本专栏深入探究从循环神经网络(RNN)到Transformer等自然语言处理(NLP)模型的架构,以及基于这些模型构建的应用程序。
本系列文章内容:
- NLP自然语言处理基础(本文)
- 词嵌入(Word Embeddings)
- 循环神经网络(RNN)、长短期记忆网络(LSTM)和门控循环单元(GRU)
- 编码器 - 解码器架构(Encoder - Decoder Architecture)
- 注意力机制(Attention Mechanism)
- Transformer
- 编写Transformer代码
- 双向编码器表征来自Transformer(BERT)
- 生成式预训练Transformer(GPT)
- 大语言模型(LLama)
- Mistral
本博客旨在在更深入地探讨自然语言处理(NLP)之前,提供对其的基础理解。此外,本博客还提供了多年来自然语言处理发展历程的见解。
1. 什么是自然语言处理(Natural Language Processing,NLP)
自然语言处理(Natural Language Processing,NLP)是构建能够以人类语言的书写、口语和组织方式来处理人类语言,或类似人类语言的数据的机器的学科。
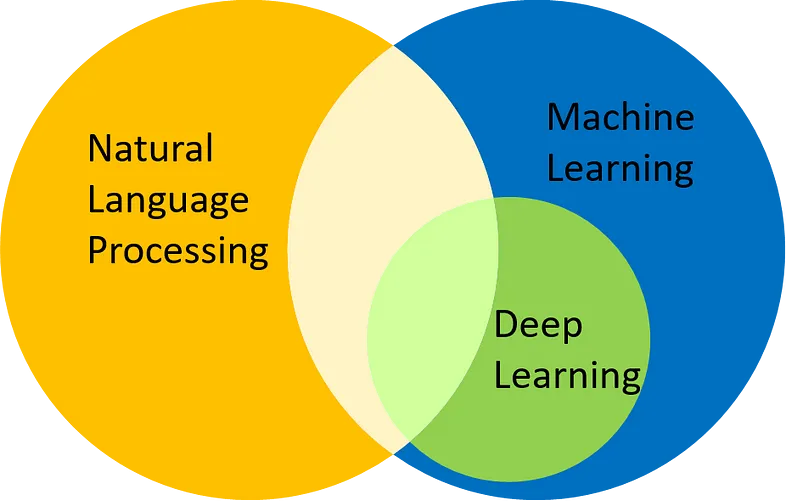
自然语言处理大致可分为两个相互重叠的领域:
- 自然语言理解(Natural Language Understanding,NLU),它处理对文本背后含义的解释。
- 自然语言生成(Natural Language Generation,NLG),它专注于生成模仿人类写作的文本。尽管与将口语转换为文本的语音识别不同,但自然语言处理通常与语音识别协同工作。
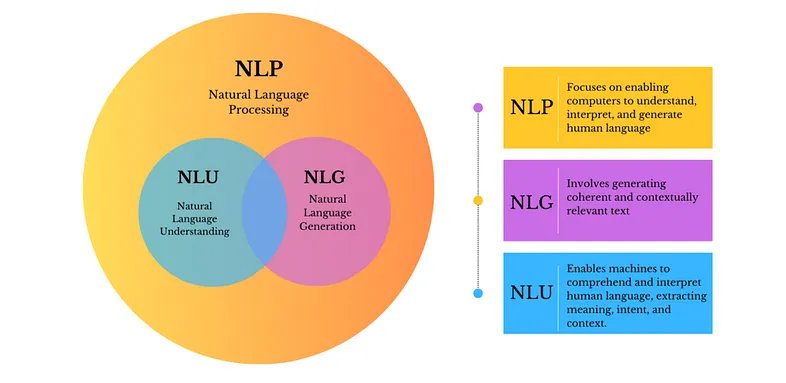
2. 自然语言处理的应用
自然语言处理(NLP)用于各种与语言相关的任务,包括回答问题、以各种方式对文本进行分类以及与用户对话。
以下是自然语言处理可以解决的一些任务:

2.1 情感分析:这涉及确定文本的情感基调。输入通常是一段文本,输出是一个概率分布,表明情感是积极的、消极的还是中性的。技术范围从传统方法,如词频 - 逆文档频率(TF - IDF)和N元语法(n - grams),到深度学习模型,如双向编码器表征来自变换器(BERT)和长短期记忆网络(LSTM)。

2.2 毒性分类:这是情感分析的一种特殊形式,毒性分类识别敌对意图,并将其分类为特定类型,如威胁或侮辱。这用于审核在线内容,确保更安全的数字空间。
2.3 机器翻译:这自动将文本从一种语言翻译成另一种语言。像OpenAI的生成式预训练变换器4(GPT - 4)和谷歌基于Transformer的模型等先进模型,在使翻译更准确且更具上下文感知方面处于领先地位。
2.4 命名实体识别(Named Entity Recognition,NER):命名实体识别模型从文本中提取并分类实体,如名称、组织和位置。这些模型在总结新闻和打击虚假信息方面至关重要。

2.5 垃圾邮件检测:垃圾邮件检测模型将电子邮件分类为垃圾邮件或非垃圾邮件,帮助像谷歌邮箱(Gmail)这样的电子邮件服务过滤掉不需要的消息。这些模型通常依赖于诸如逻辑回归、朴素贝叶斯或深度学习等技术。
2.6 语法错误纠正:纠正语法错误的模型广泛应用于像Grammarly这样的工具中。它们将语法纠正视为一个序列到序列的问题,其中输入是一个错误的句子,输出是一个纠正后的版本。
2.7 主题建模:主题建模识别文档语料库中的抽象主题。像潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)这样的技术常用于法律文档分析和内容推荐系统。
2.8 文本生成(自然语言生成,NLG):自然语言生成模型生成类似人类的文本,适用于从聊天机器人到内容创作等各种应用。像生成式预训练变换器4(GPT - 4)这样的现代模型能够在各种体裁中生成连贯且符合上下文的文本。
- 自动补全:自动补全系统预测序列中的下一个单词,应用于搜索引擎和消息应用程序等。像生成式预训练变换器3(GPT - 3)这样的模型在增强自动补全功能方面特别有效。
- 聊天机器人:聊天机器人通过查询数据库或生成对话来模拟人类对话。谷歌的语言模型对话应用(LaMDA)就是一个能够进行细致入微且类似人类对话的聊天机器人的例子。
2.9 信息检索:这涉及找到与查询相关的文档,这对搜索引擎和推荐系统至关重要。谷歌的最新模型使用多模态方法同时处理文本、图像和视频数据。

2.10 摘要:摘要是缩短文本以突出最重要信息的任务。摘要分为两种方法类别:
- 抽取式摘要:抽取式摘要专注于从长文本中提取最重要的句子,并将这些句子组合成一个摘要。通常,抽取式摘要会对输入文本中的每个句子进行评分,然后选择几个句子来形成摘要。
- 生成式摘要:生成式摘要通过释义来生成摘要。这类似于撰写摘要,其中包括原始文本中不存在的单词和句子。生成式摘要通常被建模为一个序列到序列的任务,其中输入是长文本,输出是一个摘要。
2.11 问答(Question Answering,QA):问答处理以自然语言提出的人类问题。问答领域最著名的例子之一是沃森(Watson),它在2011年参加了电视游戏节目《危险边缘》(Jeopardy),并以较大优势战胜了人类冠军。一般来说,问答任务有两种类型:
- 多项选择题:多项选择题问题由一个问题和一组可能的答案组成。学习任务是选择正确的答案。
- 开放域问题:在开放域问答中,模型在没有提供任何选项的情况下,以自然语言回答问题,通常通过查询大量文本。
3. 自然语言处理术语

3.1 文档(Document)
文档是一段单一的文本,它可以是从一个单句到一整本书的任何内容。它是自然语言处理模型处理的文本基本单元。文档的类型可以多种多样,例如电子邮件、网页、文章或推文。
示例:
- 一份来自报纸的单一新闻文章。
- 一条推文:“刚刚看了一部超棒的电影!”
- 一封电子邮件:“亲爱的约翰,希望你收到这封邮件时一切都好……”

3.2 语料库(Corpus,复数形式为Corpora)
语料库(复数形式为corpora)是大量文档的集合。它作为自然语言处理模型训练和评估的数据集。一个语料库通常包含按主题、语言或体裁相关的文档,并用于分析语言模式和构建统计模型。
示例:
- 某一特定报纸一年中所有文章的集合。
- 一个电子商务网站的客户评论数据集。
- 古登堡语料库(The Gutenberg Corpus):来自古登堡计划(Project Gutenberg)的文学文本集合。
3.3 特征(Feature)
特征是文本的一种可测量的属性或特征,用于机器学习模型中。特征是从文档中提取的,可以表示文本的各个方面,例如特定单词的存在、句子的长度或特定模式的出现。
示例:
- 词袋模型(Bag - of - Words,BoW):词汇表中的每个单词都是一个特征,其值是该单词在文档中的出现次数。
文档:“我喜欢自然语言处理(NLP)。”
特征:{“我”: 1, “喜欢”: 1, “自然语言处理(NLP)”: 1}
- 词频 - 逆文档频率(Term Frequency - Inverse Document Frequency,TF - IDF):一种用于评估一个单词在文档中相对于一个语料库的重要性的统计度量。
文档:“机器学习很有趣。”
特征(词频 - 逆文档频率得分):{“机器学习”: 0.5, “很有趣”: 0.5, “是”: 0.1, “有趣”: 0.7}
- 词性标注(Part of Speech,POS)标签:表示每个单词语法类别的特征(例如,名词、动词、形容词)。
文档:“那只敏捷的棕色狐狸跳了起来。”
特征:{“那只”: “限定词(DET)”, “敏捷的”: “形容词(ADJ)”, “棕色的”: “形容词(ADJ)”, “狐狸”: “名词(NOUN)”, “跳了起来”: “动词(VERB)”}
例如,让我们考虑下面显示的两个文档:
Sentences:
Dog hates a cat. It loves to go out and play.
Cat loves to play with a ball.
我们可以通过将上述两个文档组合在一起来构建一个语料库。
Corpus = “Dog hates a cat. It loves to go out and play. Cat loves to play with a ball.”
并且特征将是所有唯一的单词:
Fetaures: [‘and’, ‘ball’, ‘cat’, ‘dog’, ‘go’, ‘hates’, ‘it’, ‘loves’, ‘out’, ‘play’, ‘to’, ‘with’]
我们将其称为特征向量。在这里我们要记住,我们会将“a”视为单个字符而将其删除。
4. 自然语言处理是如何工作的?

自然语言处理(NLP)模型通过寻找语言组成部分之间的关系来工作,例如,在文本数据集中找到的字母、单词和句子。自然语言处理架构使用各种方法进行数据预处理、特征提取和建模。
为了更好地理解,让我们简化并分解这些步骤。
4.1 数据预处理
理解自然语言处理的第一步聚焦于在上下文框架内理解对话和语篇的含义。其主要目标是促进语音机器人和人类之间有意义的对话。
例如,向聊天机器人发出命令,如“给我展示最好的食谱”或“播放派对音乐”,就属于这一步的范畴。它涉及在正在进行的对话的上下文中理解并响应用户请求。
在模型为特定任务处理文本之前,通常需要对文本进行预处理,以提高模型性能,或将单词和字符转换为模型能够理解的格式。在这种数据预处理中可能会使用各种技术:
4.1.1 分词 Tokenization
将文本分解为称为“词元(token)”的较小单元的过程,这些词元可以是单词、子词或字符。
类型:
- 单词分词:将文本拆分为单个单词。
示例:
“I study Machine Learning on GeeksforGeeks.”
进行单词分词后为
[‘I’, ‘study’, ‘Machine’, ‘Learning’, ‘on’, ‘GeeksforGeeks’, ‘.’]
- 句子分词:将文本拆分为单个句子。
示例:
“I study Machine Learning on GeeksforGeeks. Currently, I’m studying NLP”
进行句子分词后为
[‘I study Machine Learning on GeeksforGeeks.’, ‘Currently, I’m studying NLP.’]
- 子词分词:将单词分解为更小的单元,如前缀、后缀或单个字符。
重要性:分词是许多自然语言处理流程的第一步,并且会影响后续的处理阶段。

4.1.2 词干提取 Stemming
定义:通过去除后缀和前缀,将单词还原为其词根形式的过程。
示例:单词“running”和“runner”经过词干提取后变为“run”。
与词形还原的区别:与词形还原相比,词干提取是一种更粗略的技术,并且可能并不总是生成真实的单词。
4.1.3 词形还原 Lemmatization
定义:将单词还原为其基本形式或词典形式的过程,这种基本形式被称为词元(lemma)。
示例:单词“running”和“ran”经过词形还原后变为“run”。
重要性:通过将一个单词的不同形式分组在一起,有助于理解单词的潜在含义。
词干提取器比词形还原器速度更快,计算成本更低。
from nltk.stem import WordNetLemmatizer
# 创建WordNetLemmatizer类的一个对象
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("plays", 'v'))
print(lemmatizer.lemmatize("played", 'v'))
print(lemmatizer.lemmatize("play", 'v'))
print(lemmatizer.lemmatize("playing", 'v'))
输出:
play
play
play
play
词形还原涉及将同一个单词的屈折形式分组在一起。通过这种方式,我们可以找到任何单词的基本形式,这种基本形式在本质上是有意义的。这里的基本形式被称为词元。
from nltk.stem import WordNetLemmatizer
# 创建WordNetLemmatizer类的一个对象
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("Communication", 'v'))
输出:
Communication
词形还原器比词干提取器速度更慢,计算成本更高。
4.1.4 规范化
自然语言处理(NLP)中的规范化是指将文本转换为标准形式的过程。规范化的目的是确保文本数据处理的一致性,使自然语言处理模型能够更好地理解和解释文本。一些常见的规范化技术包括将文本转换为小写形式、词干提取、词形还原,以及去除停用词或标点符号。
转换为小写:
将文本中的所有字符转换为小写,以确保像“Apple”和“apple”这样的单词被视为同一个单词。
示例:“Apple” -> “apple”去除标点符号:
在自然语言处理任务中,标点符号通常不携带重要意义,因此它们经常被去除。
示例:“Hello, world!” -> “Hello world”去除停用词:
停用词是常见的单词(如“and”、“the”、“is”),它们可能对文本的含义贡献不大,并且经常被去除。
示例:“This is a pen” -> “pen”
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer, WordNetLemmatizer
import re
# 下载必要的NLTK数据
nltk.download('punkt')
nltk.download('wordnet')
nltk.download('stopwords')
# 示例文本
text = "跑步比走路更好!苹果和橙子是不同的。"("Running is better than walking! Apples and oranges are different.")
# 转换为小写
text_lower = text.lower()
print("转换为小写后的文本:", text_lower)
# 去除标点符号
text_no_punct = re.sub(r'[^\w\s]', '', text_lower)
print("没有标点符号的文本:", text_no_punct)
# 分词
words = nltk.word_tokenize(text_no_punct)
print("分词后的单词:", words)
# 去除停用词
stop_words = set(stopwords.words('english'))
words_no_stop = [word for word in words if word not in stop_words]
print("没有停用词的文本:", words_no_stop)
# 词干提取
ps = PorterStemmer()
words_stemmed = [ps.stem(word) for word in words_no_stop]
print("词干提取后的单词:", words_stemmed)
# 词形还原
lemmatizer = WordNetLemmatizer()
words_lemmatized = [lemmatizer.lemmatize(word) for word in words_no_stop]
print("词形还原后的单词:", words_lemmatized)
输出:
转换为小写后的文本: running is better than walking! apples and oranges are different.
没有标点符号的文本: running is better than walking apples and oranges are different
分词后的单词: ['running', 'is', 'better', 'than', 'walking', 'apples', 'and', 'oranges', 'are', 'different']
没有停用词的文本: ['running', 'better', 'walking', 'apples', 'oranges', 'different']
词干提取后的单词: ['run', 'better', 'walk', 'appl', 'orang', 'differ']
词形还原后的单词: ['running', 'better', 'walking', 'apple', 'orange', 'different']
4.1.5 词性标注 Part of Speech (POS) Tagging
定义:为句子中的每个单词分配词性(如名词、动词、形容词等)的过程。
重要性:有助于理解句子的语法结构和含义。
示例:
“GeeksforGeeks is a Computer Science platform.”
让我们看看NLTK的词性标注器将如何标注这个句子。
from nltk import pos_tag
from nltk import word_tokenize
text = "GeeksforGeeks is a Computer Science platform."
tokenized_text = word_tokenize(text)
tags = tokens_tag = pos_tag(tokenized_text)
tags
输出:
[('GeeksforGeeks', 'NNP'),
('is', 'VBZ'),
('a', 'DT'),
('Computer', 'NNP'),
('Science', 'NNP'),
('platform', 'NN'),
('.', '.')]
4.2 特征提取
大多数传统的机器学习技术都处理特征——通常是描述文档与包含该文档的语料库之间关系的数字——这些特征由词袋模型(Bag-of-Words)、词频-逆文档频率(TF-IDF)或一般的特征工程(如文档长度、单词极性和元数据(例如,如果文本有相关的标签或分数))创建。更新的技术包括Word2Vec、GloVE,以及在神经网络的训练过程中学习特征。
4.2.1 词袋模型(Bag-of-Words,BoW)
定义:一种文本数据的表示方法,其中每个文档都被表示为其单词的一个集合(多重集),不考虑语法和单词顺序,但保留单词的出现次数。
词袋模型是自然语言处理中常用的一种技术,其中文本中的每个单词都被表示为一个特征,其出现频率被用作特征值。
重要性:简化了文本处理,并被用于各种自然语言处理应用中,如文本分类和信息检索。
from sklearn.feature_extraction.text import CountVectorizer
# 示例文本数据
documents = [
"巴拉克·奥巴马是美国第44任总统。"("Barack Obama was the 44th President of the United States"),
"总统住在白宫。"("The President lives in the White House"),
"美国拥有强大的经济。"("The United States has a strong economy")
]
# 初始化CountVectorizer
vectorizer = CountVectorizer()
# 拟合模型并将文档转换为词袋模型表示
bow_matrix = vectorizer.fit_transform(documents)
# 获取特征名称(语料库中的唯一单词)
feature_names = vectorizer.get_feature_names_out()
# 将词袋模型矩阵转换为数组
bow_array = bow_matrix.toarray()
# 显示词袋模型
print("特征名称(单词):", feature_names)
print("\n词袋模型表示:")
print(bow_array)
输出:
特征名称(单词): ['44th', 'barack', 'economy', 'has', 'house', 'in', 'lives', 'obama', 'of', 'president','states','strong', 'the', 'united', 'was', 'white']
词袋模型表示:
[[1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 2, 1, 1, 0],
[0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 2, 0, 0, 1],
[0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0]]

4.2.2 词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)
定义:词频-逆文档频率(TF-IDF)是一种用于评估一个单词在文档中相对于一组文档(或语料库)的重要性的数值统计量。其基本思想是,如果一个单词在某一文档中频繁出现,但在其他许多文档中不常出现,那么它应该被赋予更高的重要性。
对于语料库 D D D中的文档 d d d里的一个词项 t t t,其TF-IDF分数是通过两个度量值的乘积来计算的:词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF)。
词频(Term Frequency,TF)
词频(TF)衡量一个词项在文档中出现的频繁程度。为了避免对较长文档产生偏差,它通常会用文档中的词项总数进行归一化处理。

逆文档频率(Inverse Document Frequency,IDF)
逆文档频率(IDF)衡量一个词项在整个语料库中的重要程度。它会降低在许多文档中都出现的词项的权重,而增加在较少文档中出现的词项的权重。

在分母上加“ + 1 +1 +1”是为了防止在词项未在任何文档中出现的情况下出现除零错误。
- 结合词频和逆文档频率:TF-IDF
对于文档 d d d中的词项 t t t,TF-IDF分数是通过将其词频(TF)值与逆文档频率(IDF)值相乘来计算的:

重要性:有助于识别文档中的重要单词,并且常用于信息检索和文本挖掘中。
from sklearn.feature_extraction.text import TfidfVectorizer
# 示例文本数据(文档)
documents = [
"猫坐在垫子上。"("The cat sat on the mat."),
"猫坐在床上。"("The cat sat on the bed."),
"狗叫了。"("The dog barked.")
]
# 初始化TfidfVectorizer
vectorizer = TfidfVectorizer()
# 拟合模型并将文档转换为TF-IDF表示形式
tfidf_matrix = vectorizer.fit_transform(documents)
# 获取特征名称(语料库中的唯一单词)
feature_names = vectorizer.get_feature_names_out()
# 将TF-IDF矩阵转换为数组
tfidf_array = tfidf_matrix.toarray()
# 显示TF-IDF矩阵
print("特征名称(单词):", feature_names)
print("\nTF-IDF矩阵:")
print(tfidf_array)
输出:
特征名称(单词): ['barked', 'bed', 'cat', 'dog','mat', 'on','sat', 'the']
TF-IDF矩阵:
[[0. 0. 0.37420726 0. 0.49203758 0.37420726
0.37420726 0.58121064]
[0. 0.49203758 0.37420726 0. 0. 0.37420726
0.37420726 0.58121064]
[0.65249088 0. 0. 0.65249088 0. 0.
0. 0.38537163]]

4.2.3 N元语法(N-grams)
定义:从给定的文本或语音中提取的 n n n个项目(通常是单词或字符)的连续序列。
类型:
- 一元语法(Unigram):单个单词。
- 二元语法(Bigram):一对单词。
- 三元语法(Trigram):三个单词的序列。
重要性:捕捉文本中的上下文和单词之间的依赖关系。
import nltk
from nltk.util import ngrams
from collections import Counter
# 示例文本数据
text = "那只敏捷的棕色狐狸跳过了那只懒惰的狗。"("The quick brown fox jumps over the lazy dog")
# 将文本分词为单词
tokens = nltk.word_tokenize(text)
# 生成一元语法(1-gram)
unigrams = list(ngrams(tokens, 1))
print("一元语法:")
print(unigrams)
# 生成二元语法(2-gram)
bigrams = list(ngrams(tokens, 2))
print("\n二元语法:")
print(bigrams)
# 生成三元语法(3-gram)
trigrams = list(ngrams(tokens, 3))
print("\n三元语法:")
print(trigrams)
# 计算每个N元语法的频率(用于演示)
unigram_freq = Counter(unigrams)
bigram_freq = Counter(bigrams)
trigram_freq = Counter(trigrams)
# 打印频率(可选)
print("\n一元语法频率:")
print(unigram_freq)
print("\n二元语法频率:")
print(bigram_freq)
print("\n三元语法频率:")
print(trigram_freq)
输出:
一元语法:
[('The',), ('quick',), ('brown',), ('fox',), ('jumps',), ('over',), ('the',), ('lazy',), ('dog',)]
二元语法:
[('The', 'quick'), ('quick', 'brown'), ('brown', 'fox'), ('fox', 'jumps'), ('jumps', 'over'), ('over', 'the'), ('the', 'lazy'), ('lazy', 'dog')]
三元语法:
[('The', 'quick', 'brown'), ('quick', 'brown', 'fox'), ('brown', 'fox', 'jumps'), ('fox', 'jumps', 'over'), ('jumps', 'over', 'the'), ('over', 'the', 'lazy'), ('the', 'lazy', 'dog')]
一元语法频率:
Counter({('The',): 1, ('quick',): 1, ('brown',): 1, ('fox',): 1, ('jumps',): 1, ('over',): 1, ('the',): 1, ('lazy',): 1, ('dog',): 1})
二元语法频率:
Counter({('The', 'quick'): 1, ('quick', 'brown'): 1, ('brown', 'fox'): 1, ('fox', 'jumps'): 1, ('jumps', 'over'): 1, ('over', 'the'): 1, ('the', 'lazy'): 1, ('lazy', 'dog'): 1})
三元语法频率:
Counter({('The', 'quick', 'brown'): 1, ('quick', 'brown', 'fox'): 1, ('brown', 'fox', 'jumps'): 1, ('fox', 'jumps', 'over'): 1, ('jumps', 'over', 'the'): 1, ('over', 'the', 'lazy'): 1, ('the', 'lazy', 'dog'): 1})
4.2.4 词嵌入(Word Embeddings)
定义:词嵌入是单词的一种密集向量表示形式,它捕捉了单词的含义、句法属性以及与其他单词的关系。与像词袋模型或词频-逆文档频率(TF-IDF)这样的传统方法不同,后两者将单词视为离散的实体,而词嵌入将单词映射到一个连续的向量空间中,在这个空间中语义相似的单词彼此靠近。
示例:Word2Vec、GloVe、FastText。
重要性:捕捉单词之间的语义关系,并被用于各种自然语言处理(NLP)模型和应用中。
import gensim
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
import nltk
# 示例文本数据
text = [
"猫坐在垫子上。"("The cat sat on the mat"),
"狗对着猫叫。"("The dog barked at the cat"),
"猫追着老鼠。"("The cat chased the mouse"),
"狗追着猫。"("The dog chased the cat"),
]
# 将句子分词为单词
tokenized_text = [word_tokenize(sentence.lower()) for sentence in text]
# 在分词后的文本上训练一个Word2Vec模型
model = Word2Vec(tokenized_text, vector_size=100, window=5, min_count=1, sg=0)
# 获取特定单词“cat”(猫)的词嵌入
cat_vector = model.wv['cat']
# 打印“cat”(猫)的词嵌入
print("单词“cat”的词嵌入:")
print(cat_vector)
# 找到与“cat”(猫)最相似的单词
similar_words = model.wv.most_similar('cat', topn=3)
print("\n与“cat”最相似的单词:")
print(similar_words)
输出:
单词“cat”的词嵌入:
[-8.6196875e-03 3.6657380e-03 5.1898835e-03 5.7419385e-03
7.4669183e-03 -6.1676754e-03 1.1056137e-03 6.0472824e-03
-2.8400505e-03 -6.1735227e-03 -4.1022300e-04 -8.3689485e-03
-5.6000124e-03 7.1045388e-03 3.3525396e-03 7.2256695e-03
6.8002474e-03 7.5307419e-03 -3.7891543e-03 -5.6180597e-04
2.3483764e-03 -4.5190323e-03 8.3887316e-03 -9.8581640e-03
6.7646410e-03 2.9144168e-03 -4.9328315e-03 4.3981876e-03
-1.7395747e-03 6.7113843e-03 9.9648498e-03 -4.3624435e-03
-5.9933780e-04 -5.6956373e-03 3.8508223e-03 2.7866268e-03
6.8910765e-03 6.1010956e-03 9.5384968e-03 9.2734173e-03
7.8980681e-03 -6.9895042e-03 -9.1558648e-03 -3.5575271e-04
-3.0998408e-03 7.8943167e-03 5.9385742e-03 -1.5456629e-03
1.5109634e-03 1.7900408e-03 7.8175711e-03 -9.5101865e-03
-2.0553112e-04 3.4691966e-03 -9.3897223e-04 8.3817719e-03
9.0107834e-03 6.5365066e-03 -7.1162102e-04 7.7104042e-03
-8.5343346e-03 3.2071066e-03 -4.6379971e-03 -5.0889552e-03
3.5896183e-03 5.3703394e-03 7.7695143e-03 -5.7665063e-03
7.4333609e-03 6.6254963e-03 -3.7098003e-03 -8.7456414e-03
5.4374672e-03 6.5097557e-03 -7.8755023e-04 -6.7098560e-03
-7.0859254e-03 -2.4970602e-03 5.1432536e-03 -3.6652375e-03
-9.3700597e-03 3.8267397e-03 4.8844791e-03 -6.4285635e-03
1.2085581e-03 -2.0748770e-03 2.4403334e-05 -9.8835090e-03
2.6920044e-03 -4.7501065e-03 1.0876465e-03 -1.5762246e-03
2.1966731e-03 -7.8815762e-03 -2.7171839e-03 2.6631986e-03
5.3466819e-03 -2.3915148e-03 -9.5100943e-03 4.5058788e-03]
与“cat”最相似的单词:
[('dog', 0.06797593832015991), ('on', 0.033640578389167786), ('at', 0.009391162544488907)]
4.2.5 上下文词嵌入(Contextual Word Embeddings)
定义:上下文词嵌入基于单词在句子中的上下文来捕捉其含义。与传统的词嵌入(如Word2Vec)不同,传统词嵌入为每个单词提供一个单一的向量,而不考虑上下文,上下文词嵌入会根据周围的单词为一个单词生成不同的向量。这些嵌入是使用像BERT(双向编码器表征来自变换器,Bidirectional Encoder Representations from Transformers)这样的模型生成的,BERT在计算单词表示时会考虑整个句子。
示例:ELMo、BERT、GPT。
重要性:通过考虑周围的上下文,提供更准确的单词表示。
from transformers import BertModel, BertTokenizer
import torch
# Load pre-trained BERT model and tokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
# Example sentence
sentence = "The cat sat on the mat."
# Tokenize the input sentence and convert tokens to tensor
input_ids = tokenizer.encode(sentence, return_tensors='pt')
# Pass the input through the BERT model to get embeddings
with torch.no_grad():
outputs = model(input_ids)
last_hidden_states = outputs.last_hidden_state
# Print the shape of the last hidden states tensor
print("Shape of last hidden states:", last_hidden_states.shape)
# Convert the embeddings to numpy array (for easier manipulation)
embeddings = last_hidden_states.squeeze().numpy()
# Tokenize the sentence to match embeddings to words
tokens = tokenizer.convert_ids_to_tokens(input_ids.squeeze())
# Print the tokens and their corresponding contextual embeddings
for token, embedding in zip(tokens, embeddings):
print(f"Token: {token}")
print(f"Embedding: {embedding[:10]}...") # Print first 10 dimensions for brevity
print()
输出:
Shape of last hidden states: torch.Size([1, 9, 768])
Token: [CLS]
Embedding: [-0.3642237 -0.05305378 -0.36732262 -0.02967339 -0.460784 -0.10106134
0.01669817 0.59577715 -0.11770311 0.10289837]...
Token: the
Embedding: [-0.3978658 -0.27210808 -0.68196577 -0.00734524 0.7860015 0.17661774
0.05241349 0.72017133 0.07858636 -0.1736162 ]...
Token: cat
Embedding: [-0.35117194 -0.07356024 -0.06913986 -0.13987705 0.68294847 0.11350538
0.20849192 0.56738263 0.4069492 -0.2134663 ]...
Token: sat
Embedding: [ 0.07117955 -0.31366652 0.09802647 0.06934201 0.4834015 -0.40465042
-0.5492254 0.91489977 -0.19875513 0.16641603]...
Token: on
Embedding: [-0.5203689 -0.59298277 0.28364897 0.31230223 0.611251 -0.07076924
-1.1455988 0.3248083 -0.40707844 -0.04888151]...
Token: the
Embedding: [-0.46198413 -0.5197541 -0.37599826 0.5099069 0.47716403 -0.41718286
-0.4499631 0.41355488 -0.52844054 -0.38209906]...
Token: mat
Embedding: [-0.0415443 -0.10548864 -0.28080556 0.5944824 0.05494812 -0.33329046
0.23721729 0.21435769 -0.5872034 -0.5192848 ]...
Token: .
Embedding: [-0.23536152 -0.4874898 -0.16314735 0.24718559 0.16603808 -0.10894424
-0.47729397 0.72053766 -0.12877737 -0.6664553 ]...
Token: [SEP]
Embedding: [ 0.66511077 0.02249792 -0.41309452 0.34166738 -0.2383636 -0.40086323
0.6143277 0.11614177 0.33811757 0.20712788]...
4.3 建模
数据经过预处理后,会被输入到一个自然语言处理(NLP)架构中,该架构对数据进行建模,以完成各种任务。
- 根据手头的任务,通过上述技术提取的数值特征可以输入到各种模型中。例如,对于分类任务,词频 - 逆文档频率(TF-IDF)向量器的输出可以提供给逻辑回归、朴素贝叶斯、决策树或梯度提升树模型。或者,对于命名实体识别任务,我们可以结合使用隐马尔可夫模型和N元语法。
- 深度神经网络通常在不使用提取特征的情况下工作,尽管我们仍然可以将TF-IDF或词袋模型的特征作为输入。
- 语言模型:从非常基础的角度来说,语言模型的目标是在给定一系列输入单词时,预测下一个单词。使用马尔可夫假设的概率模型就是一个例子:

深度学习也被用于创建这样的语言模型。深度学习模型将词嵌入作为输入,并在每个时间状态下,返回下一个单词的概率分布,即字典中每个单词的概率。预训练的语言模型通过处理大型语料库(如维基百科)来学习特定语言的结构。然后,它们可以针对特定任务进行微调。例如,BERT已经针对从事实核查到撰写标题等一系列任务进行了微调。
4.3.1 命名实体识别(Named Entity Recognition,NER)
定义:在文本中识别命名实体,并将其分类为预定义类别的过程,这些类别包括人名、组织名、地点、日期等。
示例:在句子“巴拉克·奥巴马(Barack Obama)是美国(the United States)的第44任总统”中,“巴拉克·奥巴马(Barack Obama)”被识别为人名,“美国(the United States)”被识别为地理政治实体(Geopolitical Entity,GPE)。
import spacy
# 从spacy加载预训练的NLP模型
nlp = spacy.load('en_core_web_sm')
# 我们要进行命名实体识别的句子
sentence = "Barack Obama was the 44th President of the United States."
# 使用NLP模型处理句子
doc = nlp(sentence)
# 打印句子中识别出的命名实体
print("句子中的命名实体:")
for ent in doc.ents:
print(f"{ent.text}: {ent.label_}")
输出:
句子中的命名实体:
Barack Obama: PERSON
44th: ORDINAL
the United States: GPE
4.3.2 语言模型
定义:语言模型是一种统计模型,用于预测单词序列中的下一个单词。它为单词序列分配概率,有助于确定给定序列出现的可能性。语言模型在各种自然语言处理(NLP)任务中是基础,如文本生成、机器翻译和语音识别。
类型:
- 一元语法模型(Unigram Model):根据每个单词自身的概率独立预测该单词。
- 二元语法/三元语法模型(Bigram/Trigram Model):根据前一个或前两个单词预测一个单词。
- 神经语言模型(Neural Language Models):使用神经网络,如循环神经网络(Recurrent Neural Networks,RNNs)或变换器(Transformers),来捕捉文本中更复杂的模式和依赖关系。
重要性:在文本生成、机器翻译和语音识别等任务中起着基础性作用。
import nltk
from collections import defaultdict, Counter
import random
# 示例文本数据(语料库)
corpus = [
"我喜欢自然语言处理",
"我喜欢机器学习",
"我喜欢学习新事物",
"自然语言处理很有趣"
]
# 将句子分词为单词
tokenized_corpus = [nltk.word_tokenize(sentence.lower()) for sentence in corpus]
# 从分词后的语料库中创建二元语法
bigrams = []
for sentence in tokenized_corpus:
bigrams.extend(list(nltk.bigrams(sentence)))
# 计算二元语法的频率
bigram_freq = defaultdict(Counter)
for w1, w2 in bigrams:
bigram_freq[w1][w2] += 1
# 计算二元语法的概率
bigram_prob = defaultdict(dict)
for w1 in bigram_freq:
total_count = float(sum(bigram_freq[w1].values()))
for w2 in bigram_freq[w1]:
bigram_prob[w1][w2] = bigram_freq[w1][w2] / total_count
# 使用二元语法模型生成文本的函数
def generate_sentence(start_word, num_words=10):
current_word = start_word
sentence = [current_word]
for _ in range(num_words - 1):
if current_word in bigram_prob:
next_word = random.choices(
list(bigram_prob[current_word].keys()),
list(bigram_prob[current_word].values())
)[0]
sentence.append(next_word)
current_word = next_word
else:
break
return ' '.join(sentence)
# 以单词“i”开头生成一个句子
generated_sentence = generate_sentence("i", num_words=4)
print("生成的句子:", generated_sentence)
输出:
生成的句子: i love natural language
4.3.3 传统机器学习自然语言处理技术:
- 逻辑回归是一种监督分类算法,旨在根据一些输入来预测某个事件发生的概率。在自然语言处理中,逻辑回归模型可以应用于解决诸如情感分析、垃圾邮件检测和毒性分类等问题。
- 朴素贝叶斯 是一种监督分类算法,它使用以下贝叶斯公式来找到条件概率分布
P(label | text):

并根据哪个联合分布具有最高概率来进行预测。朴素贝叶斯模型中的朴素假设是单个单词之间是相互独立的。因此:

在自然语言处理中,这种统计方法可以应用于解决诸如垃圾邮件检测或在软件代码中查找错误等问题。

- 潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)用于主题建模。LDA试图将一个文档视为一组主题的集合,而将一个主题视为一组单词的集合。LDA是一种统计方法。其背后的逻辑是,我们可以仅使用语料库中的一小部分单词来描述任何主题。
- 隐马尔可夫模型:马尔可夫模型是一种概率模型,它根据系统的当前状态来决定系统的下一个状态。例如,在自然语言处理中,我们可能会根据前一个单词来推测下一个单词。我们可以将此建模为一个马尔可夫模型,在其中我们可以找到从单词1到单词2的转移概率,即P(单词1|单词2)。然后,我们可以使用这些转移概率的乘积来找到一个句子的概率。隐马尔可夫模型(Hidden Markov Model,HMM)是一种概率建模技术,它为马尔可夫模型引入了一个隐藏状态。隐藏状态是数据的一种属性,它不能被直接观察到。HMM被用于词性标注,其中句子中的单词是观察到的状态,而词性标签是隐藏状态。HMM引入了一个称为发射概率的概念,即给定隐藏状态下观察到某个值的概率。在前面的例子中,这就是给定词性标签下一个单词出现的概率。HMM假设这个概率可以反过来计算:给定一个句子,我们可以根据一个单词具有某个词性标签的可能性,以及一个特定词性标签跟随在前一个单词的词性标签之后的概率,来计算每个单词的词性标签。在实践中,这是使用Viterbi算法来解决的。

4.3.4 深度学习自然语言处理技术
- 卷积神经网络(Convolutional Neural Network,CNN):使用CNN对文本进行分类的想法最早出现在尹基姆(Yoon Kim)的论文《用于句子分类的卷积神经网络》(“Convolutional Neural Networks for Sentence Classification”)中。其核心思路是将文档视为一幅图像。然而,输入不是像素,而是表示为单词矩阵的句子或文档。

- 循环神经网络(Recurrent Neural Network,RNN):许多使用深度学习进行文本分类的技术会使用N元语法或窗口(如CNN)来处理相邻的单词。它们可以将“New York”视为一个单独的实例。然而,它们无法捕捉特定文本序列所提供的上下文。它们无法学习数据的顺序结构,在这种结构中,每个单词都依赖于前一个单词或前一个句子中的某个单词。RNN使用隐藏状态记住先前的信息,并将其与当前任务联系起来。被称为门控循环单元(Gated Recurrent Unit,GRU)和长短期记忆(Long Short-Term Memory,LSTM)的架构是RNN的一种,旨在长时间记住信息。此外,双向LSTM/GRU可以保留两个方向的上下文信息,这对文本分类很有帮助。RNN还被用于生成数学证明,以及将人类的想法转化为文字。

- 自动编码器(Autoencoders):这些是深度学习的编码器 - 解码器,它们近似于从X到X的映射,即输入等于输出。它们首先将输入特征压缩为低维表示(有时称为潜在编码、潜在向量或潜在表示),然后学习重构输入。表示向量可以用作单独模型的输入,因此这种技术可用于降维。在许多其他领域的专家中,遗传学家已经应用自动编码器来识别氨基酸序列中与疾病相关的突变。

- 编码器-解码器 序列到序列 模型(Encoder-decoder sequence-to-sequence):编码器-解码器 序列到序列架构是对自动编码器的一种改进,专门用于翻译、摘要和类似任务。编码器将文本中的信息封装到一个编码向量中。与自动编码器不同的是,解码器的任务不是从编码向量重构输入,而是生成不同的期望输出,比如翻译或摘要。

- 变换器(Transformers):变换器是一种模型架构,最早在2017年的论文《Attention Is All You Need》中描述。它摒弃了循环结构,而是完全依赖于自注意力机制来得出输入和输出之间的全局依赖关系。由于这种机制可以一次性处理所有单词(而不是一次处理一个单词),与RNN相比,它降低了训练速度和推理成本,特别是因为它具有并行性。近年来,变换器架构彻底改变了自然语言处理领域,产生了包括BLOOM、Jurassic-X和Turing-NLG等模型。它也已成功应用于各种不同的计算机视觉任务,包括生成3D图像。

Transformer模型的关键概念
- 自注意力机制(Self-Attention Mechanism):
自注意力机制允许模型在生成输出的每个部分时,关注输入序列的不同部分。它计算输入特征的加权和,权重由每个特征与其他特征的相关性决定。 - 多头注意力(Multi-Head Attention):
模型使用不同的权重矩阵(头)多次计算注意力,然后将结果连接起来。这使模型能够捕捉单词之间关系的不同方面。 - 位置编码(Positional Encoding):
由于变换器没有内置的单词顺序感知(与RNN不同),因此会将位置编码添加到输入嵌入中,以提供关于序列中每个单词位置的信息。 - 前馈神经网络(Feedforward Neural Network):
在注意力机制之后,数据会通过一个前馈神经网络,该网络会分别且相同地应用于每个位置。 - 层归一化和残差连接(Layer Normalization and Residual Connections):
变换器模型中的每个子层都使用残差连接,然后进行层归一化,这有助于稳定深度模型的训练。
重要性:由于其捕捉长距离依赖关系和并行计算的能力,在许多自然语言处理任务中处于领先水平。
import torch
import torch.nn as nn
import math
class TransformerModel(nn.Module):
def __init__(self, input_dim, model_dim, num_heads, num_layers, ffn_dim, max_seq_len, num_classes):
super(TransformerModel, self).__init__()
self.embedding = nn.Embedding(input_dim, model_dim)
self.model_dim = model_dim
self.layers = nn.ModuleList([
TransformerLayer(model_dim, num_heads, ffn_dim)
for _ in range(num_layers)
])
self.fc_out = nn.Linear(model_dim, num_classes)
def forward(self, x):
seq_len = x.size(1)
positional_encoding = self._generate_positional_encoding(seq_len)
x = self.embedding(x) + positional_encoding
for layer in self.layers:
x = layer(x)
return self.fc_out(x.mean(dim=1))
def _generate_positional_encoding(self, seq_len):
positional_encoding = torch.zeros(seq_len, self.model_dim)
for pos in range(seq_len):
for i in range(0, self.model_dim, 2):
positional_encoding[pos, i] = math.sin(pos / (10000 ** (i / self.model_dim)))
positional_encoding[pos, i + 1] = math.cos(pos / (10000 ** ((i + 1) / self.model_dim)))
return positional_encoding.unsqueeze(0)
class TransformerLayer(nn.Module):
def __init__(self, model_dim, num_heads, ffn_dim):
super(TransformerLayer, self).__init__()
self.multihead_attention = nn.MultiheadAttention(embed_dim=model_dim, num_heads=num_heads)
self.norm1 = nn.LayerNorm(model_dim)
self.ffn = nn.Sequential(
nn.Linear(model_dim, ffn_dim),
nn.ReLU(),
nn.Linear(ffn_dim, model_dim)
)
self.norm2 = nn.LayerNorm(model_dim)
def forward(self, x):
attn_output, _ = self.multihead_attention(x, x, x)
x = self.norm1(x + attn_output)
ffn_output = self.ffn(x)
x = self.norm2(x + ffn_output)
return x
# 示例用法:
input_dim = 10000 # 词汇表大小
model_dim = 512
num_heads = 8
num_layers = 6
ffn_dim = 2048
max_seq_len = 100
num_classes = 10
# 实例化模型
model = TransformerModel(input_dim, model_dim, num_heads, num_layers, ffn_dim, max_seq_len, num_classes)
# 示例输入 (batch_size=32, sequence_length=50)
x = torch.randint(0, input_dim, (32, 50))
# 前向传播
output = model(x)
print("输出形状:", output.shape)
输出:
输出形状: torch.Size([32, 10])
4.3.5 注意力机制
定义:一种允许模型在进行预测时关注输入序列不同部分的技术。
重要性:通过提供上下文相关信息,提高序列到序列任务的性能。
4.3.6 序列到序列(Sequence-to-Sequence,Seq2Seq)模型
定义:一种用于输入和输出都是序列的任务的模型架构,例如机器翻译。
组件:通常包括一个编码器和一个解码器,经常使用RNN、LSTM或变换器。
重要性:用于翻译、摘要和对话系统等任务。
4.3.7 迁移学习 Transfer Learning
定义:在新的、相关的任务上使用预训练模型,并进行最少的额外训练的技术。
重要性:允许利用现有知识,减少对大型标注数据集和大量训练的需求。
4.3.8 微调
定义:采用预训练模型,并使用额外的训练数据使其适应特定任务的过程。
重要性:提高预训练模型在特定任务应用中的性能。
4.3.9 零样本学习 Zero-Shot Learning
定义:模型利用通用知识来执行其未经过明确训练的任务的能力。
重要性:展示了模型的泛化能力以及在没有特定任务训练数据的情况下适应新任务的能力。
4.3.10 少样本学习
定义:模型从极少数示例中学习的能力。
重要性:减少对大量标注数据的需求,并展示了模型快速适应新任务的能力。
5. 自然语言处理模型和技术的比较分析
让我们将每种模型和技术与其前身进行对比分析,突出它们的优势和局限性:
词袋模型(BoW)与词频-逆文档频率(TF-IDF):词袋模型统计文档中单词的出现次数,而词频-逆文档频率(TF-IDF)则根据单词在文档以及整个语料库中的重要性为其赋予权重。TF-IDF通过赋予稀有单词更高的重要性,解决了词袋模型的一个关键局限性,从而更有效地捕捉文档的含义。然而,这两种方法都没有考虑单词的顺序和上下文,导致语义信息的丢失。
Word2Vec与词袋模型和TF-IDF:Word2Vec是一种基于神经网络的技术,它学习连续的词嵌入,能够捕捉单词之间的语义关系。与词袋模型和TF-IDF不同,Word2Vec保留了上下文信息,并在一个密集的向量空间中表示单词,使其能够捕捉同义词、反义词和类比等语义关系。然而,Word2Vec也有其局限性,例如难以处理未登录词(OOV),以及无法根据上下文捕捉一个单词的不同含义(一词多义)。
循环神经网络(RNN,包括长短期记忆网络LSTM和门控循环单元GRU)与Word2Vec:虽然Word2Vec专注于单词表示,但循环神经网络(RNN)是为对包括文本在内的数据序列进行建模而设计的。RNN可以处理不同长度的输入序列,并维护一个隐藏状态,该状态捕获了来自先前时间步的信息。这使得RNN比Word2Vec更适合处理涉及时间依赖关系的任务,如情感分析或机器翻译。
长短期记忆网络(LSTM)和门控循环单元(GRU)与普通循环神经网络(Vanilla RNN):普通循环神经网络存在梯度消失问题,这阻碍了它们学习长距离依赖关系的能力。长短期记忆网络(LSTM)和门控循环单元(GRU)是RNN的变体,通过引入门控机制来有效捕捉长期依赖关系,从而克服了这一局限性。然而,包括LSTM和GRU在内的RNN计算成本可能很高,尤其是对于长序列。
双向长短期记忆网络(Bi-directional LSTM)与长短期记忆网络(LSTM):双向长短期记忆网络通过对输入序列进行正向和反向处理,扩展了传统的LSTM。这使得模型能够捕捉来自过去和未来上下文的信息,通常在命名实体识别和情感分析等任务中能提高性能。然而,由于增加了反向传播过程,这种方法比标准的LSTM计算量更大。
变换器(Transformer)与循环神经网络(RNN,如LSTM、GRU):变换器是一种神经网络架构,它利用自注意力机制对序列中单词之间的依赖关系进行建模。与RNN不同,变换器可以并行处理输入序列,使其在计算上更高效,特别是对于长序列。此外,变换器在捕捉长距离依赖关系方面更有效,因为它们不像RNN那样受序列长度的限制。然而,由于自注意力机制,变换器可能会占用大量内存,并且通常需要大量的训练数据才能达到最佳性能。
6. 自然语言处理的发展历程
到目前为止,我们已经对自然语言处理有了很好的理解。让我们来探究一下自然语言处理的发展历程,以便全面了解其演变过程。
在后续的博客中,我们将详细讨论其中的每一个方面。
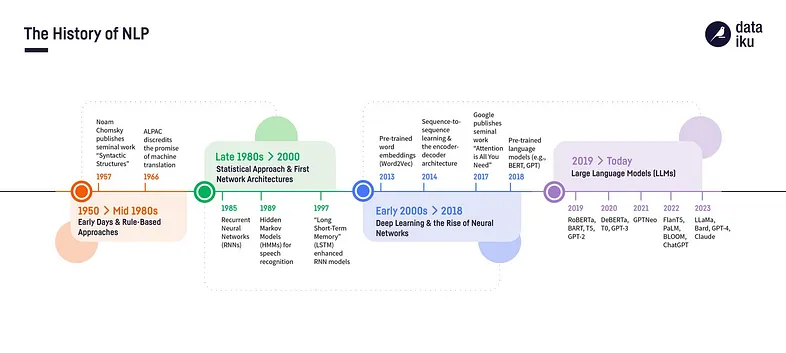
自20世纪50年代诞生以来,自然语言处理(NLP)经历了显著的变革。这段历程可以分为不同的阶段,每个阶段都以突破性的进展和创新为标志。让我们深入探讨自然语言处理的发展历程,从早期基于规则的系统到如今我们所见到的复杂的大语言模型(LLMs)。
6.1 20世纪50年代至80年代中期:早期阶段与基于规则的方法
自然语言处理的起源可以追溯到20世纪50年代,当时主要侧重于基于规则的方法。在这一时期,研究人员旨在将语言规则编码到计算机程序中,希望使机器能够理解和生成人类语言。
关键里程碑:
- 1957年:诺姆·乔姆斯基(Noam Chomsky)的开创性著作《句法结构》(Syntactic Structures)引入了转换生成语法,对计算语言学产生了深远影响。
- 1966年:自动语言处理咨询委员会(ALPAC)的报告使早期的机器翻译努力受到质疑,凸显了语言处理的挑战和复杂性。
6.2 20世纪80年代后期至2000年:统计方法与首批网络架构
20世纪80年代后期,由于计算能力的提高和大型数据集的可用性,自然语言处理从基于规则的方法转向了统计方法。
关键里程碑:
- 1985年:循环神经网络(RNN)的引入为基于序列的数据处理奠定了基础。(《通过反向传播误差学习表示》(Learning Representations by Back-Propagating Errors))
- 1989年:隐马尔可夫模型(HMMs)在语音识别和其他基于序列的任务中变得流行起来。(《用于语音识别的隐马尔可夫模型》(Hidden Markov Models for Speech Recognition))
- 1997年:由霍赫赖特(Hochreiter)和施密德胡贝尔(Schmidhuber)开发的长短期记忆(LSTM)网络,通过解决梯度消失问题改进了循环神经网络。(《长短期记忆》(Long Short-Term Memory))
统计方法的发展:
- 词袋模型(BoW):一种基础方法,通过统计单词的出现次数来表示文本数据,忽略语法和单词顺序。
- 词频-逆文档频率(TF-IDF):对词袋模型的一种改进,根据单词在文档中的出现频率的倒数来加权,突出更罕见、更具信息性的单词。(《信息检索导论》(Introduction to Information Retrieval))
6.3 21世纪初至2018年:深度学习与神经网络的兴起
21世纪初预示着深度学习技术的兴起,利用在大规模数据集上训练的大型神经网络,彻底改变了自然语言处理领域。
关键里程碑:
- 2013年:米可洛夫(Mikolov)等人提出的Word2Vec,能够创建密集的词嵌入,捕捉单词之间的语义关系。(《向量空间中词表示的高效估计》(Efficient Estimation of Word Representations in Vector Space))
- 2014年:由苏茨克弗(Sutskever)、维尼亚尔斯(Vinyals)和乐(Le)提出的序列到序列学习和编码器-解码器架构,显著推动了机器翻译的发展。(《用神经网络进行序列到序列学习》(Sequence to Sequence Learning with Neural Networks))
- 2014年:巴达瑙(Bahdanau)、赵(Cho)和本吉奥(Bengio)引入了注意力机制,使模型在翻译过程中能够关注输入序列的特定部分。(《通过联合学习对齐和翻译进行神经机器翻译》(Neural Machine Translation by Jointly Learning to Align and Translate))
- 2017年:谷歌的变换器(Transformer)模型在论文《注意力就是你所需要的一切》(Attention is All You Need)中提出,通过完全依赖注意力机制,彻底改变了自然语言处理领域。
词嵌入方法的详细发展:
词嵌入改变了机器理解单词的方式。这一历程始于Word2Vec,这是一种通过“向量化”单词来处理文本的神经网络,将语义相似的单词在连续的向量空间中放置得很近。
- 2013年:Word2Vec使用连续词袋(CBOW)和跳字(Skip-Gram)架构对词嵌入进行了变革。(《向量空间中词表示的高效估计》(Efficient Estimation of Word Representations in Vector Space))
- 2014年:由斯坦福大学的彭宁顿(Pennington)等人开发的GloVe,从语料库中聚合了全局的单词共现统计信息。(《GloVe:用于词表示的全局向量》(GloVe: Global Vectors for Word Representation))
- 2016年:来自脸书人工智能研究实验室的FastText,通过考虑子词信息对Word2Vec进行了改进,使其对形态丰富的语言非常有效。(《用子词信息丰富词向量》(Enriching Word Vectors with Subword Information))

注意力机制:
- 2014年:巴达瑙等人引入了注意力机制,通过使模型能够关注输入序列的相关部分,显著提高了翻译质量。(《通过联合学习对齐和翻译进行神经机器翻译》(Neural Machine Translation by Jointly Learning to Align and Translate))
- 2017年:瓦斯瓦尼等人引入了变换器模型,该模型仅使用注意力机制,提高了自然语言处理任务的效率和性能。(《注意力就是你所需要的一切》(Attention is All You Need))
变换器中的嵌入技术:
变换器引入了新颖的嵌入技术,包括位置前馈网络和位置编码,帮助模型理解句子中的单词顺序。(《注意力就是你所需要的一切》(Attention is All You Need))
6.4 2019年至今:大语言模型(LLMs)
近年来,大语言模型(LLMs)拓展了自然语言处理能力的边界。
关键里程碑:
- 2019年:像RoBERTa、BART、T5和GPT-2这样的模型为语言理解和生成设定了新的基准。
- RoBERTa:《一种稳健优化的BERT预训练方法》(A Robustly Optimized BERT Pretraining Approach)
- BART:《用于自然语言生成、翻译和理解的去噪序列到序列预训练》(Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension)
- 《使用统一的文本到文本变换器探索迁移学习的极限》(Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer)
- 《语言模型是无监督的多任务学习者》(Language Models are Unsupervised Multitask Learners)
- 2020年:OpenAI的GPT-3拥有1750亿个参数,展示出了令人印象深刻的语言生成和理解能力。《语言模型是少样本学习者》(Language Models are Few-Shot Learners)
- 2021年:随着DeBERTa、T0和开源的GPT-Neo等模型的出现,技术继续取得进步。
- 2022年:FlanT5、PaLM、BLOOM和ChatGPT等模型将细致入微且具有上下文感知能力的语言理解推向了前沿。
- 2023年:LLaMa、Bard、GPT-4和Claude等模型的开发展示了自然语言处理领域的持续进步。
- LLaMa:《Meta AI的大语言模型》(Large Language Model Meta AI)
- GPT-4
- Bard和Claude是专有模型,其详细信息可在各自公司的网站上查询。
大语言模型的微调:
微调对于使预训练的大语言模型适应特定任务至关重要。这涉及在较小的、特定任务的数据集上进行额外训练,使模型能够在利用其大量预训练知识的同时实现专业化。
- 2019年:像使用BERT和RoBERTa等模型进行有监督和无监督微调的技术变得普遍。
- 2020年:GPT-3凸显了少样本学习的潜力,即通过仅用几个示例对模型进行微调,就能在各种任务中取得令人瞩目的性能。《语言模型是少样本学习者》(Language Models are Few-Shot Learners)
自然语言处理的历史展示了在过去七十年中所取得的令人难以置信的进步。从早期基于规则的系统到如今复杂的大语言模型,每个时代都为我们理解人类语言做出了重大贡献。随着我们继续开发更先进的模型,自然语言处理的未来有望带来更多令人兴奋的创新和应用,让我们更接近真正理解和生成人类语言的目标。
7. 结论
在这篇博客中,我们踏上了理解自然语言处理(NLP)基础知识的旅程。我们首先定义了自然语言处理,并探讨了其核心领域:自然语言理解(NLU)和自然语言生成(NLG)。然后,我们深入研究了自然语言处理的各种应用,包括情感分析、机器翻译和命名实体识别,强调了如何使用不同的技术和模型来处理这些任务。
我们还涵盖了自然语言处理的重要概念和术语,如分词、词干提取、词形还原,以及词袋模型(BoW)和词频-逆文档频率(TF-IDF)等特征在特征提取中的作用。此外,我们讨论了像词嵌入和变换器这样的先进技术,这些技术通过实现更复杂的语言理解和生成,彻底改变了该领域。
最后,我们探索了自然语言处理的发展历程,追溯了它从20世纪50年代基于规则的系统到如今强大的大语言模型(如GPT-3和GPT-4)的演变。这一历史背景全面概述了该领域的发展程度,以及塑造现代自然语言处理的重要里程碑。
通过理解这些基础概念和自然语言处理的发展历程,读者能够更好地在未来的讨论和应用中进一步探索自然语言处理的复杂性。
8. 检验你的知识!
8.1 基础面试问题
- 自然语言处理的两个主要领域是什么,它们有何不同?
- 参考答案:自然语言理解(NLU)专注于解释文本背后的含义,而自然语言生成(NLG)则涉及生成类似人类语言的文本。
- 解释词干提取和词形还原之间的区别。为什么在某些自然语言处理任务中,一种方法可能比另一种更受青睐?
- 参考答案:词干提取通过去除词缀将单词还原为其词根形式,这可能会导致生成非单词形式。另一方面,词形还原将单词还原为其基本或词典形式(词元),通常会生成真实的单词。当准确性至关重要时,词形还原通常更受青睐,而词干提取速度更快且计算成本较低。
- 自然语言处理中分词的目的是什么,有哪些不同的类型?
- 参考答案:分词将文本分解为称为词元的较小单元,这些词元可以是单词、子词或字符。类型包括单词分词、句子分词和子词分词。
- 词频-逆文档频率(TF-IDF)与词袋模型(BoW)有何不同,它解决了什么问题?
- 参考答案:TF-IDF对BoW进行了改进,它不仅统计单词的出现次数,还根据单词在文档中相对于整个语料库的重要性为其赋予权重。它通过降低常见单词的重要性,解决了常见单词被过度表示的问题。
- 什么是词嵌入,它们相较于像BoW和TF-IDF这样的传统模型有何改进?
- 参考答案:词嵌入是单词的密集向量表示,它捕捉了单词的含义、句法属性以及与其他单词的关系。与将单词视为离散实体的BoW和TF-IDF不同,词嵌入在连续的向量空间中将语义相似的单词放置得很近,从而保留了上下文信息。
- 描述变换器模型及其在自然语言处理中的重要性。它与之前的模型(如RNN)有何不同?
- 参考答案:变换器模型完全依赖自注意力机制来处理顺序数据,而无需按顺序处理,这使得它比RNN更高效,并且能够捕捉长距离依赖关系。RNN是按顺序处理数据的,对于长序列的处理效率较低。
- 注意力机制在现代自然语言处理模型中起什么作用,它如何提高像翻译这样的任务的性能?
- 参考答案:注意力机制允许模型在生成输出的每个部分时,关注输入序列的特定部分,提供上下文相关的信息。通过关注相关的单词或短语,它提高了像翻译这样的任务的性能。
- 在大语言模型的背景下,微调与零样本学习之间的区别是什么?
- 参考答案:微调涉及使用额外的训练数据使预训练模型适应特定任务,而零样本学习是指模型利用通用知识来执行其未经过明确训练的任务的能力。
- 自然语言处理从基于规则的系统发展到大语言模型(LLMs),这对该领域产生了怎样的变化?
- 参考答案:从基于规则的系统到LLMs的发展,通过从手动编码的语言规则转变为利用大规模数据集和像变换器这样的先进架构的数据驱动方法,彻底改变了自然语言处理领域。这使得模型能够进行更复杂的语言理解和生成。
- 在自然语言处理的背景下,什么是语料库,它在模型训练中是如何使用的?
- 参考答案:语料库是作为自然语言处理模型训练和评估数据集的大量文档集合。它用于分析语言模式并构建统计模型。
8.2 进阶问题
- 假设你的自然语言处理模型在正确分类客户评论的情感方面存在问题,你会采取哪些步骤来诊断和改进该模型?
- 参考答案:步骤可能包括分析数据是否存在类别不平衡问题,审查预处理流程(例如,分词、停用词去除),检查特征提取方法(例如,TF-IDF与词嵌入),探索替代模型(例如,使用变换器而不是简单的逻辑回归),以及在不同的验证集上验证性能以排除过拟合问题。
- 在实际的自然语言处理系统中,你将如何处理未登录词(OOV)?
- 参考答案:方法可能包括使用像字节对编码(BPE)这样的子词分词方法,或者使用字符级嵌入。另一种方法可能是用一个特殊的标记替换未登录词,并对模型进行微调以更好地处理这些情况。
- 假设你被要求为一个法律文档语料库构建一个命名实体识别(NER)系统。你可能会面临哪些挑战,以及你将如何解决这些问题?
- 参考答案:可能面临的挑战包括处理特定领域的语言、长而复杂的句子,以及由于法律影响而对高准确性的需求。为了解决这些问题,可以使用在法律文本上微调过的预训练模型,纳入特定领域的嵌入,并应用主动学习等技术来迭代地提高模型的性能。
- 如果你的聊天机器人对用户查询提供了不相关的答案,你将如何调试这个问题?
- 参考答案:调试过程可能包括检查意图识别系统,验证对话流程和上下文管理,确保训练数据是多样化且具有代表性的,并分析日志以查看对话在何处出现偏差。你还可以检查模型的置信度分数,以确定问题是出在模型的理解上还是响应生成逻辑上。
- 你将如何设计一个自然语言处理系统来自动生成研究论文的摘要?你会考虑哪些因素?
- 参考答案:需要考虑的因素包括选择抽取式还是摘要式摘要方法,评估摘要的质量和长度,处理特定领域的术语,确保模型能够捕捉论文的关键贡献,以及解决像冗余和连贯性这样的挑战。你可能还会讨论在研究论文摘要数据集上微调预训练模型的重要性。
- 假设你正在处理一个使用TF-IDF特征的文本分类模型。你可以如何纳入额外的信息,例如文本的情感或作者的人口统计信息,以提高性能?
- 参考答案:一种方法可以是为情感分数或作者的人口统计信息创建额外的特征,并在将它们输入分类器之前,将这些特征与TF-IDF向量连接起来。另一种方法可以是使用多输入模型,其中一个分支处理TF-IDF特征,另一个分支处理额外的信息,在分类之前组合输出。
- 对于一个为招聘目的而设计的自然语言处理系统,你会采用哪些策略来减少模型偏差?
- 参考答案:策略可能包括仔细选择训练数据以确保多样性,使用对抗去偏等技术,监控模型的有偏差输出,并在训练期间实施公平性约束。对模型的决策进行定期审核,并在敏感决策中引入人为干预也可能很重要。
- 你将如何向没有技术背景的人解释变换器中的注意力机制的概念?
- 参考答案:你可以解释说,注意力机制允许模型关注句子中的重要单词,就像一个人在试图理解一个复杂句子时可能会关注某些单词一样。例如,在句子“猫坐在垫子上”中,模型会更多地关注“猫”和“垫子”以理解主要意思。
- 你被要求优化一个在处理稀有单词方面存在困难的机器翻译模型的性能。你会提出哪些解决方案?
- 参考答案:解决方案可以包括实现子词分词,将稀有单词分解为更常见的子词单元,使用从在大规模语料库上预训练的模型进行迁移学习,在包含稀有单词的数据集上微调模型,或者使用包含这些稀有单词的释义或合成数据来扩充数据集。
- 在你的自然语言处理模型的预测难以解释的情况下,你将如何提高模型的可解释性?
- 参考答案:方法可以包括使用更简单的模型,如决策树或逻辑回归,在变换器模型中实现注意力可视化,以查看模型关注输入的哪些部分,使用像LIME或SHAP这样的技术来解释预测,并纳入事后分析以分解模型是如何得出特定决策的。
8.3 自主探究
- 自然语言处理有哪些实际应用?
- 我们如何表示词嵌入?
- 为什么在自然语言处理中需要卷积神经网络(CNN)?
- 什么是迁移学习?进行迁移学习你会采取哪些步骤?
- GPT系列和BERT系列的主要区别是什么?
- 如果没有像NLTK和SpaCy这样的库,你会采用什么方法来构建命名实体识别管道?
- 你将如何确定文本中单词的位置?
- 相较于其他模型(如RNN),变换器有哪些优势?
- 用卷积神经网络(CNN)进行文本处理是否可行?为什么它不被优先选择,而RNN更受青睐?
- 什么是循环神经网络(RNN),它在自然语言处理中如何处理顺序数据?
- 摘要式摘要和抽取式摘要之间的区别是什么?
鸣谢
在这篇博客文章中,我们整理了来自各种来源的信息,包括研究论文、技术博客、官方文档等。每个来源都在相应的图片下方进行了适当的标注,并提供了来源链接。
以下是参考文献的汇总列表:
- https://www.xoriant.com/blog/natural-language-processing-the-next-disruptive-technology-under-ai-part-i
- https://datasciencedojo.com/blog/natural-language-processing-applications/
- https://www.deeplearning.ai/resources/natural-language-processing/
- https://www.researchgate.net/figure/Natural-Language-Processing_fig1_364842359
- https://www.linkedin.com/pulse/20141209180635-83626359-nlp-and-text-analytics-similified-document-classification/
- https://geekflare.com/natural-language-understanding/
- https://blog.dataiku.com/nlp-metamorphosis
- https://www.linkedin.com/posts/ketan-gangal_embeddings-in-natural-language-processing-activity-7066631663706882048-LAWl/
- https://medium.com/@vipra_singh/llm-architectures-explained-nlp-fundamentals-part-1-de5bf75e553a