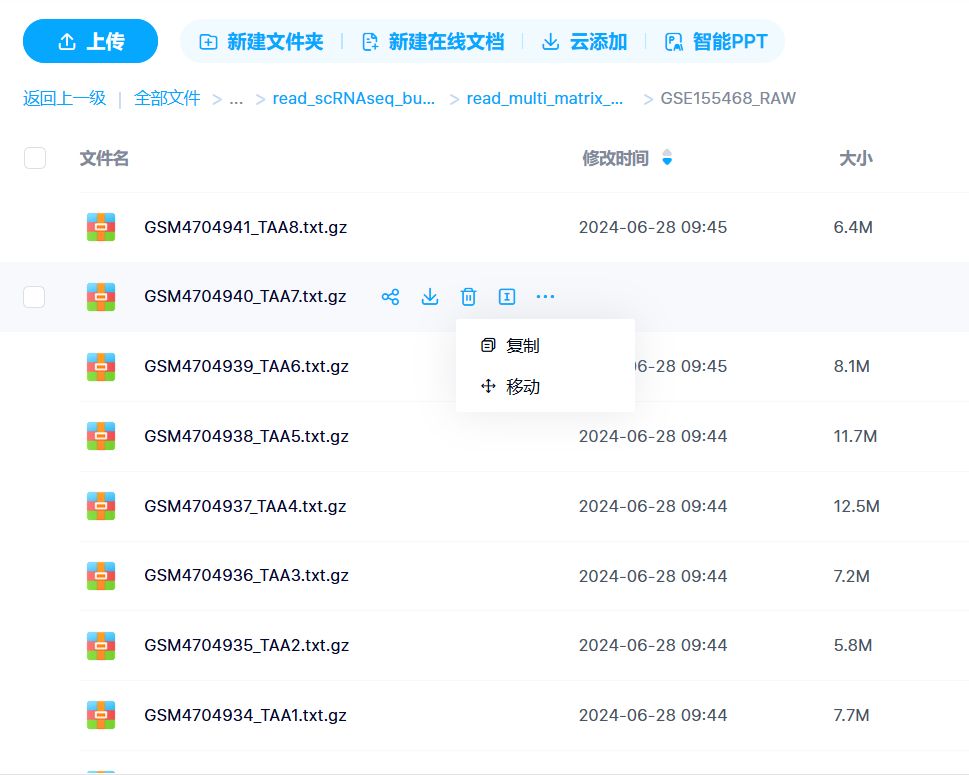
演示数据文件
不管是GEO的单细胞数据,还是自己的单细胞数据或其他来源的数据的时候,大家在对文件名可能也需要做一定的修改,就是文件名开头在第1个下划线_之前的那个文件名的名字就要把它变成是唯一的,一般GEO的数据开头就用GSM编号开头,每个样本的gsm编号就是唯一的。
如果是自己的数据也要让他前面的那个名字变成唯一的,再用一个下划线_跟后面的文件名的部分进行分隔开,然后软件只会提取出第1个下划线前面的这个名字作为样本的 id和创建出这个样本的目录.
大家注意,如果你第1个下划线前面的这个名字跟其他样本不是唯一的,那么就会造成样本的一个重复,所以的话每个样本在第1个下划线之前的名字编号都要把它变成是唯一的跟其他的样本的地名字不重复的,这是在文件名字修改和读取的时候特别重要的注意事项。
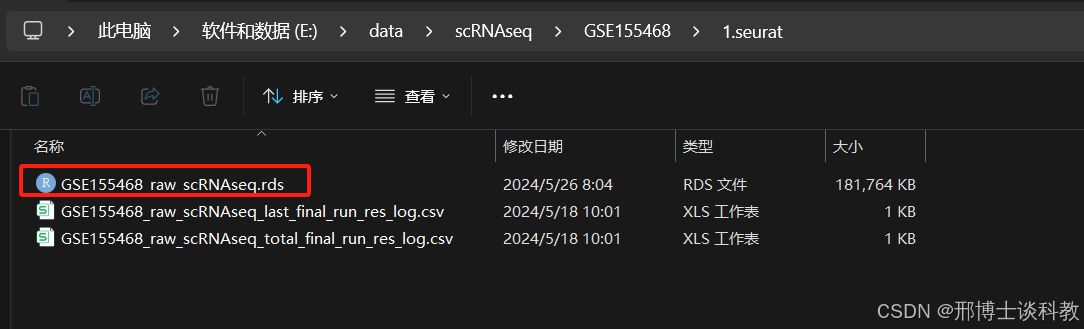
软件运行结果文件得到构建好的seurat对象的rds文件
该模块的特殊情形的处理方式1:
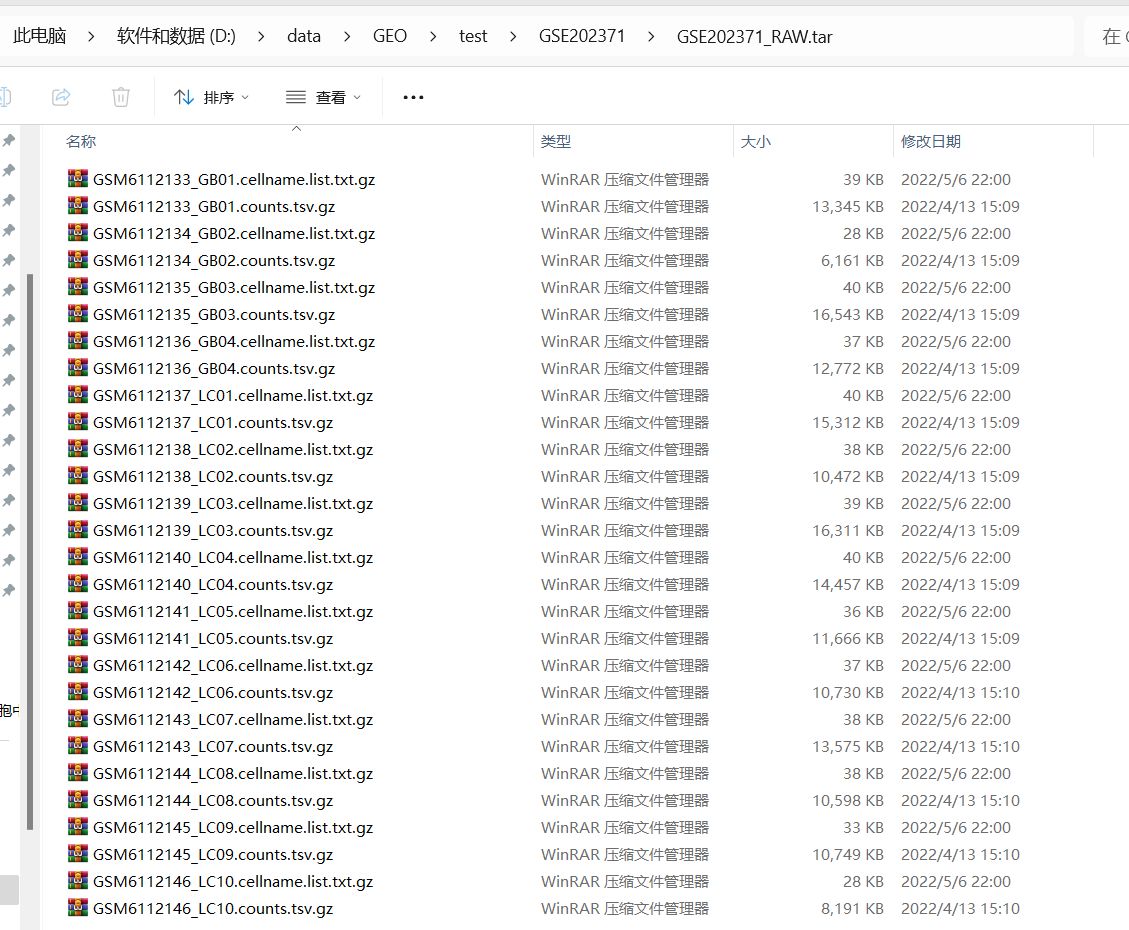
这个数据集中除了有counts.tsv.gz表达矩阵文件,还有一些cellname.list.txt.gz细胞名称文件,处理方法就是把所有非counts.tsv.gz的表达矩阵文件全部删掉,只留下counts.tsv.gz表达矩阵文件再进行读取。
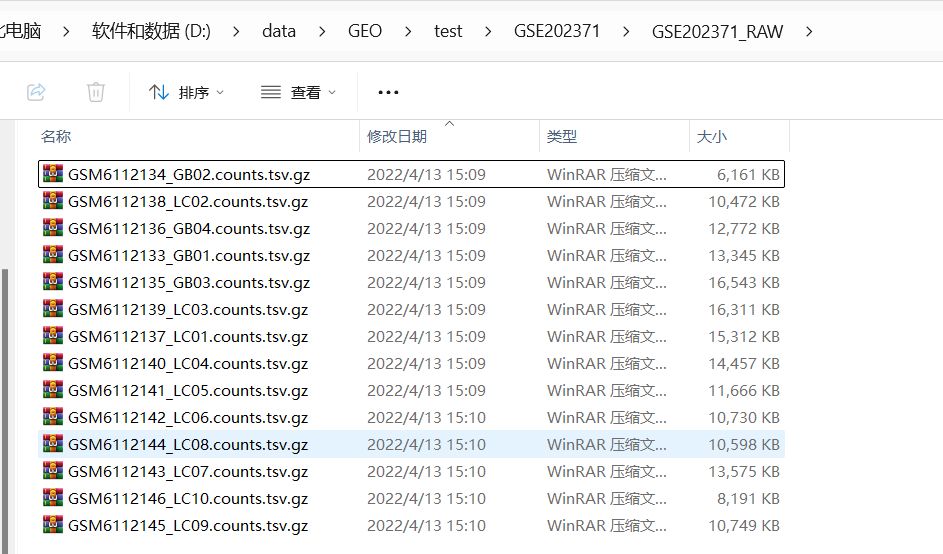
10X格式来源的单细胞测序数据下载读取和构建Seurat分析对象
读取10X数据的格式要求和注意事项
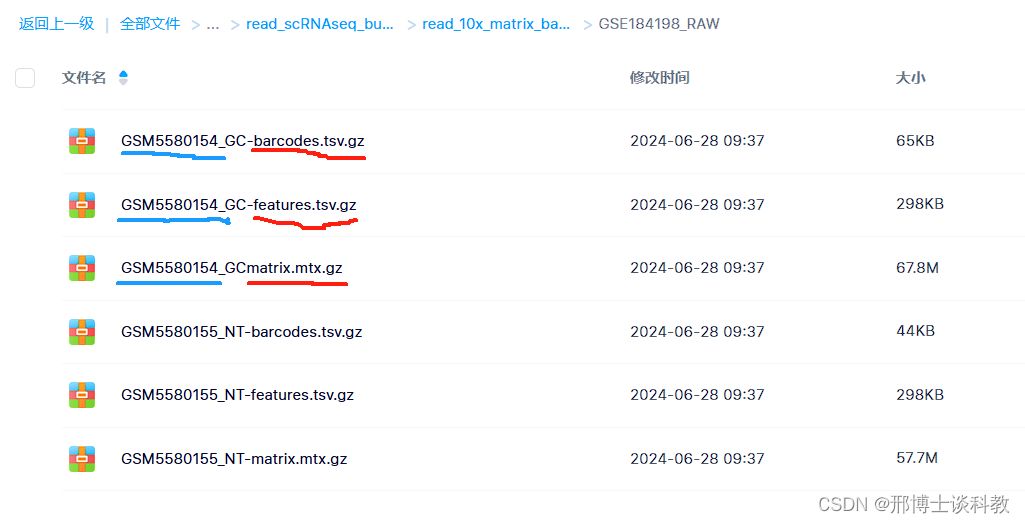
1. 如上图的演示数据集的格式所示,每个样本有三个文件,这三个文件的后缀分别是: barcodes.tsv.gz , features.tsv.gz, matrix.mtx.gz 来结尾。
2. 需要注意的是这三个文件每个文件都是一个.gz压缩包,大家不要把这些.gz压缩包文件跟他解压了,因为10X的文件读取都是以.gz压缩包的格式来读取的
3. 如果大家是用的从GEO数据库上下载的单细胞的公共数据集,一般的话,每个样本的样本编号应该对应的是一个GSM开头的样本编号,对于GEO上的数据,大家需要把GSM编号放在最前面,GSM编号跟后面的文件名用下划线_分隔开,比如GSM5580154_GCmatrix.mtx.gz,GSM5580154_GC-barcodes.tsv.gz, GSM5580154_GC-features.tsv.gz这个样本的三个10X文件, 就是GSM5580154后面加一个下划线_跟后面的GC-barcodes.tsv.gz,GC-features.tsv.gz,GCmatrix.mtx.gz进行隔开, 软件在提取这样的GSM样本编号的时候是以下划线跟后面的文件名进分隔开并只提取下划线前面的GSM编号来创建每个样本的目录,以这三个10X文件为例,后面软件只会提取出GSM5580154作为样本编号并自动创建出这样一个目录,后面会用这些GSM编号作为样本的id, 所以大家在对于GSM样本要处理的时候,大家都是要让这样的文件名开头是以大写的GSM编号开头, 且GSM编号跟后面的文件名字中间要以一个下划线隔开。
4. 对于不管是GEO的数据,而是自己的单细胞数据或其他来源的数据的时候,大家在对文件名可能也需要做一定的修改,就是文件名开头在第1个下划线之前的那个文件名的名字就要把它变成是唯一的,再用一个下划线跟后面的文件名的部分进行分隔开,然后软件只会提取出第1个下划线前面的这个名字作为样本的 id和创建出这个样本的目录,大家注意,如果你第1个下划线前面的这个名字跟其他样本不是唯一的,那么就会造成样本的一个重复,所以的话每个样本在第1个下划线之前的名字编号都要把它变成是唯一的跟其他的样本的地名字不重复的。
软件运行窗口
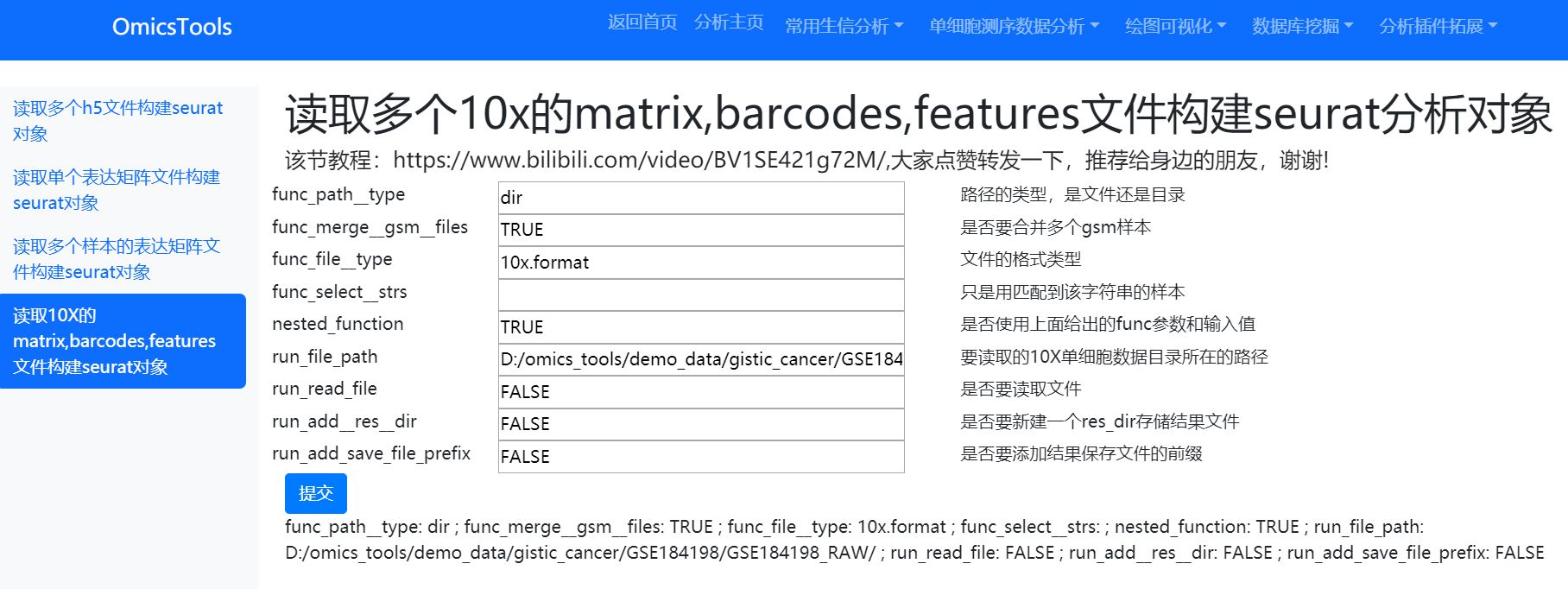
软件运行结果文件得到构建好的seurat对象的rds文件