背景
在理解与学会了Naive RAG的框架流程后,就很自然地关注到embedding模型,与问题相关的文本召回,也有很多论文在做这方面的创新。
以前一直不知道embedding模型是如何微调出来的,一直听说是微调BERT,但是不知道是怎么微调出来的。直到在B站上看到bge模型微调的视频[参考资料4]才理解。
于是便想着自己也微调出一个 embedding模型。涉及到下面三个阶段:
- 数据集制作
- 模型训练
- 评估
微调实战
装包
pip install -U FlagEmbedding[finetune]
项目基于 https://github.com/FlagOpen/FlagEmbedding,若遇到环境报错,可参考该项目的环境,完成python环境设置
FlagEmbedding论文:C-Pack: Packed Resources For General Chinese Embeddings , 也称 C-METB
介绍
你可以阅读参考资料[1]和[2],先尝试实现一次官方的微调教程。
官方微调的模型是BAAI/bge-large-en-v1.5,我选择直接微调BERT模型,这样感受微调的效果更明显。仅仅是出于学习的目的,我才选择微调BERT,如果大家打算用于生产环境,还是要选择微调现成的embedding模型。因为embedding模型也分为预训练与微调两个阶段,我们不做预训练。
embedding 模型需要通过encode方法把文本变成向量,而BERT模型没有encode方法。故要使用FlagEmbedding导入原生的BERT模型。
from FlagEmbedding.inference.embedder.encoder_only.base import BaseEmbedder
# 省略数据集加载代码
bert_embedding = BaseEmbedder("bert-base-uncased")
# get the embedding of the corpus
corpus_embeddings = bert_embedding.encode(corpus_dataset["text"])
print("shape of the corpus embeddings:", corpus_embeddings.shape)
print("data type of the embeddings: ", corpus_embeddings.dtype)
可浏览:eval_raw_bert.ipynb
项目文件介绍
数据集构建:
build_train_dataset.ipynb: 构建训练集数据,随机采样负样本数据通过修改
neg_num的值,构架了training_neg_10.json和training_neg_50.json两个训练的数据集,比较增加负样本的数量是否能提高模型召回的效果(实验结果表明:这里的效果并不好,提升不明显)。build_eval_dataset.ipynb: 构建测试集数据,评估大模型生成的效果。与FlagEmbedding数据集构建结构不同,我个人用这种数据集样式更方便,不需要像FlagEmbedding一样从下标读出正确的样本的数据。
模型训练:
finetune_neg10.shfinetune_neg50.sh
finetune_neg10.sh的代码如下:
torchrun --nproc_per_node=1 \
-m FlagEmbedding.finetune.embedder.encoder_only.base \
--model_name_or_path bert-base-uncased \
--train_data ./ft_data/training_neg_10.json \
--train_group_size 8 \
--query_max_len 512 \
--passage_max_len 512 \
--pad_to_multiple_of 8 \
--query_instruction_for_retrieval 'Represent this sentence for searching relevant passages: ' \
--query_instruction_format '{}{}' \
--output_dir ./output/bert-base-uncased_neg10 \
--overwrite_output_dir \
--learning_rate 1e-5 \
--fp16 \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--warmup_ratio 0.1 \
--logging_steps 200 \
--save_steps 2000 \
--temperature 0.02 \
--sentence_pooling_method cls \
--normalize_embeddings True \
--kd_loss_type kl_div
bash finetune_neg10.sh > finetune_neg10.log 2>&1 & 把训练的日志保存到 finetune_neg10.log 日志文件中,训练用时6分钟。
neg10代表每条数据10个负样本,neg50代表每条数据50个负样本。
评估:
评估是在所有语料上完成的评估,并不是在指定的固定数量的负样本上完成的评估。
由于是在全部语料上完成召回,故使用到了faiss向量数据库。
eval_raw_bert.ipynb: 评估BERT原生模型eval_train_neg10.ipynb: 评估基于10条负样本微调后的模型eval_train_neg50.ipynb: 评估基于50条负样本微调后的模型eval_bge_m3.ipynb: 评估 BAAI 现在表现效果好的 BGE-M3 模型
结论:通过评估结果,可看出BERT经过微调后的提升明显,但依然达不到BGE-M3 模型的效果。
微调硬件配置要求
微调过程中GPU显存占用达到了9G左右
设备只有一台GPU
debug 重要代码分析【选看】
下述代码是旧版本的代码,不是最新的FlagEmbedding的代码:
- 视频教程,bge模型微调流程:https://www.bilibili.com/video/BV1eu4y1x7ix/
推荐使用23年10月份的代码进行debug,关注核心代码。新版的加了抽象类与继承,增加了很多额外的东西,使用早期版本debug起来更聚焦一些。
python run.py
--output_dir output
--model_name_or_path BAAI/bge-large-zh-v1.5
--train_data ./toy_finetune_data.jsonl
--learning_rate 1e-5
--fp16
--num_train_epochs 5
--per_device_train_batch_size 2
--dataloader_drop_last True
--normlized True
--temperature 0.02
--query_max_len 64
--passage_max_len 256
--train_group_size 2
--negatives_cross_device
--logging_steps 10
--query_instruction_for_retrieval "为这个句子生成表示以用于检索相关文章:"
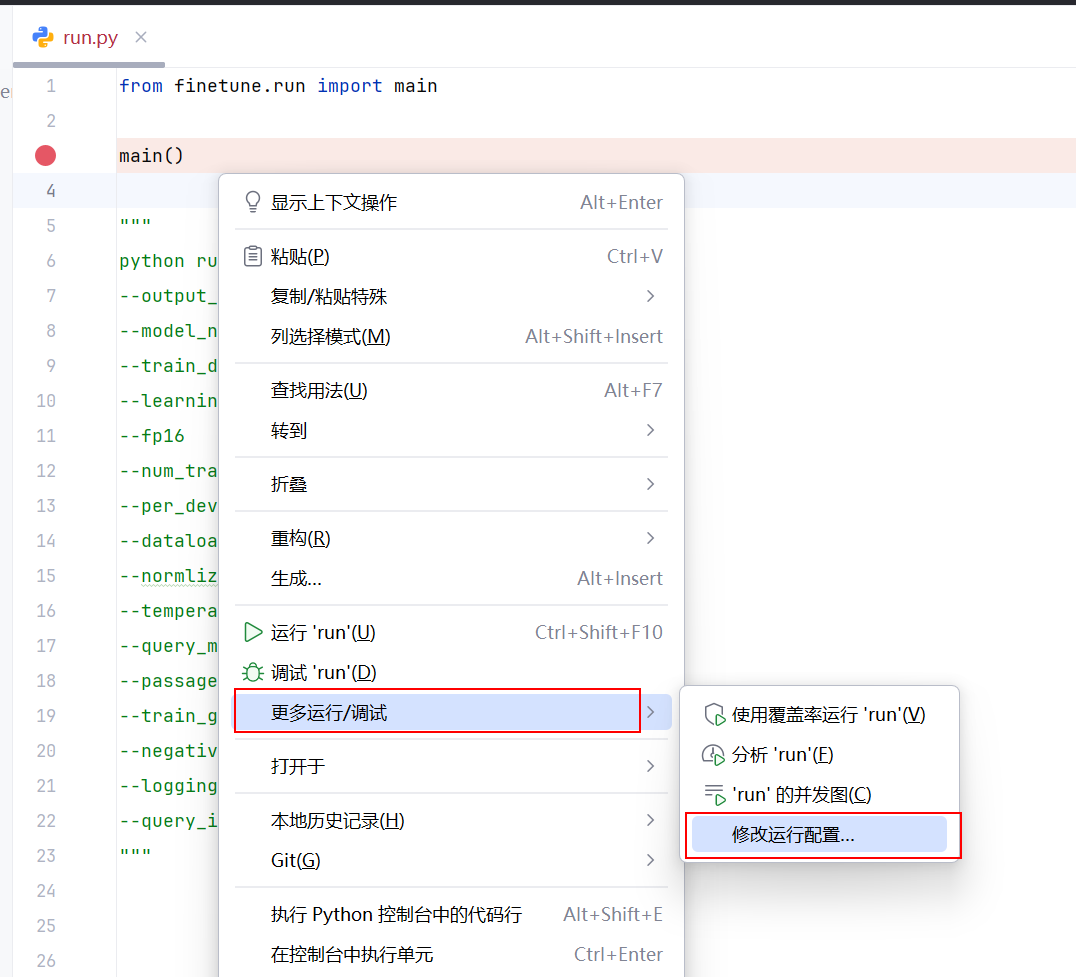
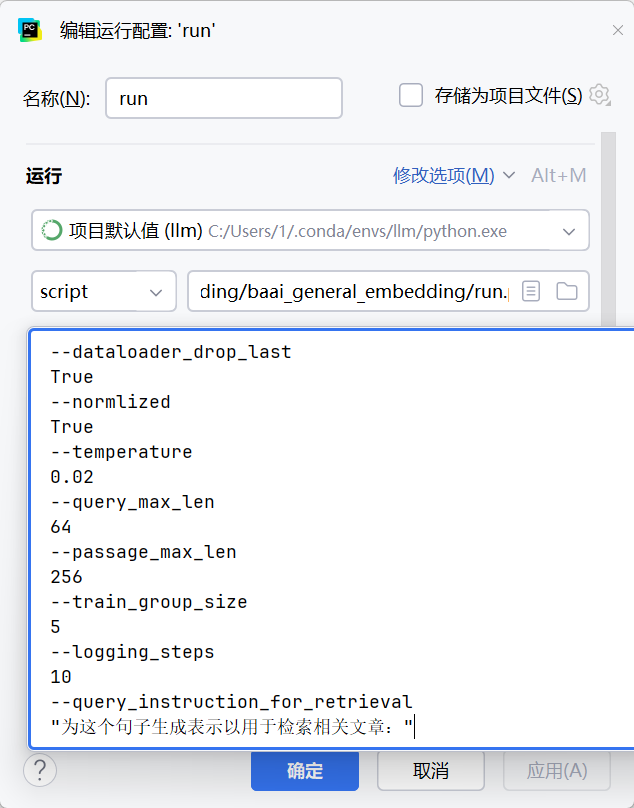
由于需要传递参数再运行脚本,需要在pycharm配置一些与运行相关的参数:
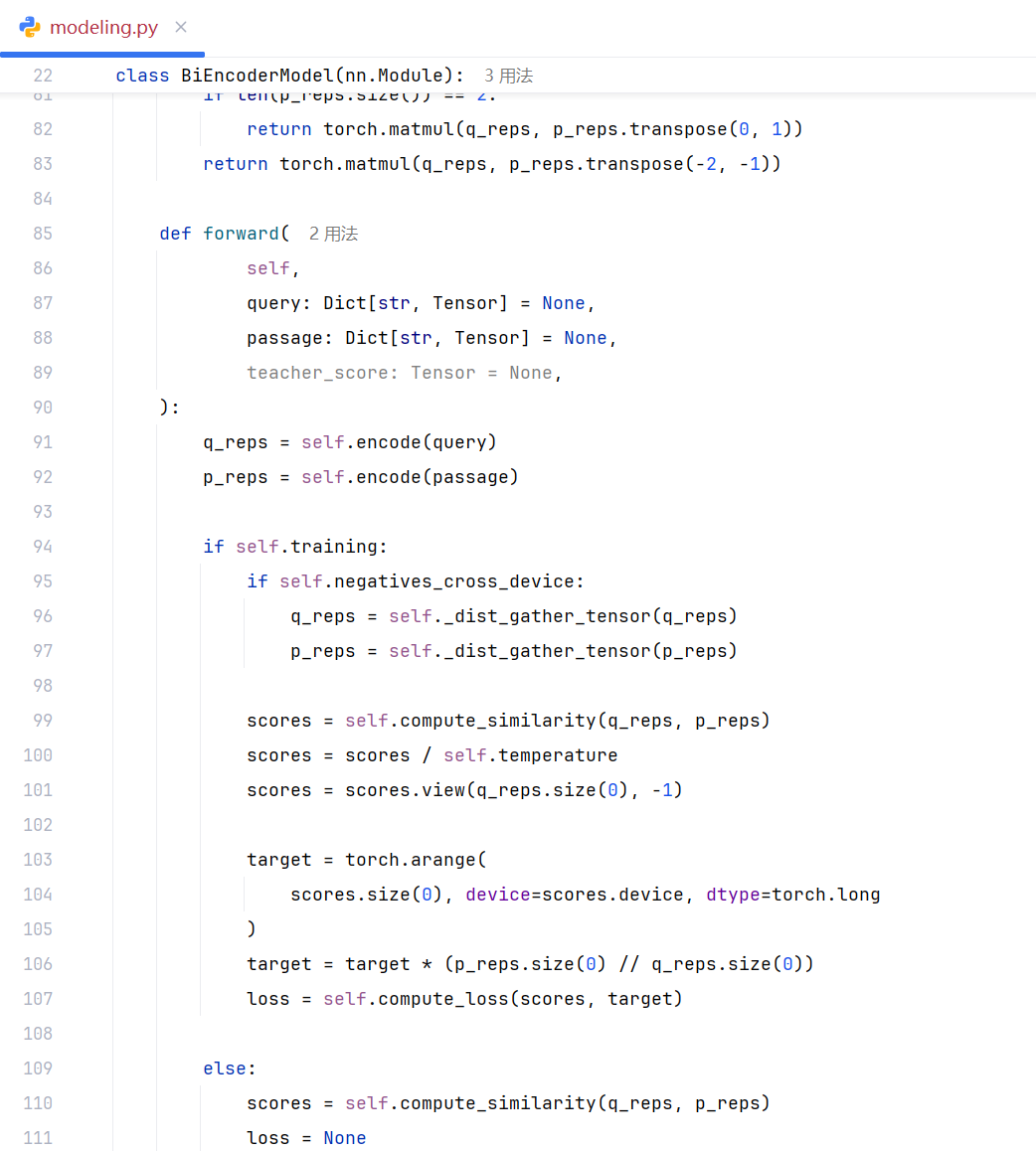
下述是embedding计算损失的核心代码,这里的query与passage都是batch_size数量的输入,如果只是一条query与passage,大家理解起来就容易很多。由于这里是batch_size数量的输入,代码中涉及到矩阵运算会给大家带来理解困难。
比较难理解的是下述代码,这里的target 其实就是label:
target = torch.arange(
scores.size(0), device=scores.device, dtype=torch.long
)
target = target * (p_reps.size(0) // q_reps.size(0))
p_reps 是相关文本矩阵, q_reps 是问题矩阵。每一个问题都对应固定数量的相关文本。p_reps.size(0) // q_reps.size(0) 是每个问题对应的相关文本的数量。下一行的target 乘以 相关文本的块数,得到query对应的 Gold Truth(也称 pos 文本)的下标,因为在每个相关文本中,第一个位置都是正确文本,其后是负样本,这些 Gold Truth 下标之间的距离是固定,通过乘法就可以计算出每个 Gold Truth 的下标。
额外补充【选看】:
在微调的过程中,不要错误的以为每个问题只和自己的相关文本计算score。真实的情况是,在batch_size的数据中,每个问题会与所有的相关文本计算score。根据上述代码可看出 target 最大的取值是:query的数量 x 相关文本数量,这也印证了每个问题会与所有的相关文本都计算score。故我们在随机采样负样本的时候,负样本数量设置的太小也不用太担心,因为在计算过程中负样本的数量会乘以 batch_size。
【注意】:query的数量 = batch_size
- 损失函数

def compute_loss(self, scores, target):
return self.cross_entropy(scores, target)
C-METB 论文中,关于损失函数的介绍,公式看起来很复杂,本质就是cross_entropy。
资源分享
上述的代码开源在github平台,为了不增大github仓库的容量,数据集没有上传到github平台。若希望直接获得完整的项目文件夹,从下述提供的网盘分享链接进行下载:
github开源地址:https://github.com/JieShenAI/csdn/tree/main/25/04/embedding_finetune
通过网盘分享的文件:embedding_finetune.zip
链接: https://pan.baidu.com/s/1CDRpkkjS1-0jtmIBiTWx1A 提取码: free
最新的代码,请以 github 的链接为准,网盘分享的文件,本意只是为了存储数据,避免增加github仓库的容量
参考资料
[1] BAAI官方微调教程: https://github.com/FlagOpen/FlagEmbedding/blob/master/Tutorials/7_Fine-tuning/7.1.2_Fine-tune.ipynb
[2] BAAI官方评估教程:https://github.com/FlagOpen/FlagEmbedding/blob/master/Tutorials/4_Evaluation/4.1.1_Evaluation_MSMARCO.ipynb
[3] 多文档知识图谱问答:https://jieshen.blog.csdn.net/article/details/146390208
[4] bge模型微调流程:https://www.bilibili.com/video/BV1eu4y1x7ix/
[5] FlagEmbedding 旧版本可用于debug的代码:https://github.com/FlagOpen/FlagEmbedding/blob/9b6e521bcb7583ed907f044ca092daef0ee90431/FlagEmbedding/baai_general_embedding/finetune/run.py