自然语言处理框架
目录
bert自然语言处理框架
概念
BERT(Bidirectional Encoder Representations from Transformers)是 Google 于 2018 年提出的,基于Transformer的双向编码器表示模型,它通过预训练学习到了丰富的语言表示,并可以用于各种自然语言处理任务。它的核心思想是通过双向上下文理解和大规模预训练,学习通用的语言表示,再通过微调(Fine-tuning)适配下游任务。
核心特点
双向上下文编码:与传统模型(如 LSTM 或 GPT)不同,BERT 通过 Transformer 的 Self-Attention 机制同时学习单词的左右上下文。例如,在句子 “The bank of the river” 中,“bank” 的语义会根据上下文双向编码,避免歧义。
Transformer 架构:基于 Transformer 的 Encoder 层(原始论文使用 12 或 24 层),无需循环结构即可捕捉长距离依赖关系。
预训练 + 微调范式:
- 预训练:在大规模无标签文本(如 Wikipedia、BookCorpus)上训练,学习通用语言表示。
- 微调:用少量标注数据对预训练模型进行轻微调整,适配具体任务(如分类、问答)。
应用场景
通过微调,BERT 可应用于几乎所有 NLP 任务:
- 文本分类(如情感分析)
用 [CLS] 位置的输出向量作为分类特征。 - 命名实体识别(NER)
对每个单词的输出向量进行标签预测。 - 问答系统(SQuAD)
预测答案在文本中的起始和结束位置。 - 句子相似度
比较两个句子的嵌入表示。
框架和数据集
结构
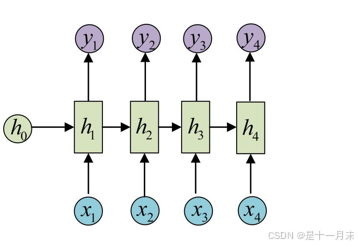
- 传统RNN网络
- 串联,导致数据必须从h1-h2-…hm。数据训练时间变长,因为需要要等h1的结果出来才能计算h2。
- 并行计算效果不好,也就是不能多台服务器同时训练一个网络。
- 传统word2vec
- 词向量一旦训练好了,就不会改变
- 不同语境中的词含义不同,例如 【a、台湾人说机车。 b、机车】
因此根据上下文不同的语境,应该有多个不同的词向量。
- Bert
Self-Attention 机制同时学习单词的左右上下文。
基于 Transformer 的 Encoder 层(原始论文使用 12 或 24 层),无需循环结构即可捕捉长距离依赖关系。- Multi-Head Self-Attention 层,计算输入序列中所有词对的关联权重,动态捕捉上下文依赖。
- 前馈神经网络(Feed-Forward Network, FFN)层,对每个位置的表示进行非线性变换。
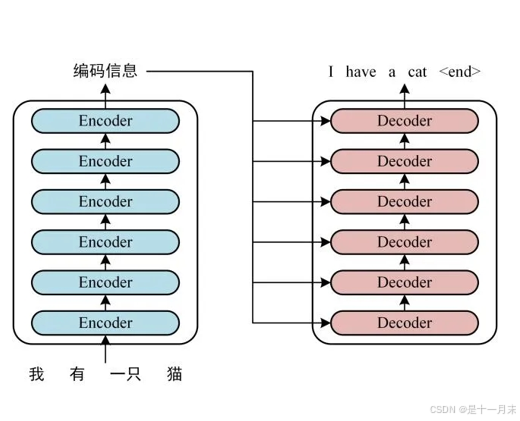
编码-解码框架
- Encoder-Decoder:也就是编码-解码框架,目前大部分attention模型都是依附于Encoder-Decoder框架进行实现。
- 在NLP中Encoder-Decoder框架主要被用来处理序列-序列问题。也就是输入一个序列,生成一个序列的问题。这两个序列可以分别是任意长度。
- Encoder:编码器,对于输入的序列<x1,x2,x3…xn>进行编码,使其转化为一个语义编码C,这个C中就储存了序列<x1,x2,x3…xn>的信息。
- Decoder:解码器,根据输入的语义编码C,然后将其解码成序列数据,解码方式也可以采用。Decoder和Encoder的编码解码方式可以任意组合。
Self-Attention 机制
The animal didn’t cross the street because it was too tired.
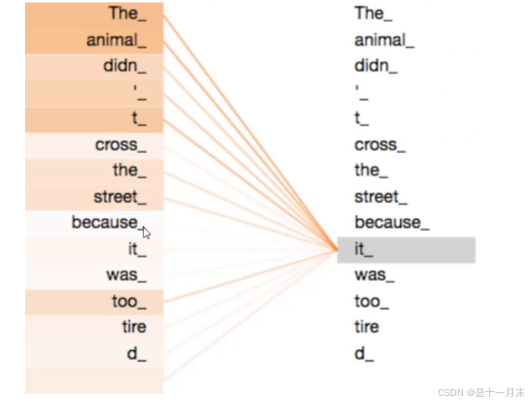
计算一段话中每个词之间的匹配程度,通过匹配程度得到每个词的特征重要性。
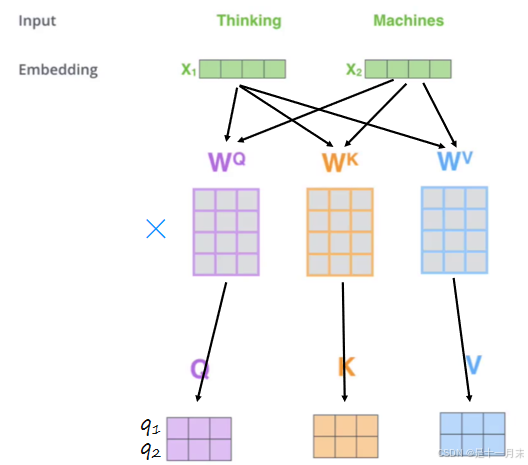
- 首先输入经过编码后得到的词向量
- 构建三个矩阵,相当于cnn的卷积核,分别为wQ、wK、wv矩阵。
- 将每一个词向量与矩阵相乘。得到QKV矩阵。
- 其中Q:为需要查询的
- K:为等着被查的
- V:实际的特征信息
q1和k1的内积表示第1个词和第1个词的匹配程度
q1和k2的内积表示第1个词和第2个词的匹配程度
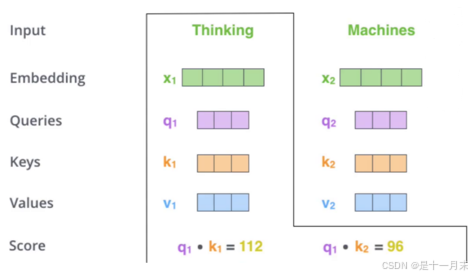
每个词的Q会跟整个序列中的每一个K计算得分,然后基于得分再分配特征。
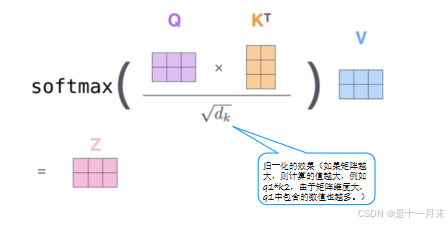

因此当和不同的词组合成序列,就会得到不同的特征值。因为不同的组合序列语句,注意力不同。
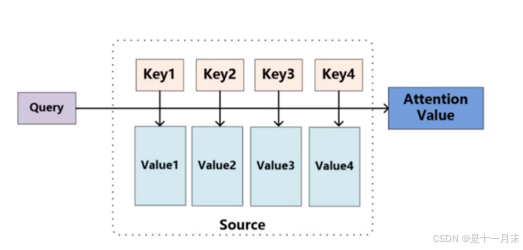
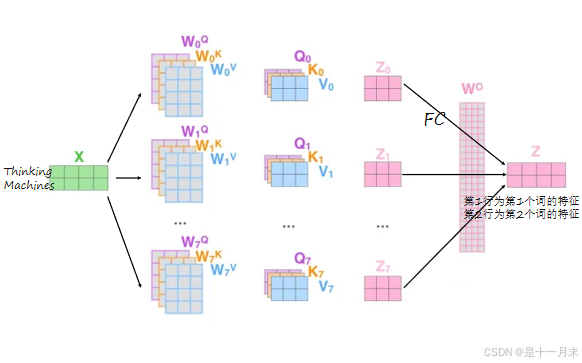
multi-headed机制
卷积神经网络种有多组卷积核,就会产生多个特征图。同理,在transformer中有多组q、k、v就会得到多种词的特征表达。
- 通过不同的head得到多个特征表达,一般8个head
- 将所有特征拼接在一起
- 降维,将Z0~Z7连接一个FC全连接实现降维
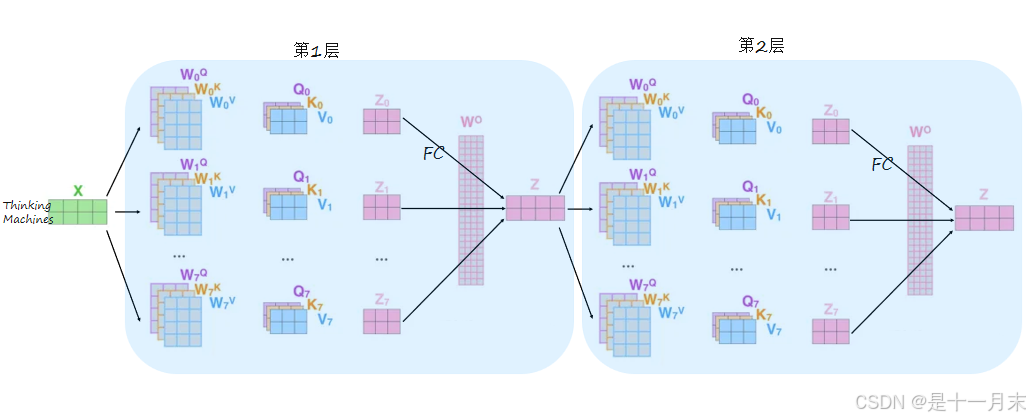
多层堆叠网络层
位置编码
还需要考虑词的顺序,长度,每个位置的真实的权重,Transformer的作者设计了一种可以满足上面要求的三角函数位置编码方式。
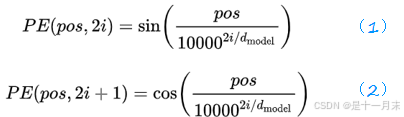
- word embedding:是词向量,由每个词根据查表得到
- pos embedding:就是位置编码。
- composition:word embedding和pos embedding逐点相加得到,既包含语义信息又包含位置编码信息的最终矩阵。
- pos:指当前字符在句子中的位置(如:”你好啊”,这句话里面“你”的pos=0),
- dmodel:指的是word embedding的长度(例“民主”的word embedding为[1,2,3,4,5],则dmodel=5),
- 2i表示偶数,2i+1表示奇数。取值范围:i=0,1,…,dmodel−1。偶数使用公式(1),奇数时使用公式(2)。
当pos=3,dmodel=128时Positional Encoding(或者说是pos embedding)的计算结果为:
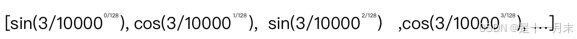
不同语句相同位置的字符PE值一样(如:当pos=0时,PE=0)。

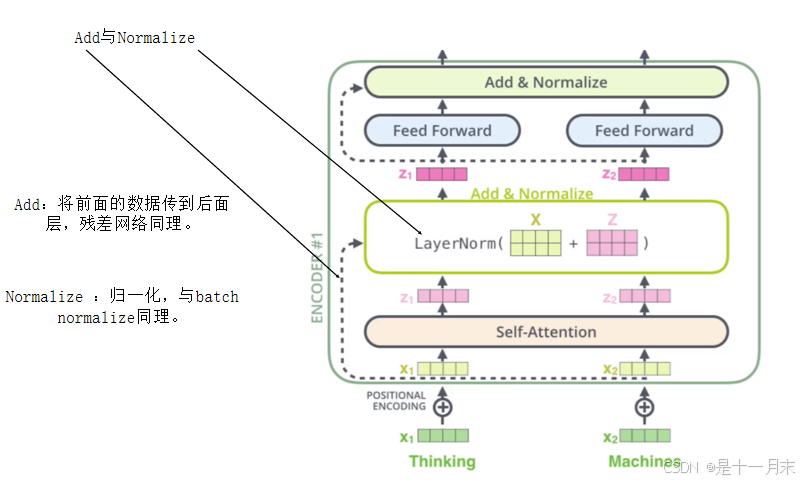
Add与Normalize
Add:将前面的数据传到后面层,残差网络同理。
Normalize :归一化,与batch normalize同理。
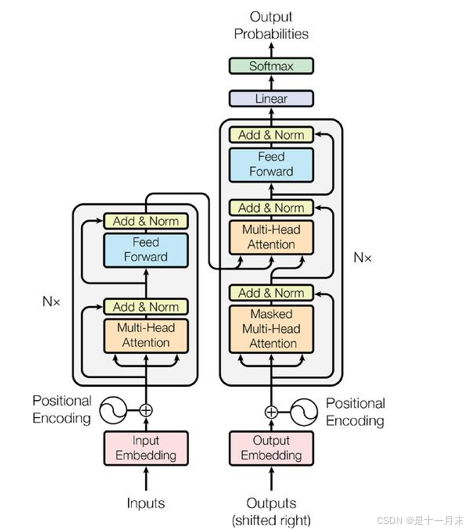
整体框架
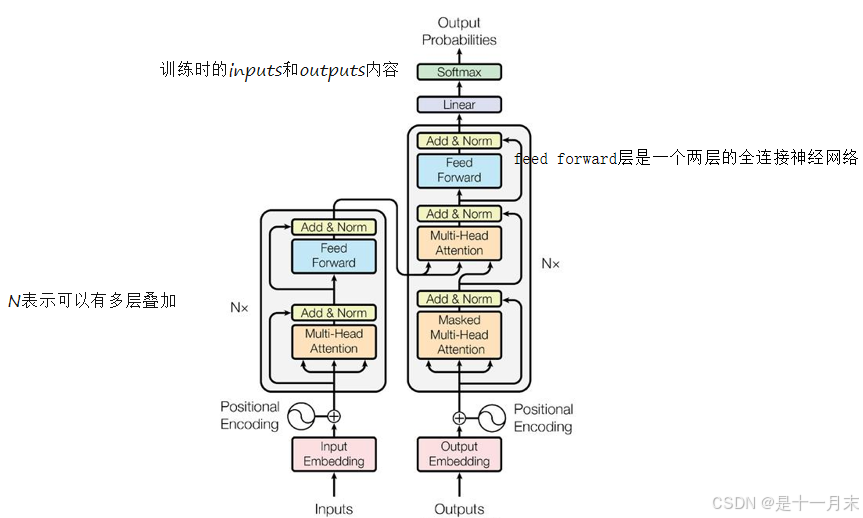
outputs
- outputs(shifted right):指在解码器处理过程中,将之前的输出序列向右移动一位,并在最左侧添加一个新的起始符(如“”或目标序列开始的特殊token)作为新的输入。这样做的目的是让解码器在生成下一个词时,能够考虑到已经生成的词序列。
- 作用:通过“shifted right”操作,解码器能够在生成每个词时,都基于之前已经生成的词序列进行推断。这样,解码器就能够逐步构建出完整的输出序列。
- 示例说明:假设翻译任务,输入是“我爱中国”,目标输出是“I love China”。在解码器的处理过程中:
在第一个步, 解码器接收一个起始符(如“”)作为输入,并预测输出序列的第一个词“I”。
在第二个步,解码器将之前的输出“I”和起始符一起作为新的输入(即“ I”),并预测下一个词 ,“love”。
以此类推,直到解码器生成完整的输出序列“I love China”。
训练数据集
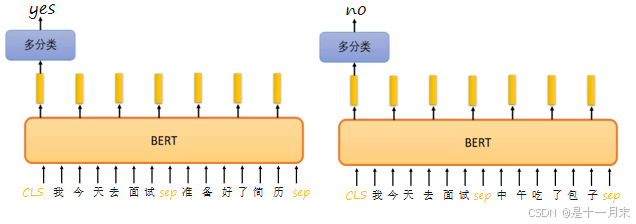
- CLS:分类标记(Classification Token)用于表示输入序列的开始。在输入序列中,CLS应放置在句子的开头。在训练过程中,CLS也当作一个词参与训练,得到对应与其他词汇关系的词向量。
- SEP:分隔符标记(Separator Token)用于分隔两个句子或表示单个句子的结束。在处理多个句子时SEP应放置在每个句子的结尾。在训练过程中,SEP也当作一个词参与训练,得到对应与其他词汇关系的词向量。
方法1:随机的将句子中的15%的词汇进行mask,让模型去预测mask的词汇。
解决传统语言模型只能单向预测的问题。
注:一般选择字进行mask,词的可能性太多,例如今天,明天,后天,上午,下午,没有,再次等等。
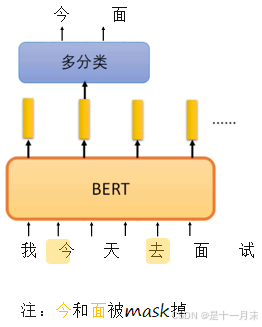
方法2:预测两个句子是否应该连在一起。
帮助模型理解句子间关系。