本节代码将展示如何在预训练的BERT模型基础上进行微调,以适应特定的下游任务。
⭐学习建议直接看文章最后的需复现代码,不懂得地方再回看
微调是自然语言处理中常见的方法,通过在预训练模型的基础上添加额外的层,并在特定任务的数据集上进行训练,可以快速适应新的任务。以下是从模型微调的角度对代码的详细说明:
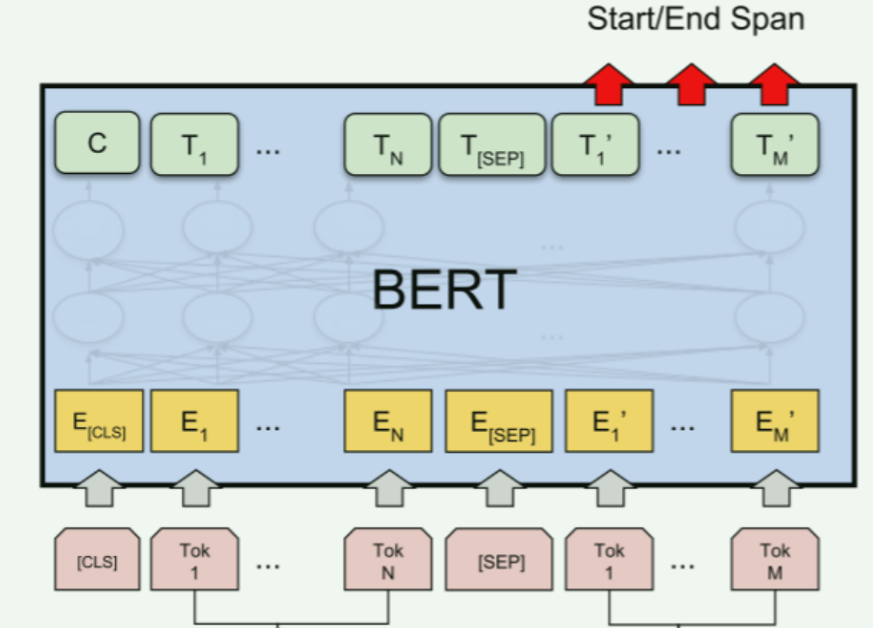
1. 加载预训练模型
self.bert = BertModel.from_pretrained(model_path)预训练模型:使用
transformers库的BertModel.from_pretrained方法加载一个预训练的BERT模型。model_path是预训练模型的路径或名称,例如"bert-base-chinese"。优势:
预训练模型已经在大规模语料上进行了训练,学习了通用的语言表示。
微调可以利用这些预训练的参数,快速适应新的任务,通常只需要较少的数据和训练时间。
2. 添加任务特定的头
self.mlm_head = nn.Linear(d_model, vocab_size)
self.nsp_head = nn.Linear(d_model, 2)MLM头:
mlm_head是一个线性层,用于预测被掩盖的单词。输入是BERT模型的输出,输出是词汇表大小的预测概率。NSP头:
nsp_head是一个线性层,用于预测两个句子是否相邻。输入是BERT模型的[CLS]标记的输出,输出是二分类的概率。
3. 前向传播
def forward(self, mlm_tok_ids, seg_ids, mask):
bert_out = self.bert(mlm_tok_ids, seg_ids, mask)
output = bert_out.last_hidden_state
cls_token = output[:, 0, :]
mlm_logits = self.mlm_head(output)
nsp_logits = self.nsp_head(cls_token)
return mlm_logits, nsp_logitsBERT模型的输出:
bert_out.last_hidden_state:BERT模型的输出,形状为(batch_size, seq_len, d_model)。[CLS]标记的输出:output[:, 0, :],用于NSP任务。
任务特定的输出:
mlm_logits:MLM任务的预测结果。nsp_logits:NSP任务的预测结果。
4. 数据处理
class BERTDataset(Dataset):
def __init__(self, nsp_dataset, tokenizer: BertTokenizer, max_length):
self.nsp_dataset = nsp_dataset
self.tokenizer = tokenizer
self.max_length = max_length
self.cls_id = tokenizer.cls_token_id
self.sep_id = tokenizer.sep_token_id
self.pad_id = tokenizer.pad_token_id
self.mask_id = tokenizer.mask_token_id
def __getitem__(self, idx):
sent1, sent2, nsp_label = self.nsp_dataset[idx]
sent1_ids = self.tokenizer.encode(sent1, add_special_tokens=False)
sent2_ids = self.tokenizer.encode(sent2, add_special_tokens=False)
tok_ids = [self.cls_id] + sent1_ids + [self.sep_id] + sent2_ids + [self.sep_id]
seg_ids = [0]*(len(sent1_ids)+2) + [1]*(len(sent2_ids) + 1)
mlm_tok_ids, mlm_labels = self.build_mlm_dataset(tok_ids)
mlm_tok_ids = self.pad_to_seq_len(mlm_tok_ids, 0)
seg_ids = self.pad_to_seq_len(seg_ids, 2)
mlm_labels = self.pad_to_seq_len(mlm_labels, -100)
mask = (mlm_tok_ids != 0)
return {
"mlm_tok_ids": mlm_tok_ids,
"seg_ids": seg_ids,
"mask": torch.tensor(mask, dtype=torch.long),
"mlm_labels": mlm_labels,
"nsp_labels": torch.tensor(nsp_label)
}数据处理:
将文本数据转换为词索引(
tok_ids)。添加特殊标记(
[CLS]和[SEP])。生成段嵌入(
seg_ids)。生成MLM任务的数据(
mlm_tok_ids和mlm_labels)。填充或截断序列到固定长度(
max_length)。
掩码:生成掩码,用于标记哪些位置是有效的输入(非填充部分)。
5. 训练过程
for epoch in range(epochs):
for batch in tqdm(trainloader, desc="Training"):
batch_mlm_tok_ids = batch["mlm_tok_ids"]
batch_seg_ids = batch["seg_ids"]
batch_mask = batch["mask"]
batch_mlm_labels = batch["mlm_labels"]
batch_nsp_labels = batch["nsp_labels"]
mlm_logits, nsp_logits = model(batch_mlm_tok_ids, batch_seg_ids, batch_mask)
loss_mlm = loss_fn(mlm_logits.view(-1, vocab_size), batch_mlm_labels.view(-1))
loss_nsp = loss_fn(nsp_logits, batch_nsp_labels)
loss = loss_mlm + loss_nsp
loss.backward()
optim.step()
optim.zero_grad()
print("Epoch: {}, MLM Loss: {}, NSP Loss: {}".format(epoch, loss_mlm, loss_nsp))训练步骤:
前向传播:将输入数据通过模型,得到MLM和NSP任务的预测结果。
计算损失:分别计算MLM和NSP任务的损失。
反向传播:计算梯度并更新模型参数。
优化器:使用Adam优化器,学习率设置为
1e-3。
进度条:使用
tqdm显示训练进度,使训练过程更加直观。
6. 微调的优势
快速适应新任务:预训练模型已经学习了通用的语言表示,微调可以快速适应新的任务,通常只需要较少的数据和训练时间。
节省计算资源:从头训练BERT模型需要大量的计算资源和时间,而微调只需要在预训练模型的基础上进行少量的训练。
更好的性能:预训练模型在大规模数据上进行了训练,通常具有更好的性能。微调可以进一步提升模型在特定任务上的表现。
需复现代码
import re
import math
import torch
import random
import torch.nn as nn
from tqdm import tqdm
from transformers import BertTokenizer, BertModel
from torch.utils.data import Dataset, DataLoader
class BERT(nn.Module):
def __init__(self, vocab_size, d_model, seq_len, N_blocks, num_heads, dropout, dff):
super().__init__()
self.bert = BertModel.from_pretrained(model_path)
self.mlm_head = nn.Linear(d_model, vocab_size)
self.nsp_head = nn.Linear(d_model, 2)
def forward(self, mlm_tok_ids, seg_ids, mask):
bert_out = self.bert(mlm_tok_ids, seg_ids, mask)
output = bert_out.last_hidden_state
cls_token = output[:, 0, :]
mlm_logits = self.mlm_head(output)
nsp_logits = self.nsp_head(cls_token)
return mlm_logits, nsp_logits
def read_data(file):
with open(file, "r", encoding="utf-8") as f:
data = f.read().strip().replace("\n", "")
corpus = re.split(r'[。,“”:;!、]', data)
corpus = [sentence for sentence in corpus if sentence.strip()]
return corpus
def create_nsp_dataset(corpus):
nsp_dataset = []
for i in range(len(corpus)-1):
next_sentence = corpus[i+1]
rand_id = random.randint(0, len(corpus) - 1)
while abs(rand_id - i) <= 1:
rand_id = random.randint(0, len(corpus) - 1)
negt_sentence = corpus[rand_id]
nsp_dataset.append((corpus[i], next_sentence, 1)) # 正样本
nsp_dataset.append((corpus[i], negt_sentence, 0)) # 负样本
return nsp_dataset
class BERTDataset(Dataset):
def __init__(self, nsp_dataset, tokenizer: BertTokenizer, max_length):
self.nsp_dataset = nsp_dataset
self.tokenizer = tokenizer
self.max_length = max_length
self.cls_id = tokenizer.cls_token_id
self.sep_id = tokenizer.sep_token_id
self.pad_id = tokenizer.pad_token_id
self.mask_id = tokenizer.mask_token_id
def __len__(self):
return len(self.nsp_dataset)
def __getitem__(self, idx):
sent1, sent2, nsp_label = self.nsp_dataset[idx]
sent1_ids = self.tokenizer.encode(sent1, add_special_tokens=False)
sent2_ids = self.tokenizer.encode(sent2, add_special_tokens=False)
tok_ids = [self.cls_id] + sent1_ids + [self.sep_id] + sent2_ids + [self.sep_id]
seg_ids = [0]*(len(sent1_ids)+2) + [1]*(len(sent2_ids) + 1)
mlm_tok_ids, mlm_labels = self.build_mlm_dataset(tok_ids)
mlm_tok_ids = self.pad_to_seq_len(mlm_tok_ids, 0)
seg_ids = self.pad_to_seq_len(seg_ids, 2)
mlm_labels = self.pad_to_seq_len(mlm_labels, -100)
mask = (mlm_tok_ids != 0)
return {
"mlm_tok_ids": mlm_tok_ids,
"seg_ids": seg_ids,
"mask": torch.tensor(mask, dtype=torch.long),
"mlm_labels": mlm_labels,
"nsp_labels": torch.tensor(nsp_label)
}
def pad_to_seq_len(self, seq, pad_value):
seq = seq[:self.max_length]
pad_num = self.max_length - len(seq)
return torch.tensor(seq + pad_num * [pad_value], dtype=torch.long)
def build_mlm_dataset(self, tok_ids):
mlm_tok_ids = tok_ids.copy()
mlm_labels = [-100] * len(tok_ids)
for i in range(len(tok_ids)):
if tok_ids[i] not in [self.cls_id, self.sep_id, self.pad_id]:
if random.random() < 0.15:
mlm_labels[i] = tok_ids[i]
if random.random() < 0.8:
mlm_tok_ids[i] = self.mask_id
elif random.random() < 0.9:
mlm_tok_ids[i] = random.randint(106, self.tokenizer.vocab_size - 1)
return mlm_tok_ids, mlm_labels
if __name__ == "__main__":
data_file = "4.10-BERT/背影.txt"
model_path = "/Users/azen/Desktop/llm/models/bert-base-chinese"
tokenizer = BertTokenizer.from_pretrained(model_path)
corpus = read_data(data_file)
max_length = 25 # len(max(corpus, key=len))
print("Max length of dataset: {}".format(max_length))
nsp_dataset = create_nsp_dataset(corpus)
trainset = BERTDataset(nsp_dataset, tokenizer, max_length)
batch_size = 16
trainloader = DataLoader(trainset, batch_size, shuffle=True)
vocab_size = tokenizer.vocab_size
d_model = 768
N_blocks = 2
num_heads = 12
dropout = 0.1
dff = 4*d_model
model = BERT(vocab_size, d_model, max_length, N_blocks, num_heads, dropout, dff)
lr = 1e-3
optim = torch.optim.Adam(model.parameters(), lr=lr)
loss_fn = nn.CrossEntropyLoss()
epochs = 20
for epoch in range(epochs):
for batch in tqdm(trainloader, desc = "Training"):
batch_mlm_tok_ids = batch["mlm_tok_ids"]
batch_seg_ids = batch["seg_ids"]
batch_mask = batch["mask"]
batch_mlm_labels = batch["mlm_labels"]
batch_nsp_labels = batch["nsp_labels"]
mlm_logits, nsp_logits = model(batch_mlm_tok_ids, batch_seg_ids, batch_mask)
loss_mlm = loss_fn(mlm_logits.view(-1, vocab_size), batch_mlm_labels.view(-1))
loss_nsp = loss_fn(nsp_logits, batch_nsp_labels)
loss = loss_mlm + loss_nsp
loss.backward()
optim.step()
optim.zero_grad()
print("Epoch: {}, MLM Loss: {}, NSP Loss: {}".format(epoch, loss_mlm, loss_nsp))
pass
pass