TCL(一面)
1. Spring 初始化Bean前要做什么?有几种方式
在 Spring 容器调用 Bean 的初始化方法(如 init-method、@PostConstruct 等)之前,会按顺序完成以下关键步骤:实例化 → 属性注入 → Aware 接口回调 → BeanPostProcessor 前置处理。
实例化:通过构造函数或工厂方法创建 Bean 的实例。
属性注入:通过
setter方法、字段注入(如@Autowired)或构造器注入,完成 Bean 的依赖注入。Aware 接口回调:如果 Bean 实现了 Spring 的
Aware接口,Spring 会调用对应的回调方法,使 Bean 能感知容器信息。BeanPostProcessor 的前置处理:调用所有注册的
BeanPostProcessor的postProcessBeforeInitialization()方法,允许对 Bean 进行自定义修改(如代理增强)。
在初始化阶段(即上述步骤完成后),Spring 提供了以下三种主要方式来定义 Bean 的初始化逻辑:
使用
@PostConstruct注解:在方法上添加@PostConstruct注解,Spring 会在依赖注入完成后调用该方法。
@Component
public class MyBean {
@PostConstruct
public void init() {
// 初始化逻辑
}
}
实现
InitializingBean接口:实现InitializingBean接口,并重写afterPropertiesSet()方法。
@Component
public class MyBean implements InitializingBean {
@Override
public void afterPropertiesSet() {
// 初始化逻辑
}
}
配置
init-method:在 XML 或 Java 配置中指定自定义的初始化方法。XML 示例:
<bean id="myBean" class="com.example.MyBean" init-method="customInit"/>
Java 注解配置示例:
@Bean(initMethod = "customInit")
public MyBean myBean() {
return new MyBean();
}
2. 微服务和单体的区别与优势是什么?
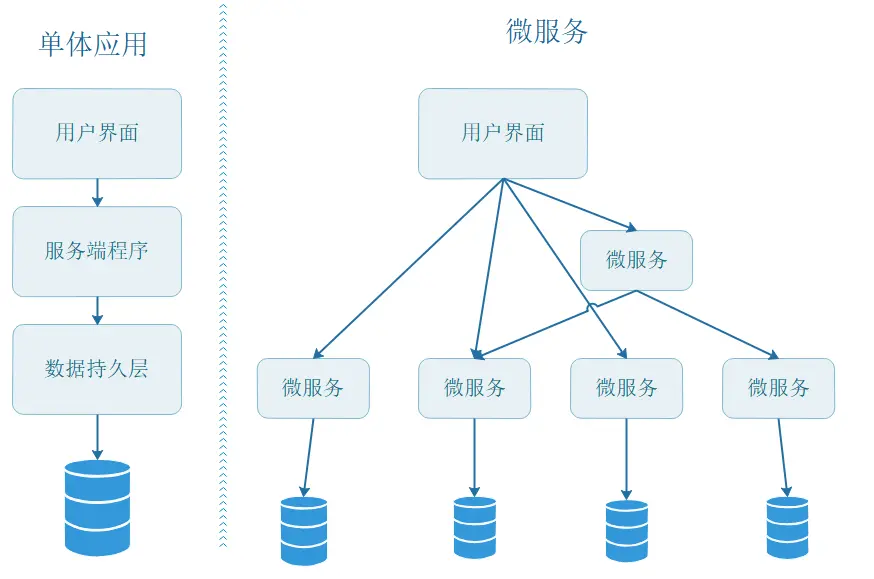
所有功能模块(如用户管理、订单处理、支付等)集中在一个单一的代码库中,编译为一个可执行文件或服务,共享同一个数据库和资源。单体架构适合业务简单、团队小的场景,优势是开发效率高、性能好,不过随着随着业务增长,代码库臃肿,维护会变的更困难,而且任何修改都可能影响全局,回归测试成本高。
将应用拆分为多个独立的、松耦合的小型服务,每个服务专注于单一业务功能,拥有独立的代码库、数据库和进程,通过API(如REST或gRPC)通信。微服务通过解耦服务实现灵活扩展和独立部署,但复杂度高,适合大型系统(如电商平台、社交网络)。
3. Spring Cloud组件有哪些?
我项目用的是Spring Cloud Alibaba,我简单说一下Spring Cloud Alibaba组件:
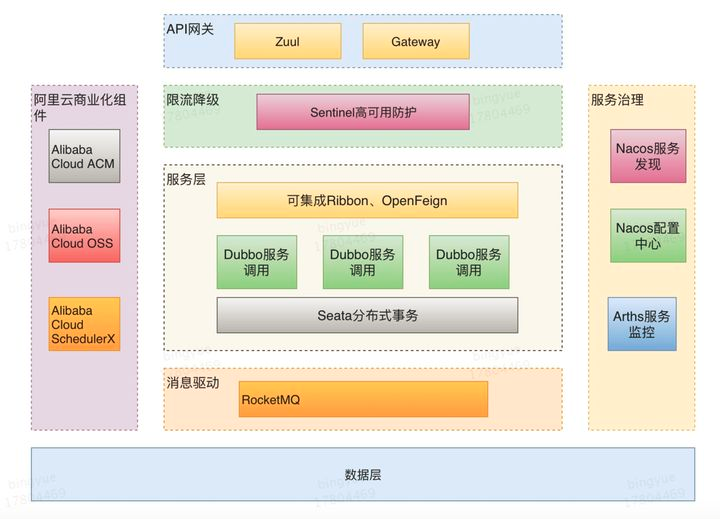
Nacos:其服务注册和发现功能能让服务提供者将自身服务信息注册到 Nacos 服务器,服务消费者从服务器获取服务列表,此外,Nacos 还支持配置的动态更新,可实现服务的快速上下线和配置的实时生效。
Sentinel:负责流量控制与熔断降级,Sentinel 可以通过配置规则对服务的流量进行精准控制,防止服务因流量过大而崩溃。同时,当服务出现异常时,它能快速进行熔断降级,保障系统的稳定性。
Seata;分布式事务,支持AT模式(自动补偿)、TCC、Saga等, 可以帮助开发者在微服务架构中处理分布式事务问题,确保数据的一致性。通过 Seata,开发者可以像处理本地事务一样处理分布式事务,降低了开发的复杂度。
RocketMQ:分布式消息队列,支持顺序消息、事务消息、延迟消息,开发者可以方便地在微服务之间进行异步通信,实现解耦和流量削峰。例如,在电商系统中,订单服务可以通过 RocketMQ 向库存服务发送消息,实现库存的扣减。
Dubbo:提供了高效的远程服务调用能力,支持多种协议和负载均衡策略。在微服务架构中,使用 Dubbo 可以方便地实现服务之间的远程调用,提高系统的性能和可扩展性。
Arthas:开源的Java动态追踪工具,基于字节码增强技术,功能非常强大。
4. Kafka 分区和消费者的关系是怎样的?
Kafka 的主题(Topic)可以被划分为多个分区(Partition),分区是物理上的概念,每个分区是一个有序的、不可变的消息序列。分区分布在不同的 broker 上,以此实现数据的分布式存储。
消费者从 Kafka 的主题中读取消息,消费者可以组成消费者组(Consumer Group),每个消费者组内有多个消费者实例。
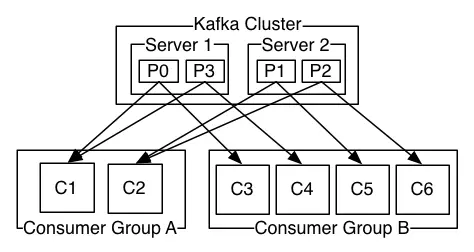
在一个消费者组内,一个分区只能被一个消费者实例消费。这种设计保证了分区内消息消费的顺序性,因为一个分区的消息只能由一个消费者按顺序处理。比如,一个主题有 3 个分区,一个消费者组中有 3 个消费者,那么这 3 个消费者会分别对应一个分区进行消息消费。
如果两个消费者负责同一个分区,那么就意味着两个消费者同时读取分区的消息,由于消费者自己可以控制读取消息的偏移量,就有可能C1才读到2,而C1读到1,C1还没处理完,C2已经读到3了,则会造成很多浪费,因为这就相当于多线程读取同一个消息,会造成消息处理的重复,且不能保证消息的顺序。
如果消费者数量 > 分区数,多余消费者闲置,比如主题 orders 有 3 个分区(P0、P1、P2),消费者组 group-1 有 3 个消费者(C1、C2、C3):
P0 → C1
P1 → C2
P2 → C3
如果消费者组扩容到 4 个消费者,第 4 个消费者(C4)将无法分配到分区,处于空闲状态。
5. Kafka 如何批量拉取消息?
可以通过调整配置参数来实现 Kafka 批量拉取消息:
设置
max.poll.records:该参数用于设定一次poll操作最多拉取的消息数量。例如,在 Java 中创建KafkaConsumer实例时,通过props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 100);将其设置为 100,意味着每次poll最多拉取 100 条消息。调整
fetch.max.bytes:此参数用于设置一次fetch请求能够拉取的最大数据量。如果消息体较大,可适当调大该参数,以确保能拉取到足够数量的消息。在 Java 中可通过props.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, 1024 * 1024);将其设置为 1MB。
6. Redis分布式锁实现原理?
分布式锁是用于分布式环境下并发控制的一种机制,用于控制某个资源在同一时刻只能被一个应用所使用。如下图所示:
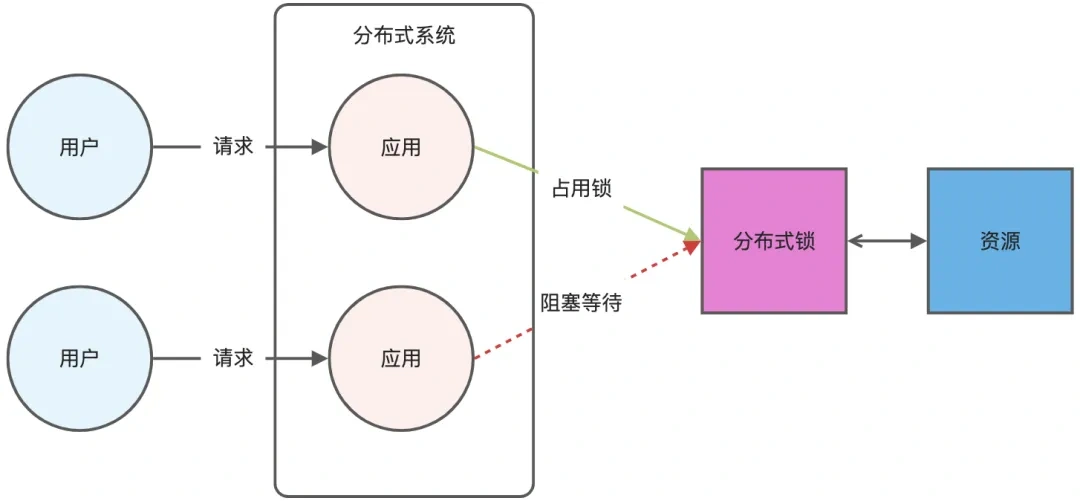
Redis 本身可以被多个客户端共享访问,正好就是一个共享存储系统,可以用来保存分布式锁,而且 Redis 的读写性能高,可以应对高并发的锁操作场景。Redis 的 SET 命令有个 NX 参数可以实现「key不存在才插入」,所以可以用它来实现分布式锁:
如果 key 不存在,则显示插入成功,可以用来表示加锁成功;
如果 key 存在,则会显示插入失败,可以用来表示加锁失败。
基于 Redis 节点实现分布式锁时,对于加锁操作,我们需要满足三个条件。
加锁包括了读取锁变量、检查锁变量值和设置锁变量值三个操作,但需要以原子操作的方式完成,所以,我们使用 SET 命令带上 NX 选项来实现加锁;
锁变量需要设置过期时间,以免客户端拿到锁后发生异常,导致锁一直无法释放,所以,我们在 SET 命令执行时加上 EX/PX 选项,设置其过期时间;
锁变量的值需要能区分来自不同客户端的加锁操作,以免在释放锁时,出现误释放操作,所以,我们使用 SET 命令设置锁变量值时,每个客户端设置的值是一个唯一值,用于标识客户端;
满足这三个条件的分布式命令如下:
SET lock_key unique_value NX PX 10000
lock_key 就是 key 键;
unique_value 是客户端生成的唯一的标识,区分来自不同客户端的锁操作;
NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作;
PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁。
而解锁的过程就是将 lock_key 键删除(del lock_key),但不能乱删,要保证执行操作的客户端就是加锁的客户端。所以,解锁的时候,我们要先判断锁的 unique_value 是否为加锁客户端,是的话,才将 lock_key 键删除。
可以看到,解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性,因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,保证了锁释放操作的原子性。
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这样一来,就通过使用 SET 命令和 Lua 脚本在 Redis 单节点上完成了分布式锁的加锁和解锁。
7. Redision使用方式是什么?
Redisson 是一个基于 Redis 的 Java 客户端,提供了丰富的分布式数据结构和服务,其中 分布式锁是其核心功能之一,以下是 Redisson 实现分布式锁的完整方式。
引入依赖:如果你使用 Maven 项目,可在
pom.xml里添加以下依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.2</version> <!-- 选择合适的版本 -->
</dependency>
配置客户端:要使用 Redisson,得先创建一个
RedissonClient实例。以下是一个简单的单机 Redis 配置示例:
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonConfigExample {
public static RedissonClient getRedissonClient() {
Config config = new Config();
// 单机模式
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
return Redisson.create(config);
}
}
实现分布式锁代码:Redisson 提供了多种分布式数据结构,例如分布式锁、分布式集合等。下面是使用分布式锁的示例:
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
publicclass RedissonLockExample {
public static void main(String[] args) {
RedissonClient redisson = RedissonConfigExample.getRedissonClient();
// 获取锁对象
RLock lock = redisson.getLock("myLock");
try {
// 尝试加锁,最多等待100秒,锁的持有时间为10秒
boolean isLocked = lock.tryLock(100, 10, java.util.concurrent.TimeUnit.SECONDS);
if (isLocked) {
try {
// 模拟业务操作
System.out.println("获得锁,开始执行任务");
Thread.sleep(5000);
} finally {
// 释放锁
lock.unlock();
System.out.println("释放锁");
}
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 关闭 Redisson 客户端
redisson.shutdown();
}
}
}
8. MySQL索引底层结构是什么?有什么优势?
MySQL InnoDB 引擎是用了B+树作为了索引的数据结构。
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键顺序存放的。每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都有两个指针,分别指向下一个叶子节点和上一个叶子节点,形成一个双向链表。
主键索引的 B+Tree 如图所示:
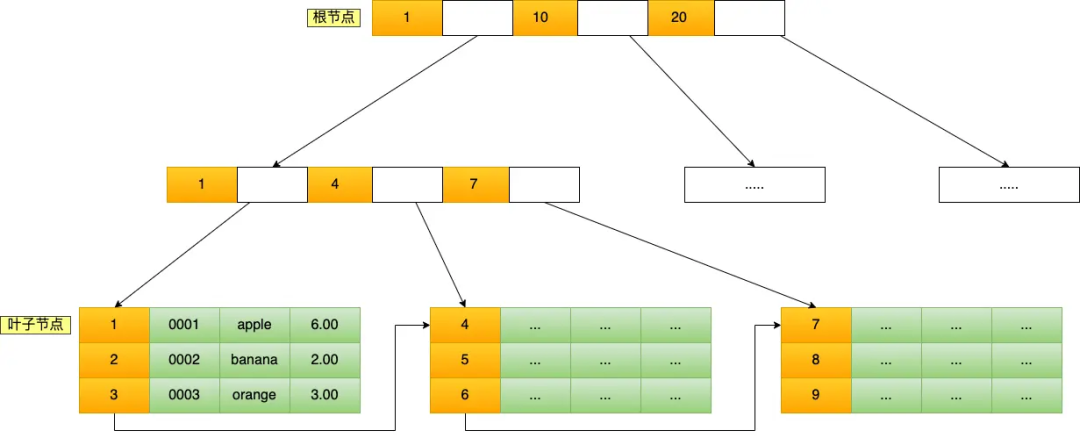
比如,我们执行了下面这条查询语句:
select * from product where id= 5;
这条语句使用了主键索引查询 id 号为 5 的商品。查询过程是这样的,B+Tree 会自顶向下逐层进行查找:
将 5 与根节点的索引数据 (1,10,20) 比较,5 在 1 和 10 之间,所以根据 B+Tree的搜索逻辑,找到第二层的索引数据 (1,4,7);
在第二层的索引数据 (1,4,7)中进行查找,因为 5 在 4 和 7 之间,所以找到第三层的索引数据(4,5,6);
在叶子节点的索引数据(4,5,6)中进行查找,然后我们找到了索引值为 5 的行数据。
数据库的索引和数据都是存储在硬盘的,我们可以把读取一个节点当作一次磁盘 I/O 操作。那么上面的整个查询过程一共经历了 3 个节点,也就是进行了 3 次 I/O 操作。
B+Tree 存储千万级的数据只需要 3-4 层高度就可以满足,这意味着从千万级的表查询目标数据最多需要 3-4 次磁盘 I/O,所以B+Tree 相比于 B 树和二叉树来说,最大的优势在于查询效率很高,因为即使在数据量很大的情况,查询一个数据的磁盘 I/O 依然维持在 3-4次。
9. 联合索引的失效场景你知道哪些?
6 种会发生索引失效的情况:
当我们使用左或者左右模糊匹配的时候,也就是 like %xx 或者 like %xx%这两种方式都会造成索引失效;
当我们在查询条件中对索引列使用函数,就会导致索引失效。
当我们在查询条件中对索引列进行表达式计算,也是无法走索引的。
MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。如果字符串是索引列,而条件语句中的输入参数是数字的话,那么索引列会发生隐式类型转换,由于隐式类型转换是通过 CAST 函数实现的,等同于对索引列使用了函数,所以就会导致索引失效。
联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
10. mysql Explain 执行计划中 key 和possible_key的区别是什么?
explain 是查看 sql 的执行计划,主要用来分析 sql 语句的执行过程,比如有没有走索引,有没有外部排序,有没有索引覆盖等等。
如下图,就是一个没有使用索引,并且是一个全表扫描的查询语句。

对于执行计划,比较重要的参数有:
possible_keys 字段表示可能用到的索引;
key 字段表示实际用的索引,它是从
possible_keys所列出的索引中挑选出来的,如果这一项为 NULL,说明没有使用索引;key_len 表示索引的长度;
rows 表示扫描的数据行数。
type 表示数据扫描类型
11. 追问:那 extra中出现 Using index condition、Using filesort是为什么?
Using index condition:表示使用了索引条件下推优化,当查询条件中的部分列使用了索引,但还有其他条件无法通过索引直接过滤时,就会出现
Using index condition。数据库会先利用索引来获取满足索引条件的记录,然后再在存储引擎层根据剩余的条件对这些记录进行过滤,而不是像以前那样先把所有满足索引条件的记录都读取到服务器层,再进行过滤。例如,有一个复合索引idx_country_industry,查询语句为SELECT * FROM c WHERE country = 'Ukraine' AND industry = 'banking',如果只使用country列的索引来查询,那么就会先通过索引找到所有country为Ukraine的记录,然后在存储引擎层再根据industry = 'banking'这个条件进一步过滤,此时Extra列就会显示Using index condition,这样可以减少存储引擎和服务器层之间的数据传输,以及回表的次数,提高查询性能。Using filesort :当查询语句中包含 group by 操作,而且无法利用索引完成排序操作的时候, 这时不得不选择相应的排序算法进行,甚至可能会通过文件排序,效率是很低的,所以要避免这种问题的出现。
12. TCP四次挥手中 第三步FIN丢失,会进入什么状态?
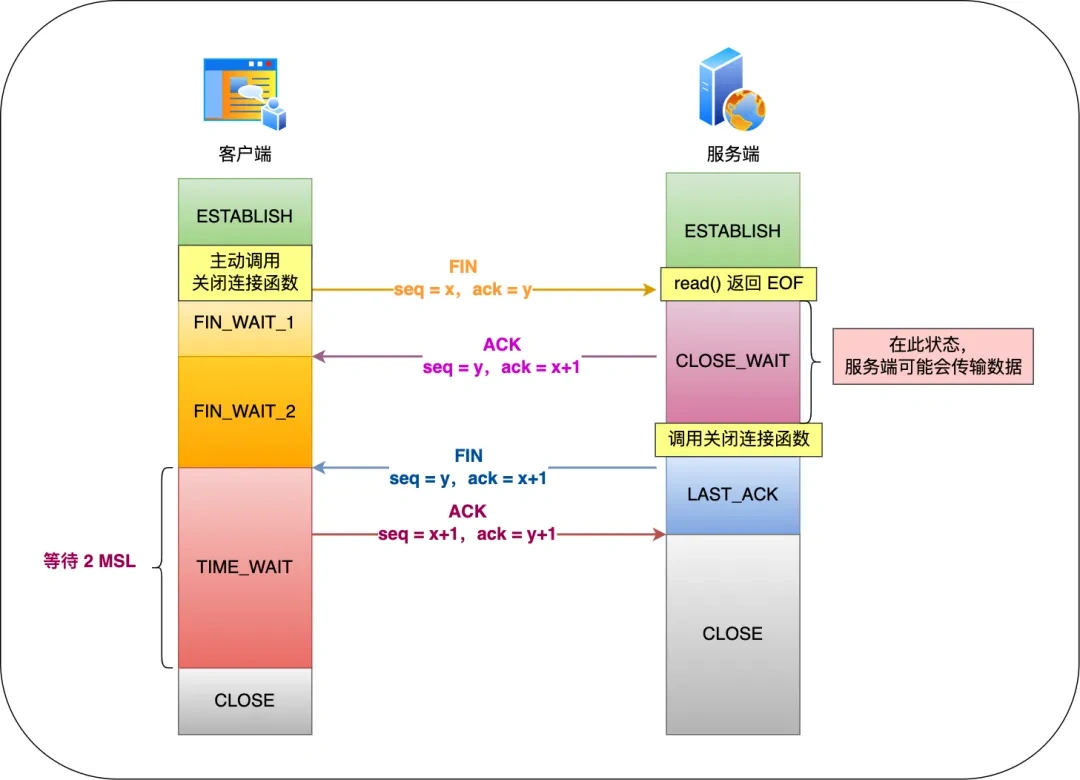
在 TCP 四次挥手中,如果第三步的 FIN 丢失,相关方会进入以下状态:
服务端(被动关闭方):服务端发送 FIN 后会进入 LAST_ACK 状态。由于 FIN 丢失,服务端收不到客户端的 ACK 确认,会触发超时重传机制,重新发送 FIN 报文,直到收到客户端的 ACK 或者达到最大重传次数。如果达到最大重传次数后仍未收到 ACK,服务端最终会进入 CLOSED 状态,释放连接资源。
客户端(主动关闭方):客户端处于 FIN_WAIT_2 状态,等待服务端的 FIN 报文。因为未收到服务端的 FIN,客户端会一直保持 FIN_WAIT_2 状态。如果客户端的应用程序没有设置超时时间,那么这个连接可能会一直处于 FIN_WAIT_2 状态,导致资源无法释放。不过,在实际应用中,通常会设置超时机制,当超过一定时间未收到服务端的 FIN 报文,客户端会认为连接出现异常,从而主动释放连接,进入 CLOSED 状态。
13. 了解哪些网络编程框架?
了解过 netty,它是基于 Java NIO 的高性能、异步事件驱动的网络应用框架,netty有以下特点:
高性能:基于 Java NIO 实现,单线程可处理万级并发连接,吞吐量达百万级 QPS。
低延迟:零拷贝技术减少内存复制,ByteBuf 动态扩展优化内存分配。
易用性:通过高度抽象的 API 屏蔽底层 NIO 细节,降低开发门槛。
协议扩展性:内置 HTTP、WebSocket、MQTT 等协议支持,支持自定义私有协议。
这是一张Netty官网关于Netty的核心架构图:
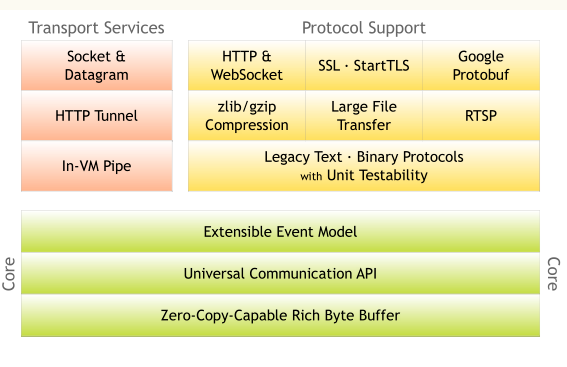
可以看到Netty由以下三个核心部分构成:
传输服务:传输服务层提供了网络传输能力的定义和实现方法。它支持 Socket、HTTP 隧道、虚拟机管道等传输方式。Netty 对 TCP、UDP 等数据传输做了抽象和封装,用户可以更聚焦在业务逻辑实现上,而不必关系底层数据传输的细节。
协议支持:Netty支持多种常见的数据传输协议,包括:HTTP、WebSocket、SSL、zlib/gzip、二进制、文本等,还支持自定义编解码实现的协议。Netty丰富的协议支持降低了开发成本,基于 Netty 我们可以快速开发 HTTP、WebSocket 等服务。
Core核心:Netty的核心,提供了底层网络通信的通用抽象和实现,包括:可扩展的事件驱动模型、通用的通信API、支持零拷贝的Buffer缓冲对象。
介绍完 Netty 的模块结构,我们再来看一下它的处理架构:
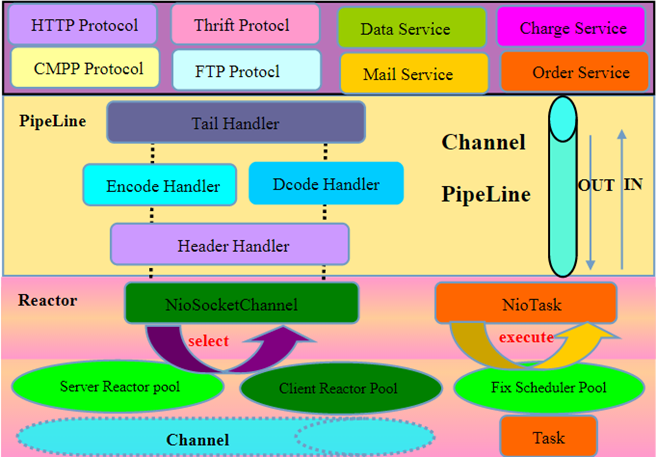
Netty 的架构也很清晰,就三层:
底层 IO 复用层,负责实现多路复用。
通用数据处理层,主要对传输层的数据在进和出两个方向进行拦截处理,如编/解码,粘包处理等。
应用实现层,开发者在使用 Netty 的时候基本就在这一层上折腾,同时 Netty 本身已经在这一层提供了一些常用的实现,如 HTTP 协议,FTP 协议等。
一般来说,数据从网络传递给 IO 复用层,IO 复用层收到数据后会将数据传递给上层进行处理,这一层会通过一系列的处理 Handler 以及应用服务对数据进行处理,然后返回给 IO 复用层,通过它再传回网络。
在 Netty 处理架构图中,可以看到在 IO 复用层上标注了一个「Reactor」:
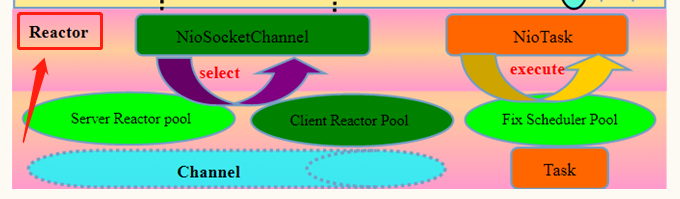
这个「Reactor」代表的就是其 IO 复用层具体的实现模式 -- Reactor 模式,Netty 主要采用了 主从 Reactor 多线程模型:
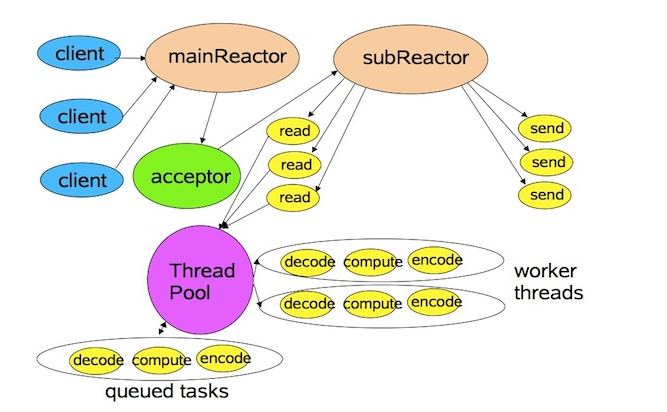
在 Reactor 模式中,分为主反应组(MainReactor)和子反应组(subReactor)以及 ThreadPool,主反应组(MainReactor)负责处理连接,连接建立完成以后由主线程对应的 acceptor 将后续的数据处理(read/write)分发给子反应组(subReactor)进行处理,而 Threadpool 对应的是业务处理线程池。
服务端处理请求流程:
Reactor主线程对象通过seletct监听连接事件,收到事件后,通过Acceptor处理连接事件
当Acceptor处理连接事件后,主Reactor线程将连接分配给子Reactor线程
Reactor子线程将连接加入连接队列进行监听,并创建handler进行各种事件处理
当有新事件发生时,子Reactor线程会调用对应的handler进行处理
handler读取数据分发给worker线程池分配一个独立的线程进行业务处理,并返回结果给handler
handler收到响应的结果后,通过send将结果返回给客户端
该模型虽然编程复杂度高,但是其优势比较明显,体现在:
主从线程职责分明,主线程只需要接收新请求,子线程完成后续的业务处理
主从线程数据交互简单,主线程只需要把新连接传给子线程