资源类型
在 Kubernetes 中,Pod 作为最小的原子调度单位,所有跟调度和资源管理相关的属性都属于 Pod。其中最常用的资源就是 CPU 和 Memory。
CPU 资源
在 Kubernetes 中,一个 CPU 等于 1 个物理 CPU 核或者一个虚拟核,取决于节点是一台物理主机还是运行在某物理主机上的虚拟机。CPU 的请求是允许带小数的,比如 0.5 等价于 500m,表示请求 500 millicpu 或 0.5 个 cpu 的意思,这样 Pod 就会被分配 1 个 CPU 一半的计算能力。需要注意的是,Kubernetes 不允许设置精度小于 1m 的 CPU 资源。
Memory 资源
Memory 以 bytes 为单位,Kubernetes 支持使用 Ei、Pi、Ti、Gi、Mi、Ki(或者E、P、T、G、M、K)作为 bytes 的值。
其中 1Mi=1024*1024;1M=1000*1000,还要注意后缀的小写情况,400m实际上请求的是 0.4 字节。
资源的请求和限制
在 Kubernetes 中,CPU 是一种可压缩资源,当可压缩资源不足时,Pod 会处于 Pending 状态;而 Memory 是一种不可压缩资源,当不可压缩资源不足时,Pod 会因 OOM 而被杀掉。所以合理的请求和分配 CPU 和 Memory 资源,可以提高应用程序的性能。Pod 可以由多个 Container 组成,每个 Container 的资源配置通过累加,形成 Pod 整体的资源配置。
针对每个容器的资源请求和限制,可以通过以下字段设置:
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
下面是一个示例:
该 Pod 有两个容器,每个容器请求的 CPU 和 Memory 都是 0.25 CPU 和 64 MiB,每个容器的资源限制都是 0.5 CPU 和 128 MiB,所以该 Pod 的资源请求为 0.5 CPU 和 128 MiB,资源限制为 1 CPU 和 256 MiB。
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"QoS模型
除了通过 limits 和 requests 限制和请求资源,Kubernetes 还会根据值的不同,为 Pod 设置优先级。当 Node 上的资源不足时,驱逐低优先级的 Pod,以保证更重要的 Pod 正常运行。这里就要介绍 Kubernetes 中的 QoS**(Quality of Service,服务质量)**。
QoS 类一共有三种:Guaranteed、Burstable 和 BestEffort。当一个 Node 耗尽资源时,Kubernetes 驱逐策略为:BestEffort Pod > Burstable Pod > Guaranteed Pod。
- BestEffort:pod没有设置requests和limit
- Burstable:pod设置request和limit,但request<limit
- Guaranteed:pod设置request和limit,并且request=limit
Guaranteed
判断依据:
Pod 中的每一个 Container 都同时设置了 Memory limits 和 requests,且值相等
Pod 中的每一个 Container 都同时设置了 CPU limits 和 requests,且值相等
比如下面的 Pod 中,CPU 的请求和限制都为 0.7 CPU,Memory 的请求和限制都为 200 MiB。当该 Pod 创建后,它的 QoS Class 字段的值就是:Guaranteed。属于该类型的 Pod 具有最严格的资源限制,且最不可能被驱逐。只有当获取的资源超出 limits 值或没有可被驱逐的 BestEffort Pod 或 Burstable Pod,这些 Pod 才会被杀死。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
需要注意的是,当 Pod 仅设置了 limits 没有设置 requests 时,Kubernetes 会自动为它设置与 limits 相同的 requests 值。
Burstable
判断依据:
不满足 Guaranteed 的判断条件
至少有一个 Container 设置了 requests
在下面的 Pod 中,Memory 的限制为 200 MiB,请求为 100 MiB。两者不相等,所以被划分为 Burstable。
如果不指定 limits 的值,那么默认 limits 等于 Node 容量,允许 Pod 灵活地使用资源。如果 Node 资源不足,导致 Pod 被驱逐,只有在 BestEffort Pod 被驱逐后,Burstable Pod 才会被驱逐。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-2
namespace: qos-example
spec:
containers:
- name: qos-demo-2-ctr
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
BestEffort
判断依据:
不满足 Guaranteed 或 Burstable 的判断条件
既没有设置 limits,也没有设置 requests
属于 BestEffort 的 Pod,可以使用未分配给其他 QoS 类中的资源。如果 Node 有 16 核 CPU 可供使用,且已经为 Guaranteed Pod 分配了 4 核 CPU,那么 BestEffort Pod 可以随意使用剩余的 12 核 CPU。
如果 Node 的资源不足,那么将首先驱逐 BestEffort Pod。
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-3
namespace: qos-example
spec:
containers:
- name: qos-demo-3-ctr
image: nginx
限制范围和资源配额
默认情况下,Kubernetes 中的容器可以使用的资源是没有限制的。但是当多个用户使用同一个集群时,可能会出现有人占用过量的资源,导致其他人无法正常使用集群的情况。
限制范围和资源配额正是解决该问题的方法。其中限制范围通过 LimitRange 对象,在命名空间级别下限制 Pod 中容器的资源使用量,在创建 Pod 时,自动设置 CPU 和 Memory 的请求和限制。资源配额通过 ResourceQuota 对象,对每个命名空间的资源总量进行限制,避免命名空间中的程序无限制地使用资源。
在下面的例子中,定义了一个 LimitRange 对象。在该命名空间创建的 Pod 将遵循以下条件:
如果未指定 CPU 的 requests 和 limits,则均为 0.5 CPU
如果只指定了 requests,则 limits 的值在 0.1 CPU 和 1 CPU 之间
如果只指定了 limits,则 request 的值与 limits 相同,低于 0.1 CPU 的设为 0.1 CPU,高于 1 CPU 的设为 1 CPU。
如果命名空间存在多个 LimitRange 对象,应用哪个默认值是不确定的
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-resource-constraint
spec:
limits:
- default: # 此处定义默认限制值
cpu: 500m
defaultRequest: # 此处定义默认请求值
cpu: 500m
max: # max 和 min 定义限制范围
cpu: "1"
min:
cpu: 100m
type: Container
需要注意的是,当只指定了 requests,没有指定 limits 时,requests 的值大于 LimitRange 设置的 limits 的默认值,将导致 Pod 无法调度。
资源配额的流程如下:
集群管理员为每个命名空间创建一个或多个 ResourceQuota 对象
当用户在命名空间下创建对象时,Kubernetes 的配额系统会跟踪集群的资源使用情况,以确保使用的资源总量不超过 ResourceQuota 中的配额
如果命名空间下的计算资源(CPU、Memory)被开启,则用户必须为 Pod 设置 limits 和 requests,否则系统将拒绝 Pod 的创建(或者使用 LimitRanger 解决)
下面的 ResourceQuota 定义了命名空间的资源限制:该命名空间中所有 Pod 的 CPU 总量不能超过 2,Pod 的 Memory 总量不能超过 2 GiB,PVC 的存储总量不能超过 5 GiB,Pod 的数量不能超过 10 个。
apiVersion: v1
kind: ResourceQuota
metadata:
name: example-quota
spec:
hard:
cpu: "2"
memory: 2Gi
storage: 5Gi
pods: "10"
CPU 管理器策略
默认情况下,kubelet 使用 CFS 配额 来对 Pod 的 CPU 进行约束。当 Node 上运行了很多 CPU 密集型任务时,Pod 可能会争夺可用的 CPU 资源,工作负载可能会迁移到不同的 CPU 核,对上下文切换敏感的工作负载的性能会受到影响。为此,kubelet 提供了可选的 CPU 管理器策略。
管理策略
CPU 管理器目前有两种策略:
None:默认策略
Static:允许为节点上具有整数型 CPU requests 的 Guaranteed Pod 赋予 CPU 亲和性和独占性。
此策略管理一个 CPU 共享池,该共享池最初包含节点上所有的 CPU 资源。可独占性 CPU 资源数量等于 CPU 总量减去通过 kubeReserved 或 systemReserved 参数指定的 CPU 数量。这些参数指定的 CPU 供 BestEffort Pod、Burstable Pod 和 Guaranteed 中请求了非整数值 CPU 的 Pod 使用。只有那些请求了整数型 CPU 的 Guaranteed Pod,才会被分配独占 CPU 资源。
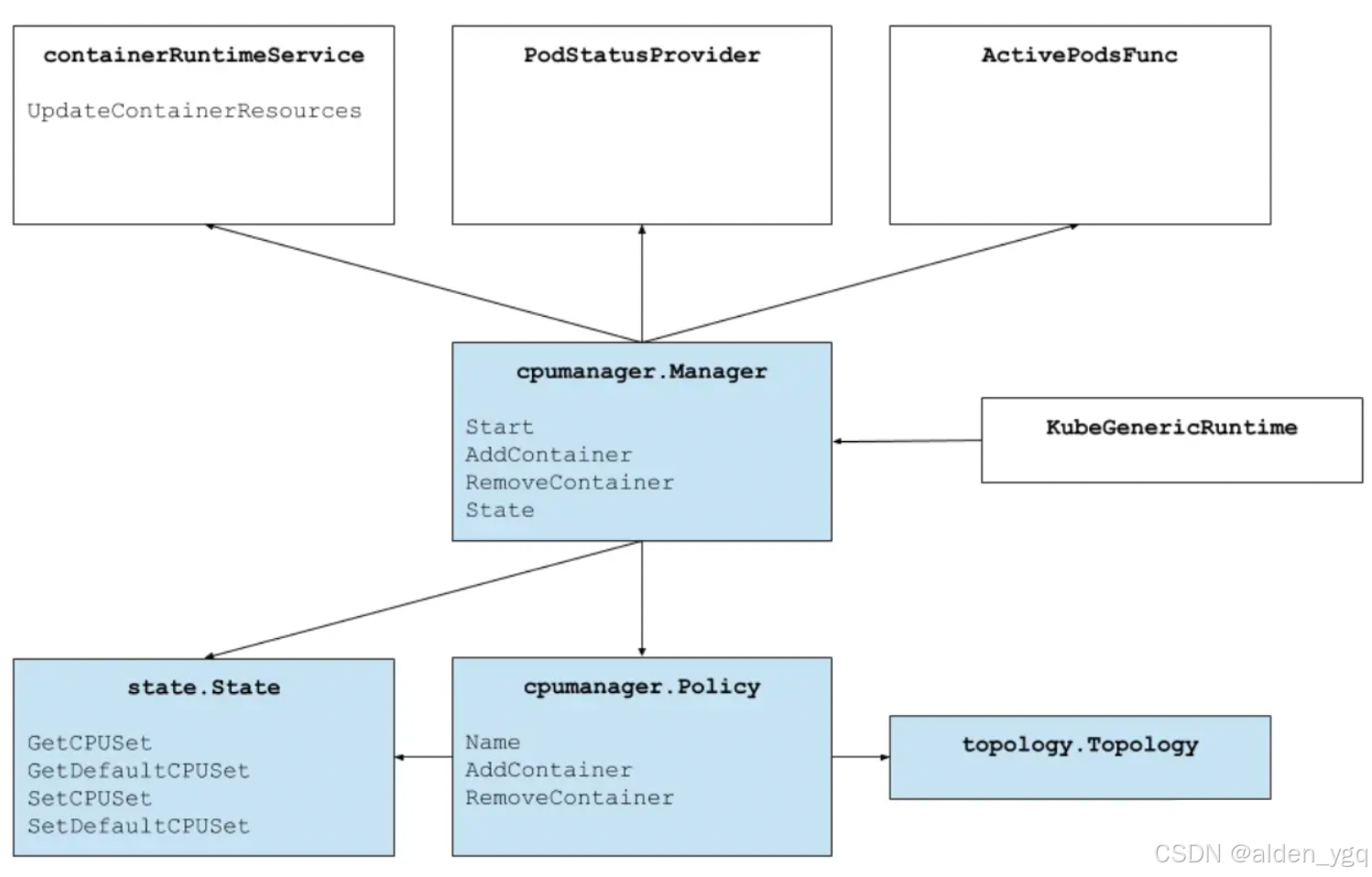
上图显示了 CPU 管理器的结构。CPU 管理器使用contaimerRuntimeService接口的UpdateContainerResources方法来修改容器可以运行的 CPU。Manager 定期使用 cgroupfs 技术来与每个正在运行的容器的 CPU 资源的当前状态进行协调。
使用场景
如果工作负载具有以下场景,那么通过使用该策略,操作系统在CPU之间进行上下文切换的次数大大减少,容器里应用的性能会得到大幅提升。
对 CPU 节流敏感
对上下文切换敏感
对处理器换成未命中敏感
验证策略
由于 CPU 管理器策略只能在 kubelet 生成新 Pod 时生效,所以简单地从 "None" 更改为 "Static" 将不会对现有的 Pod 起作用。 因此,为了正确更改节点上的 CPU 管理器策略,可以执行以下步骤:
腾空节点
停止 kubelet
删除旧的 CPU 管理器状态文件。该文件的路径默认为/var/lib/kubelet/cpu_manager_state。这将清除 CPUManager 维护的状态,以便新策略设置的 cpu-sets 不会与之冲突
编辑 kubelet 配置/var/lib/kubelet/config.yml,以将 CPU 管理器策略更改为所需的值
启动 kubelet
对需要更改其 CPU 管理器策略的每个节点重复此过程。
以下示例在config.yml添加了字段,如果该 Node 有 64 核,那么共享池将有 8 核,剩余的 56 核将用于指定了整数型 CPU 的 Guaranteed Pod。
systemReserved:
cpu: "4"
memory: "500m"
kubeReserved:
cpu: "4"
memory: "500m"
cpuManagerPolicy: "Static"
当重新启动 kubelet 后,就会新建cpu_manager_state,"policyName" 字段将从 “None” 变为 “Static”。
{"policyName":"Static","defaultCpuSet":"","checksum":1353318690}创建一个 calculate.yml,用来验证 Static 策略是否真的生效。用 go 写了一个可以并发计算 200000 以内的素数的程序 calculate_primes。指定部署在启动了 Static 策略的 dc02-pff-500-5c24-cca-e881-3c40 节点上,并把 Pod 设置为 Guaranteed。
apiVersion: batch/v1
kind: Job
metadata:
name: calculate-job
spec:
template:
metadata:
name: calculate-job
spec:
nodeName: ***
containers:
- name: calculate-container
image: ubuntu:latest
command: ["./calculate_primes", "2000000"]
resources:
limits:
cpu: "5"
memory: "100Mi"
volumeMounts:
- name: mix-storage-volume
mountPath: ***
volumes:
- name: mix-storage-volume
persistentVolumeClaim:
claimName: mix-storage-pvc
restartPolicy: Never
backoffLimit: 0
查看 Pod 可以确认确实为 Guaranteed。
通过 taskset -cp PID 和 cat cpu_manager_state 可以查看 calculate_primes 进程使用了序号为 8-12 的5个 CPU,表明 Static 策略生效,程序可以独占 CPU。
而使用 None 策略时,通过 taskset -cp PID 命令可以查看当前进程并不会独占 CPU,而是在 64 个 CPU 间随意切换。
CPU、Memory 限制和请求的最佳实践
Natan Yellin 通过“口渴的探险家”和“披萨派对”的例子,给出了关于 CPU 、Memory 限制和请求的最佳实践。
省略版
永远设置 Memory limits == requests
绝不设置 CPU limits
口渴的探险家
在该故事中,CPU 就是水,CPU 饥饿就是死亡。A 和 B 在沙漠中旅行,他们有一个神奇的水瓶,每天可以产生 3 升水,每人每天需要 1 升水才能存活。
情景1:without limits, without requests
A 很贪婪,在 B 之前喝光了所有的水,导致 B 渴死。因为没有限制和请求,所以 A 能喝掉所有的水,导致 CPU 饥饿。
情景2:with limits, with or without requests
A 和 B 都喝了 1 升水,但是 A 生病了,需要额外的水,B 不让 A 喝,因为 A 的限制是每天 1 升水,所以 A 渴死了。当有 CPU 限制时,就可能发生这种情况,即使有很多资源,也无法使用。
情景3:without limits, with requests
这次轮到 B 生病了,需要额外的水,但是当喝到只剩 1 升水时停下了,因为 A 每天需要 1 升水。两个人都活了下来。当没有 CPU 限制但有请求时就会出现这种情况,一切正常。
用表格概括一下 limits 和 requests 的区别
| Pod | CPU limits | No CPU limits |
|---|---|---|
| CPU requests | 能使用的CPU 在 requests和limits之间无法使用更多的 CPU | 能够使用 requests 指定的 CPU 数量多余的CPU也能用,不会造成浪费 |
| No CPU requests | 能够使用 limits 指定的 CPU 数量无法使用更多的 CPU | 随意使用可能会耗尽节点资源 |
Kubernetes 给出了解释:
Pod 保证能够获得所请求的 CPU 数量,如果没有 limits,可能会使用多余的 CPU,但不会抢占其他正在运行任务的CPU。
披萨派对
想象一个披萨派对,每个人点 2 片,最多可以吃 4 片,相当于 requests = 2,limits = 4。但在订购披萨的时候,是按每人 2 片的数量订的。派对开始了,每张桌子都为坐下的人准备了 2 片披萨,谁都可以拿。但是在你准备吃的时候发现披萨没有了,此时一个保镖出来把正在吃披萨的另一个人击倒,收集剩下的披萨(准确地说是也包括这个人吃过的披萨),给桌子上的其他人吃。并把刚才的那个人安排到另一张有更多披萨的桌子上。
当 Node 上的 Memory 不足时(OOM),就会出现这种情况。Pod 访问不可用的 Memory,就会因 OOM 而被终止。如果客人只允许吃掉所订购数量的披萨,即 requests = limits,那么大家都将相安无事。
总结
在 Kubernetes 中,CPU 和 Memory 资源的管理和分配是非常重要的。通过合理地分配和管理这些资源,可以确保 Kubernetes 集群的稳定性和可用性,提高应用程序的性能。