概念 :质量验证与反馈机制
- ✅ 优点:自动化质量检查,实现持续优化闭环
- ❌ 缺点:评估准确性依赖模型能力

from typing import TypedDict
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from typing_extensions import Literal
import os
from pydantic import BaseModel,Field
# 初始化模型
llm = ChatOpenAI(
model="gpt-3.5-turbo",
openai_api_key=os.environ["GPT_API_KEY"],
openai_api_base="https://api.chatanywhere.tech/v1",
streaming=False # 禁用流式传输
)
class Feedback(BaseModel):
grade: Literal["合格", "不合格"] = Field(
description="判断文章的逻辑性是否合格"
)
feedback: str = Field(
description="对文章的逻辑性进行评价,给出修改建议"
)
class State(TypedDict):
topic: str # 主题
paper: str # 文章内容
feedback: str # 反馈内容
good_or_not: str # 逻辑性是否合格
count: int # 文章生成次数
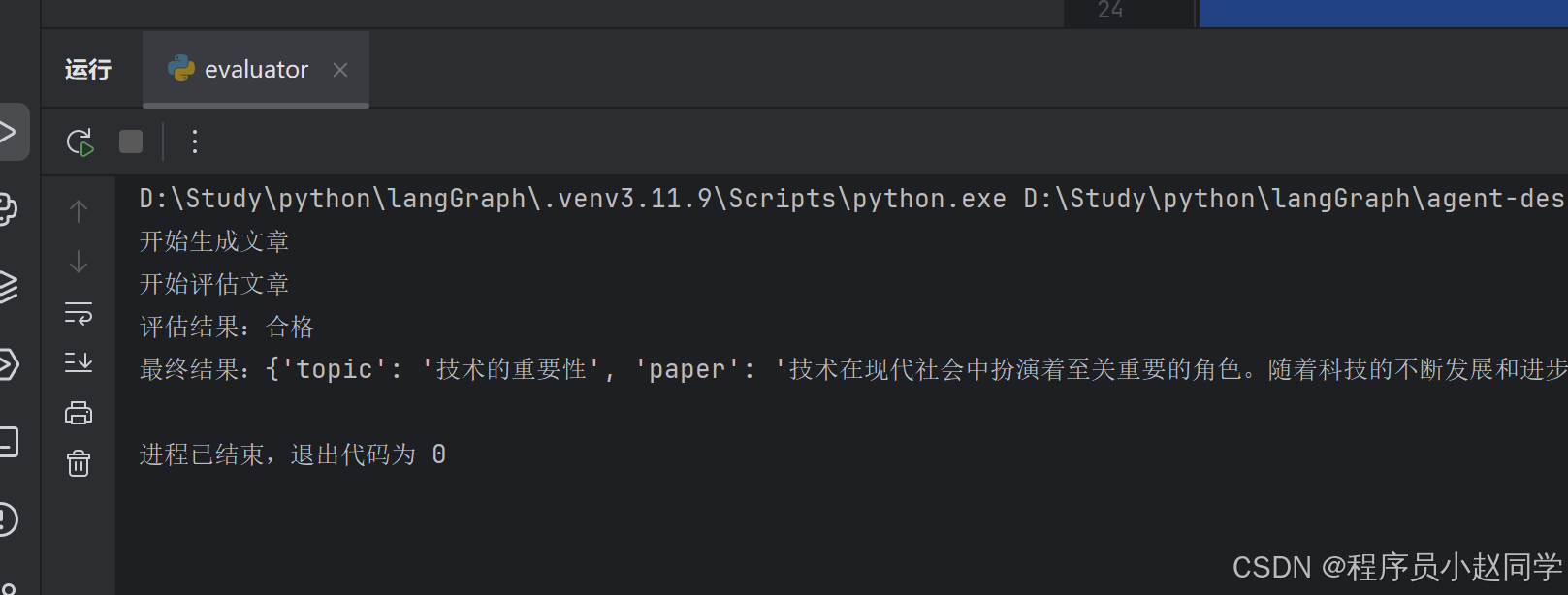
def llm_call_generator(state: State):
print("开始生成文章")
if state.get("feedback"):
prompt = f"""根据提供的主题写一篇文章。确保文章逻辑严谨,有说服力。
主题为:{state['topic']}
你同事需要考虑如下修改建议:{state['feedback']}
"""
msg = llm.invoke(prompt)
else:
prompt = f"""根据提供的主题写一篇文章。确保文章逻辑严谨,有说服力。
主题为:{state['topic']}
"""
msg = llm.invoke(prompt)
count = state.get("count", 0) + 1
return {
"paper": msg.content,
"count": count
}
def llm_call_evaluator(state: State):
print("开始评估文章")
evaluate = llm.with_structured_output(Feedback, method="function_calling")
prompt = f"""
请对文章进行逻辑性判断,给出评价。
文章为:{state['paper']}
"""
msg = evaluate.invoke(prompt)
print(f"评估结果:{msg.grade}")
return {
"feedback": msg.feedback,
"good_or_not": msg.grade
}
def route_paper(state: State):
if state["good_or_not"] == "合格":
return "Accept"
elif state["count"] >= 2:
return "Accept"
elif state["good_or_not"] == "不合格":
return "Reject and Feedback"
workflow = StateGraph(State)
workflow.add_node("llm_call_generator", llm_call_generator)
workflow.add_node("llm_call_evaluator", llm_call_evaluator)
workflow.add_edge(START, "llm_call_generator")
workflow.add_edge("llm_call_generator", "llm_call_evaluator")
workflow.add_conditional_edges(
"llm_call_evaluator",
route_paper,
{
"Accept": END,
"Reject and Feedback": "llm_call_generator"
}
)
graph = workflow.compile()
result = graph.invoke({"topic": "技术的重要性"})
print(f"最终结果:{result}")
执行结果:
常见问题
遇到的问题如下:
结构化输出这里太难用了 每次都报结构化输出失败。。。
router = llm.with_structured_output(Route)
openai.BadRequestError: Error code: 400 - {‘error’: {‘code’: ‘invalid_parameter_error’, ‘param’: None, ‘message’: ‘<400> InternalError.Algo.InvalidParameter: The tool call is not supported.’, ‘type’: ‘invalid_request_error’}, ‘id’: ‘chatcmpl-a711b580-58af-9286-bad1-ddc36b8a44d2’, ‘request_id’: ‘a711b580-58af-9286-bad1-ddc36b8a44d2’}
During task with name ‘llm_call_router’ and id ‘3437df04-e2bc-aac5-f29b-c3417070c369’
原因:
with_structured_output方法对很多大模型没有适配,原本用的deepseek一直报错,换成chatgpt之后就没问题了