背景介绍
文档版面区域检测技术通过精准识别并定位文档中的标题、文本块、表格等元素及其空间布局关系,为后续文本分析构建结构化上下文,是文档图像智能处理流程的核心前置环节。随着大语言模型、文档多模态及RAG(检索增强生成)等技术快速发展,高质量结构化数据已成为模型训练与文档知识库构建的关键需求。基于版面检测模型定位识别文档图像的布局,结合如文本识别、公式识别、表格识别及信息抽取等下游任务,能够为大模型产出丰富的结构化训练数据,增强大模型的公式理解、表格解析以及对文档层次结构的理解能力。
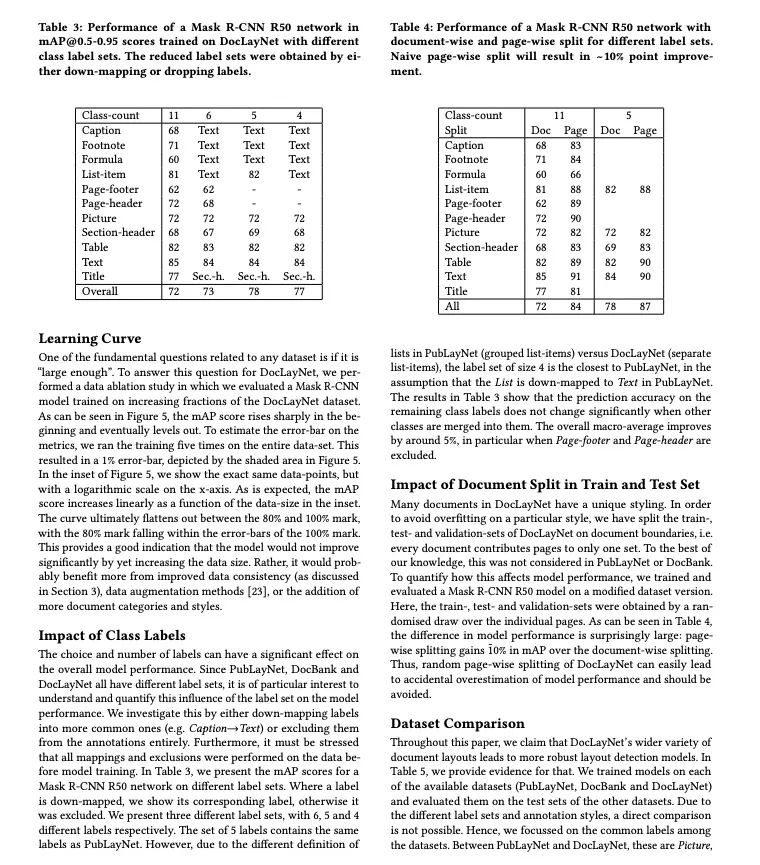
然而,当前版面检测模型在满足构建 AI 数据的需求时仍面临诸多挑战:其一,多样化文档适用性不足,现有算法多聚焦于论文类文档,对杂志、报纸、研报等复杂版式的检测效果有限,难以获取类型丰富的大模型训练数据;其二,复杂版面结构识别能力有限,类别定义不全面(如行间/行内公式未单独定义),需额外模型辅助识别,导致处理效率降低与模型管理复杂化;其三,实时性能不足,难以满足大模型对海量训练数据的快速获取的需要。
为此,飞桨团队推出PP-DocLayout版面区域检测模型,支持中英文论文、研报、试卷、书籍、报纸、杂志等多种文档类型的23类版面区域的高精度识别与定位,显著提升大模型获取训练数据的多样性与高质量,同时满足大模型海量数据构建的高效率需求,基于 PaddleX 高性能推理引擎,轻量级模型在 CPU 上每秒可处理约69个文档图像页面,T4 GPU上每秒可处理高达123个文档图像页面,大幅超越现有开源方案。
一、效果速览
论文





报纸或杂志






研报





试卷、书籍或笔记





合同或条款





二、算法解读
针对版面检测任务,PP-DocLayout 系列支持 23 个常见版面布局类别,包含文档标题、段落标题、文本、页码、摘要、目录、参考文献、脚注、页眉、页脚、算法、公式、公式编号、图像、图像标题、表格、表格标题、图表、图表标题、印章、页眉图像、页脚图像和侧栏文本。这些类别覆盖全面,涵盖了多样化文档中常见的版面元素;类别结构层次清晰,通过识别文档标题、摘要、段落标题和正文等元素,可以更好地解析文档的语义层次和逻辑关系;同时包含公式、印章、表格、图表等高价值信息的结构化数据,允许更精准的进一步数据处理和分析;增加细粒度的页眉图像、页脚图像、侧栏文本等细小元素类别,利于下游版面恢复任务提高文档版面布局顺序预测的质量。
PP-DocLayout 系列提供了三个不同尺度的模型,以满足不同场景的需求:
- 高精度模型:PP-DocLayout-L,基于飞桨自研高精度检测模型 RT-DETR-L 训练得到,其在精度上达到了90.4 mAP@0.5,相对上一版本精度提升 15% 以上,尤其适合需要高精度的任务场景;在效率上也有所保障,基于 PaddleX 的高性能推理,高精度 PP-DocLayout-L 模型在 T4 GPU 上每个页面端到端推理耗时 13.4 ms。
- 精度和效率均衡模型:PP-DocLayout-M,基于飞桨自研精度-效率均衡的检测模型 PP-PicoDet-M 训练得到,适合精度效率兼顾要求的任务,其在精度上达到了75.2 mAP@0.5,基于 PaddleX 的高性能推理模式,PP-DocLayout-M 高精度模型能够在 T4 GPU 上每个页面端到端推理耗时 12.7ms。
- 高效率模型:PP-DocLayout-S,基于飞桨自研高效率检测模型 PP-PicoDet-S 训练得到,以提升推理速度和降低模型大小为目标,适合于资源受限的环境和实时应用场景。基于 PaddleX 的高性能推理模式,高效率模型在 T4 GPU上能够能实现毫米级别预测,单页面处理耗时约 8.1ms,CPU上能够实现单页面耗时 14.5ms。

注:以上精度指标的评估集是 PaddleX 自建的版面区域检测数据集,包含中英文论文、杂志、合同、书本、试卷和研报等常见的 500 张文档类型图片。GPU 推理耗时基于 NVIDIA Tesla T4 机器,CPU 推理速度基于 Intel® Xeon® Gold 6271C CPU @ 2.60GHz,线程数为 8,精度类型为 FP32。
PP-DocLayout 在数据和算法层面均做了优化:
- 在数据层面,采用了基于主动学习的数据轮动方法,筛选较难的样本和类别,获取大量人工矫正标签的高质量多类型文档的版面检测模型训练数据。
- 算法层面:
1)更优的泛化能力:PP-DocLayout-L 的骨干网络采用了蒸馏技术,骨干网络基于大模型蒸馏得到,大幅增强模型泛化性能。通过知识蒸馏技术,可以将一个大规模、复杂的“教师”模型的知识传递给一个相对较小的“学生”模型。在这里,我们将基于大规模文档数据训练得到的 GOT-OCR2.0 模型的视觉编码器作为“教师”模型,而将飞桨自研的高精度骨干网络 PP-HGNetV2-B4 作为“学生”模型。我们收集了大量多种类型的约 50 万文档图像数据,并利用 L2 损失函数,将大模型的输出作为目标,指导小模型的学习。这样,小模型能够更好的支持复杂下游任务,如版面区域检测。在版面区域检测任务中,PP-DocLayout-L 的训练使用经过知识蒸馏的 PP-HGNetV2-B4 作为预训练模型,从而能够更快速地收敛,并提升精度和泛化能力。

骨干网络知识蒸馏

2)优化伪标签质量的半监督学习:PP-DocLayout-M/S 采用了半监督学习技术,基于 PP-DocLayout-L 生成伪标签,在伪标签生成过程中,根据每个类别得分分布制定最佳阈值获取较高质量伪标签,优化标签质量。基于真实人工标注和伪标签数据,训练 PP-DocLayout-M 和 PP-DocLayout-S 模型,增强模型精度。

3)灵活易用后处理:支持每个类别的动态阈值调整,可根据数据优化漏检和误检情况;支持重叠框过滤,可过滤多余的检测框;可自由扩张框边长,便于输入正确完整布局到下游任务;可选框的合并模式,支持输出外边框,内框和所有框,适用于不同的下游任务需求。
三、使用方法
安装
安装PaddlePaddle
# cpu
python -m pip install paddlepaddle==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
# gpu,该命令仅适用于 CUDA 版本为 11.8 的机器环境
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# gpu,该命令仅适用于 CUDA 版本为 12.3 的机器环境
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/
安装PaddleX Wheel包
pip install https://paddle-model-ecology.bj.bcebos.com/paddlex/whl/paddlex-3.0.0rc0-py3-none-any.whl
快速体验
PaddleX 提供了简单易用的 Python API,只需几行代码即可体验模型预测效果,可以下载测试图片,方便大家快速体验效果:
图片下载地址:
https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/layout.jpg
from paddlex import create_model
model = create_model(model_name="PP-DocLayout-L")
output = model.predict("layout.jpg", batch_size=1, layout_nms=True)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/res.json")
上述代码中:
- 首先使用模型名称调用 create_model() 方法实例化对象;
- 然后使用 predict() 方法进行预测,对于预测结果支持 print() 方法进行打印,save_to_img() 方法进行可视化并保存为图片以及 save_to_json() 方法保存预测的结构化输出。
下图1为测试图像,2图为 PP-DocLayout-L 模型版面检测结果。

此外,调用模型的 predict() 方法进行推理预测时,predict() 方法参数支持传入版面模型后处理参数和是否开启高性能推理:
- threshold: 动态阈值调整,支持传入浮点数或自定义各个类别的阈值字典,为每个类别设定专属的检测得分阈值。这意味着您可以根据自己的数据,灵活调节漏检或误检的情况,确保每一次检测更加精准;
- layout_nms : 重叠框过滤,布尔类型,用于指定是否使用NMS(非极大值抑制)过滤重叠框,启用该功能,可以自动筛选最优的检测结果,消除多余干扰框;
- layout_unclip_ratio: 可调框边长,不再局限于固定的框大小,通过调整检测框的缩放倍数,在保持中心点不变的情况下,自由扩展或收缩框边长,便于输出正确完整的版面区域内容;
- layout_merge_bboxes_mode: 框合并模式,模型输出的检测框的合并处理模式,可选“large”保留外框,“small”保留内框,不设置默认保留所有框。例如一个图表区域中含有多个子图,如果选择“large”模式,则保留一个图表最大框,便于整体的图表区域理解和对版面图表位置区域的恢复,如果选择“small”则保留子图多个框,便于对子图进行一一理解或处理。在下游任务中无论是想突出整体,还是聚焦细节,都能轻松实现。
- use_hpip:是否启用高性能推理来优化您模型的推理过程,进一步提升效率。
二次开发
如果对模型效果满意,可以直接对产线进行高性能推理/服务化部署/端侧部署,如果在您的场景中,效果还有进一步优化空间,您也可以使用 PaddleX 进行便捷高效的二次开发,使用自己场景的数据对模型微调训练获得更优的精度。基于 PaddleX 便捷的二次开发能力,使用统一命令即可完成数据校验、模型训练与评估推理,无需了解深度学习的底层原理,按要求准备好场景数据,简单运行命令即可完成模型迭代,此处展示版面区域检测模型二次开发流程:
python main.py -c paddlex/configs/modules/layout_detection/PP-DocLayout-L.yaml \
-o Global.mode=train \
-o Global.dataset_dir=./dataset/layout_det_examples
上述命令中:main.py 为模型开发统一入口文件;-c 用于指定模型配置文件的参数,模型配置文件 PP-DocLayout-L.yaml 中包含了模型的信息,如模型名、学习率、批次大小等,其中 mode 支持指定数据校验(dataset_check)、训练(train)、评估(evaluate)、模型导出(export)和推理(predict)。更多参数也可以继续在命令中追加参数设置或可通过修改.yaml配置文件中的具体字段来进行设置。
其余更详细的使用方法及产线部署、自定义数据集相关的内容,请参考PaddleX官方教程文档:
版面区域检测模块使用教程
https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-rc/docs/module_usage/tutorials/ocr_modules/layout_detection.md
精彩课程
为了帮助您迅速且深入地了解版面区域检测全流程解决方案,百度研发工程师精心打造视频精讲课程,为您深度解析本次技术升级。此外,我们还将开设针对版面区域检测产线的产业场景实战营,配套详细教程文档,手把手带您体验从数据准备、数据校验、模型训练、性能优化到模型部署的完整开发流程。机会难得,立即点击链接报名:https://www.wjx.top/vm/eArkGEn.aspx?udsid=730670
