如本教程有问题,感谢大家在评论区指出。
如操作过程中遇到解决不了的问题,可以在评论区提问,作者看到了会回复。
微调简介
模型微调通过在特定任务数据集上继续训练预训练模型来进行,使得模型能够学习到与任务相关的特定领域知识。
微调步骤
- 准备数据集,数据集格式如下:
{
“instructions”: “你好”,
“input”: “”,
“output”: “你好,我是DeepseekR1模型,很高兴为您服务!”
}
instructions:这里包含的是对模型的指示或者说是任务描述,告诉模型应该做什么。
input:这是具体的输入数据,基于上面的指示(instructions),模型将根据这部分内容来生成回答或执行特定的任务。在这个例子中,input字段是空的,意味着没有特定的额外信息或数据提供给模型处理。
output:这是模型基于instructions和input生成的回答或结果。
- 模型选择
- 迁移学习:在新数据集上继续训练模型,同时保留预训练模型的知识
- 参数调整
- 模型评估:在验证集上评估模型的性能
微调的优势
显著减少所需的数据量和计算资源
环境准备
https://modelscope.cn/my/mynotebook
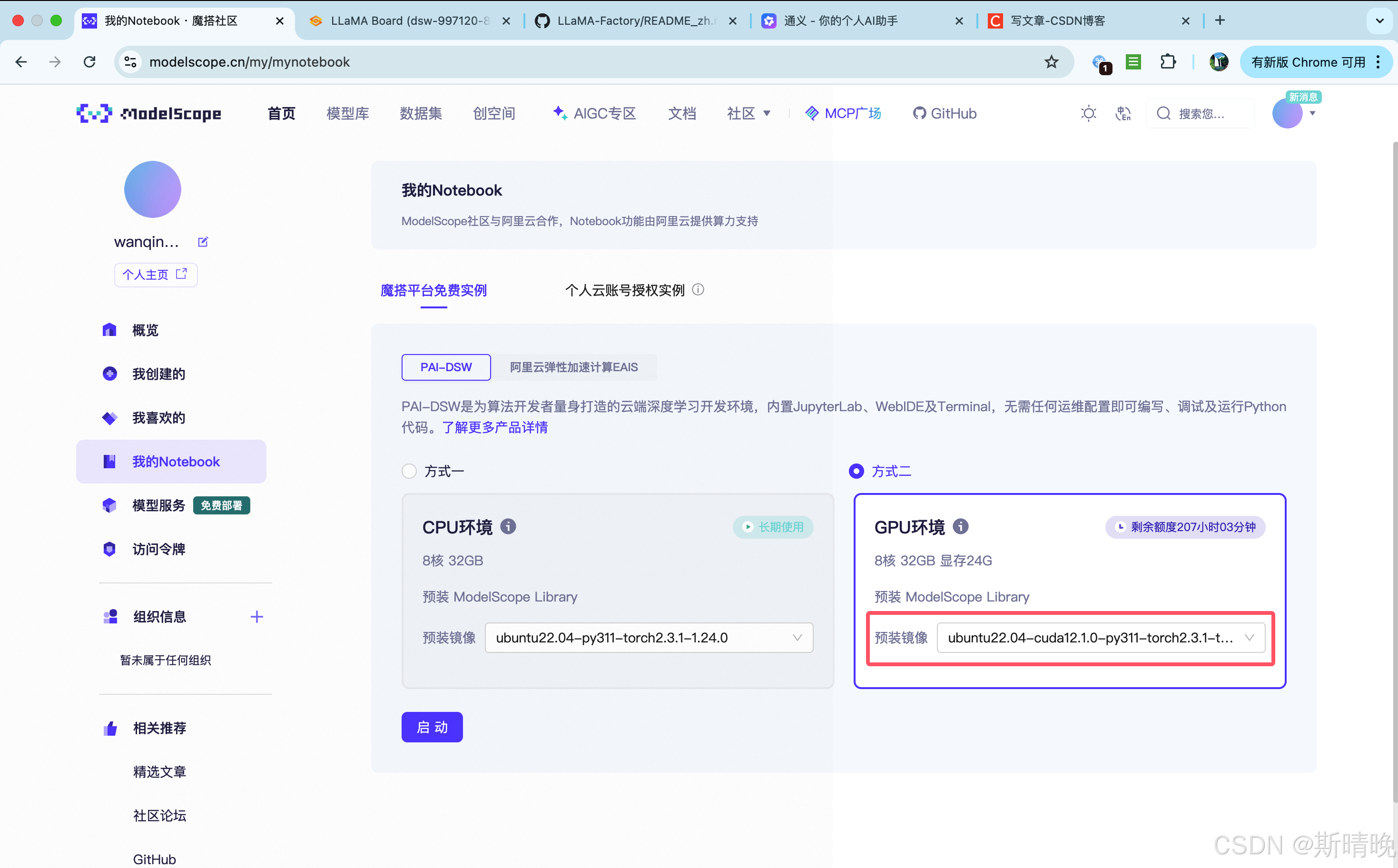
LLaMA-Factory 讲解
- 下载 LLaMA-Factory 仓库
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
- 安装
cd LLaMA-Factory
pip uninstall -y vllm
pip install -e ".[torch,metrics]"
- 若出现环境冲突,执行如下命令安装
pip install --no-deps -e .
- 检查
llamafactory-cli version
- 启动
export USE_MODELSCOPE_HUB=1 && llamafactory-cli webui
配置内网穿透
- 下载 natapp
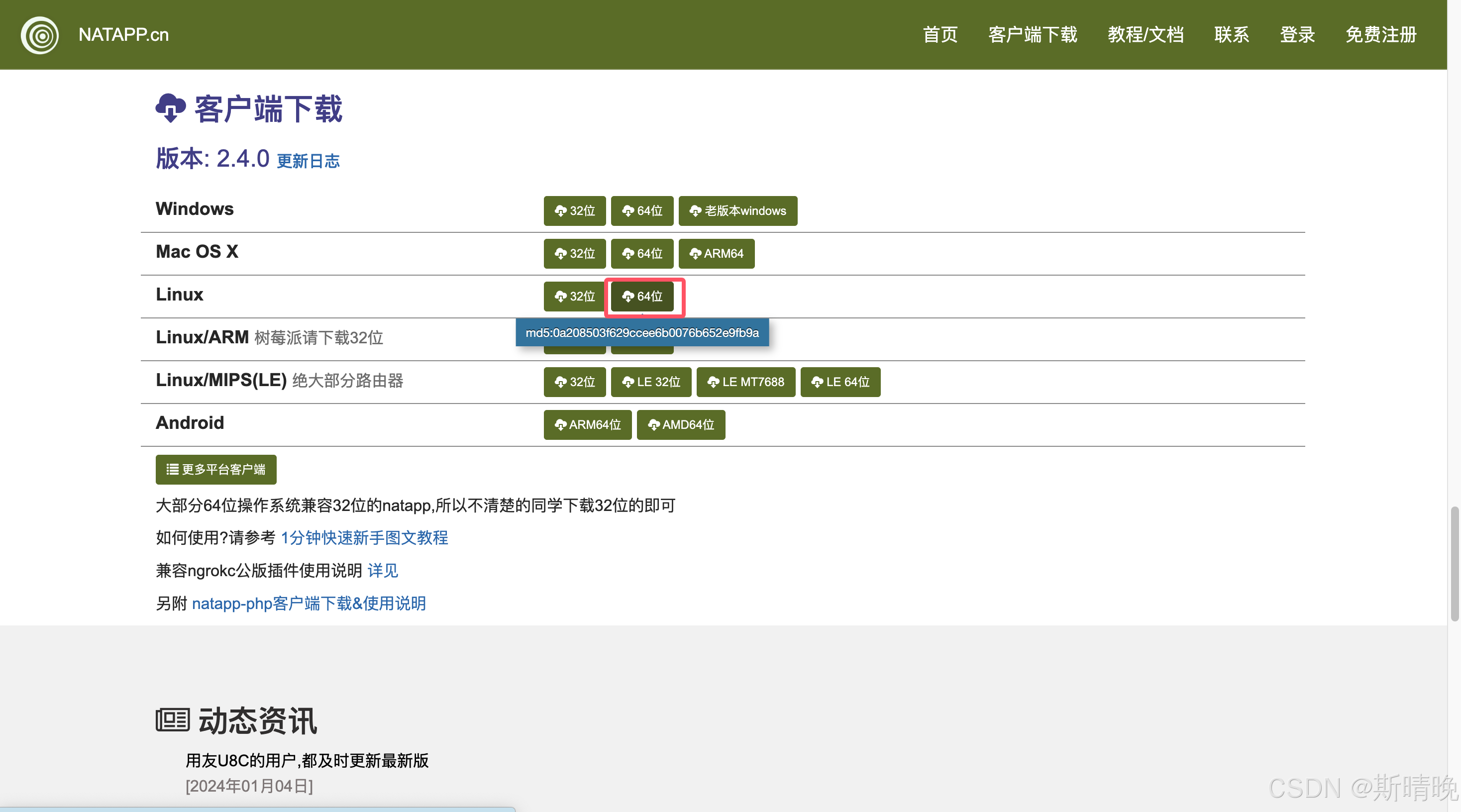
- 上传到服务器
- 配置 natapp 客户端
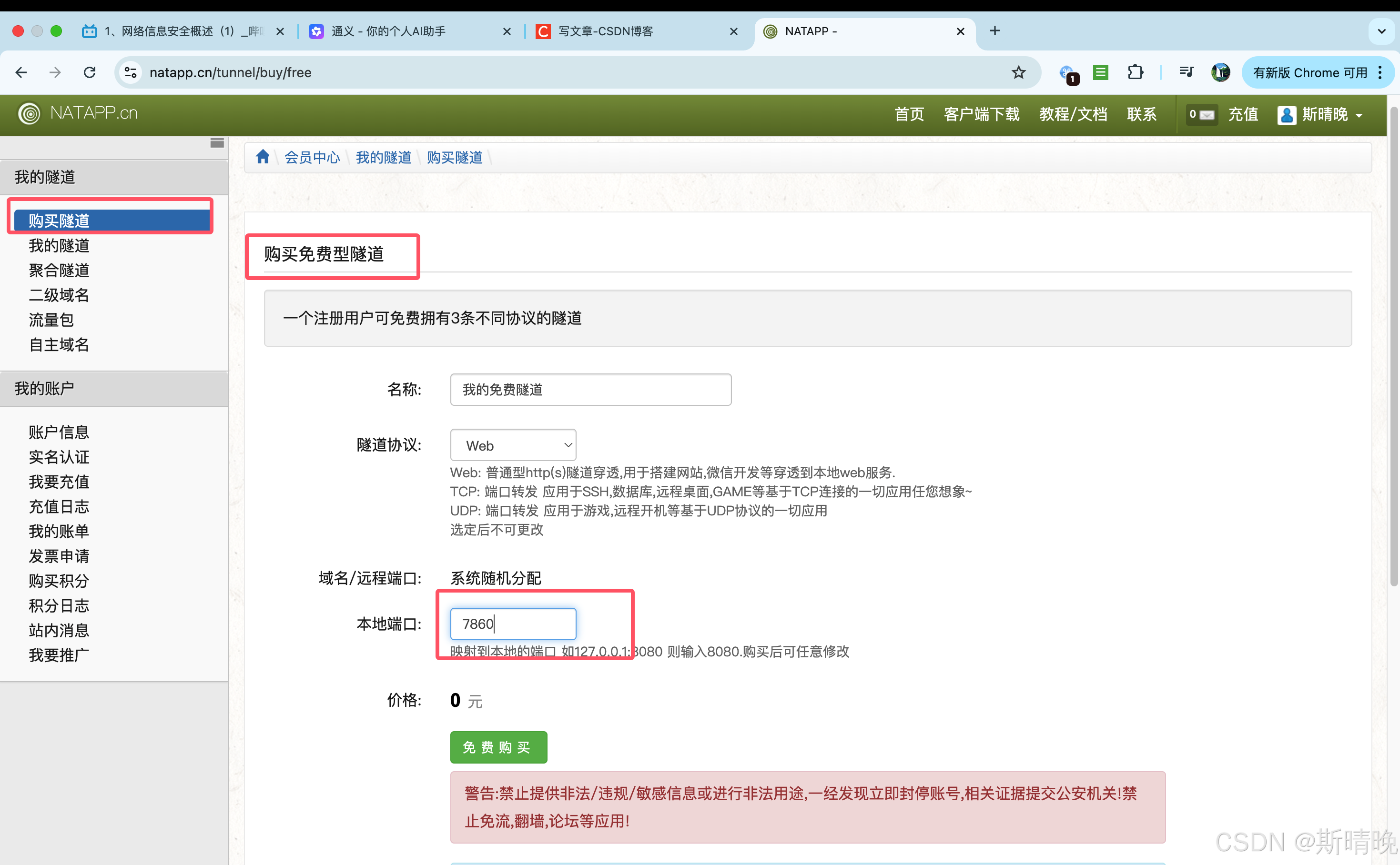
- 在服务器执行如下命令
cd natapp
chmod a+x natapp
./natapp -authtoken=
- authtoken 通过如下位置获取
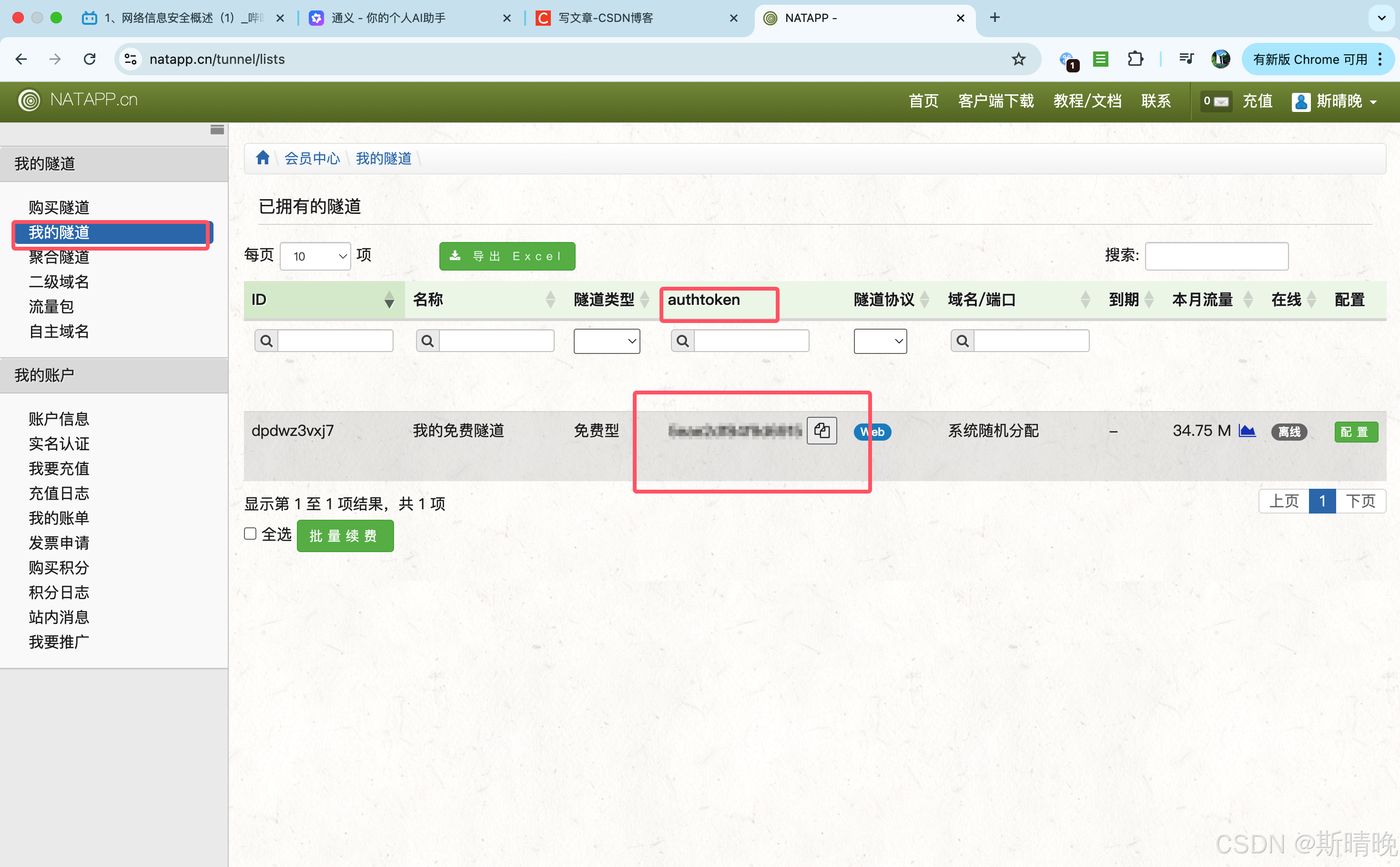
chmod 是 Change Mode 的缩写
a 表示 “all”(所有用户),包括文件的所有者(owner)、所属组(group)和其他用户(others)。
+x 表示为这些用户添加“可执行”权限(execute permission)。
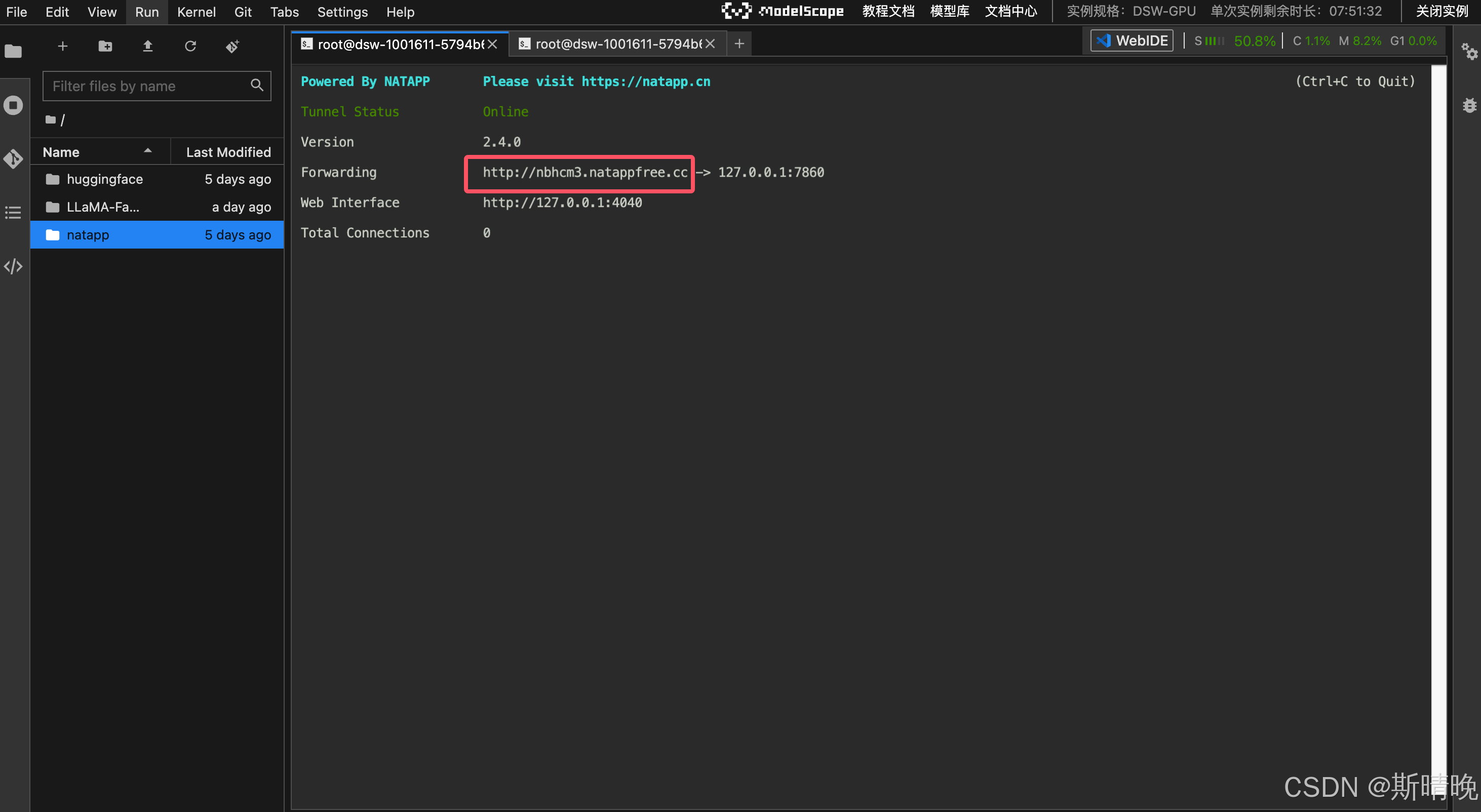
- 访问链接
- 看到如下页面
微调实践
下载模型
export HF_ENDPOINT=https://hf-mirror.com
export HF_HOME=/mnt/workspace/huggingface
echo $HF_HOME
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
llamafactory-cli webui
进入 web-ui
deepseek-r1模型位置:
/mnt/workspace/huggingface/hub/models--deepseek-ai--DeepSeek-R1-Distill-0wen-1.5B/
snapshots/ad9f0ae0864d7fbcd1cd905e3c6c5b069cc8b562
—— 下面内容大家通过 web-ui 自己探索就好了 ~~ 这里不过多截图了 ~~
训练
- 数据集准备
- LLaMA-Factory/data
- dataset_info.json 所有数据集信息,在此处添加自定义数据集
- train_data.json
- eval_data.json
- 使用 easy-dataset 构造数据集
https://github.com/ConardLi/easy-dataset/blob/main/README.zh-CN.md
导出
- 导出位置:/mnt/workspace/LLaMA-Factory/merge