文章目录

引言:微服务时代的日志挑战
在单体架构时代,我们通过查看单个应用日志就能快速定位问题。但当系统拆分为微服务后,一个请求可能横跨多个服务节点,传统的日志记录方式如同散落的拼图,难以还原完整的业务场景。接下来将分享一次真实的微服务全链路日志建设历程,揭秘如何通过技术选型打造可视化日志追踪体系。
一、业务痛点与需求分析
当系统从单体架构迁移到Spring Cloud微服务体系后,原有日志系统暴露出三大问题:
- 日志孤岛:各服务独立记录日志,无法串联完整请求路径
- 规范缺失:日志格式不统一,关键信息记录不全
- 定位低效:排查问题需要跨多台服务器拼凑日志
为此我们提出核心需求矩阵:
| 需求类型 | 具体要求 |
|---|---|
| 基础记录 | 中间件调用、SQL执行、服务间调用耗时统计 |
| 链路追踪 | 跨服务请求树状结构可视化 |
| 高阶功能 | 日志查询统计、监控报警、性能分析 |
二、技术选型的六维评估模型
面对众多开源方案(SkyWalking/Zipkin/Jaeger等),
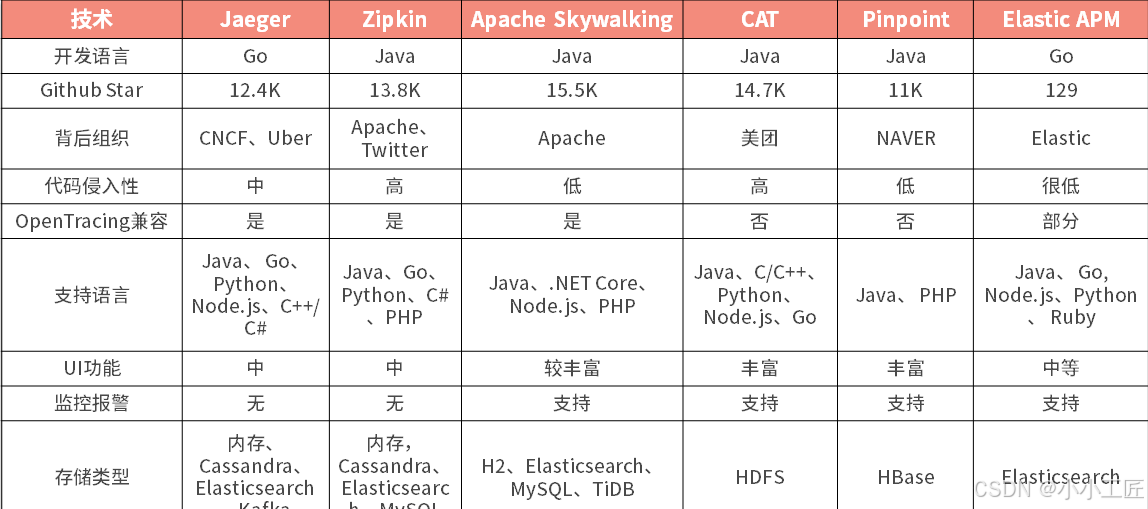
我们建立了一套量化评估体系:
1. 标准化支持 OpenTracing
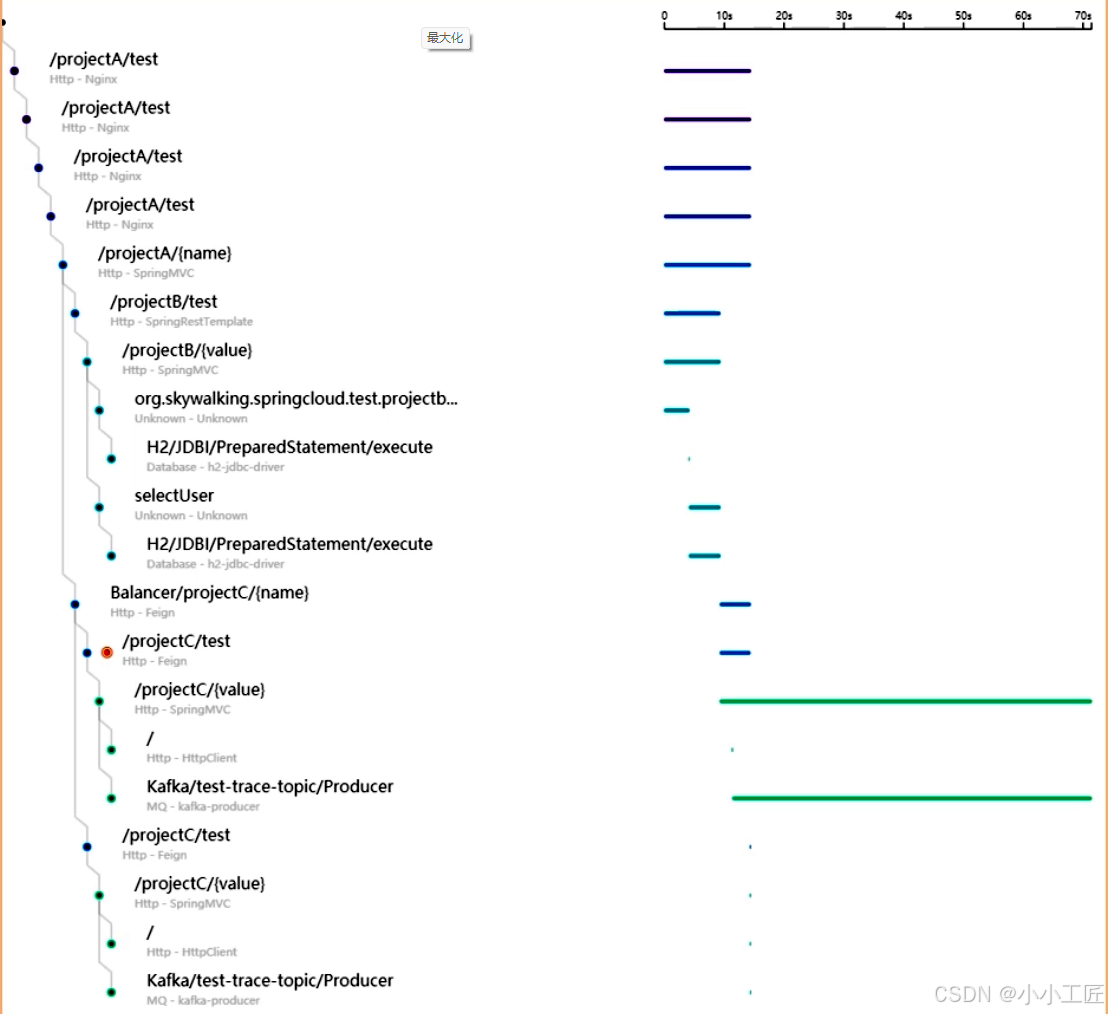
OpenTracing规范成为关键指标。该标准定义了Trace(完整请求链路)和Span(具体执行单元)的模型:

在上图中,我们看到一个客户端调用 Order API 的请求时经历的整个流程(1 到 10),即 1 个 Trace,之后它又调用了 Product Service 的整个过程(2 到 5),这就是 1 个 Span,每个 Span 代表 Trace 中被命名且被计时的连续性执行片段。
通过上图我们还发现,Span 中又包含了一个子 Span,比如调用 Product Service 的过程中,Product Service 会访问一次数据库(3 到 4),这也是一个 Span。因此,我们可以得出一个 Span 可以包含多个子 Span,而 Span 与 Span 之间的关系就叫 Reference。
2. 存储扩展性
选择Elasticsearch作为存储引擎,其优势在于:
- 天然支持时间序列数据
- 分布式横向扩展能力
- 与现有ELK体系无缝集成
3. 性能损耗
通过压力测试对比(模拟500并发场景):
| 方案 | TPS下降 | 内存增幅 |
|---|---|---|
| SkyWalking | <8% | 12% |
| Pinpoint | 53% | 68% |
4. 功能完备性
对比主流方案功能点:
| 功能 | SkyWalking | Zipkin | Jaeger |
|---|---|---|---|
| 服务拓扑图 | ✔️ | ❌ | ❌ |
| 慢查询分析 | ✔️ | ❌ | ✔️ |
| 报警规则 | ✔️ | ❌ | ❌ |
| 日志采样策略 | ✔️ | ✔️ | ✔️ |

5. 侵入性控制
采用Java Agent字节码增强技术,实现零代码入侵:
# 启动参数示例
-javaagent:/path/skywalking-agent.jar
-Dskywalking.agent.service_name=order-service
6. 社区生态
参考CNCF官方数据(2023):
| 方案 | GitHub Stars | 企业用户数 |
|---|---|---|
| SkyWalking | 23k | 1200+ |
| Jaeger | 18k | 800+ |
三、SkyWalking落地实践与调优
1. 核心架构解析
SkyWalking 数据收集机制是这样的:服务中有一个本地缓存,我们把收集的所有日志数据先存放在这个缓存中,然后后台线程通过异步的方式将缓存中的日志发送给 SkyWalking 服务端。通过这种机制,在日志埋点的地方,我们无须等待服务端接收受数据,也就不影响系统性能。
数据采集流程:
- Agent通过字节码增强埋点
- 本地缓存Trace数据(环形队列结构)
- gRPC异步上报至OAP Server
- 数据持久化到Elasticsearch
2. 关键配置示例: 采样率控制
流量大时,我们不可能收集每个请求的日志,这样数据量太大了。那 SkyWalking 如何控制采样比例呢?
SkyWalking 会在每个服务器上配置采样比例,比如设置为 100,代表 1% 的请求数据会被收集,如下代码所示。
agent-analyzer:
default:
...
sampleRate: ${SW_TracE_SAMPLE_RATE:1000} # The sample rate precision is 1/10000. 10000 means 100% sample in default.
forceSampleErrorSegment: ${SW_FORCE_SAMPLE_ERROR_SEGMENT:true} # When sampling mechanism activated, this config would make the error status segment sampled, ignoring the sampling rate.
这样,我们就可以通过 sampleRate 控制采样比率了,一般而言,流量越大,采样比例越小。
不过,这里有 2 点需要特别注意。
- 一旦启用 forceSampleErrorSegment ,出现错误时所有的数据全部会收集,此时 sampleRate 对出错的请求不再适用。
- 所有相关联服务的 sampleRate 最好保持一致,如果 A 调用 B,然后 A、B 的采样率不一样,就会出现一个 Trace 串不起来的情况。
存储策略:
# application.yml
recordDataTTL: 72 # 原始数据保留3天
metricsDataTTL: 168 # 指标数据保留7天
3. 高可用部署方案

四、五大避坑指南
1. 内存控制策略
设置合理的缓存队列大小,防止服务端宕机导致内存溢出:
buffer.channel_size: 5000 # 内存队列容量
buffer.buffer_size: 30000 # 磁盘队列容量(需挂载SSD)
2. 全链路采样一致性
通过环境变量统一配置采样率:
# 所有服务的启动参数
-Dskywalking.trace.sample_rate=1000
3. 跨语言支持方案
对于非Java服务(如Node.js),使用Sidecar模式:
const { ApolloServer } = require('apollo-server');
const { SkyWalkingClient } = require('skywalking-client');
const client = new SkyWalkingClient({
serviceName: 'node-service',
oapServer: 'http://oap:12800'
});
4. 自定义埋点扩展
在基础框架层手动埋点:
public class RedisTemplateWrapper extends RedisTemplate {
@Override
public ValueOperations opsForValue() {
Span span = ContextManager.createLocalSpan("Redis/GET");
try {
return super.opsForValue();
} finally {
span.tag("db.type", "redis");
span.finish();
}
}
}
5. 监控告警配置
设置慢查询告警规则:
rules:
service_sla_rule:
metrics-name: service_sla
op: "<"
threshold: 99
period: 10
count: 3
silence-period: 5
message: Service SLA低于99%
五、总结与展望
通过SkyWalking的落地,我们实现了:
✅ 请求全链路可视化追踪
✅ 端到端性能分析
✅ 异常请求快速定位
未来演进方向:
- 与Service Mesh集成,实现更细粒度控制
- 结合AIOps实现异常预测
- 构建统一的观测平台(Metrics/Logs/Traces融合)
微服务可观测性建设永无止境,选择适合当前阶段的工具,同时保持架构的开放性,才能在技术迭代中立于不败之地。正如Martin Fowler所言:“监控系统应该像氧气一样无处不在却不觉存在”,这正是我们持续追求的目标。
