作者:鹰角网络高级大数据研发 茅旭辉
背景介绍
鹰角网络是一家年轻且富有创新的游戏公司,致力于开发充满挑战性和艺术价值的游戏产品。公司目前涵盖了游戏开发、运营和发行的全生命周期业务。随着业务的扩展,鹰角网络从单一爆款游戏发展到多赛道、多平台、全球化的战略布局,在数据业务上进行了全面的优化和升级。
从业务上看,以《明日方舟》为代表的长线运营游戏,具有相对高频的活动周期和丰富多样的活动玩法,反映到数据层面则是数据需求量高、潮汐现象显著,需要高效的开发模式支持和灵活的弹性资源供给。我们的数据支持不仅仅有传统的BI报表形式,更是深入集成到游戏玩法和运营层面透出,对于引擎稳定性有强烈诉求。另外,内部面向业务的分析跑数场景,存在基于Thrift Server等能力扩展支持的诉求。
为什么选择阿里云EMR Serverless Spark
原有架构痛点
在业务发展过程中,原有架构逐渐暴露出了如下痛点:
产品功能上,缺少外部Catalog支持和DolphinScheduler等流行调度引擎集成支持
引擎性能上,社区兼容性相对较低产生稳定性问题,且不支持Remote Shuffle Service服务导致性能问题
服务保障上,技术支持力度较弱,在用户痛点发掘和产品迭代方面做的不足
EMR Serverless Spark优势
我们期待的云原生大数据架构是基于开放生态、资源弹性、可插拔集成理念下的半托管+全托管灵活组合架构,而EMR Serverless Spark正是完美匹配这套理念的重要一环。它是一款兼容开源 Spark 的高性能 Lakehouse 产品,为用户提供任务开发、调试、发布、调度和运维等全方位的产品化服务,显著简化了大数据计算的工作流程,使用户能更专注于数据分析和价值提炼,具备如下核心优势:
丰富的功能支持
元数据管理:支持管理Paimon Catalog,并且支持对接外部Hive MetaStore元数据服务。
调度引擎支持:提供了Airflow、DolphinScheduler等多种调度引擎无缝集成。
资源管理模型:提供了易于理解的三级资源管理模型(工作空间、队列、会话)和细粒度的队列资源监控。
生态能力:提供了Spark Thrift Server、Notebook等多种生态功能,便于业务灵活使用。
优秀的引擎性能
Shuffle性能:内置Celeborn服务,解决了大Shuffle场景下的磁盘限制问题。
SQL执行引擎:内置的高性能Fusion引擎,为计算加速提供支持。
稳定性:100%保持社区兼容性,并积极修复潜在Bug。
版本支持:持续追踪Spark社区版本,提供多版本迭代支持和完整的引擎特性使用。
完善的服务保障
问题响应:提供了专业的技术咨询和解决方案支持,增强合作信任度。
产品规划:提供了清晰的产品迭代规划,持续解决用户痛点场景。
技术方案设计
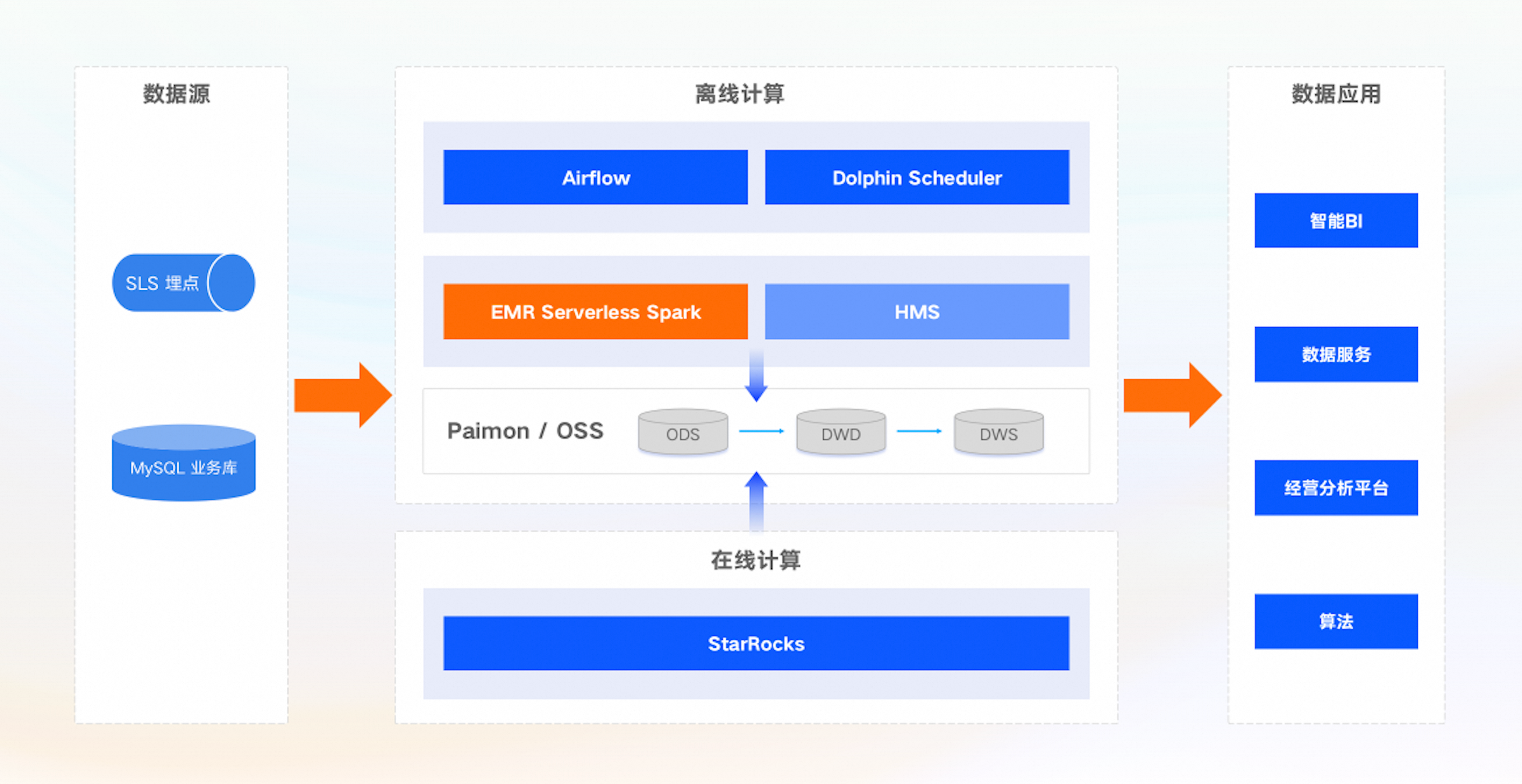
数据采集
在数据采集和管理方面,我们采用了自研的埋点工具来获取和管理日志数据,并利用Flink CDC技术同步数据库表。这确保了数据的实时性和准确性,为后续的数据分析提供了可靠的基础。
离线调度
在离线调度方面,我们实施了两种策略一种引擎,一是使用Airflow服务支持有代码基础的研发用户,同时为普通数据分析师和数仓研发提供了DolphinScheduler服务,这两种调度系统都实现了对 EMR Serverless Spark 的对接,满足平台服务的灵活性。
我们选择了 Serverless Spark 作为其离线计算引擎,相比于之前的架构,Serverless Spark显著减少了运维成本,并提高了系统的稳定性和可靠性。其 Celeborn 能力解决了大 Shuffle 任务操作中的磁盘限制问题,同时任务状态与调度工具实现了强一致性,无需二次确认,进一步优化了数据处理流程。
在线计算
为了支持在线计算和数据应用,我们使用Starrocks进行在线计算,高质量的指标数据通过智能BI系统实现可视化实时展示,并提供了清晰的业务洞察。同时,数据还被整合到经营分析平台,为其业务发展提供了统一支持。数据也应用于算法团队进行业务探索与数据科学分析。
典型应用场景
DolphinScheduler 集成作业开发
Serverless Spark在DolphinScheduler中集成了专用的作业类型ALIYUN_SERVERLESS_SPARK,支持SQL、SQL File、Jar包等多种作业形式。我们在本地Git仓库开发作业,通过CI流程部署到OSS存储路径下,并使用SQL File/Jar作业类型,提交相应的作业文件到Serverless Spark执行计算。
Thrift Server 支持 Ad-Hoc
Serverless Spark内置了Thrift Server服务,支持通过JDBC的方式连接Spark执行SQL查询,提供了便捷将Spark环境与其他数据分析工具集成的途径。目前Spark Thrift Server能力在内部主要支持以下两类场景:
以产品运营人员为主的Ad-Hoc分析场景,期望通过Spark引擎执行SQL查询,但希望忽略资源配置等非必要信息,可以直接使用DolphinScheduler内置的SQL作业类型 + Spark数据源进行简单查询。同时Spark Thrift Server会话支持动态资源配置,可以自适应支持Ad-Hoc查询所需资源。
以数仓研发为主的数据结果返回场景,能够拿到SQL查询结果并传递给下游作业使用。
迁移后的收益
通过这一系列技术栈的优化,我们不仅优化了数据管理和分析流程,还有效支持了公司的全球化战略和业务扩展,目前我们已经在海外基于 EMR Serverless Spark 搭建类似数据架构。
EMR Serverless Spark主要给我们带来了以下收益:
1. 研发效率提升,支持业务快速发展
迁移到EMR Serverless Spark + DolphinScheduler架构后,使用Spark SQL会话功能快速开发验证+DolphinScheduler生产调度的模式,研发效率显著提升,多次保障了关键活动节点的数据产出支持。
2. 计算效率提升,增强SLA保障
在以用户宽表为代表的指标计算场景下,单作业计算用时从30分钟降低到15分钟,计算加速50%;核心SLA链路整体产出时间缩短1.5小时,大幅增强了SLA保障能力。
3. 稳定性提升,降低运维压力
EMR Serverless Spark 的多版本管理能力为用户提供了灵活的选择空间,支持快速升级至最新优化版本,确保用户始终享有最稳定的运行体验。
总结及后续期待
经过了业务实践证明,EMR Serverless Spark在大数据研发下Spark生态领域的经典业务场景具备了足够的优势。对于未来,我们期望它能继续以开放原则发展Lakehouse生态能力,例如统一Catalog管理等能力,并逐步覆盖更多的边缘场景和探索型场景。