👀学习参考视频
📚从生物神经元到人工神经元
- 神经元是信息处理的基本单元。
- 生物神经元:大脑中的神经元通过电信号传递信息。当一个神经元接收到足够强的信号时,它会“激活”,将信号传递给其他神经元。
- 人工神经元(感知机):模拟生物神经元,接受输入信号,通过计算决定是否激活。
- 想象神经元是一个工厂里的工作站。原材料(输入信号)被送到工作站,工人(计算过程)对原材料进行初步加工(线性计算,计算输入的加权和并加上偏置),质检员(激活函数)决定是否加工这些材料,并将成品(输出信号)传递给下一个工作站。

📚神经网络初识
神经网络是模仿人脑结构和功能的计算模型,由大量简单的人工神经元(节点)组成,通过连接权重传递和处理信息,能够学习数据中的模式和规律,广泛应用于图像识别、自然语言处理等领域。
🐇激活函数——让神经元“动起来”
激活函数决定神经元是否传递信号。常见激活函数有Sigmoid、ReLU、Tanh。它们的核心作用是引入非线性并控制信号的传递方式,让网络能学习复杂模式。

⭐️激活函数像质检员。比如:
ReLU:如果输入值小于0,直接扔掉(输出0);如果大于0,原样通过。
Sigmoid:质检员会根据输入值打分(0到1之间),比如“这个包裹有70%的概率需要特殊处理”。

激活函数套娃实现复杂线性关系的激活,理论上可以逼近任意的线性函数,但这样表示太繁琐且麻烦——用神经元表示,每套一层相当于神经元水平方向又扩展了一层,水平扩展以后,中间的就是隐藏层,起始和末端分别是输入层和输出层。

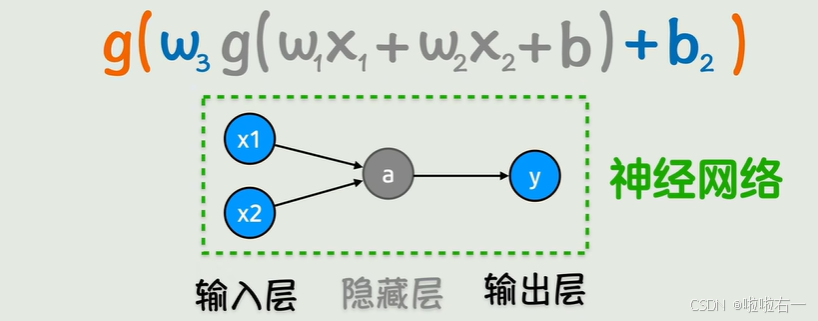
- 神经网络由输入层、隐藏层、输出层构成。
- 输入层:接收原始数据(如图像像素、文字等)。
- 隐藏层:负责提取数据的特征(如识别图像中的边缘、颜色)。
- 输出层:生成最终结果(如分类结果“猫”或“狗”)。
虽然函数可能非常复杂,但我们的目标非常简单且明确——根据已知的一组x和y的值,猜出所有的w和b都是多少。
🐇权重与偏置——调整信息的重要性
- 权重控制输入信号的影响程度,偏置调整激活阈值。
- 权重(Weights):每个输入信号乘以一个权重值,决定其重要性。权重的本质是通过线性组合放大/抑制输入信号,公式为 z = w 1 x 1 + w 2 x 2 + . . . + w n x n + b z = w_1x_1 + w_2x_2 + ... + w_nx_n + b z=w1x1+w2x2+...+wnxn+b。
- 偏置(Bias):类似“门槛”,调整神经元激活的难易程度。偏置独立于输入的常量,决定激活函数的触发难易度,公式为 输出 = f ( z ) = f ( 加权和 + b ) 输出= f(z) = f(\text{加权和} + b) 输出=f(z)=f(加权和+b)。
🐇训练神经网络——学习的过程
通过调整权重和偏置,让网络输出接近正确答案。
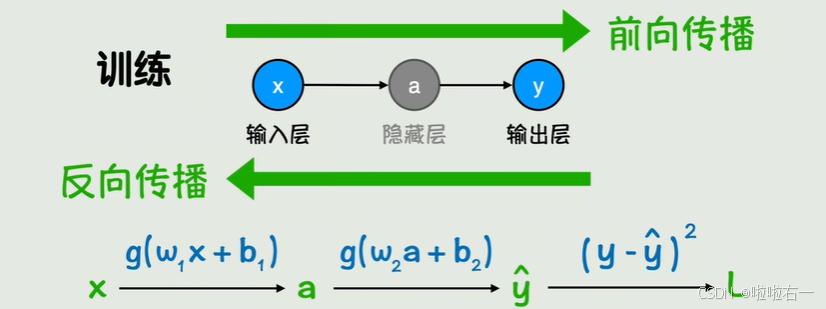
前向传播:数据从输入层流向输出层,生成预测结果。
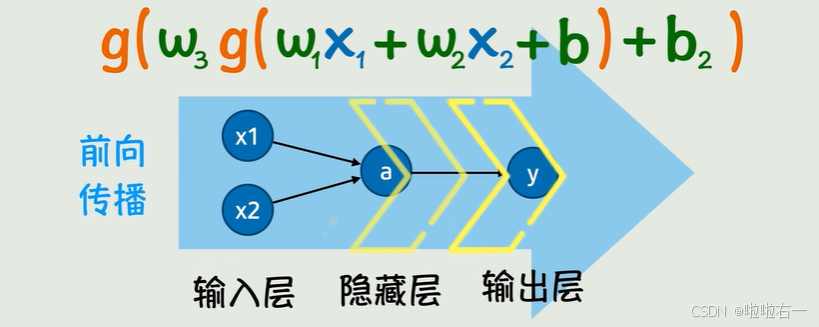
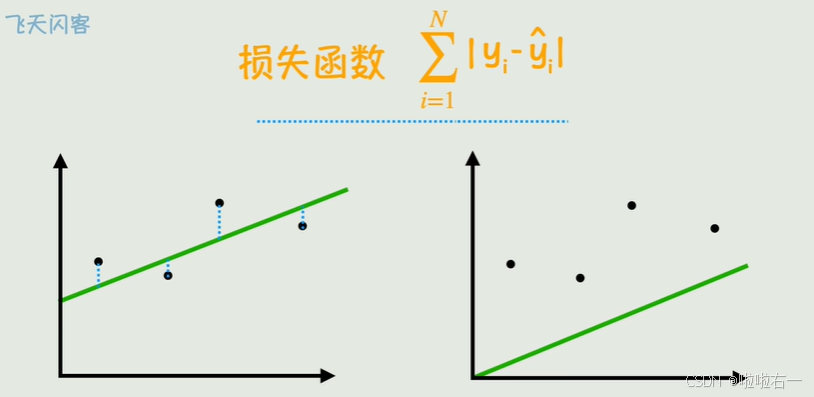
损失函数:计算预测结果与真实答案的差距,如均方误差: M S E = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 MSE= \frac{1}{N} \sum_{i=1}^{N} \left( y_i - \hat{y}_i \right)^2 MSE=N1∑i=1N(yi−y^i)2)。

反向传播:根据误差反向调整权重和偏置。
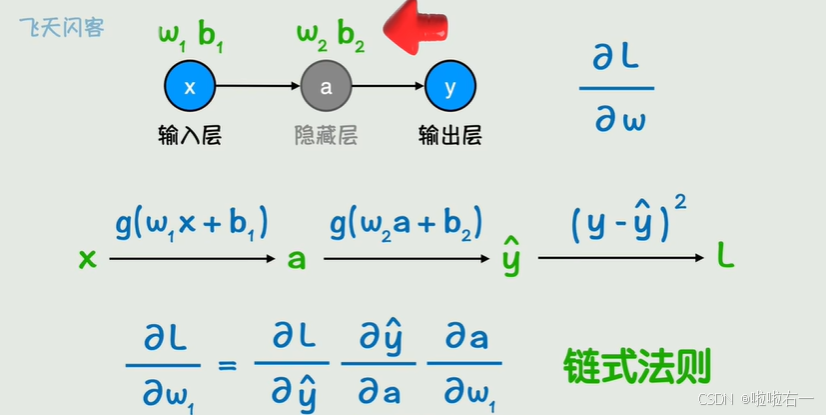
优化器(如梯度下降):决定如何调整参数。

神经网络的训练,就是一个通过错误不断自我修正的过程,和人类学习本质上是一样的。
⭐️训练神经网络像教一个新手厨师做菜:
- (前向传播)厨师按自己的菜谱(当前参数)做了一道宫保鸡丁(输出结果)→ 神经网络根据权重和偏置计算预测值。
- (损失函数)你对照标准菜谱(真实标签),逐项打分:辣度差距:-3分(少放了辣椒),甜度差距:+2分(糖放多了)→ 计算预测值与真实值的误差(如MSE)。
- (反向传播)你告诉厨师,辣椒的影响:每少放1克辣椒,辣度降低2分(梯度计算 ∂ l o s s / ∂ 辣椒 ∂loss/∂辣椒 ∂loss/∂辣椒);糖的影响:每多放1克糖,甜度增加1分(梯度计算 ∂ l o s s / ∂ 糖 ∂loss/∂糖 ∂loss/∂糖)→ 通过链式法则计算每个参数的梯度。
- (优化器)厨师根据反馈调整菜谱,普通厨师:直接按误差比例调整(SGD优化器);聪明厨师:参考上次调整的效果,避免反复震荡(Adam优化器)→ 根据梯度更新权重和偏置。
- (迭代训练)厨师重复做这道菜100次(epoch),每次调整后味道越来越接近标准→ 模型通过多次迭代最小化损失函数。
- ps:学习率 ↔ 厨师的调整幅度,如果厨师每次只敢微调0.1克盐(小学习率),学习速度慢但稳定;如果一次猛加5克盐(大学习率),可能导致味道失控(梯度爆炸)。
🐇过拟合与正则化——避免“死记硬背”
- 防止模型在训练数据上表现太好,但泛化能力差。
- 过拟合:模型记住了训练数据的细节(如噪声),但无法处理新数据,像学生死记硬背考试题,但遇到新题就懵了。
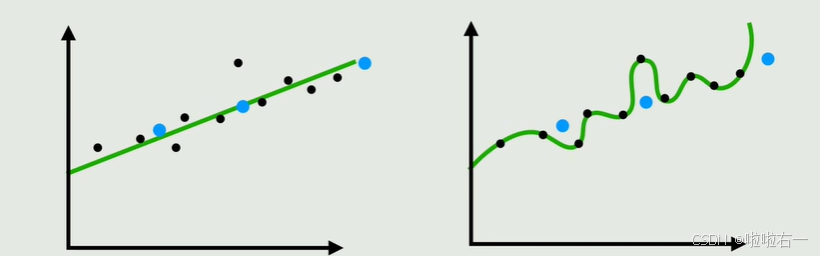
- 正则化(如L1/L2正则化、Dropout):
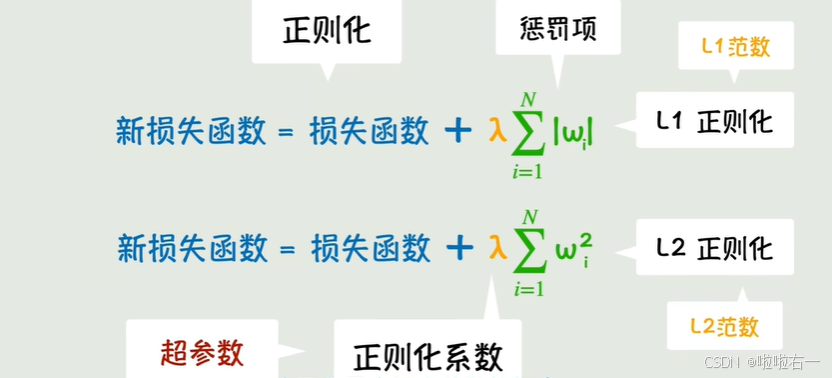
- L1/L2正则化:限制模型的复杂度。通过在损失函数中添加权重惩罚项,抑制其野蛮生长。
- Dropout:随机让一部分学生缺席复习(训练时随机忽略部分神经元)。

- L1/L2正则化:限制模型的复杂度。通过在损失函数中添加权重惩罚项,抑制其野蛮生长。