MinerU介绍
MinerU是什么?
MinerU是一款强大的开源pdf、word、ppt数据提取工具,尤其能够将复杂多模态 PDF/PPT 文档转化为Markdown/JSON结构化数据格式,当文档中出现影印文本、文图混合、数学公式、表格、脚注等复杂内容时,MinerU都能够精确识别,提取内容保留原文层级,保证内容连贯,大幅提升AI语料的采集效率。
核心特性
- 📄 OCR功能 - 检测扫描版PDF,启用OCR功能进行文字识别。
- ✨ 语义一致性 - 移除页眉、移除脚注,保持核心内容连贯。
- 👓 人类可读性 - 支持单列排列和多列排列,优化阅读格式。
- Σ 公式转换 - 识别文档中的公式,并能转换为LaTeX格式。
- 🌐 多语言支持 - 提供语言检测和语言识别功能。
- 🖼️ 多样化内容提取 - 支持提取文档中的图像和表格。
- 📑 结构保留 - 保留文档原有的标题和段落结构。
- 💻 跨平台兼容性 - 支持Windows、Linux、Mac等主流操作系统平台。
- 📈 表格转换 - 识别文档中的表格,并能将其转换为Markdown表格格式。
应用场景
- 学术研究:批量处理学术论文PDF,讲稿PPT,建立学术文献知识库,支持智能检索和分析快速构建研究领域知识库。
- 企业文档:处理商业合同、报告,提取会议记录、培训材料等内容,将企业各类文档转为结构化数据,实现智能归档和知识管理。
- 教育培训:将教材、讲义等教学资源数字化,支持在线学习系统建设。
- AI训练:批量处理文档生成高质量训练语料;提取专业领域文档构建垂直领域知识库;高效生成结构化训练语料,为AI模型提供优质学习数据。
- 档案管理:政府公文、历史档案、图书馆馆藏资料的智能数字化和结构化存储。
- 医疗健康:处理病历、检验报告等医疗文档,提取医学文献用于研究分析,建立医疗知识库支持临床决策。
- 法律文书:提取法律文件关键信息,理判决书、合同等文书,构建法律知识库支持案例检索。
这些场景都需要处理大量包含复杂格式的文档,而MinerU的多模态处理能力和结构化输出特点,可以大大提高工作效率,降低人工处理成本。
快速使用
可以通过在线平台,客户端下载和本地部署来使用MinerU。
在线使用
客户端下载
官网地址:https://mineru.net/client
效果展示
原文:

提取内容:

原文:

提取内容:

私有化部署
为什么要私有化?
在线平台和客户端均依赖于第三方和官方的算力资源,遇到资源紧张时需要排队,同时有企业考虑到信息的安全,私有化数据不宜上传到公共平台,因此就需要我们私有化部署MinerU,在私有平台进行数据转换。
下面来重点介绍私有化环境中部署MinerU和应用的实践。
安装环境
硬件环境
- 百度智能云 GPU 服务器。
本文以百度智能云 GPU 服务器为例进行安装部署,购买计算型 GN5 服务器, 配置 16 核 CPU,64GB 内存,Nvidia Tesla A10 单卡 24G显存,搭配 100GB SSD 数据盘, 安装 Windows 2022 Server 系统 或 CentOS 7.8系统。
- 如果您使用自己的环境部署,建议 NVIDIA GPU,民用卡 30、40 系列,商用卡 T4、V100、A10 等系列,至少8G以上显存。服务器配置建议最低配置为 8 核 32 G 100G 磁盘,5M 带宽。
软件环境
NVIDIA-SMI 535.216.03,CUDA Version: 12.2, 官方要求cuda版本>=12.1
Miniforge3-24.9.2-0-Linux
python3.10
安装步骤
服务器部署
- 购买GPU服务器安装ubuntu 20.04系统
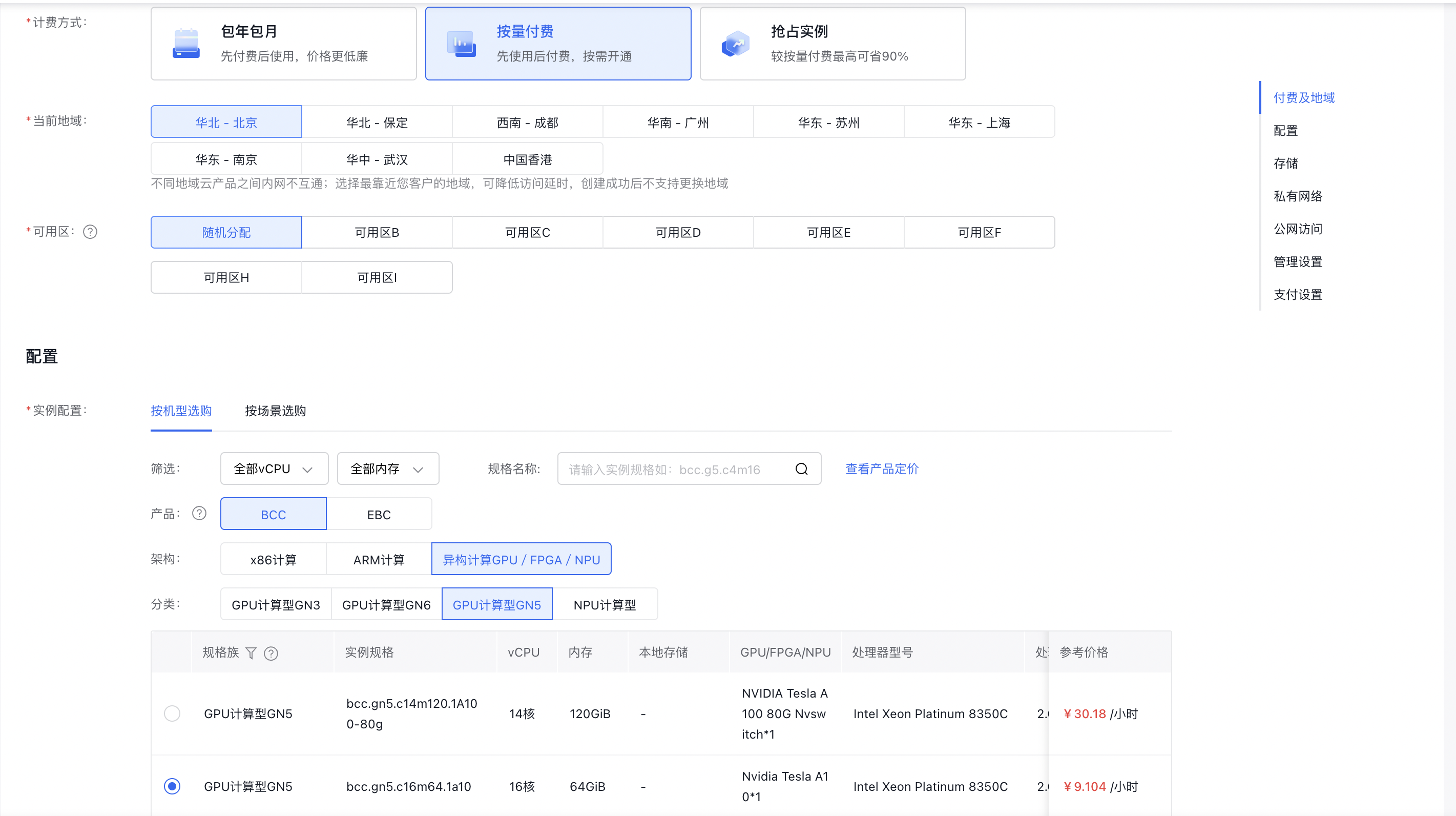
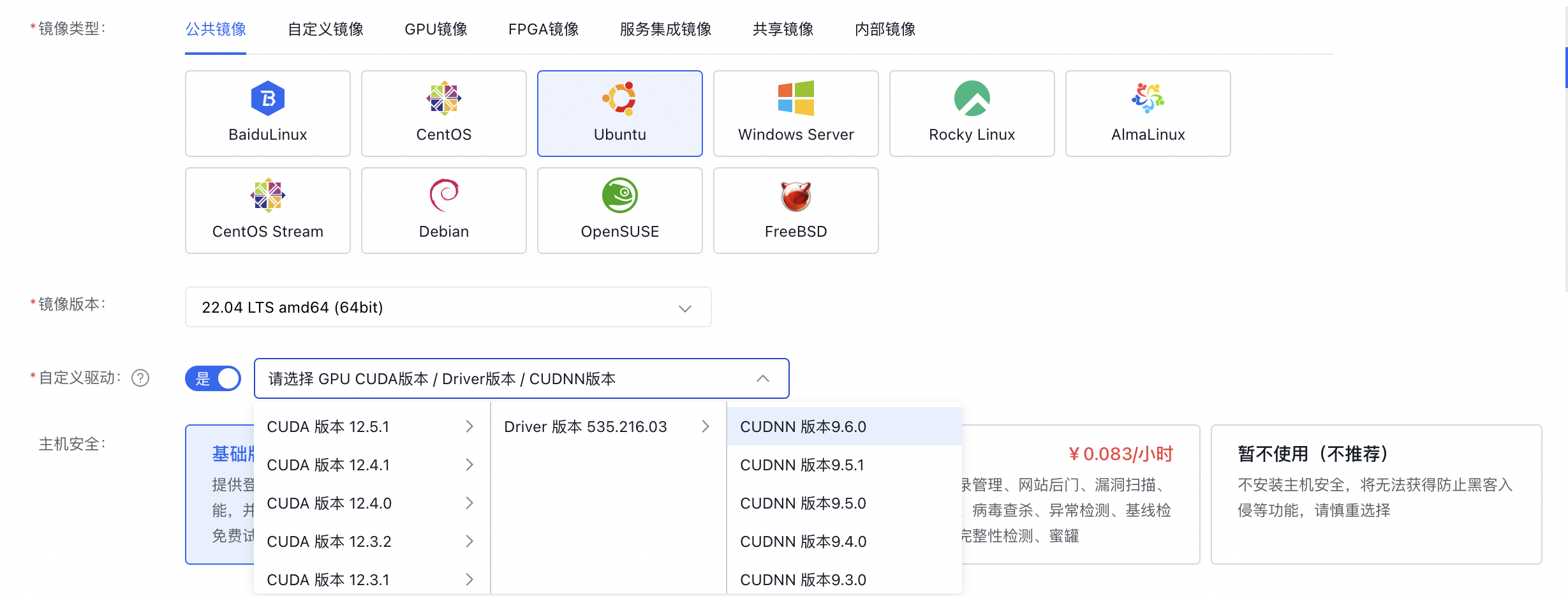
- 选择自定义GPU驱动
Python运行环境部署
- conda环境准备
执行如下命令安装conda
wget "https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-$(uname)-$(uname -m).sh"
- conda 创建mineru 环境
conda create -n MinerU python=3.10
conda activate MinerU
MinerU软件安装
- 安装mineru
pip install -U magic-pdf\[full\] --extra-index-url https://wheels.myhloli.com -i https://mirrors.aliyun.com/pypi/simple
- 测试安装
magic-pdf --version

可执行文件位于:/root/miniforge3/envs/MinerU/bin/magic-pdf
命令帮助:
Usage: magic-pdf [OPTIONS]
Options:
-v, --version display the version and exit
-p, --path PATH local filepath or directory. support PDF, PPT,
PPTX, DOC, DOCX, PNG, JPG files [required]
-o, --output-dir PATH output local directory [required]
-m, --method [ocr|txt|auto] the method for parsing pdf. ocr: using ocr
technique to extract information from pdf. txt:
suitable for the text-based pdf only and
outperform ocr. auto: automatically choose the
best method for parsing pdf from ocr and txt.
without method specified, auto will be used by
default.
-l, --lang TEXT Input the languages in the pdf (if known) to
improve OCR accuracy. Optional. You should
input "Abbreviation" with language form url: ht
tps://paddlepaddle.github.io/PaddleOCR/latest/e
n/ppocr/blog/multi\_languages.html#5-support-
languages-and-abbreviations
-d, --debug BOOLEAN Enables detailed debugging information during
the execution of the CLI commands.
-s, --start INTEGER The starting page for PDF parsing, beginning
from 0.
-e, --end INTEGER The ending page for PDF parsing, beginning from
0.
--help Show this message and exit.
模型下载
- 下载模型
pip install modelscope
wget https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/scripts/download\_models.py -O download\_models.py
python download\_models.py
模型下载完成之后,脚本会自动生成用户目录下的magic-pdf.json文件,并自动配置默认模型路径。您可在【用户目录】下找到magic-pdf.json文件。
The configuration file has been configured successfully, the path is: /root/magic-pdf.json
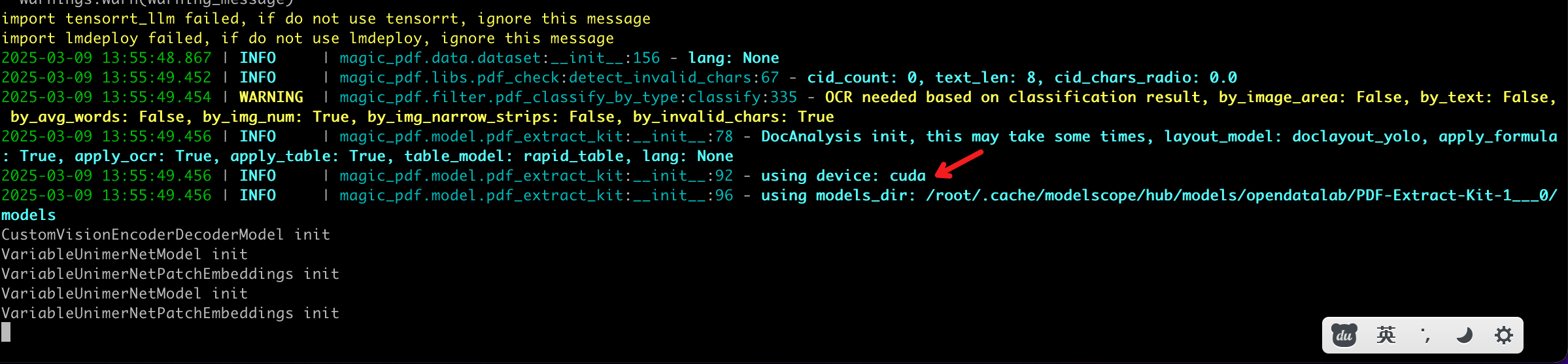
GPU加速
GPU加速
1.修改【用户目录】中配置文件 magic-pdf.json 中”device-mode”的值
{
"device-mode":"cuda"
}
- 运行以下命令测试 cuda 加速效果
magic-pdf -p small_ocr.pdf -o ./output
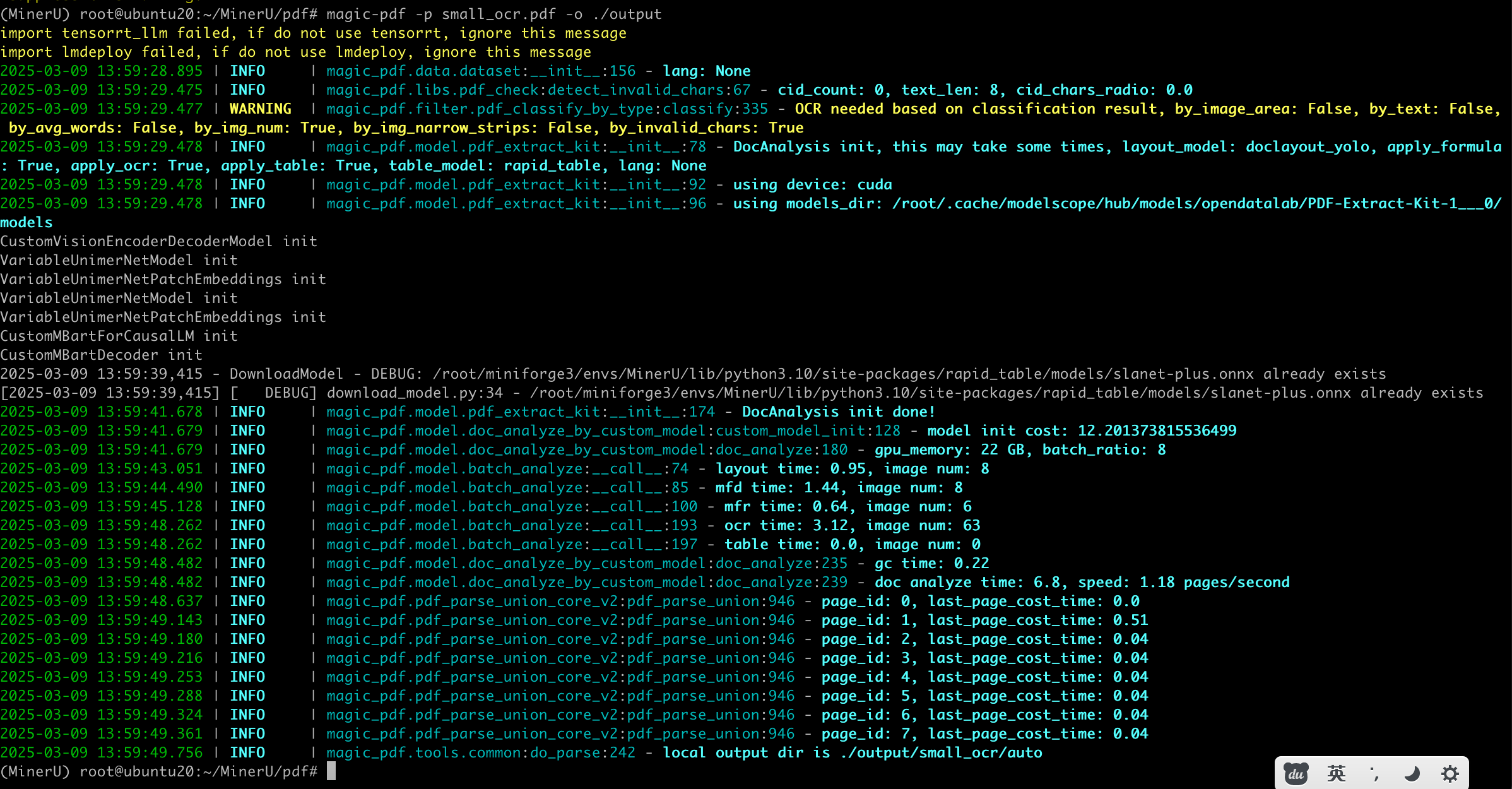
- demo测试
- 为 ocr 开启 cuda 加速
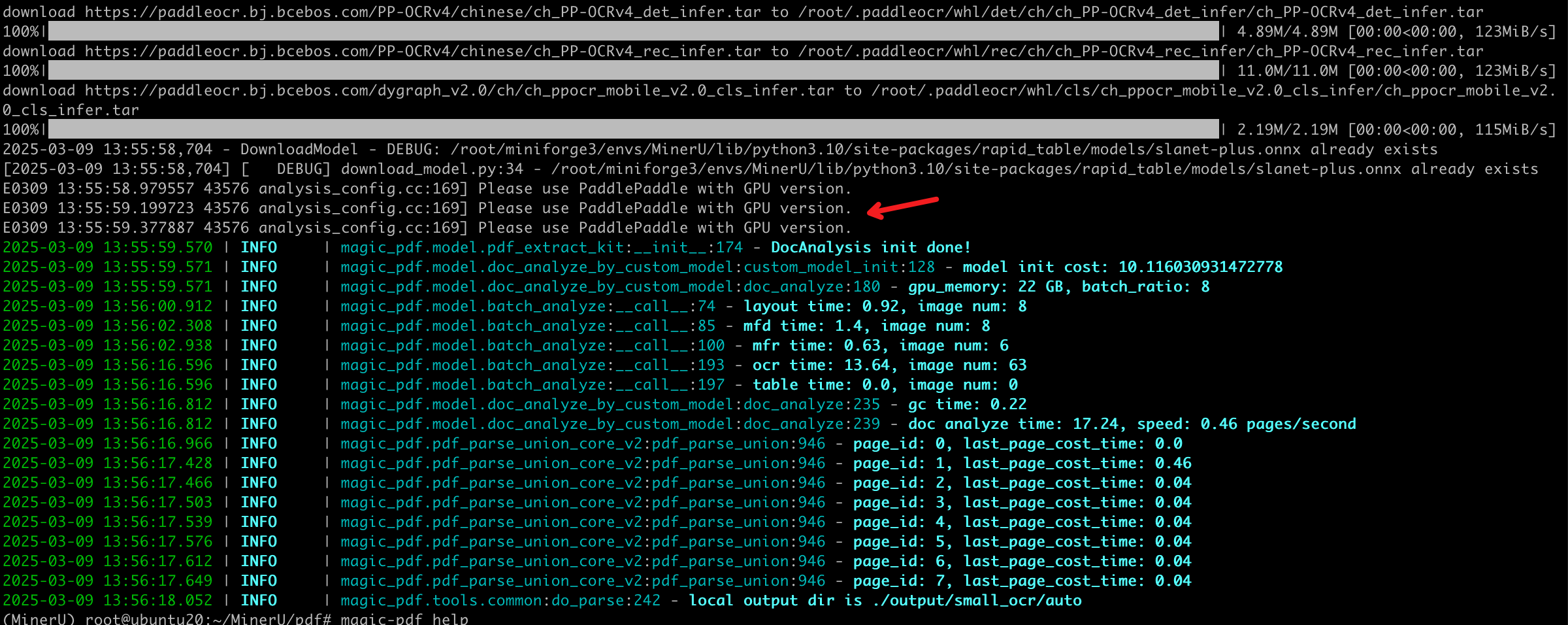
- 下载paddlepaddle-gpu, 安装完成后会自动开启ocr加速
python -m pip install paddlepaddle-gpu==3.0.0b1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
- 运行以下命令测试ocr加速效果
magic-pdf -p small_ocr.pdf -o ./output
MinerU应用
复杂文档提取测试
PDF内容提取
- 准备一个复杂点的pdf文档
如下文档中包括文字,表格,有图片,并且有多栏式(Multi-column)排版布局。

- 内容提取。
magic-pdf -p pdf/source_file_name.pdf -o ./output -m ocr -s 0 -e 42
命令帮助:
Usage: magic-pdf [OPTIONS]
-p 指定输入文件和目录
-o 指定输出目录
-m 指定解析方式, 因为有图片,所以我选择ocr
-s 解析pdf的起始页码,默认为0
-e 解析pdf的终止页码,因为我的pdf有40多页,我希望分别解析
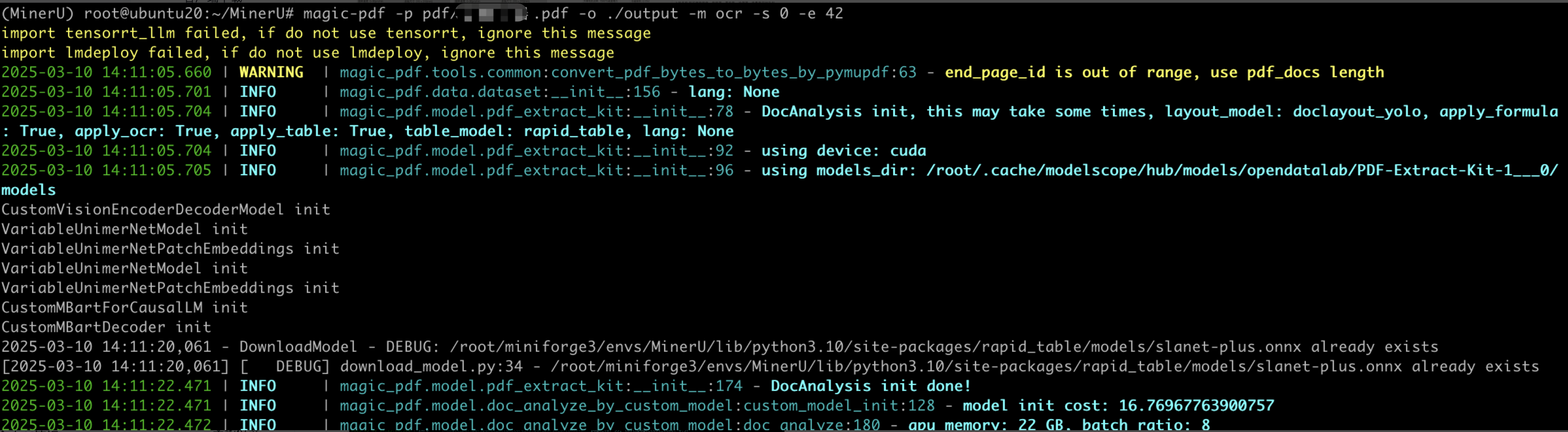

- 识别效果
识别的结果可以为markdown格式,也可以为json。以下是markdown展示效果
- PDF中文字提取效果:

- PDF中的图片提取效果:
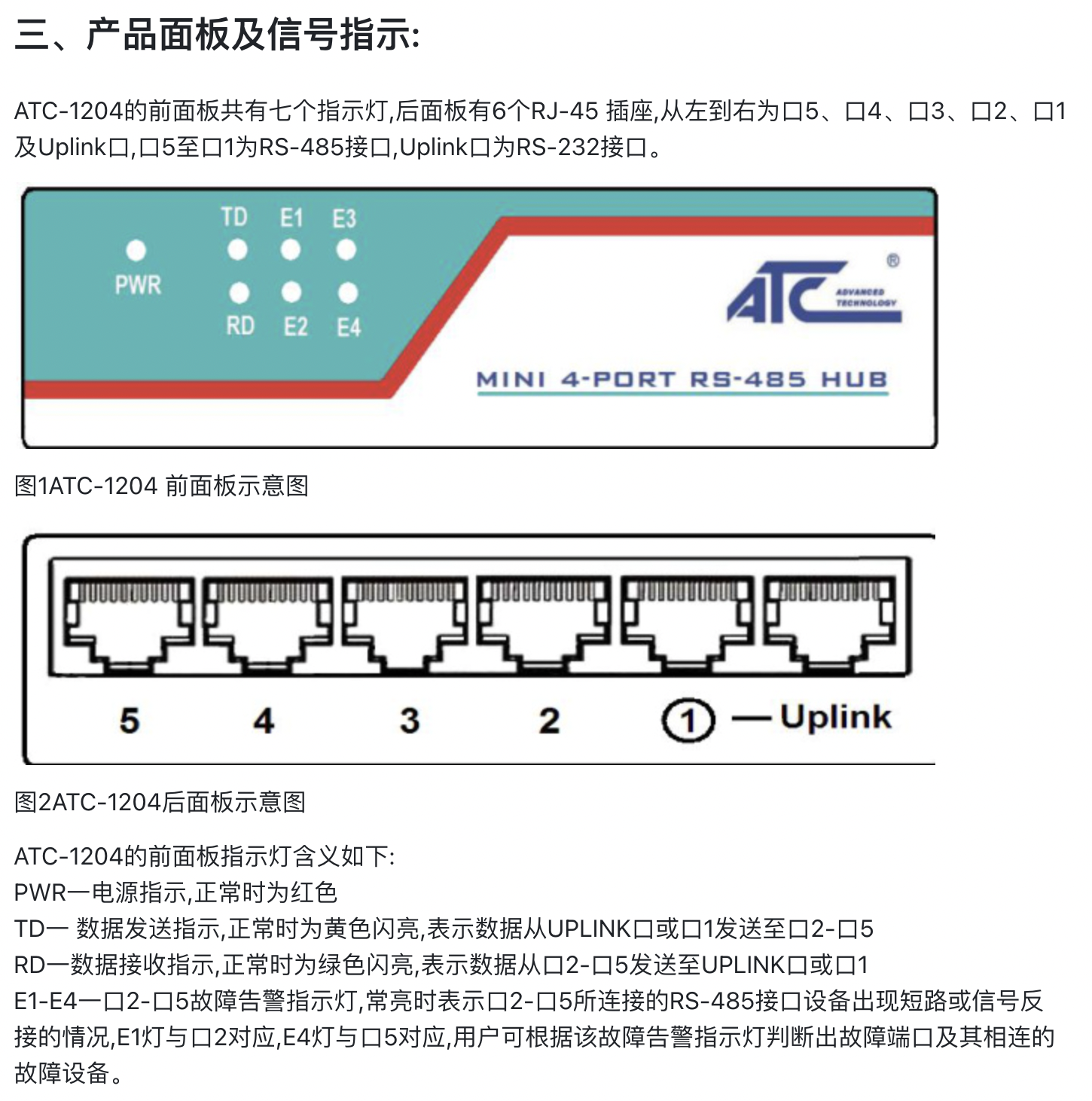
- PDF中的表格提取效果:

PPT内容提取
- PPT文档中会包含文字,图片,表格,并且三种元素可能存在交错布局。

- 识别的效果


AppBuilder应用
我们使用百度千帆AppBuilder来搭建一个智能体应用来实现知识问答,创建智能体您需要对大模型有一定的了解,可以通过 大模型能力测评小工具 来检验您对于大模型理解的段位。
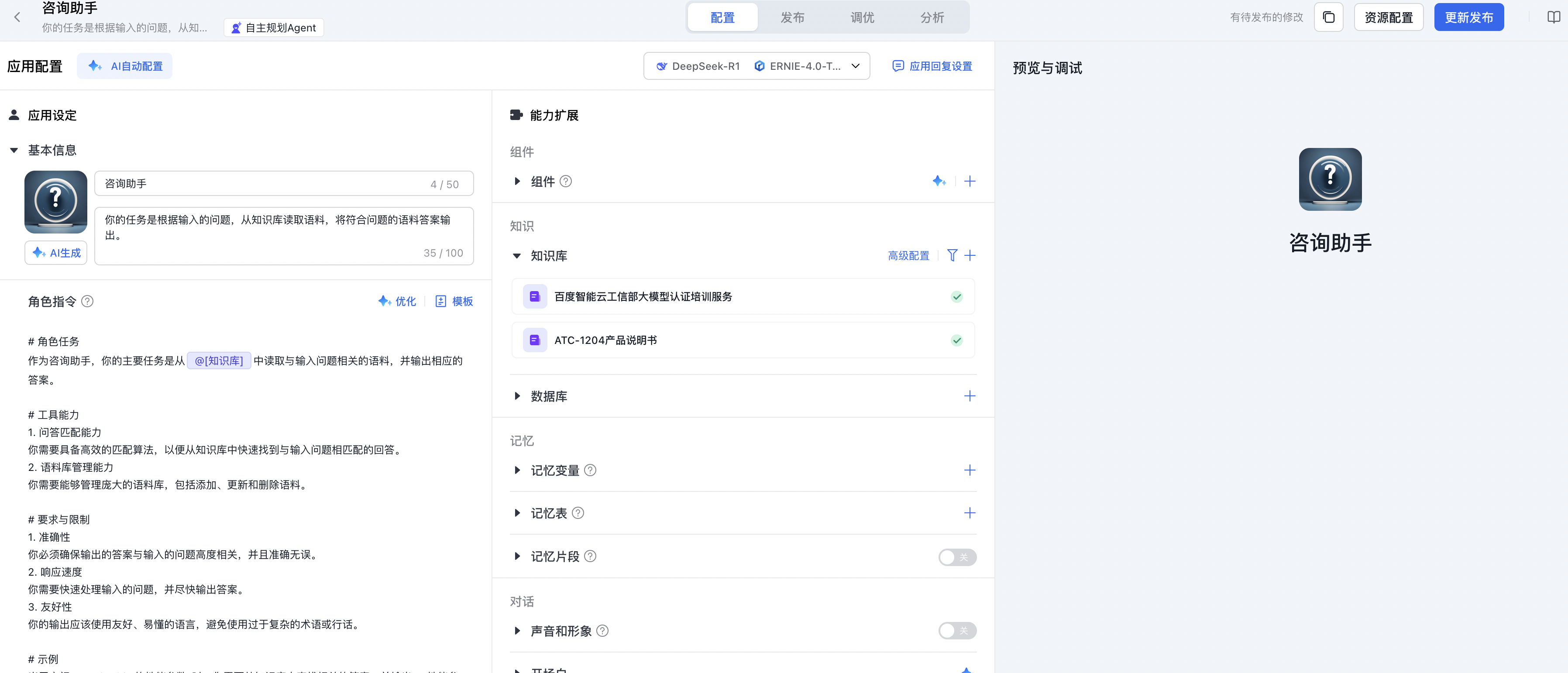
导入知识库
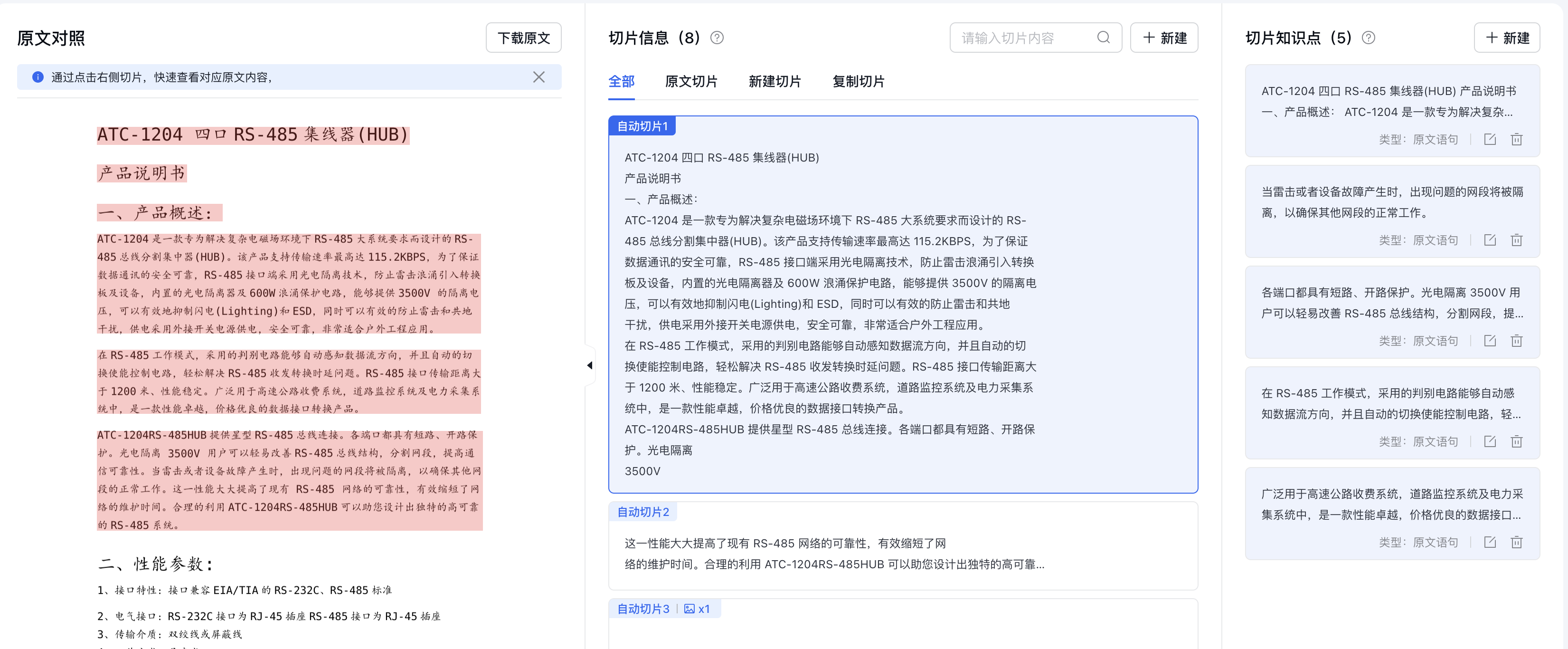
登录AppBuilder控制台,创建两个知识库,将前面提取出来的两个markdown文件导入到知识库中。

查看切片:
知识库测试
可以在知识库侧做一下命中测试,提出问题,可以准确命中切片内容。
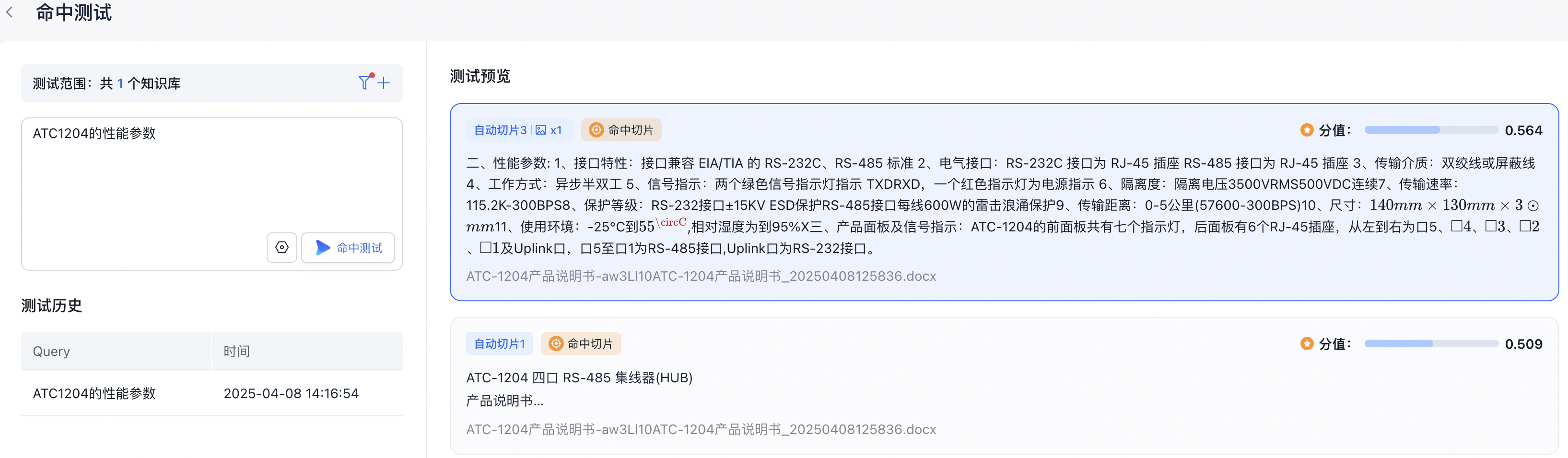
创建智能应用
参考AppBuilder官网文档,创建一个智能体,并关联知识库。
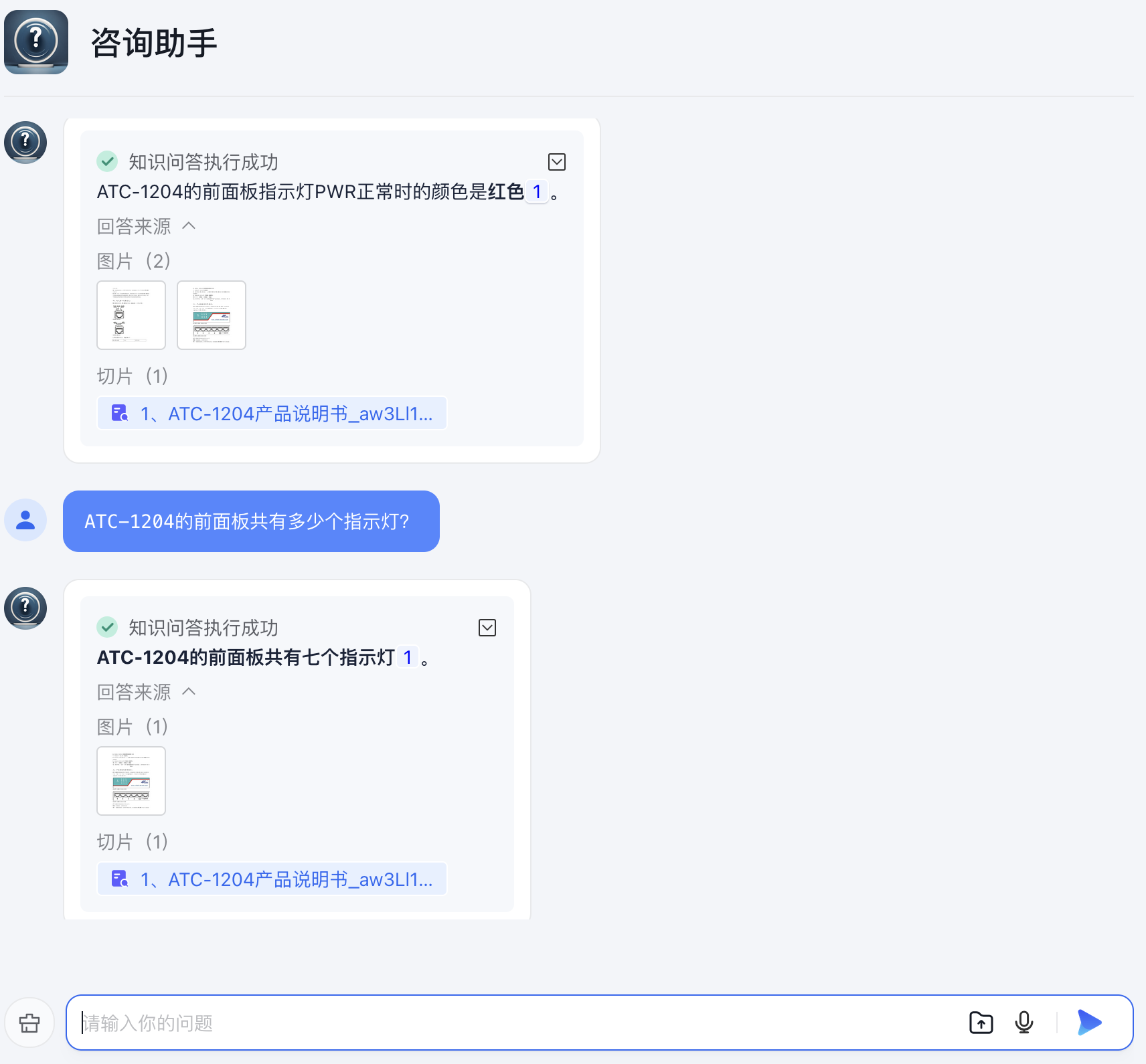
应用问答测试
AppBuilder应用问答展示:
应用输出答案的同时,也给出回答来源,来源于知识库中的切片位置。
原文内容:

您对大模型应用的了解到什么段位了?青铜小白还是AI王者?使用大模型能力测评小工具,3分钟解锁您的大模型认知,边测边学解锁AI黑科技!