实验名称
K近邻算法实现葡萄酒分类
实验目的
通过未知品种的拥有13种成分的葡萄酒,应用KNN分类算法,完成葡萄酒分类;
熟悉K近邻算法应用的一般过程;
通过合理选择K值从而提高分类得到正确率;
实验背景
本例实验采用UCI开放的葡萄酒样本数据,数据下载地址为 http://archive.ics.uci.edu/ml/datasets/Wine。该数据记录了意大利同一地区种植的葡萄酿造的3个不同品种的葡萄酒数据,包含了178组葡萄酒经过化学分析后记录的13种成分的数据。
在wine数据集中,这些数据包括了三种酒中13种不同成分的数量。文件中,每行代表一种酒的样本,共有178个样本;一共有14列,其中,第一个属性是类标识符,分别是1/2/3来表示,代表葡萄酒的三个分类。后面的13列为每个样本的对应属性的样本值。剩余的13个属性是,酒精、苹果酸、灰、灰分的碱度、镁、总酚、黄酮类化合物、非黄烷类酚类、原花色素、颜色强度、色调、稀释葡萄酒的OD280/OD315、脯氨酸。其中第1类有59个样本,第2类有71个样本,第3类有48个样本。
wine_data.csv 清洗前的数据
wine_data_clean.csv 清洗后的数据
Attrl~Attr13代表葡萄酒化学分析的13维数据列名标签,LABEL代表葡萄酒种类列名标签
实验原理
KNN算法,是一种非常直观并且容易理解和实现的有监督习方法。该算法既可以用于分类也可以用于回归。该算法的基本思想是对于给定测试样本,先基于指定的距离度量找出训练集中与其最近的k个样本(即k个近邻),然后基于这k个“邻居”的信息来进行预测。该算法被形象地描述为“近朱者赤,近墨者黑”。
通常,在分类任务中采用“投票法”,即在特征空间中选择距离待标记样本 最近的k个已标记样本,通过投票等方式,将占比最高的类别标记作为测试样本分类结果;在回归任务中使用“平均法”,即取k个邻居输出标记的平均值作为预测结果。
实验环境
ubuntu18.04
jupyter 1.0.0
python3.9.17
pandas 2.0.3
numpy 1.25.2
matplotlib 3.7.2
scikit-learn 1.3.1
建议课时
2课时
实验步骤
一、项目准备
打开一个Terminal终端安装实验所需的数据的资源包
pip install ucimlrepo
打开jupyter notebook,点击new新建一个python3文件
from ucimlrepo import fetch_ucirepo
# fetch dataset
wine = fetch_ucirepo(id=109)
# data (as pandas dataframes)
X = wine.data.features
y = wine.data.targets
# metadata
print(wine.metadata)
# variable information
print(wine.variables)
输出如下:
{'uci_id': 109, 'name': 'Wine', 'repository_url': 'https://archive.ics.uci.edu/dataset/109/wine', 'data_url': 'https://archive.ics.uci.edu/static/public/109/data.csv', ...', 'citation': None}}
name role type demographic \
0 class Target Categorical None
1 Alcohol Feature Continuous None
2 Malicacid Feature Continuous None
3 Ash Feature Continuous None
4 Alcalinity_of_ash Feature Continuous None
5 Magnesium Feature Integer None
6 Total_phenols Feature Continuous None
7 Flavanoids Feature Continuous None
8 Nonflavanoid_phenols Feature Continuous None
9 Proanthocyanins Feature Continuous None
10 Color_intensity Feature Continuous None
11 Hue Feature Continuous None
12 0D280_0D315_of_diluted_wines Feature Continuous None
13 Proline Feature Integer None
description units missing_values
0 None None no
1 None None no
2 None None no
3 None None no
4 None None no
5 None None no
6 None None no
...
10 None None no
11 None None no
12 None None no
13 None None no
查看特征数据
X
输出为:
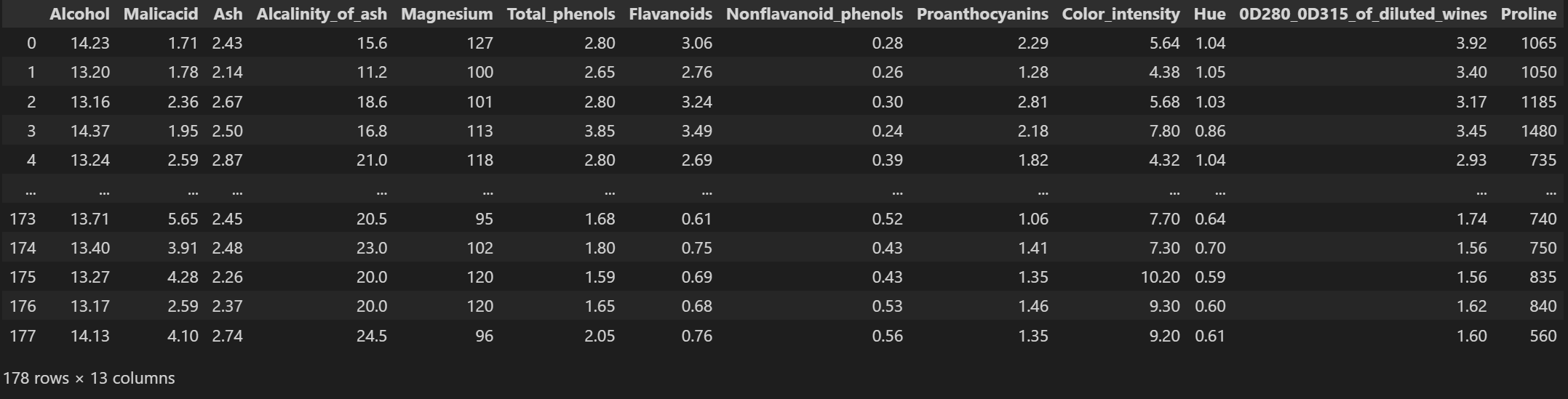
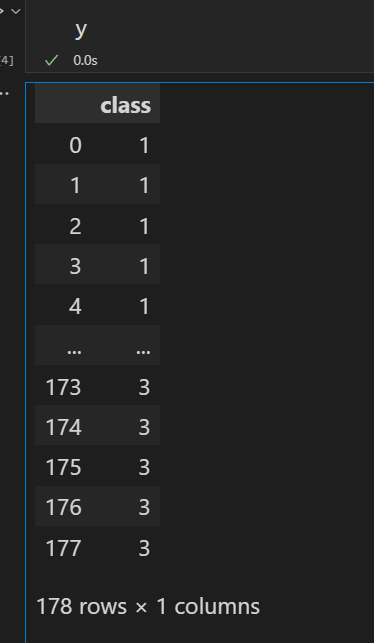
查看标签数据
y
输出为:
二.导入依赖
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
设置列标签名称,Al至A13代表葡萄酒化学分析的13维数据列名标签,即13种成分,LABEL代表葡萄酒种类列名标签。
构建列名的映射
# 构建列名的映射
cols_dict={}
num=0
for i in X.columns:
num = num+1
# print(i," ","A"+str(num))
cols_dict[i]="A"+str(num)
print(cols_dict)
输出如下
{‘Alcohol’: ‘A1’, ‘Malicacid’: ‘A2’, ‘Ash’: ‘A3’, ‘Alcalinity_of_ash’: ‘A4’, ‘Magnesium’: ‘A5’, ‘Total_phenols’: ‘A6’, ‘Flavanoids’: ‘A7’, ‘Nonflavanoid_phenols’: ‘A8’, ‘Proanthocyanins’: ‘A9’, ‘Color_intensity’: ‘A10’, ‘Hue’: ‘A11’, ‘0D280_0D315_of_diluted_wines’: ‘A12’, ‘Proline’: ‘A13’}
替换列名
X = X.rename(columns=cols_dict)
X
输出如下:

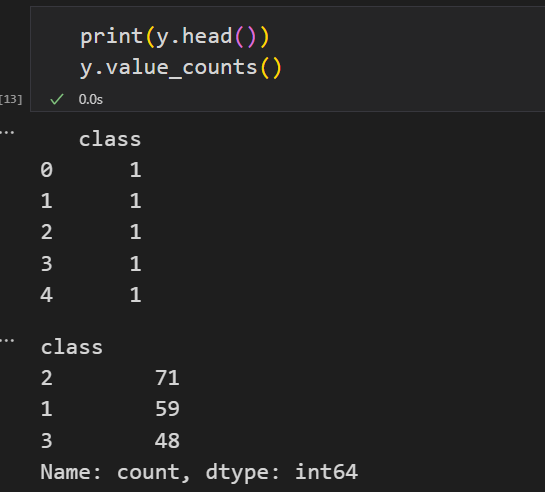
查看y的值
print(y.head())
y.value_counts()
输出如下
构建列名的映射
# 构建列名的映射
cols_dict={}
num=0
for i in X.columns:
num = num+1
# print(i," ","A"+str(num))
cols_dict[i]="A"+str(num)
cols_dict["class"]="LABEL"
print(cols_dict)
输出入下
{‘Alcohol’: ‘A1’, ‘Malicacid’: ‘A2’, ‘Ash’: ‘A3’, ‘Alcalinity_of_ash’: ‘A4’, ‘Magnesium’: ‘A5’, ‘Total_phenols’: ‘A6’, ‘Flavanoids’: ‘A7’, ‘Nonflavanoid_phenols’: ‘A8’, ‘Proanthocyanins’: ‘A9’, ‘Color_intensity’: ‘A10’,
‘Hue’: ‘A11’, ‘0D280_0D315_of_diluted_wines’: ‘A12’, ‘Proline’: ‘A13’, ‘class’: ‘LABEL’}
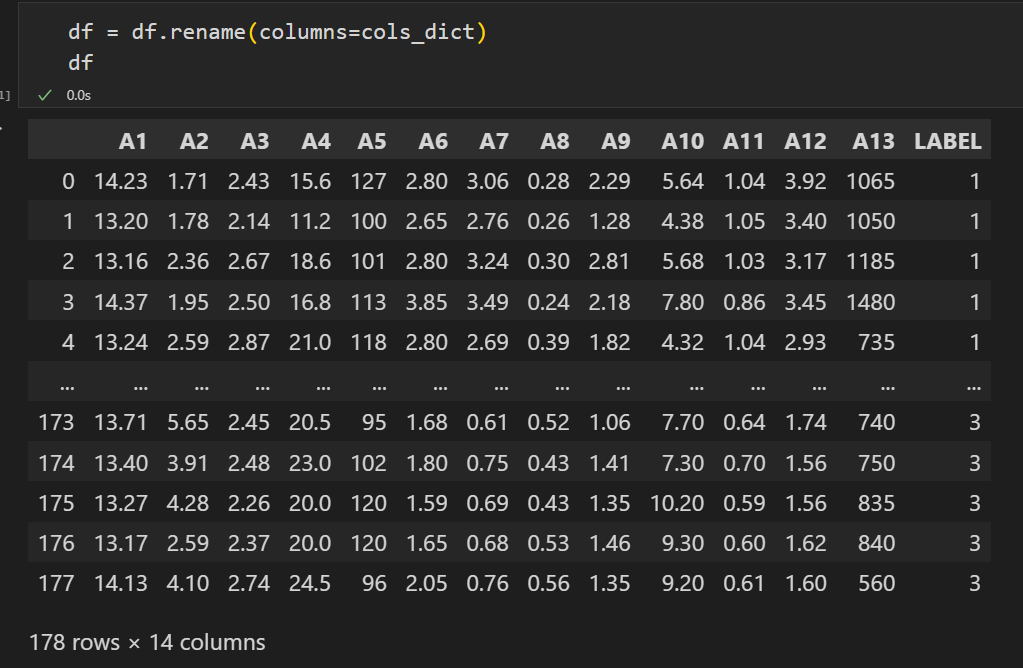
拼接X和y为df
df = pd.concat([X,y],axis=1)
df
输出如下:

重命名df列名
df = df.rename(columns=cols_dict)
df
输出如下:
三.查看样本基本信息
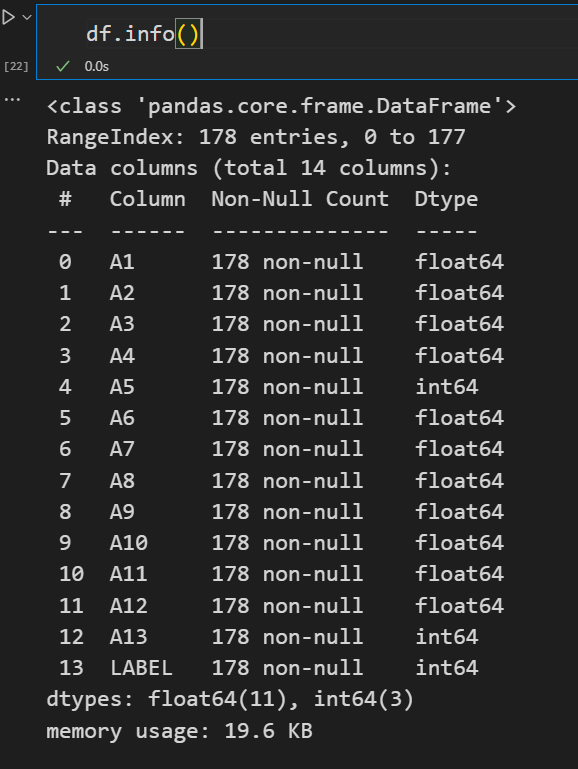
#info()函数用于获取 DataFrame 的简要摘要
df.info()
通过pandas的info()函数查看样本数据的列名、无有空数据、数据类型。
代码为dataset.info(),运行结果如图所示:此图展示了数据的基本信息。
四. 查看数据大致分布
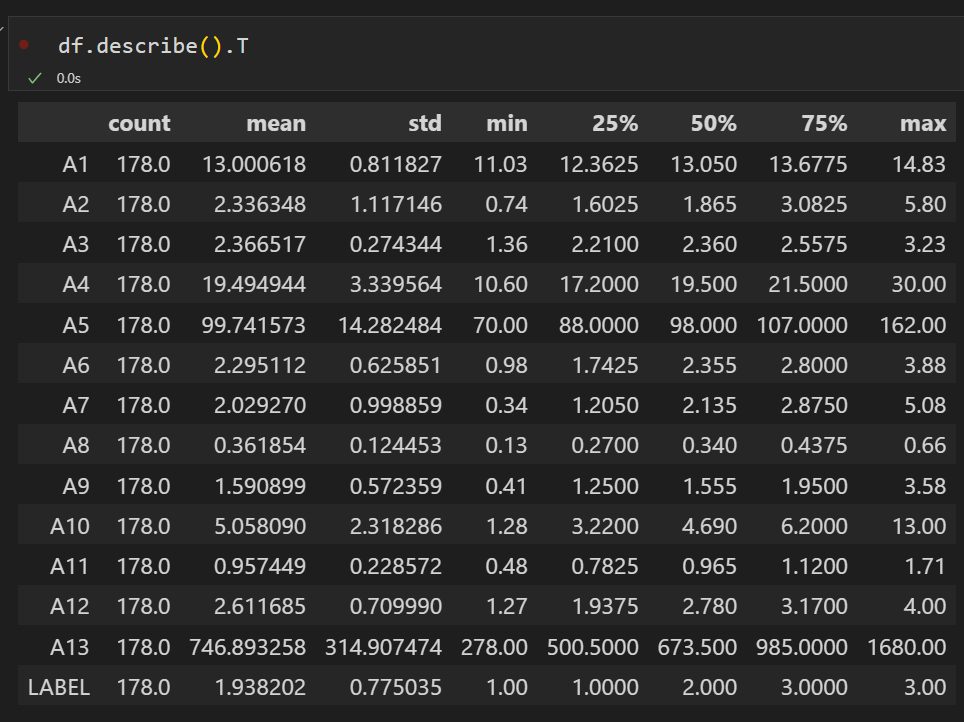
通过pandas的describe ()函数查看样本数据的平均值、方差、最小值25%分位数、50%分位数、75%分位数和最大值,以便了解数据大致分布。
df.describe().T
五.绘制箱线图进行数据分析
为进一步对样本数据的分布进行可视化分析和异常值探测,我们有必要了解一下箱形图。箱形图因形状如箱子而得名,又称为盒须图、盒式图、盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图。
了解箱形图的含义后,对数据进行可视化。通过matplotlib绘制箱线图进一步分析葡萄酒13种成分的统计情况,以便发现样本中有无异常数据,箱形图的可视化代码如下:设置相关图形参数,unicode_minus为正常显示负号,字体大小为12,风格为seaborn的darkgrid,类型kind为箱形图box,且包含子图,不共享x、y坐标轴等。然后展示图片,show。
fig = plt.figure(figsize=(15,10))
# print(plt.style.available)
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.size']=12
plt.style.use('seaborn-v0_8-darkgrid')
p=df.plot(kind='box',subplots=True,layout=(5,5),sharex=False, sharey=False,figsize=(10,10))
plt.show()

通过箱线图展示了葡萄酒13种成分(Al~A13)的数据分布情况,其上四分位、下四分位和中位线的分布不均匀,在A2~A5、A9~A11成分中存在异常数据。
使用matplotlib绘图
fig = plt.figure(figsize=(15,10))
ax = fig.subplots(3,5)
# print(type(ax[0][0]))
# 由于 ax 是一个二维数组,需要使用双重循环遍历
row, col = ax.shape
print(row, col) # 3 5
num = 0
for i in df.columns:
if num >= row * col:
break
# // 表示整除,% 表示取余
r = num // col
c = num % col
ax[r, c].boxplot(df[i])
num += 1
输出如下:

六.异常值检测
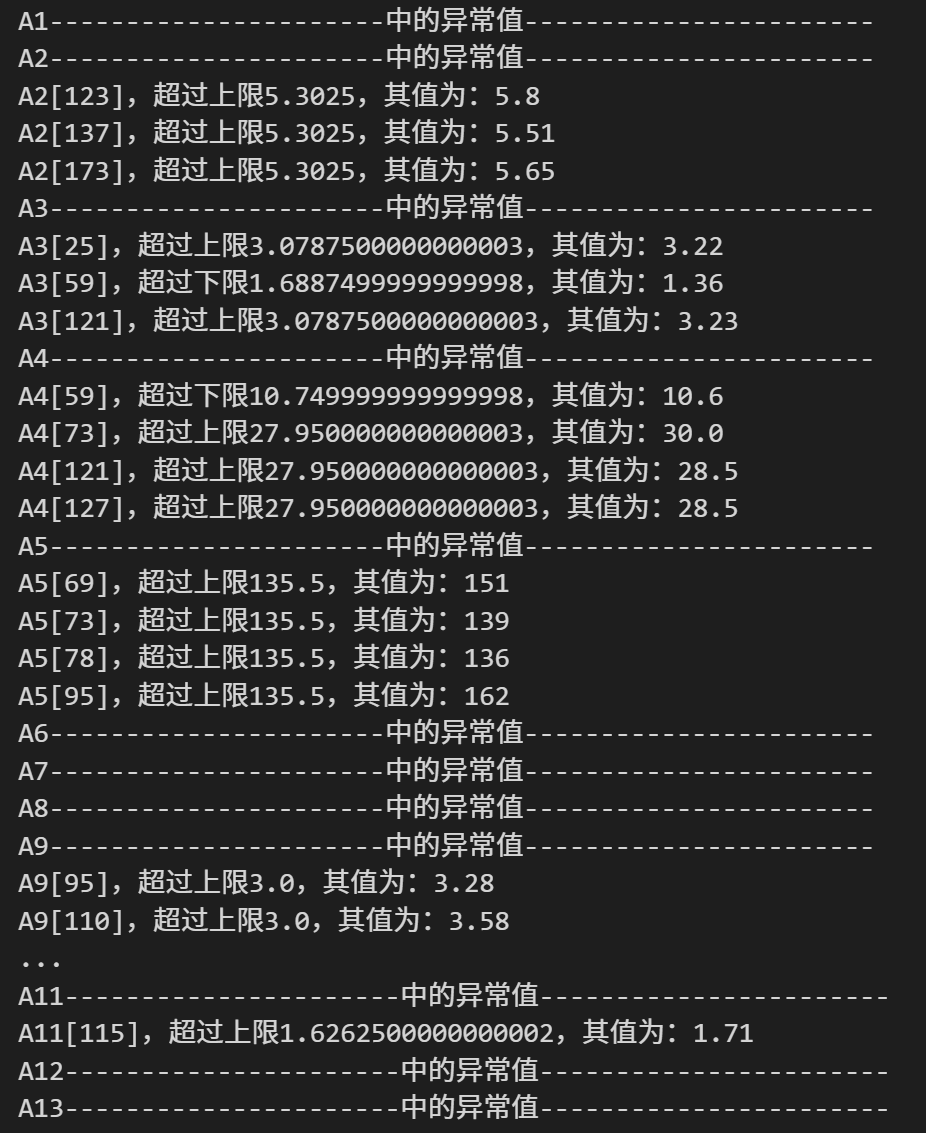
通过箱线图的可视化分析可知,样本数据中是存在异常值的。先使用quantile()计算分位数,然后结合箱线图解释中异常值的定义编码实现。
for i in range(1,14):
columnName='A{0}'.format(i)
columsDatas=df[columnName]
#上四分位数
qu=columsDatas.quantile(q=0.75)
# 下四分位数
ql=columsDatas.quantile(q=0.25)
# 计算四分位间距
iqr=qu-ql
# 上限
up = qu + 1.5 * iqr
# 下限
low = ql - 1.5 * iqr
print(columnName+"中的异常值".center(50,"-"))
for (index,value) in zip(columsDatas.index,columsDatas.values):
if value>up:
print("{0}[{1}],超过上限{2},其值为:{3}".format(columnName,index,up,value))
else:
if value<low:
print("{0}[{1}],超过下限{2},其值为:{3}".format(columnName,index,low,value))
通过打印异常值可以看出,A2、A3、A4和A5中存在异常值,且都一一展示其数值
七.数据清洗
此时,需要对异常值进行处理。处理的方法与业务有直接的关系,如果去掉数据对应用模型本身没有影响,则可去掉异常值。否则,需要依据一定的算法对异常值进行更改、替换,如采用邻近数据的平均值、专家的印象值等。这里依据异常样本数据的前后值,进行人为近似估计更改这些异常值,例如,A2异常值5.8前后的数据分别为4.43和4.31,所以估计该异常值为4.37,取前后数据的平均值。代码如下
hasErrorData=False
for i in range(1,14):
columnName='A{0}'.format(i)
columsDatas=df[columnName].copy()
#上四分位数
qu=columsDatas.quantile(q=0.75)
# 下四分位数
ql=columsDatas.quantile(q=0.25)
# 计算四分位间距
iqr=qu-ql
# 上限
up = qu + 1.5 * iqr
# 下限
low = ql - 1.5 * iqr
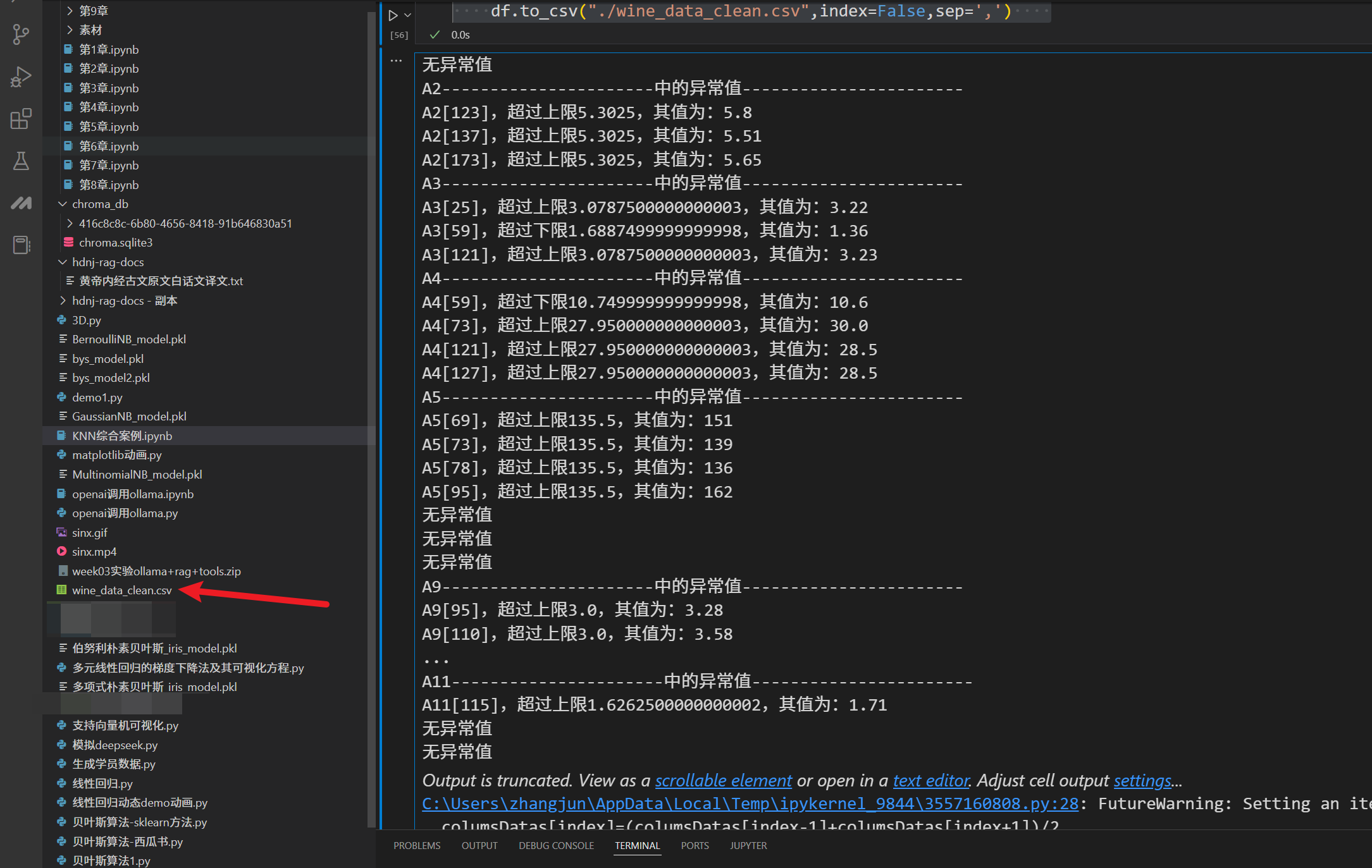
if any(columsDatas>up) or any( columsDatas<low):
print(columnName+"中的异常值".center(50,"-"))
for (index,value) in zip(columsDatas.index,columsDatas.values):
if value>up:
print("{0}[{1}],超过上限{2},其值为:{3}".format(columnName,index,up,value))
else:
if value<low:
print("{0}[{1}],超过下限{2},其值为:{3}".format(columnName,index,low,value))
for (index,value) in zip(columsDatas.index,columsDatas.values):
if value>up or value< low:
#使用前后值方式对数据进行清理
columsDatas[index]=(columsDatas[index-1]+columsDatas[index+1])/2
#将清理后的数据写回DataFrame中
df[columnName]=columsDatas
hasErrorData=True
else:
print('无异常值')
#如有异常数据,则将清洗后的数据另存为wine_data_clean.csv
if hasErrorData:
df.to_csv("./wine_data_clean.csv",index=False,sep=',')
输出如下
八.数据标准化,从清洗后的文件中获取数据
数据清洗完毕后,则是数据标准化,在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。数据标准化的目的就是在不影响各维度间数量关系的情况下,收敛数据间大小的差异(如将数据映射到0~1范围之内)。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
通过数据切片分别获得葡萄酒的13个特征数据,以及葡萄酒的分类数据,然后数据标准化处理,获得13个特征数据的标准化数据。
names =[ 'A1', 'A2', 'A3', 'A4', 'A5', 'A6', 'A7','A8', 'A9', 'A10', 'A11', 'A12', 'A13', 'LABEL']
#此处使用已清洗过的数据
df=pd.read_csv('./wine_data_clean.csv',names=names,skiprows=1)
# 获得葡萄酒的13个特征数据
x_datas=df.iloc[:,:13]
# 获得葡萄酒的分类数据
y_datas=df.iloc[:,13]
# 数据标准化
sc=StandardScaler()
sc.fit(x_datas)
x_datas=sc.transform(x_datas)
# x_datas=sc.fit_transform(x_datas) 不要这么用 要获得fit的结果
print(x_datas[0])
""" [ 1.51861254 -0.56906271 0.26128041 -1.24987992 2.28925387 0.80899739
1.03481896 -0.65956311 1.3408019 0.299684 0.39346131 1.84791957
1.01300893]
"""
x_datas.shape # (178, 13)
输出如下:

九.分割数据集
为了提高分类的准确率,需要对训练集和测试集进行划分。本节将数据集按1:3的分割,其中25%作为测试集,75%作为训练集。分割后的数据集应用于KNN模型,通过性能分析及交叉验证,求取最合理的k值。
代码如下:首先通过train_test_split函数分割数据,并通过序列解包的方式赋值给变量。
# 此处特别注意 x_train,x_test,y_train,y_test的书写顺序
x_train,x_test,y_train,y_test= train_test_split(x_datas,y_datas,test_size=0.25,random_state=9)
print('x_train训练集样本数:',len(x_train))
print('y_train训练集样本数:',len(y_train))
print('x_test测试集样本数:',len(x_test))
print('y_test测试集样本数:',len(y_test))
通过数据打印可以看到,训练数据与测试数据的数量分别是133和45,符合1:3的分割比例。
x_train训练集样本数: 133
y_train训练集样本数: 133
x_test测试集样本数: 45
y_test测试集样本数: 45
十.建立KNN分类模型
模型这里还是采用KNN分类模型,基于欧氏距离,建立模型,并使用x_test数据测试模型性能,代码如下,邻近值设置为3
knn=KNeighborsClassifier(n_neighbors=3)
knn.fit(x_train,y_train)
print('准确率为:',knn.score(x_test,y_test))
输出如下:
准确率为1.0
十一.利用5折交叉验证寻找最佳k值
刚才的代码只是给定一个邻居数k的结果,但是我们不知道的是,这k是不是最佳值。因此我们再利验证寻找最佳k值。
首先将k取值范围设定在用10折交叉1到15之间,间隔为2,然后定义k_scores列表变量,用于存储验证结果。接下来则是针对每个k值进行KNN分类,并通过cross_val_score函数进行10折验证,计算k的评分,并保存结果。
# k_range=1,3,5...19
k_range=list(range(1,16,2))
# 用于存放第一个k值所对应的评分
k_scores=[]
for k in k_range:
#使用k定义分类器
testKnn=KNeighborsClassifier(k)
#使用5折验证,计算k的评分
testKnnScore= cross_val_score(testKnn,x_train,y_train,cv=10)
#取5折评分结果的均值
k_scores.append(testKnnScore.mean())
print(*zip(k_range,k_scores))
程序运行结果如图所示,从数据中容易发现,当k值为11时,评分最高。
输出如下:
(1, 0.9406593406593406) (3, 0.9483516483516483) (5, 0.9703296703296704) (7, 0.9631868131868131) (9, 0.9626373626373625) (11, 0.9774725274725276) (13, 0.9697802197802197) (15, 0.962087912087912)
十二.对验证结果进行可视化
如果数据较多,查看结果会比较困难,那么我们可以通过可视化方式展示结果。
# 指定默认字体:解决plot不能显示中文问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.size']=12
plt.xticks(k_range)
plt.ylim(0.9,1)
plt.xlabel('k取值')
plt.ylabel('交叉验证的准确率')
plt.scatter(k_range,k_scores)
plt.plot(k_range,k_scores)
for (k,score) in zip(k_range,k_scores):
plt.text(k,score,round(score,2))
plt.grid(visible=True,axis='both',linestyle='--')
plt.show()
如果数据较多,查看结果会比较费劲,那么我们可以通过可视化方式展示结果。

十三.葡萄酒分类预测
测试全部数据
经过之前葡萄酒数据的分析与验证,针对本次样本数据,当k=11时,分类效果较好。下面基于欧氏距离建模,使用Sklearn工具进行葡萄酒KNN分类器的程序编写与实现。
k=11
knn=KNeighborsClassifier(n_neighbors=k)
knn.fit(x_train,y_train.values.ravel())
y_predict=knn.predict(x_test)
print('k=',k,'时,x_test数据集葡萄酒预测分类为:')
print(y_predict)
print('k=',k,'时,x_test数据集葡萄酒实际分类为:')
print(y_test.values)
代码运行结果如图所示,当k=11时,将测试数据的预测分类与实际分类都展示了出来。

测试单个数据
names =[ 'A1', 'A2', 'A3', 'A4', 'A5', 'A6', 'A7','A8', 'A9', 'A10', 'A11', 'A12', 'A13', 'LABEL']
#此处使用已清洗过的数据
df=pd.read_csv('./wine_data_clean.csv',names=names,skiprows=1)
# 获得葡萄酒的13个特征数据
x_datas_one=df.iloc[0:1,:13]
# 获得葡萄酒的分类数据
y_datas_one=df.iloc[0:1,13]
print(x_datas_one)
print("----")
print(y_datas_one)
输出如下:
处理特征数据
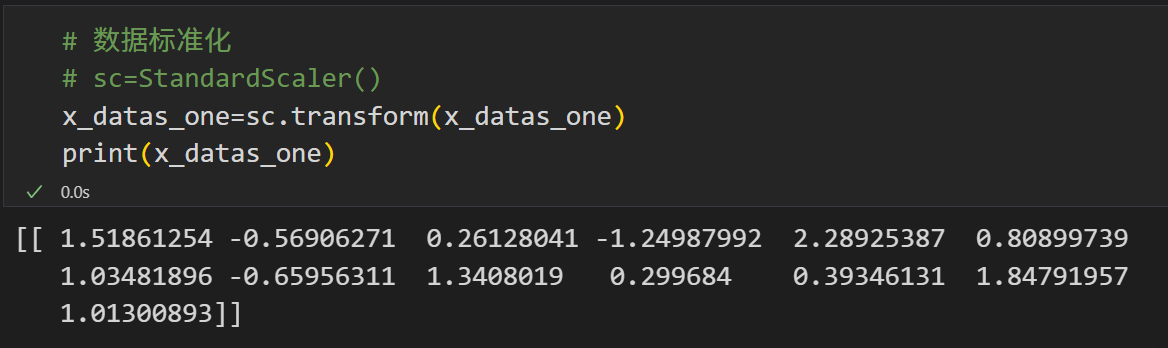
# 数据标准化
# 数据标准化
# sc=StandardScaler()
x_datas_one=sc.transform(x_datas_one)
print(x_datas_one)
输出如下:
基于模型预测结果
knn.predict(x_datas_one)
输出如下:
array([1], dtype=int64)
实验总结
本次实验学习了K近邻算法应用的一般过程,包含数据准备、清洗、标准化、建模与结果分析。最终的KNN葡萄酒分类器模型,在基于欧氏距离及k=11的情况下,分类结果与实际数据分类情况100%吻合。实际项目中,很难遇到这种情况,也说明本次数据具有极强的代表性。希望同学们课下多加练习。