线性结构(Linear Structures)
线性结构的核心定义
- 一对一的有序关系
线性结构中的元素按逻辑顺序排列,每个元素(除首尾外)仅有唯一的前驱和后继,形成类似“排队”的链式关系 - 有限性和连续性
线性表是有限序列,逻辑顺序可通过物理连续存储(数组)或逻辑指针连接(链表)实现,二者在性能上互补
线性结构的几种类型
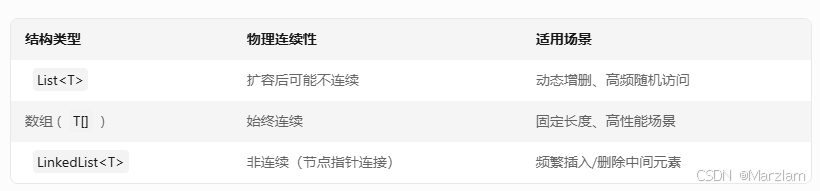
数组 (Array)
固定长度、内存连续存储,支持O(1)随机访问,但增删效率低(需移动元素)
示例:int[] array = new int[5];
使用场景:
已知固定长度且频繁随机访问的场景
高性能数值计算(如数学矩阵)
List
动态扩容的泛型集合(默认容量翻倍)底层基于数组实现,适用于频繁修改数据的场景
索引访问时间复杂度:O(1)
尾部插入平均时间复杂度:O(1)(扩容时O(n))
优化技巧:预分配容量(new List(1000)避免频繁扩容
list.Add(item); // 尾部插入
list.Insert(index, item); // 中间插入(慎用,可能导致O(n)操作)
List扩容机制的核心逻辑
- 触发条件与扩容策略
当 List 的元素数量(Count)超过当前容量(Capacity)时触发扩容。
默认初始容量为 0,首次添加元素时扩容至 4,后续每次扩容容量翻倍(如 4→8→16)。
扩容时会创建新数组(容量为原数组的 2 倍),并将旧数组元素复制到新数组中,旧数组被释放。
内存分配流程
List<int> list = new List<int>(); // 初始容量0
list.Add(1); // 触发首次扩容,容量4,分配连续内存块A
list.Add(5); // 触发第二次扩容,容量8,分配新内存块B,复制A内容后释放A
每次扩容后,新数组在托管堆中申请新的连续内存块,但新旧数组的物理地址可能完全无关。
- 内存“不连续”的深层原因
- 物理连续性的局限
单次扩容周期内:新数组在物理上是连续的(如容量8的数组占用一块连续内存),但多次扩容后,新旧数组可能分布在托管堆的不同区域。
托管堆的动态分配:托管堆内存分配是动态的,新数组可能无法在旧数组释放后的原地址扩展(旧内存块可能已被其他对象占用),导致新旧物理地址分散。不过这没关系扩容后关注的是新的空间,至于新老空间是否连续物理地址不重要,老的空间不需要了已经,重要关注的新的物理地址内存是不是连续的,为什么新的内存会不连续呢就是下面碎片化问题 - 内存碎片化问题
旧数组释放后,其内存块会被标记为空闲,可能被后续小对象占用,形成“空洞”。
多次扩容后,新数组需在堆中寻找足够大的连续空间,若存在碎片,可能被迫分配到非连续区域。 - 逻辑连续性的保证
尽管物理内存可能分散,List 通过数组索引模拟逻辑连续性,开发者通过 list[i] 访问元素时无需感知底层物理变化。
迭代器(如 foreach)和索引器均基于逻辑顺序操作,与物理内存分布无关
- 物理连续性的局限
LinkedList
实现:System.Collections.Generic.LinkedList
非连续内存存储,节点通过指针连接,插入/删除效率O(1),但随机访问效率O(n)
适用场景:LRU缓存、实时数据处理
缺点:
内存开销大(每个节点存储前后指针)
不支持索引访问
LinkedList<string> linkedList = new LinkedList<string>();
linkedList.AddLast("A");
linkedList.AddFirst("B"); // 仅修改头尾指针
链表(LinkedList)的核心概念
- 基本结构
链表是由节点(Node) 构成的线性数据结构,每个节点包含两部分:
数据域:存储实际数据(如整数、对象等)。
指针域:存储指向下一个节点的引用(Next指针)。在双向链表中,还包含指向前驱节点的Prev指针 - 物理存储特性
链表的节点在内存中非连续分布,通过指针动态链接。这与数组(如List)的连续内存块形成鲜明对比。
优势:动态调整大小,无需预分配固定内存;劣势:随机访问需遍历,时间复杂度为O(n)
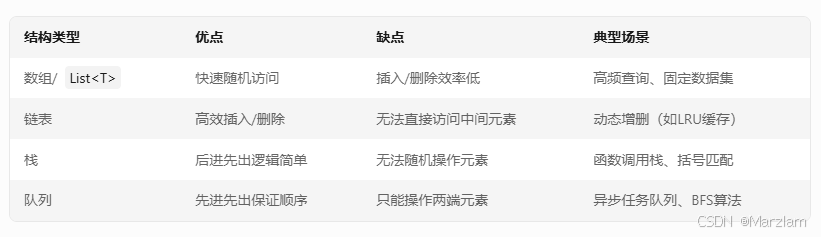
栈(Stack)与队列(Queue):
栈遵循LIFO(后进先出)原则(如递归调用),队列遵循FIFO(先进先出)原则(如任务调度\消息队列)
示例:Stack stack = new Stack();
对比线性结构
键值对结构(Key-Value Structures)
特点:通过键快速检索值,适用于缓存、配置管理等场景
哈希表 Hashtable
哈希表的核心原理
- 基本结构
底层实现:基于数组(Entry[]),每个数组元素称为一个桶(Bucket)。
键的哈希化:
对键(Key)调用GetHashCode()生成哈希码(int类型)。
通过哈希函数(如取模运算)将哈希码映射到数组索引。
冲突解决:
开放寻址法 双重散列(C# Dictionary采用此方法):冲突时探测下一个空桶。
链表法:每个桶存储链表或树结构
例子:图书馆的书架和编号系统
假设你是一家图书馆的管理员,图书馆有100个书架(每个书架有一个编号,比如0到99)。你需要快速找到任何一本书的位置。
哈希函数:生成书的“编号规则”
问题:每本书有唯一书名(Key),如何快速知道它放在哪个书架?
解决方案:设计一个“编号规则”(哈希函数)。
例如:将书名的每个字母转换成数字(A=1, B=2…),相加后取余数。
比如书名《C#入门》:
C=3, #=特殊符号(假设为0),入=20, 门=5 → 3+0+20+5=28
书架编号 = 28 % 100(总书架数) → 28号书架存储书:按规则放入书架
将《C#入门》放在28号书架。
接着处理另一本书《算法导论》:
假设计算后得到书架编号也是28(哈希冲突)!
解决冲突:
方法1(链表法):在28号书架旁边加一个小篮子,两本书都放在这里。
方法2(开放寻址法):将《算法导论》放到下一个空书架(比如29号)。找书:快速定位
当有人借《C#入门》时:
用同样的规则计算书名 → 得到28号书架。
如果28号书架只有这本书,直接取走。
如果有冲突(比如旁边有小篮子),再逐个对比书名(Equals()方法)确认。书架不够时:扩容
如果图书馆的书增加到超过70本(假设负载因子0.7),书架可能不够用。
扩容操作:
新建200个书架(数量翻倍)。
将所有书重新计算编号(比如原28号书架的书可能分散到28号和128号)

Dictionary<K, T>
- 实现:System.Collections.Generic.Dictionary<TKey, TValue>
底层:哈希表(开放寻址法)
特性:
平均插入/查找时间复杂度:O(1)
哈希冲突处理:开放寻址法
关键点:
Key需实现GetHashCode()和Equals()
避免频繁扩容(初始化时指定预估容量)
使用场景:
快速查找/去重操作(如缓存系统)
SortedDictionary<TKey, TValue>
- 实现:红黑树(自平衡二叉搜索树)
特性:
按键有序遍历
插入/删除/查找时间复杂度:O(log n)
适用场景:需要有序键值对的场景(如排行榜)
树形结构(Tree Structures)
特点:数据元素存在一对多关系,适用于层级数据组织
二叉树(Binary Tree)/完全二叉树/红黑树
核心概念与生活举例
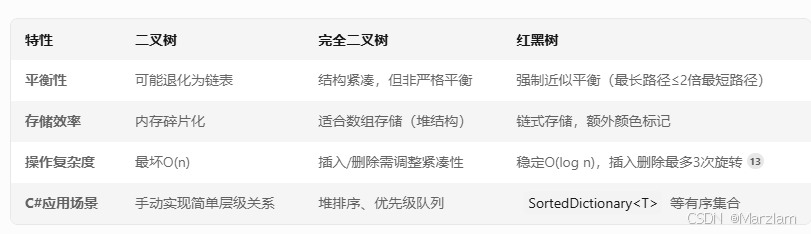
- 二叉树(Binary Tree)
定义:每个节点最多有2个子节点(左/右),没有强制平衡规则。在C#中可通过TreeNode类手动实现。
生活案例:
公司组织架构
例如CEO(根节点)下设技术部(左子节点)和市场部(右子节点),每个部门再细分团队。这种层级结构天然形成二叉树,但若管理层级拉长(如单边发展),会退化成“链表”,效率低下。 - 完全二叉树(Complete Binary Tree)
定义:除最后一层外,其他层节点必须填满,且最后一层节点从左到右紧密排列。
生活案例:
超市货架摆放
货架每层摆满商品后才开新层,且新商品必须从左侧开始填充。这种结构类似完全二叉树,保证存储紧凑,方便快速盘点(如堆排序中的数组存储)。 - 红黑树(Red-Black Tree)
定义:一种自平衡二叉查找树,通过颜色规则(根黑、红不连续、黑高平衡)和旋转操作维护近似平衡。
生活案例:
智能交通系统
红绿灯(红色节点)和普通路口(黑色节点)交替分布,确保主干道(最长路径)和支路(最短路径)车流量差异不超过2倍,避免拥堵
红黑树像一套智能调控系统:在普通道路(二叉树)基础上,通过红绿灯规则(颜色约束)和立交桥(旋转操作),让数据流动高效稳定
- 性能优化路径
普通二叉树 → 完全二叉树:通过紧凑布局提升存储效率,适合静态数据。
完全二叉树 → 红黑树:引入动态平衡机制,解决插入/删除导致的性能退化问题
堆(Heap)
- 堆的核心概念与特性
堆是一种完全二叉树结构,其核心特性是父节点与子节点的值满足特定顺序。在C#中,堆通常通过数组实现,并分为两类:
大根堆:父节点的值 ≥ 子节点值,根节点为最大值。
小根堆:父节点的值 ≤ 子节点值,根节点为最小值。 - 核心规则:
完全二叉树性质:所有层级除最后一层外必须填满,最后一层从左到右填充。
数组存储:节点索引满足 parentIndex = (childIndex - 1) / 2,左子节点为 2 * parentIndex + 1,右子节点为 2 * parentIndex + 2 - 堆的应用场景与生活案例
优先级队列
案例:医院急诊科分诊系统
患者按病情严重程度(优先级)排队,最危急的患者优先就诊。使用大根堆时,病情最重的患者(最大值)始终在堆顶。
C#实现:PriorityQueue 底层基于堆结构,适用于任务调度、实时数据处理等场景。
堆排序
案例:快递分拣中心
包裹按重量从小到大排序。通过构建小根堆,每次取出最轻包裹(根节点),直到堆为空
动态数据流处理
案例:股票价格实时监控
系统需要快速获取当前最高价(大根堆)或最低价(小根堆),堆的O(1)时间复杂度获取极值特性非常适合此场景
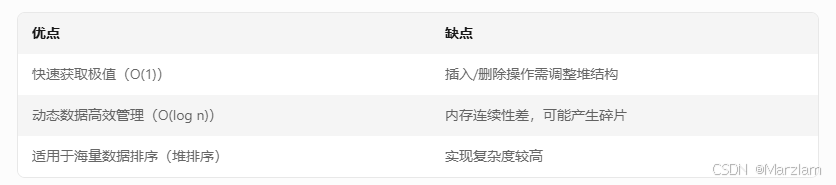
堆结构通过完全二叉树和数组的巧妙结合,实现了高效的极值管理和动态排序
集合结构
特点:元素唯一,支持集合运算(交集、并集)
HashSet
- 实现:基于哈希表
特性:
唯一元素,快速判断存在性
集合操作(并集、交集、差集)
时间复杂度:
添加/查找:平均O(1),最坏O(n)
SortedSet
- 实现:红黑树
特性:
有序唯一集合
查找/插入/删除:O(log n)
应用场景:需要有序且快速范围查询的场景