一、DOM4j 简介
DOM4j 是一个基于 Java 的开源 XML 解析库,具有以下特点:
- 高性能:基于
SAX解析器,支持快速读取 XML。 - 灵活性:支持创建、修改、查询 XML 文档。
- 易用性:提供简洁的 API,适合树形结构操作。
- 广泛使用:被 Hibernate 等框架采用。
二、环境准备
1. 添加依赖
方式一:通过 Maven(推荐) 在 pom.xml 中添加以下依赖:
Xml
<dependency>
<groupId>org.dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>2.1.3</version> <!-- 使用最新版本 -->
</dependency>方式二:手动下载 JAR 包
- 访问 DOM4j 官网 或 Maven 仓库 下载
dom4j-x.x.x.jar。 - 将 JAR 包添加到项目类路径中(如 IntelliJ 中右键项目 →
Open Module Settings→Libraries→ 添加 JAR)。
三、XML 文件示例
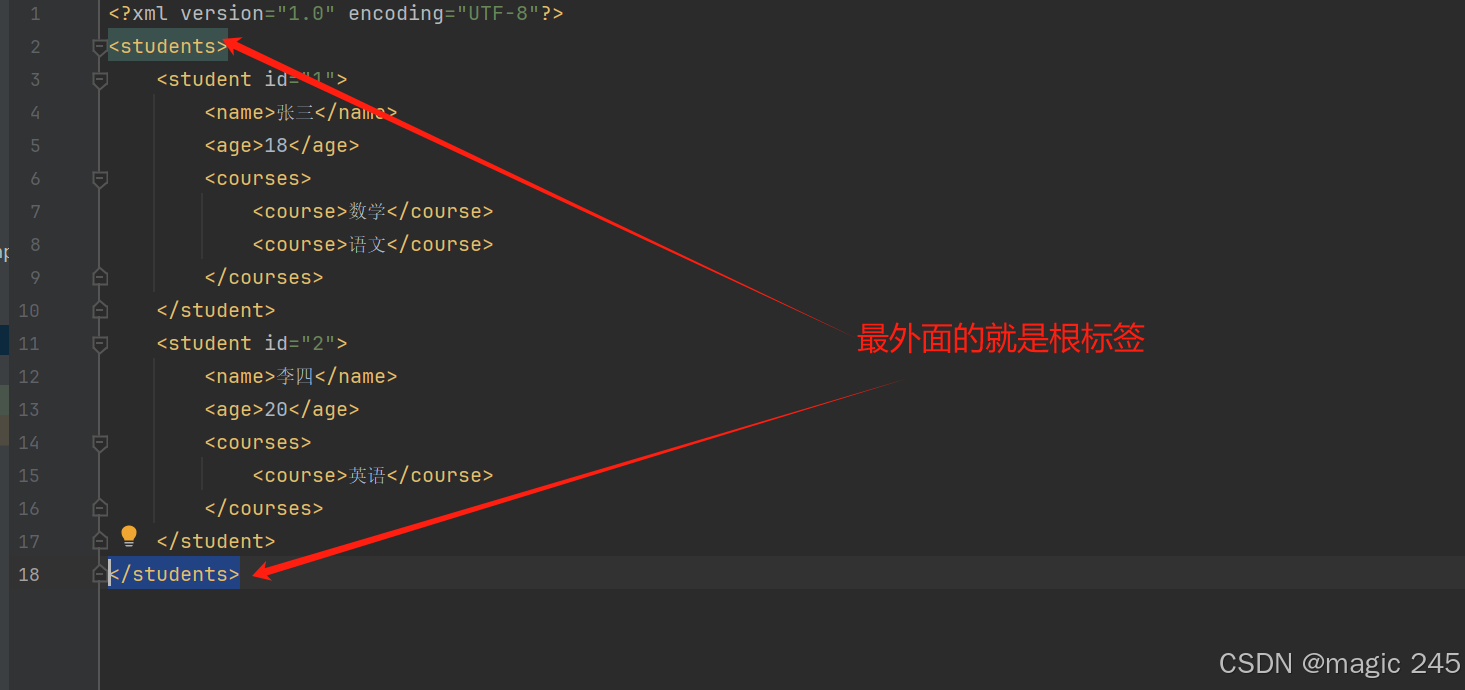
假设有一个 students.xml 文件:
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student id="1">
<name>张三</name>
<age>18</age>
<courses>
<course>数学</course>
<course>语文</course>
</courses>
</student>
<student id="2">
<name>李四</name>
<age>20</age>
<courses>
<course>英语</course>
</courses>
</student>
</students>四、解析 XML 的步骤
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.util.List;
public class XMLParser {
public static void main(String[] args) {
try {
// 1. 创建解析器
SAXReader reader = new SAXReader();
// 2. 加载 XML 文件(替换为实际路径)
Document document = reader.read("students.xml");
// 3. 获取根元素
Element root = document.getRootElement();
// 4. 遍历所有学生节点
List<Element> students = root.elements("student");
for (Element student : students) {
// 处理每个学生节点
processStudent(student);
}
} catch (Exception e) {
e.printStackTrace();
}
}
private static void processStudent(Element student) {
// 获取属性
String id = student.attributeValue("id");
// 获取子元素的文本内容
String name = student.elementText("name");
String age = student.elementText("age");
// 获取嵌套元素中的所有课程
Element coursesElement = student.element("courses");
List<Element> courses = coursesElement.elements("course");
String coursesText = courses.stream()
.map(Element::getText)
.reduce((a, b) -> a + ", " + b)
.orElse("");
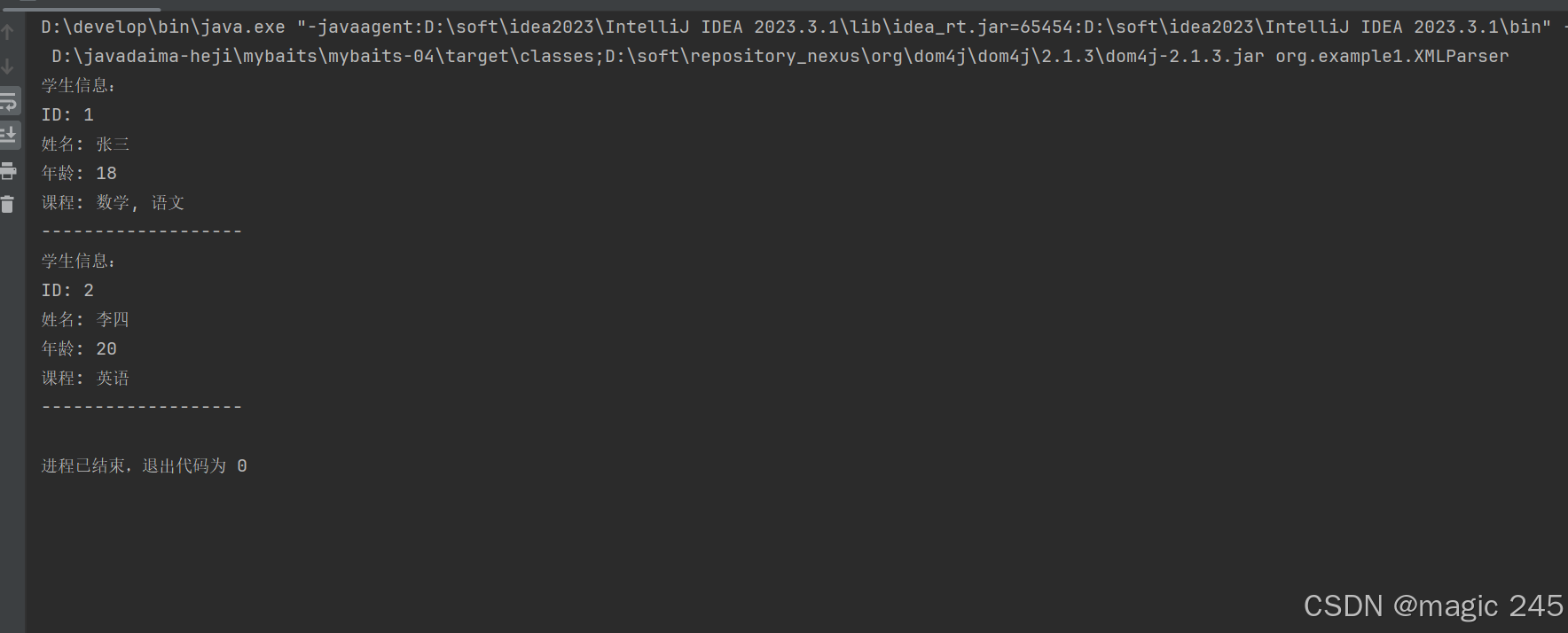
System.out.println("学生信息:");
System.out.println("ID: " + id);
System.out.println("姓名: " + name);
System.out.println("年龄: " + age);
System.out.println("课程: " + coursesText);
System.out.println("-------------------");
}
}1.遇到了报错
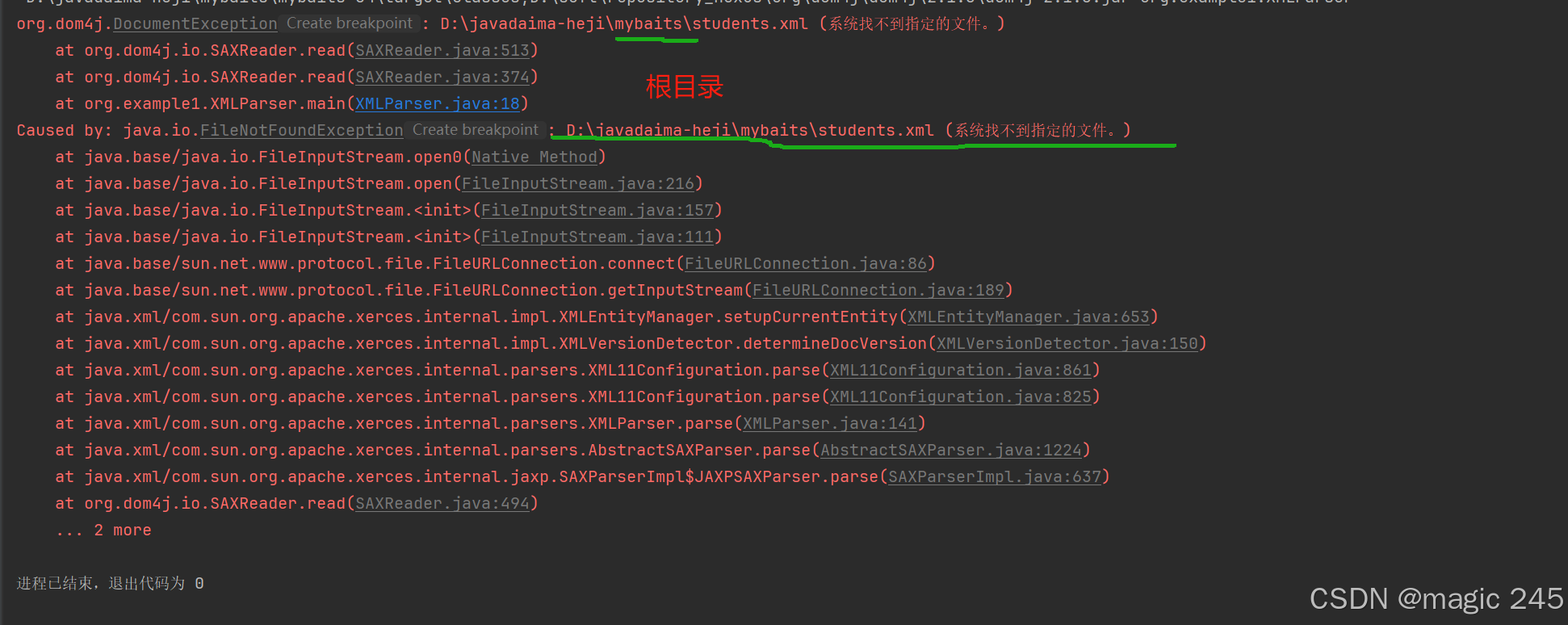
原因:
Document document = reader.read("students.xml"); // 这里路径是相对路径相对路径的基准目录 是程序的 工作目录(Working Directory),通常为项目的根目录或模块目录。
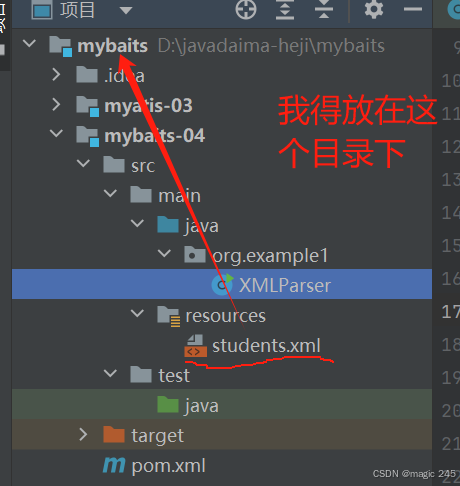
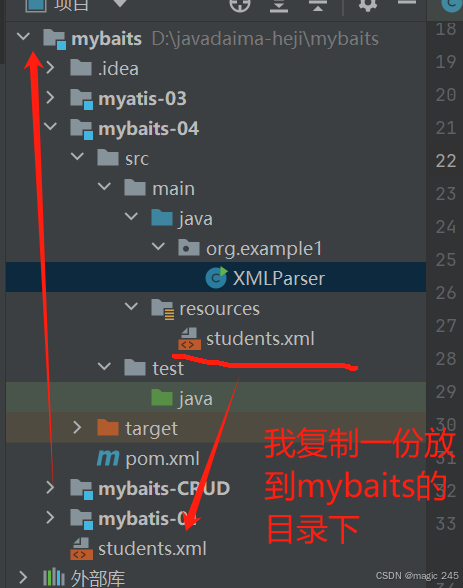
2.方法2
使用资源目录(推荐)
将 XML 文件放在项目的 资源目录(如 src/main/resources),并通过类加载器加载:
将 students.xml 放到 src/main/resources 目录:
D:\javadaima-heji\mybaits\mybaits-04\src\main\resources\students.xml修改代码:
import org.dom4j.io.SAXReader;
import java.io.InputStream;
public class XMLParser {
public static void main(String[] args) {
try {
SAXReader reader = new SAXReader();
// 通过类加载器加载资源文件
InputStream inputStream = XMLParser.class.getClassLoader().getResourceAsStream("students.xml");
Document document = reader.read(inputStream); // 使用输入流
// 继续处理...
} catch (Exception e) {
e.printStackTrace();
}
}
}package org.example1;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.InputStream;
import java.util.List;
public class XMLParser {
public static void main(String[] args) {
try {
// 1. 创建解析器
SAXReader reader = new SAXReader();
InputStream inputStream = XMLParser.class.getClassLoader().getResourceAsStream("students.xml");
Document document = reader.read(inputStream); // 使用输入流
// 3. 获取根元素
Element root = document.getRootElement();
// 4. 遍历所有学生节点
List<Element> students = root.elements("student");
for (Element student : students) {
// 处理每个学生节点
processStudent(student);
}
} catch (Exception e) {
e.printStackTrace();
}
}
private static void processStudent(Element student) {
// 获取属性
String id = student.attributeValue("id");
// 获取子元素的文本内容
String name = student.elementText("name");
String age = student.elementText("age");
// 获取嵌套元素中的所有课程
Element coursesElement = student.element("courses");
List<Element> courses = coursesElement.elements("course");
String coursesText = courses.stream()
.map(Element::getText)
.reduce((a, b) -> a + ", " + b)
.orElse("");
System.out.println("学生信息:");
System.out.println("ID: " + id);
System.out.println("姓名: " + name);
System.out.println("年龄: " + age);
System.out.println("课程: " + coursesText);
System.out.println("-------------------");
}
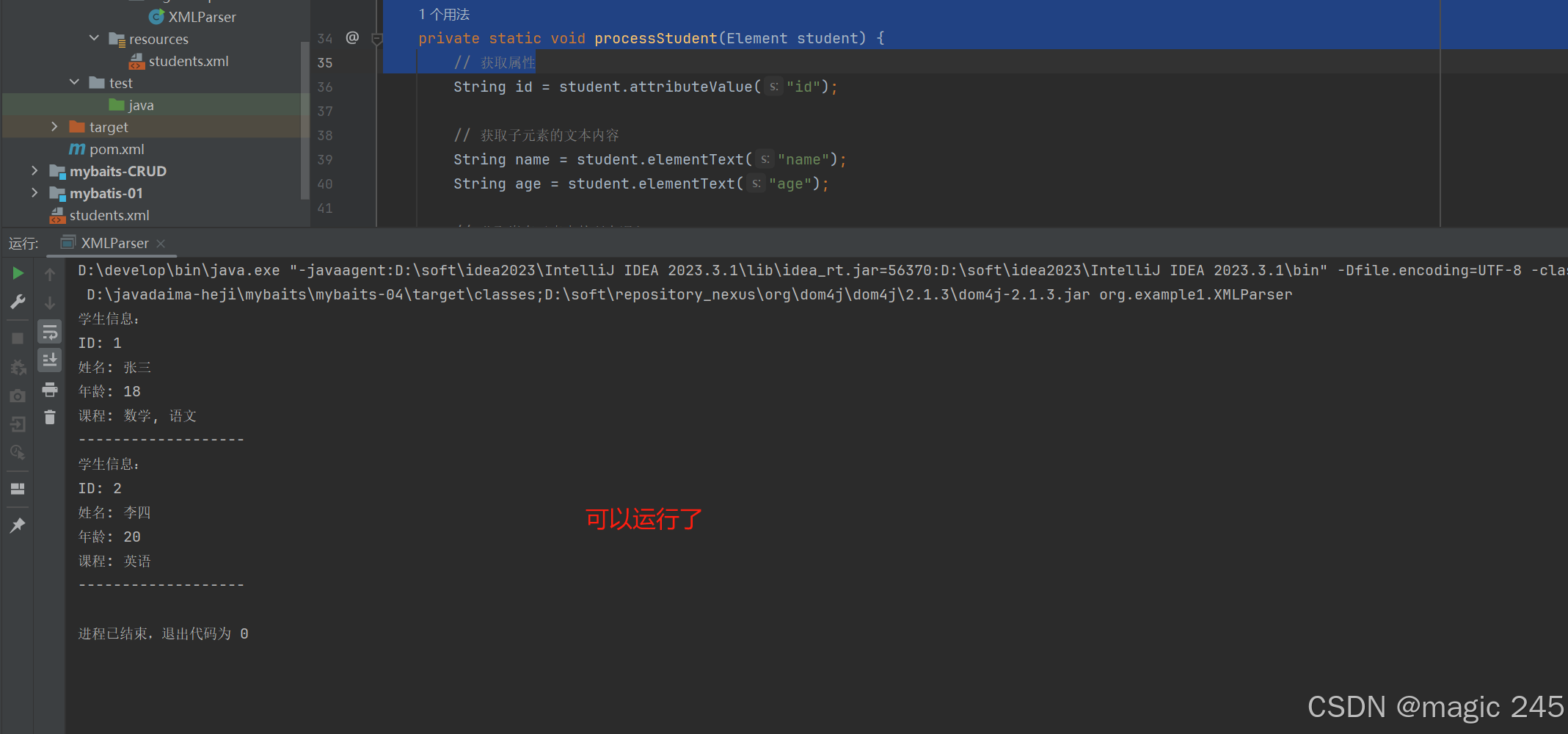
}一样可以运行
五、关键方法说明
| 方法 | 描述 | 示例 |
|---|---|---|
reader.read(file) |
加载 XML 文件为 Document |
Document doc = reader.read("students.xml"); |
getRootElement() |
获取根元素 | Element root = doc.getRootElement(); |
elements(String name) |
获取子元素列表 | root.elements("student") |
attributeValue(String name) |
获取属性值 | student.attributeValue("id") |
elementText(String name) |
获取子元素文本 | student.elementText("name") |
1.getRootElement() 方法
语法
Element getRootElement();此方法属于 Document 类,其作用是获取 XML 文档的根元素,返回类型为 Element。
运行示例
假设存在一个名为 students.xml 的 XML 文件,内容如下:
下面的方法示例也使用该xml文件
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student id="1">
<name>Alice</name>
<age>20</age>
</student>
<student id="2">
<name>Bob</name>
<age>21</age>
</student>
</students>下面是使用 getRootElement() 方法获取根元素的 Java 代码:
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
public class GetRootElementExample {
public static void main(String[] args) {
try {
// 创建 SAXReader 对象
SAXReader reader = new SAXReader();
// 读取 XML 文件,得到 Document 对象
Document document = reader.read(new File("students.xml"));
// 获取根元素
Element root = document.getRootElement();
System.out.println("根元素名称: " + root.getName());
} catch (DocumentException e) {
e.printStackTrace();
}
}
}运行结果:

⑴常见错误场景:
如果 XML 文件结构为:
<class>
<students>
<student>...</student>
</students>
</class>此时根元素是class,要获取students节点需要:
Element studentsNode = root.element("students");⑵Element类型
在 dom4j 中,Element是核心类之一,用于表示 XML 文档中的元素节点(标签)。以下是关于Element类型的详细说明:
①. Element 的作用
- 代表 XML 元素:每个 XML 标签(如
<students>、<student>)都对应一个Element对象。- 提供节点操作方法:可通过
Element访问子元素、属性、文本内容等。- 层级关系:通过父元素的
elements()方法获取子元素列表,形成树状结构。
2. elements(String name) 方法:获取子元素列表
语法
List<Element> elements(String name);该方法属于 Element 类,用于获取指定名称的子元素列表,返回类型为 List<Element>。
运行示例
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
public class ElementsExample {
public static void main(String[] args) {
try {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("students.xml"));
Element root = document.getRootElement();
// 获取名为 "student" 的子元素列表
List<Element> students = root.elements("student");
for (Element student : students) {
System.out.println("学生元素: " + student.getName());
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}运行结果
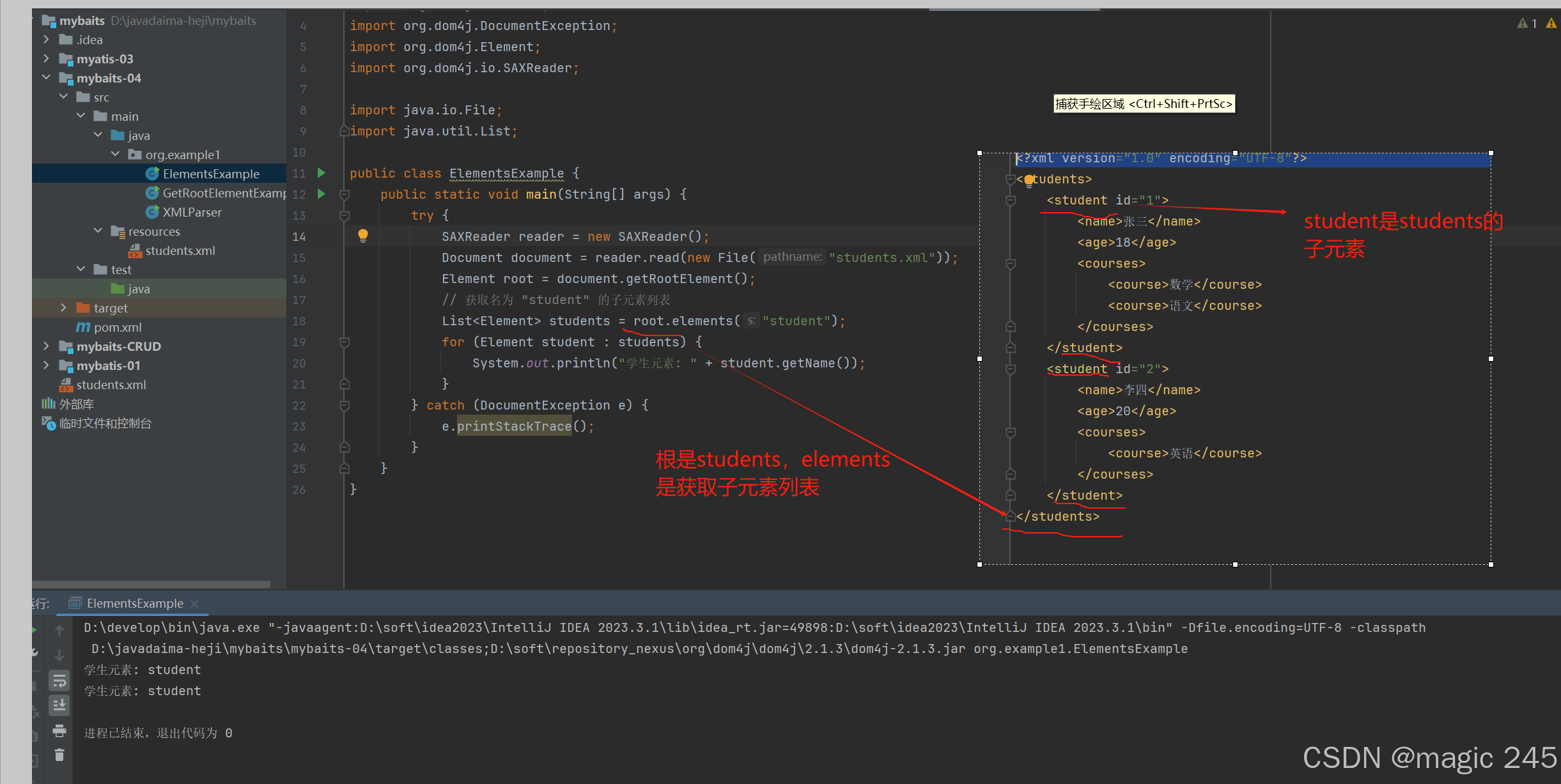
在这段代码中,先获取 XML 文档的根元素,然后使用 elements("student") 方法获取所有名为 student 的子元素列表,最后遍历该列表并打印每个子元素的名称。
3.attributeValue(String name) 方法
语法
String attributeValue(String name);此方法属于 Element 类,用于获取指定名称的属性值,返回类型为 String。
运行示例
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
public class AttributeValueExample {
public static void main(String[] args) {
try {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("students.xml"));
Element root = document.getRootElement();
List<Element> students = root.elements("student");
for (Element student : students) {
// 获取 "id" 属性值
String id = student.attributeValue("id");
System.out.println("学生 ID: " + id);
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
在上述代码中,先获取所有 student 子元素列表,然后遍历该列表,使用 attributeValue("id") 方法获取每个 student 元素的 id 属性值并打印。
4. elementText(String name) 方法
语法
String elementText(String name);该方法属于 Element 类,用于获取指定名称子元素的文本内容,返回类型为 String。
运行示例
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
public class ElementTextExample {
public static void main(String[] args) {
try {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("students.xml"));
Element root = document.getRootElement();
List<Element> students = root.elements("student");
for (Element student : students) {
// 获取 "name" 子元素的文本内容
String name = student.elementText("name");
System.out.println("学生姓名: " + name);
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
在这段代码中,先获取所有 student 子元素列表,然后遍历该列表,使用 elementText("name") 方法获取每个 student 元素下 name 子元素的文本内容并打印。