引领东方语言识别新风潮!Dolphin语音模型开创自动语音识别(ASR)新时代
在全球语音识别技术领域,随着人工智能的飞速发展,许多技术巨头纷纷推出了多语言支持的语音识别系统,如Whisper等。然而,尽管这些模型在西方语言上的表现卓越,但在东方语言的识别上却常常力不从心,特别是在复杂的汉语方言、少数民族语言等领域,识别效果依然存在不小的差距。为了解决这一难题,海天瑞声与清华大学联合推出了全新的
Dolphin语音识别模型
,这一突破性的技术不仅支持40种东方语言,还能够精准识别22种中文方言,成功弥补了现有模型在东方语言处理上的不足。

Dolphin:东方语言的“听写大师”
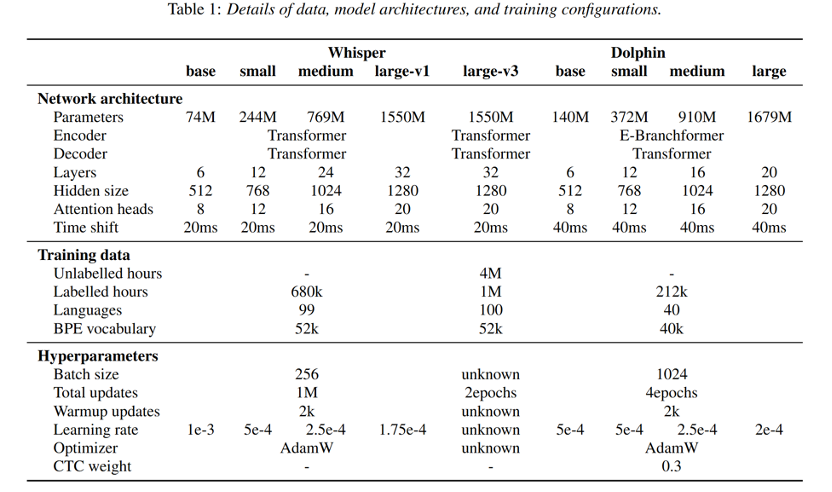
Dolphin语音识别模型是专门为东方语言设计的一款大规模语音识别系统。它借鉴了Whisper和OWSM(开放Whisper风格语音模型)等技术的先进架构,并进行了针对性的优化,尤其在东方语言的识别准确率上进行了深度调优。
核心亮点
支持多达40种东方语言
,包括中文、日语、泰语、俄语等,并且精准覆盖22种中文方言,如粤语、闽南语、上海话等,甚至可以辨识不同地区的方言差异。轻量化设计
:Dolphin的base版仅有140M参数,相较于Whisper大型模型,Dolphin模型体积更小,但在识别效果上却能遥遥领先,尤其是在字错率(WER)上表现出色。高效的训练数据
:模型使用了超过212,000小时的训练数据,包括海天瑞声的高质量专有数据和多个开源数据集,确保了广泛的语言覆盖和精准的识别效果。
Dolphin的技术架构:创新与高效并存
Dolphin语音识别模型的技术架构是其能够在多语言和多方言识别中脱颖而出的核心之一。与现有的主流语音识别模型相比,Dolphin采用了一些创新性的设计和架构优化,专门针对东方语言的特点进行了深度优化。其技术架构基于CTC-Attention联合架构
,结合了E-Branchformer编码器
和Transformer解码器
的优势,这一设计大大提升了模型的识别精度和效率。
1. CTC-Attention联合架构
Dolphin采用的CTC-Attention联合架构
结合了CTC(Connectionist Temporal Classification)和Attention机制
的优点。这种架构有助于克服传统ASR模型在长语音序列中捕捉上下文信息的困难。
CTC
:CTC是一种用于序列建模的技术,它可以在没有对齐信息的情况下处理长语音序列。CTC通过最大化正确输出的概率来解决语音信号的时间对齐问题,在语音识别中得到了广泛应用。通过CTC,模型能够学习到输入语音和文本之间的时间对齐关系,尤其在长语音片段的处理上表现优异。Attention机制
:相比CTC,Attention机制
能够通过加权求和的方式,在每个时间步关注输入序列中的相关部分,这使得它能够处理长序列中的依赖关系,且能够更好地捕捉上下文信息。在Dolphin中,Attention机制被用来优化文本生成过程,提高了模型的准确性和输出质量。
这种CTC-Attention联合架构
使得Dolphin不仅能够对长语音进行高效的序列建模,还能捕捉到语音中的细微变化,从而提升对复杂语音和多方言的识别能力。
2. E-Branchformer编码器
Dolphin的编码器采用了E-Branchformer
,这是一种基于Transformer的创新架构,具备分支结构
的设计,能够更高效地捕捉语音信号中的局部和全局依赖关系。
分支结构
:E-Branchformer通过并行分支的方式,同时处理语音的局部特征和全局特征。这种设计有助于更全面地理解语音信号,尤其是在语音包含复杂的音素变化时,能够提供更加丰富的特征表示。Transformer优势
:与传统的卷积神经网络(CNN)和循环神经网络(RNN)相比,Transformer架构能够更好地处理长距离的依赖关系,尤其在处理复杂的语言结构和方言时,能够显著提高语音识别的准确性。
3. Transformer解码器
Dolphin的Transformer解码器
延续了Transformer架构在序列到序列任务中的优异表现。通过自注意力机制,Transformer解码器能够在生成文本时充分利用输入语音的上下文信息,确保输出文本的流畅性和准确性。
序列到序列任务
:在ASR任务中,输入的语音序列需要被转换为对应的文本序列。Transformer解码器的自注意力机制可以帮助模型更加精确地生成文本,特别是在面对带有多种方言、口音或者语速较快的语音时,依然能够保持高准确度。并行处理
:Transformer解码器的并行处理能力大大提高了模型的推理速度,尤其在面对大规模多语言数据时,能够保持较低的延迟,提高了实时语音识别的能力。
4. 4倍下采样层
Dolphin采用了4倍下采样层
,这一创新设计极大地提高了计算效率。下采样层通过减少输入特征的序列长度来加速计算过程,同时保持关键语音信息的完整性。
提高训练速度
:下采样层使得模型能够以较低的计算成本进行训练,同时在不丧失语音信息的前提下提高了训练速度。这一设计对于训练大规模的多语言模型尤为重要,尤其是在资源有限的情况下,能够显著缩短训练时间。无损信息保留
:尽管进行了下采样,Dolphin依然能够保留语音信号中的关键信息,确保语音识别的准确性不受影响。
5. 两级语言标签系统
Dolphin在多语言、多方言的处理上,采用了创新的两级语言标签系统
。这一系统通过引入语言标记
和地区标记
,有效解决了多种语言和方言之间的细微差异,尤其是在处理复杂的中文方言时。
语言标记
:通过对每种语言的标记(如:表示中文,表示日语等),Dolphin能够更好地理解语音的基本语言结构。地区标记
:每种语言还附带地区标记(如:表示中国,表示日本等),这一设计能够让模型识别出不同地区方言的细微差别,进一步提高方言识别的准确性。例如,粤语和普通话在音素上有很大区别,Dolphin能够通过地区标签,精准捕捉这些差异。
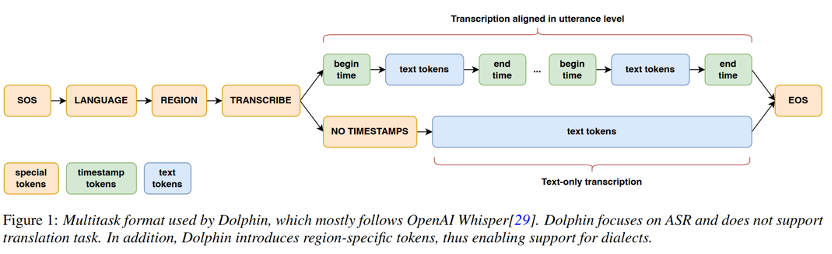
6. 多任务格式
Dolphin在训练时采用了多任务格式
,这使得模型不仅可以进行语音识别(ASR),还可以同时进行其他语音相关任务,如语言识别、语音活动检测等。这一设计提高了模型的多功能性,使其能够在多种应用场景下表现出色。
- 任务特定令牌
:与Whisper的设计类似,Dolphin使用任务特定的令牌来指示不同的任务类型(如转录、语言识别等)。这种灵活的任务管理方式,使得Dolphin能够同时处理多种语音任务,且保证每个任务的高效性。
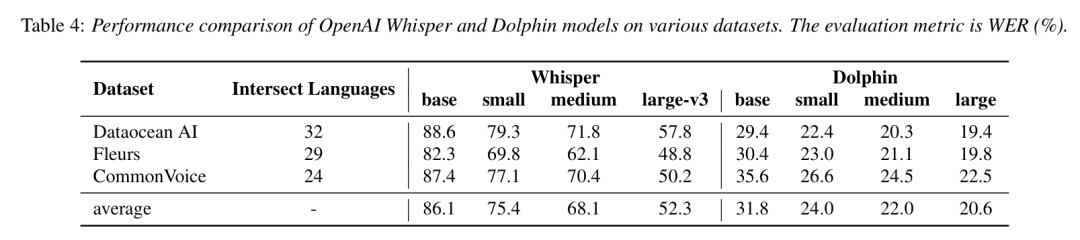
Dolphin的卓越表现:跨越语言障碍
Dolphin的性能在多个测试集上都得到了验证,并且在许多方面超越了现有的主流模型,特别是在东方语言的识别准确率
上,Dolphin展示了强大的竞争力。
例如,在Dataocean AI
的测试集中,Dolphin base版的字错率(WER)为29.4%,远低于Whisper large-v3的57.8%。而在一些具有挑战性的东方语言测试中,如中文
、日语
、泰语
等,Dolphin模型都展现了明显的优势,特别是在多种中文方言
的识别上,Dolphin的识别效果堪称业界领先。
此外,Dolphin在多个应用场景中的表现也同样令人瞩目:
跨境商务
:可以实时转录东南亚多语种的商务会议,提供高效的语音转文本服务。文化保护
:对一些濒危方言(如闽东语)的数字化存档起到了积极作用,帮助保护和传承文化遗产。智能客服
:能够精准识别带口音的普通话,提高智能客服系统的响应准确性和用户体验。
下载链接
OpenCSG社区:
https://opencsg.com/models/AIWizards/dolphin-base
https://opencsg.com/models/AIWizards/dolphin-small
HF社区:
https://huggingface.co/DataoceanAI