在当今快节奏的都市生活中,餐饮品牌的门店布局不仅反映了其市场策略,更折射出消费者对便捷、品质和品牌认同的追求。汉堡王(Burger King)作为全球知名的西式快餐品牌之一,在中国市场同样占据重要地位。自进入中国市场以来,汉堡王凭借其独特的“火烤”特色以及多样化的菜单选择,迅速在全国范围内扩张,并逐渐形成了与本地市场的深度融合,成为肯德基、麦当劳之外的重要竞争者。不同于德克士的“东方口味西式快餐”定位,汉堡王强调的是其独有的火烤工艺和经典的美式风味,吸引了大量追求正宗西式快餐体验的消费者。其门店分布广泛覆盖一二线城市,并逐步向三四线城市下沉,展现出强大的市场渗透力和品牌影响力。
本文将深入探讨GET请求在获取汉堡王官方网站的门店分布信息中的实际应用,并展示如何使用Python的requests库发送GET请求,从汉堡王官方网站提取详细的门店位置信息,涵盖全国范围内的所有汉堡王店铺。处理响应数据的方法包括解析JSON格式的数据或者HTML页面,以便有效地提取所需信息。通过多维度的数据分析视角,挖掘汉堡王门店分布中隐含的市场策略与消费趋势。这项研究不仅能为餐饮行业从业者提供选址决策支持,也可为商业地理学研究提供新的数据支撑,更可为广大消费者带来更加便捷的门店查询体验。
汉堡王官方网站:餐厅 - BURGER KING® 汉堡王中国官网
我们第一步先找到门店数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;

负载:对于GET请求:负载通常包含了传递的参数,有些网页负载可能为空,或者没有负载,因为所有参数都通过URL传递,这里我们可以看到它的传参包括,省份、地级市,是明文传输;
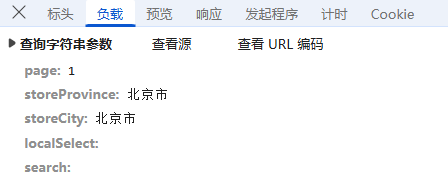
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;
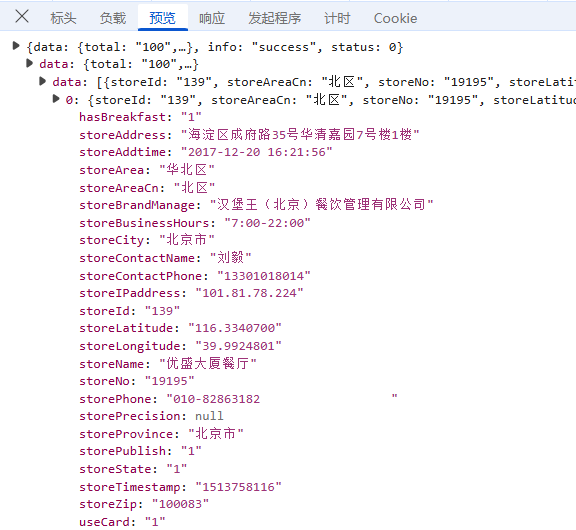
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应数据存储位置,获取所有店铺列表的相关标签数据;
- 我们通过改变查询关键字(省份、地级市),来遍历全国门店数据;
- 坐标转换,通过coord-convert库实现GCJ-02转WGS84;
第一步:我们先找到对应数据存储位置,获取所有店铺列表,经过测试,每次查询一类关键词会返回一个html,我们通过修改关键词来进行数据获取,为了方便我们直接建立一个包含省份、地级市字典,通过遍历关键词来查询全国数据;
第二步:利用GET请求遍历获取所有店铺列表,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
import requests
import json
import pandas as pd
from datetime import datetime
import math
import time
# 省份和城市数据
PROVINCE_CITY_DICT = {
"北京市": ["北京市"],
"天津市": ["天津市"],
"上海市": ["上海市"],
"重庆市": ["重庆市"],
"河北省": ["石家庄市", "唐山市", "秦皇岛市", "邯郸市", "邢台市", "保定市", "张家口市", "承德市", "沧州市", "廊坊市",
"衡水市"],
"山西省": ["太原市", "大同市", "阳泉市", "长治市", "晋城市", "朔州市", "晋中市", "运城市", "忻州市", "临汾市",
"吕梁市"],
"内蒙古自治区": ["呼和浩特市", "包头市", "乌海市", "赤峰市", "通辽市", "鄂尔多斯市", "呼伦贝尔市", "巴彦淖尔市",
"乌兰察布市"],
"辽宁省": ["沈阳市", "大连市", "鞍山市", "抚顺市", "本溪市", "丹东市", "锦州市", "营口市", "阜新市", "辽阳市",
"盘锦市", "铁岭市", "朝阳市", "葫芦岛市"],
"吉林省": ["长春市", "吉林市", "四平市", "辽源市", "通化市", "白山市", "松原市", "白城市"],
"黑龙江省": ["哈尔滨市", "齐齐哈尔市", "鸡西市", "鹤岗市", "双鸭山市", "大庆市", "伊春市", "佳木斯市", "七台河市",
"牡丹江市", "黑河市", "绥化市"],
"江苏省": ["南京市", "无锡市", "徐州市", "常州市", "苏州市", "南通市", "连云港市", "淮安市", "盐城市", "扬州市",
"镇江市", "泰州市", "宿迁市"],
"浙江省": ["杭州市", "宁波市", "温州市", "嘉兴市", "湖州市", "绍兴市", "金华市", "衢州市", "舟山市", "台州市",
"丽水市"],
"安徽省": ["合肥市", "芜湖市", "蚌埠市", "淮南市", "马鞍山市", "淮北市", "铜陵市", "安庆市", "黄山市", "滁州市",
"阜阳市", "宿州市", "六安市", "亳州市", "池州市", "宣城市"],
"福建省": ["福州市", "厦门市", "莆田市", "三明市", "泉州市", "漳州市", "南平市", "龙岩市", "宁德市"],
"江西省": ["南昌市", "景德镇市", "萍乡市", "九江市", "新余市", "鹰潭市", "赣州市", "吉安市", "宜春市", "抚州市",
"上饶市"],
"山东省": ["济南市", "青岛市", "淄博市", "枣庄市", "东营市", "烟台市", "潍坊市", "济宁市", "泰安市", "威海市",
"日照市", "临沂市", "德州市", "聊城市", "滨州市", "菏泽市"],
"河南省": ["郑州市", "开封市", "洛阳市", "平顶山市", "安阳市", "鹤壁市", "新乡市", "焦作市", "濮阳市", "许昌市",
"漯河市", "三门峡市", "南阳市", "商丘市", "信阳市", "周口市", "驻马店市"],
"湖北省": ["武汉市", "黄石市", "十堰市", "宜昌市", "襄阳市", "鄂州市", "荆门市", "孝感市", "荆州市", "黄冈市",
"咸宁市", "随州市"],
"湖南省": ["长沙市", "株洲市", "湘潭市", "衡阳市", "邵阳市", "岳阳市", "常德市", "张家界市", "益阳市", "郴州市",
"永州市", "怀化市", "娄底市"],
"广东省": ["广州市", "韶关市", "深圳市", "珠海市", "汕头市", "佛山市", "江门市", "湛江市", "茂名市", "肇庆市",
"惠州市", "梅州市", "汕尾市", "河源市", "阳江市", "清远市", "东莞市", "中山市", "潮州市", "揭阳市",
"云浮市"],
"广西壮族自治区": ["南宁市", "柳州市", "桂林市", "梧州市", "北海市", "防城港市", "钦州市", "贵港市", "玉林市",
"百色市", "贺州市", "河池市", "来宾市", "崇左市"],
"海南省": ["海口市", "三亚市", "三沙市", "儋州市"],
"四川省": ["成都市", "自贡市", "攀枝花市", "泸州市", "德阳市", "绵阳市", "广元市", "遂宁市", "内江市", "乐山市",
"南充市", "眉山市", "宜宾市", "广安市", "达州市", "雅安市", "巴中市", "资阳市"],
"贵州省": ["贵阳市", "六盘水市", "遵义市", "安顺市", "毕节市", "铜仁市"],
"云南省": ["昆明市", "曲靖市", "玉溪市", "保山市", "昭通市", "丽江市", "普洱市", "临沧市"],
"西藏自治区": ["拉萨市", "日喀则市", "昌都市", "林芝市", "山南市", "那曲市"],
"陕西省": ["西安市", "铜川市", "宝鸡市", "咸阳市", "渭南市", "延安市", "汉中市", "榆林市", "安康市", "商洛市"],
"甘肃省": ["兰州市", "嘉峪关市", "金昌市", "白银市", "天水市", "武威市", "张掖市", "平凉市", "酒泉市", "庆阳市",
"定西市", "陇南市"],
"青海省": ["西宁市", "海东市"],
"宁夏回族自治区": ["银川市", "石嘴山市", "吴忠市", "固原市", "中卫市"],
"新疆维吾尔自治区": ["乌鲁木齐市", "克拉玛依市"]
}
def fetch_bk_stores_by_city(province, city):
"""获取指定省份城市的汉堡王店铺信息"""
try:
store_list = []
first_page = True
current_page = 1
total_pages = 1
while current_page <= total_pages:
# 请求URL和参数
url = "https://www.bkchina.cn/restaurant/getMapsListAjax"
params = {
'page': current_page,
'storeProvince': province,
'storeCity': city,
'localSelect': '',
'search': ''
}
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}
# 发送GET请求
response = requests.get(url, params=params, headers=headers)
response.raise_for_status()
# 解析JSON响应
data = response.json()
# 检查响应状态
if data.get('status') != 0 or 'data' not in data:
print(f"获取 {province} {city} 数据失败: {data.get('info', '未知错误')}")
return None
# 提取店铺列表
stores = data['data']['data']
# 如果是第一页,计算总页数
if first_page:
total_stores = int(data['data']['total'])
if total_stores == 0:
print(f"{province} {city} 没有店铺数据")
return None
total_pages = math.ceil(total_stores / 5)
print(f"{province} {city} 总店铺数: {total_stores}")
first_page = False
# 处理每个店铺的数据
for store in stores:
store_info = {
'storeName': store.get('storeName', ''),
'storeAddress': store.get('storeAddress', ''),
'storeBusinessHours': store.get('storeBusinessHours', ''),
'storePhone': store.get('storePhone', ''),
'storeProvince': store.get('storeProvince', ''),
'storeCity': store.get('storeCity', ''),
'storeArea': store.get('storeArea', ''),
'storeAreaCn': store.get('storeAreaCn', ''),
'storeLatitude': store.get('storeLatitude', ''),
'storeLongitude': store.get('storeLongitude', ''),
'storeId': store.get('storeId', ''),
'storeNo': store.get('storeNo', ''),
'storeBrandManage': store.get('storeBrandManage', ''),
'storeContactName': store.get('storeContactName', ''),
'storeContactPhone': store.get('storeContactPhone', ''),
'storeAddtime': store.get('storeAddtime', ''),
'hasBreakfast': store.get('hasBreakfast', ''),
'useCard': store.get('useCard', '')
}
store_list.append(store_info)
current_page += 1
if current_page <= total_pages:
time.sleep(1)
return store_list
except Exception as e:
print(f"获取 {province} {city} 数据时出错: {str(e)}")
return None
def fetch_all_stores():
"""获取所有省份城市的汉堡王店铺信息"""
all_stores = []
for province, cities in PROVINCE_CITY_DICT.items():
print(f"\n开始获取 {province} 的数据...")
for city in cities:
print(f"\n正在获取 {province} {city} 的数据...")
stores = fetch_bk_stores_by_city(province, city)
if stores:
all_stores.extend(stores)
print(f"{province} {city} 数据获取成功,获取到 {len(stores)} 家店铺")
time.sleep(2) # 在获取不同城市数据之间添加延时
if all_stores:
# 创建DataFrame
df = pd.DataFrame(all_stores)
# 生成输出文件名(包含时间戳)
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
output_file = f'bk_stores_all_{timestamp}.csv'
# 保存为CSV文件
df.to_csv(output_file, index=False, encoding='utf-8-sig')
print(f"\n所有数据获取完成!")
print(f"总共获取到 {len(all_stores)} 家店铺信息")
print(f"数据已保存到:{output_file}")
return df
return None
if __name__ == "__main__":
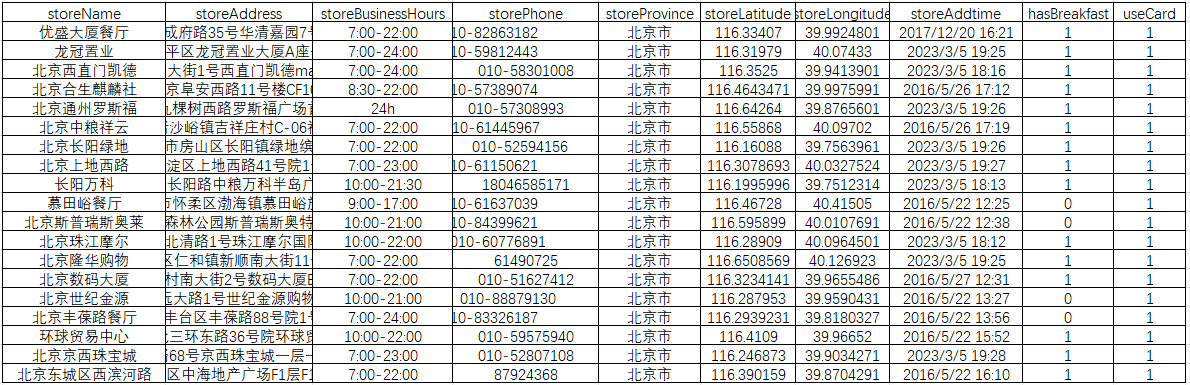
fetch_all_stores()这里我们建立一个包含省份、地级市的字典,并遍历查询每组关键词下的汉堡王店铺,获取数据标签如下, storeName(店铺名称)、storeAddress(店铺地址)、storeBusinessHours(营业时间)、storePhone(店铺电话)、storeProvince(所在省份)、storeCity(所在城市)、storeLatitude(纬度)、storeLongitude(经度)、storeAddtime(开业时间)、hasBreakfast(是否供应早餐(0-否,1-是))useCard(是否可用会员卡(0-否,1-是)),其他一些非关键标签,这里省略;
第三步:坐标系转换,由于汉堡王门店使用的是百度坐标系(GCJ-02),为了在ArcGIS上准确展示而不发生偏移,我们需要将门店的坐标从GCJ-02转换为WGS-84坐标系。我们可以利用coord-convert库中的gcj2wgswgs(lng, lat)函数,也可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具 (latlongconverter.online);
对CSV文件中的门店坐标列进行转换。完成坐标转换后,再将数据导入ArcGIS进行可视化;
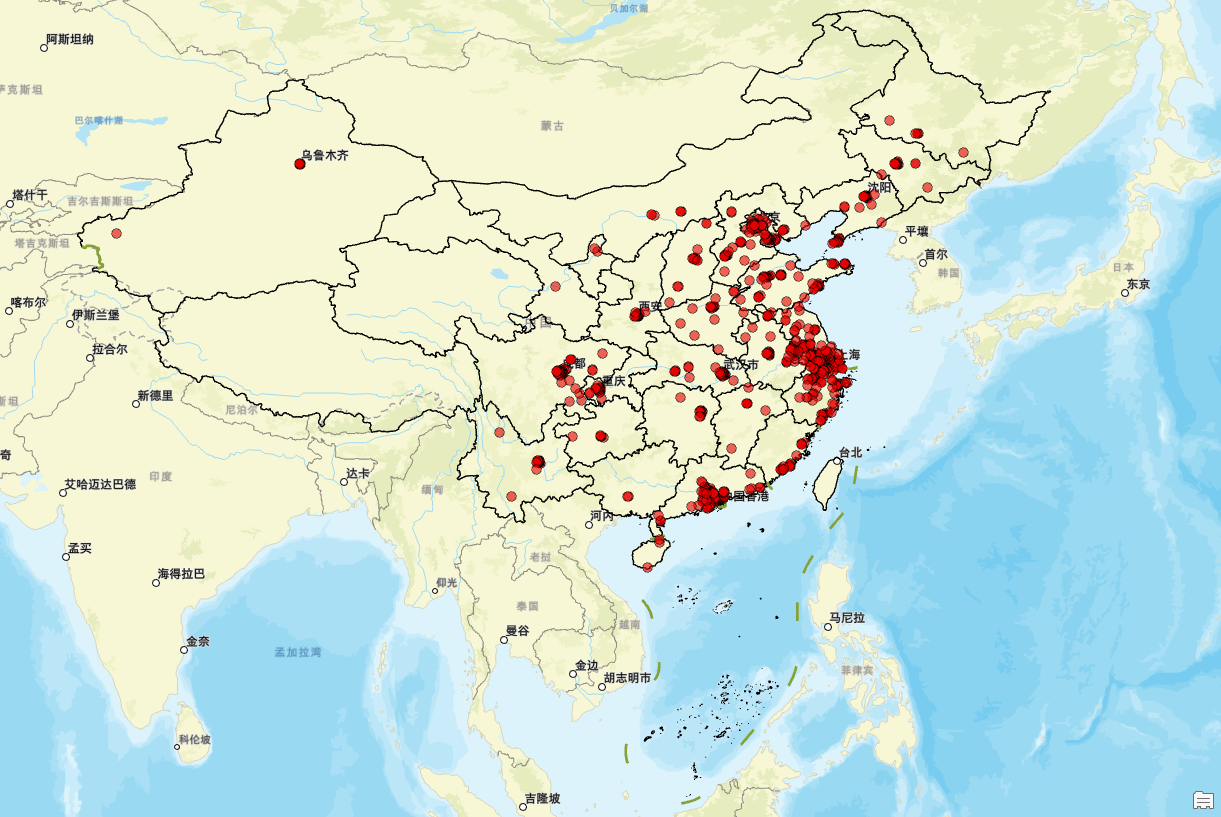
接下来,我们进行看图说话:
首先,在一线城市如北京、上海、广州和深圳,汉堡王通过高度集中的布局来吸引那些追求品质生活、愿意为高质量快餐支付溢价的城市居民。这些地区的消费者通常具有较高的消费能力和对国际品牌的认可度,非常适合汉堡王展示其品牌形象和推广高端产品线。此外,这些城市的快节奏生活方式也与汉堡王快捷方便的服务理念相契合。
其次,在二线城市如南京、杭州、成都、武汉等地,汉堡王同样展现了广泛的覆盖。这些城市虽然经济发展水平略低于一线城市,但拥有活跃的商业环境和庞大的年轻人口基数,这为汉堡王提供了广阔的市场空间。在这里,汉堡王可以通过调整菜单价格和推出本地化口味的产品来吸引更多消费者,进一步巩固其市场份额。
值得注意的是,汉堡王正在逐步向三四线城市下沉,比如徐州、临沂、洛阳等城市。这一战略转变反映了品牌对于中国广阔内陆市场潜力的认识。在这些城市,尽管消费者的购买力可能不如一二线城市,但他们对于新鲜事物的好奇心和对西方快餐文化的向往使得汉堡王有机会开拓新的客群。
从地理分布上看,东部沿海地区和部分中部地区成为汉堡王重点布局的区域,这是因为这些地方经济活力强、人口密集,符合汉堡王针对都市白领和年轻家庭的品牌定位。而在西部地区,尽管门店数量相对较少,但随着当地经济的发展和消费者口味的变化,汉堡王也在逐步增加门店,以期捕捉到新兴市场的增长机会。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。