目录
前置:
1 本系列将以 “PyQt6实例_批量下载pdf工具”开头,放在 【PyQt6实例】 专栏
2 本节讲述“批量pdf网址获取”没有涉及到PyQt6的知识点,是“批量下载pdf工具”的一个步骤
3 “批量下载pdf工具”实例是以下载巨潮pdf文件为使用场景,所以pdf网址获取来自巨潮
4 本系列后续会在B站录制视频,到时会在文末贴出链接。本人还是建议先看博文,不懂的再看视频,这样效率高,节约时间。
步骤:
step one 安装包
1 新建项目,创建虚拟环境
2 安装包 pip install akshare
step two 获取股票代码
打开通达信-》行情-》A股-》按“34”回车

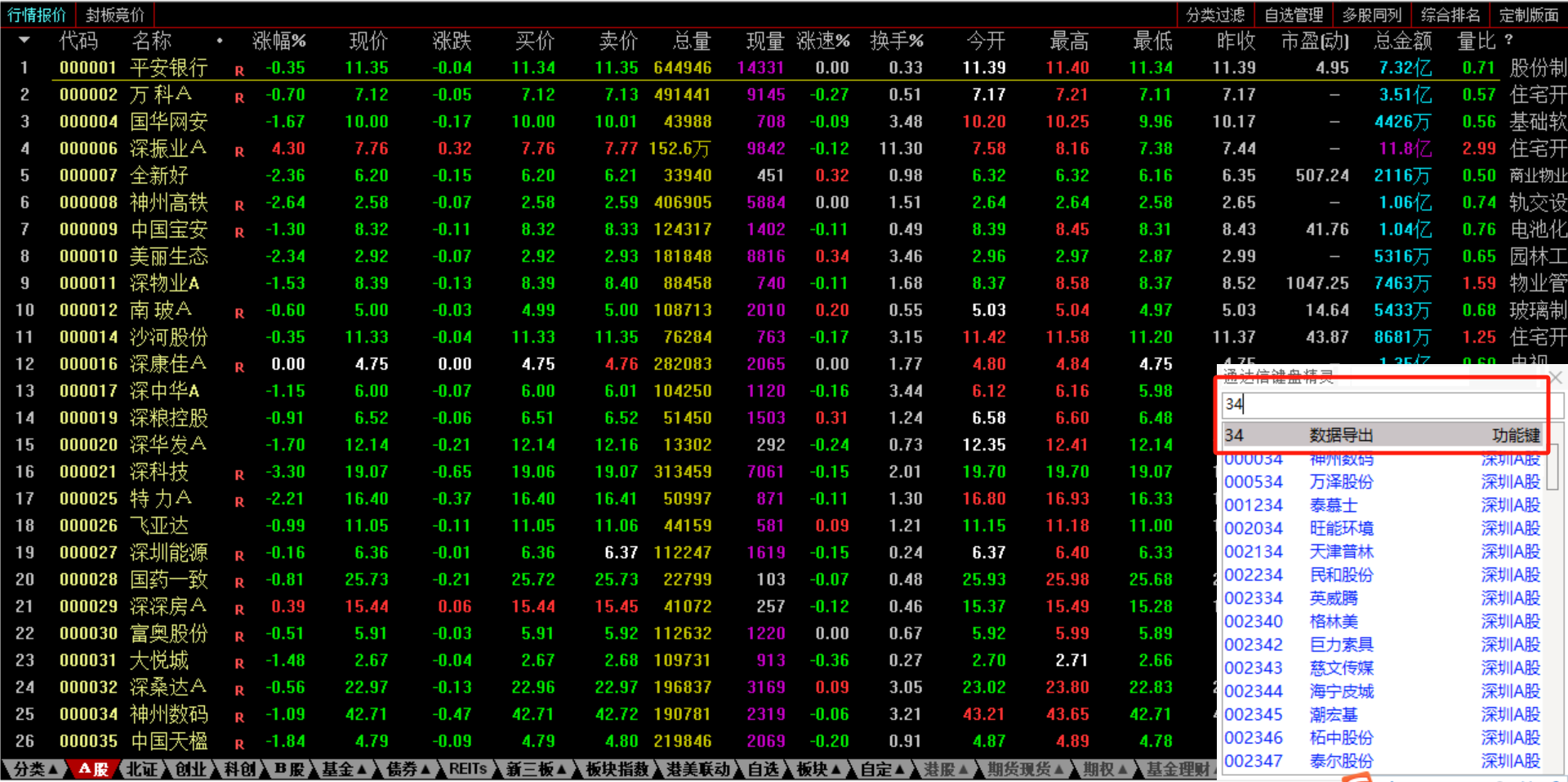

![]()

取代码这一列,存储到txt文件中

step three 敲代码,实现
import akshare as ak
from concurrent.futures import ThreadPoolExecutor
from datetime import datetime
# {'年报', '半年报', '一季报', '三季报', '业绩预告', '权益分派',
# '董事会', '监事会', '股东大会', '日常经营', '公司治理', '中介报告',
# '首发', '增发', '股权激励', '配股', '解禁', '公司债', '可转债', '其他融资',
# '股权变动', '补充更正', '澄清致歉', '风险提示', '特别处理和退市', '退市整理期'}
def req_from_ak(thread_num:int,stock_ticker_list:list):
category_str = '权益分派'
end_date_str = '20250329'
pre_dir = r'E:/temp003/'
print(f'thread {thread_num} start.')
for symbol_str in stock_ticker_list:
try:
df = ak.stock_zh_a_disclosure_report_cninfo(symbol=symbol_str, market="沪深京",
category=category_str,
start_date="20000101",
end_date=end_date_str)
df.to_excel(pre_dir+symbol_str+'.xlsx',engine='openpyxl')
except:
print(symbol_str)
print(f'thread {thread_num} execute end. {datetime.now().strftime("%Y-%m-%d %H:%M:%s")}')
pass
def start_execute():
with open('./stock_ticker.txt',mode='r',encoding='utf-8') as fr:
contents = fr.read()
stock_ticker_list = contents.split('\n')
print(len(stock_ticker_list))
thread_count = 5
interval = len(stock_ticker_list)//thread_count
if interval == 0:
thread_count = 1
params_list = []
thread_num_list = []
for i in range(0,thread_count):
if i == thread_count-1:
pre_list = stock_ticker_list[i*interval:]
else:
pre_list = stock_ticker_list[i*interval:i*interval+interval]
thread_num_list.append(i)
params_list.append(pre_list)
with ThreadPoolExecutor() as executor:
executor.map(req_from_ak, thread_num_list,params_list)
print('线程池任务分配完毕')
pass
if __name__ == '__main__':
start_execute()
pass使用多线程,获取得快些


公告链接是要使用的。
step four 网址转pdf网址

import os
import pandas as pd
def trans_url_to_pdfurl():
pre_dir = r'E:/temp003/'
tar_dir = r'E:/temp005/'
file_list = os.listdir(pre_dir)
for file_one in file_list:
ticker = file_one[0:6]
pre_file_path = pre_dir + file_one
df = pd.read_excel(pre_file_path,engine='openpyxl')
url_list = df['公告链接'].to_list()
pdf_url_list = []
for u_one in url_list:
u_one_00 = u_one.split('&')
node_00 = u_one_00[1].replace('announcementId=','')
node_01 = u_one_00[-1].replace('announcementTime=','')
node_01 = node_01[0:10]
tar_node = f'http://static.cninfo.com.cn/finalpage/{node_01}/{node_00}.PDF'
pdf_url_list.append(tar_node)
pass
pdf_url_list_str = '\n'.join(pdf_url_list)
with open(f'{tar_dir}/{ticker}.txt', mode='w', encoding='utf-8') as fw:
fw.write(pdf_url_list_str)
pass
pass
if __name__ == '__main__':
trans_url_to_pdfurl()
pass

至此,批量下载pdf工具 用于下载的pdf网址就准备好了。
视频
https://www.bilibili.com/video/BV1ASZwYhEGn/
https://www.bilibili.com/video/BV1oEZwYDE6N/
https://www.bilibili.com/video/BV1wuZwYZEJe/
https://www.bilibili.com/video/BV1XtZwYyEo4/