一、 背景介绍及问题概述
项目需求需要在rk3568开发板上面,通过rtsp协议拉流的形式获取摄像头预览,然后进行人脸识别 姿态识别等后续其它操作。由于rtsp协议一般使用h.264 h265视频编码格式(也叫 AVC 和 HEVC)是不能直接用于后续处理,需要先解码后获取解码后的数据,一般解码后的数据格式为:YUV420P 或者 NV12 格式,YUV420P格式转码的可以参考libyuv库 ,这边测试设备是大华摄像头解码后格式为NV12格式,所有是以NV12转码NV21(也称之为:裸码或原始数据) ,Android 手机相机预览帧就是NV21格式。
先看NV21 输出优化后的效果 55 -58秒 4秒视频,gif限制5M 仅参考效果即可

二、 RTSP 拉流基础与编码格式简述
RTSP 协议在 Android 中的应用:
RTSP 是用于控制流媒体播放的协议,Android 中常通过 FFmpeg 或 GStreamer 实现视频流的接入与播放,适用于实时监控、远程视频等场景。
H264 与 H265 编码格式区别
H265 相比 H264 压缩效率更高,支持更高分辨率的视频传输,但解码开销更大,对性能要求更高,尤其在移动端解码时容易造成卡顿。
FFmpeg 在拉流中的角色
FFmpeg 负责解析 RTSP 协议、解封装音视频流,并将其解码为原始帧数据,为后续图像处理与播放提供底层支持。
NV12
YUV420 格式,Y 分量后紧跟交错排列的 UV 分量,常用于解码输出。
NV21
YUV420 格式,Y 分量后紧跟交错排列的 VU 分量,Android 摄像头默认输出格式。
三、RTSP 拉流
网上常见Android拉流第三方库:VLC for Android / LibVLC FFmpeg / FFmpegKit / FFmpeg Android Java FFmpeg FFmpeg / FFmpegKit / FFmpeg Android Java ExoPlayer + RTSP 扩展 GStreamer for Android
简单说一下上面几个库的情况,第一个库适用快速播放,第四个库对Android支持不太友好,所以在第二和第三个之中挑选,由于也是第一次接触rtsp协议,选择简单易于集成和官方库第三个ExoPlayer + RTSP,尝试直接通过rtsp协议获取摄像头预览数据,单从播放流畅度来看,效果还是很不错的,但是由于rtsp协议获取到是压缩后的数据格式H264.H.265,并不能满足项目需求。
下面是一个 AndroidX Media ExoPlayer demo示例参考地址:AndroidX Media ExoPlayer
四、RTSP H.264、H.265 解码、转码和出现的问题
RTSP拉流之后H.264 还需要java层通过MediaCodec硬解码获取NV12,在转码格式NV21 后传入YuvImage 构造 Bitmap,再绘制到 Canvas 上这种形式效率很低,单纯解码NV12需要32毫秒左右,在转码NV21到Canvas显示更是需要100毫秒,这种就会在预览界面上看到明显的延迟。
然后感觉java层rtsp协议读取 转码确实效率比较低,哪怕是另开线程转码也不能解决效率问题。
只能想在C层处理了,那就有前面提到的FFmpeg库,但是这个开源库需要自己搭建linux/ubuntu环境编译出来so和源码,在集成到Android项目。必要时可以考虑自己编译,网上有很多教程~https://github.com/1244975831/RtmpPlayerDemo
直接找了一个比较贴近项目需求的FFmpeg解码转码nv21的项目,拉下来后运行后发现画面拉伸,卡顿掉帧严重,而且FFmpeg版本比较老旧。
下面是已经编译的 FFmpeg_Android Demo地址:RtmpPlayerDemo
五、解决卡顿掉帧 拉伸问题
优化前FFmpeg拉流源码
extern "C"
JNIEXPORT void JNICALL
Java_com_example_rtmpplaydemo_RtmpPlayer_nativeStart(JNIEnv *env, jobject) {
//开始播放
stop = false;
if (frameCallback == NULL) {
return;
}
// 读取数据包
int count = 0;
while (!stop) {
if (av_read_frame(pFormatCtx, pPacket) >= 0) {
//解码
int gotPicCount = 0;
int decode_video2_size = avcodec_decode_video2(pCodecCtx, pAvFrame, &gotPicCount,
pPacket);
LOGI("decode_video2_size = %d , gotPicCount = %d", decode_video2_size, gotPicCount);
LOGI("pAvFrame->linesize %d %d %d", pAvFrame->linesize[0], pAvFrame->linesize[1],
pCodecCtx->height);
if (gotPicCount != 0) {
count++;
sws_scale(
pImgConvertCtx,
(const uint8_t *const *) pAvFrame->data,
pAvFrame->linesize,
0,
pCodecCtx->height,
pFrameNv21->data,
pFrameNv21->linesize);
//获取数据大小 宽高等数据
int dataSize = pCodecCtx->height * (pAvFrame->linesize[0] + pAvFrame->linesize[1]);
LOGI("pAvFrame->linesize %d %d %d %d", pAvFrame->linesize[0],
pAvFrame->linesize[1], pCodecCtx->height, dataSize);
jbyteArray data = env->NewByteArray(dataSize);
env->SetByteArrayRegion(data, 0, dataSize,
reinterpret_cast<const jbyte *>(v_out_buffer));
// onFrameAvailable 回调
jclass clazz = env->GetObjectClass(frameCallback);
jmethodID onFrameAvailableId = env->GetMethodID(clazz, "onFrameAvailable", "([B)V");
env->CallVoidMethod(frameCallback, onFrameAvailableId, data);
env->DeleteLocalRef(clazz);
env->DeleteLocalRef(data);
}
}
av_packet_unref(pPacket);
}
}优化后FFmpeg拉流源码
extern "C"
JNIEXPORT void JNICALL
Java_com_natives_lib_RtmpPlayer_nativeStart(JNIEnv *, jobject) {
isPlaying = true;
// 启动解码和渲染线程
pthread_create(&decodeThread, nullptr, decodeFunc, nullptr);
pthread_create(&renderThread, nullptr, renderFunc, nullptr);
AVRational timeBase = formatCtx->streams[0]->time_base;
while (isPlaying && av_read_frame(formatCtx, packet) >= 0) {
if (packet->stream_index != 0) {
av_packet_unref(packet);
continue;
}
AVPacket *pktCopy = av_packet_alloc();
if (!pktCopy) {
av_packet_unref(packet);
continue;
}
av_packet_ref(pktCopy, packet);
// 使用 packet->pts 或 dts(回退方案),并转换为微秒
int64_t pts = (packet->pts != AV_NOPTS_VALUE) ? packet->pts : packet->dts;
if (pts == AV_NOPTS_VALUE) {
// 最后兜底:使用系统时间(非推荐)
pts = av_gettime();
} else {
pts = av_rescale_q(pts, timeBase, {1, 1000000}); // 转换为微秒单位
}
pktCopy->pts = pts;
// 清理队列中过期帧
{
std::unique_lock<std::mutex> lock(queueMutex);
while (!packetQueue.empty()) {
AVPacket *front = packetQueue.front();
int64_t frontPts = front->pts;
if (av_gettime() - frontPts > MAX_QUEUE_TIME * 1000000) {
av_packet_unref(front);
packetQueue.pop();
} else {
break;
}
}
// 判断是否可入队(关键帧优先)
if ((packet->flags & AV_PKT_FLAG_KEY) || packetQueue.size() < MAX_QUEUE_SIZE) {
packetQueue.push(pktCopy);
queueCond.notify_one();
} else {
av_packet_unref(pktCopy); // 丢弃非关键帧
}
}
av_packet_unref(packet);
}
// 通知线程退出
isPlaying = false;
queueCond.notify_all();
pthread_join(decodeThread, nullptr);
pthread_join(renderThread, nullptr);
}
优化前:单线程处理拉流、解码、渲染,所有处理都在单线程处理,无时间戳控制,播放帧不判断时效性,可能导致延迟累积或卡顿所有帧无差别处理,avcodec_decode_video2较旧 API效率低。
优化后:使用多线程(拉流、解码、渲染分离)提升并发效率,使用 packet->pts 转换为微秒进行帧时间控制时间,增加队列管理逻辑、清理超时帧、控制最大缓存避免内存堆积,关键帧优先入队丢弃非关键帧,保障解码连续性和渲染提高播放流畅度。
注:
这边还有一个问题,在视频流分辨率在2688*1520下,在3568开发板下只有每秒9帧(输入源每秒25帧),在1920*1080分辨率下有每秒18帧,1280*720分辨率则是 每秒25帧。
市面上主流手机则不存在这种问题,在2688*1520下也可以跑满25帧。
六、cmake编译问题
一开始是在app里面直接编译so库,没有其它问题。当我把编译源码相关文件拉到本地依赖库时,就会找不到编译的so库。感觉很奇妙的问题,花了几个小时才找到原因,还是遭了熟练度的坑。
流程:新建lib库,在app里依赖lib,然后直接调用lib内的native
1.刚开始以为是so没有编译成功,但是在build里可以找到生成的so。
2 .考虑到是否生成so没有打入apk问题,所以一直找不到。但是直接依赖lib是直接合并到APK 或 AAB 中 dex和lib库的,会默认合并so库才对哇。
3.直接查看apk包内的lib库
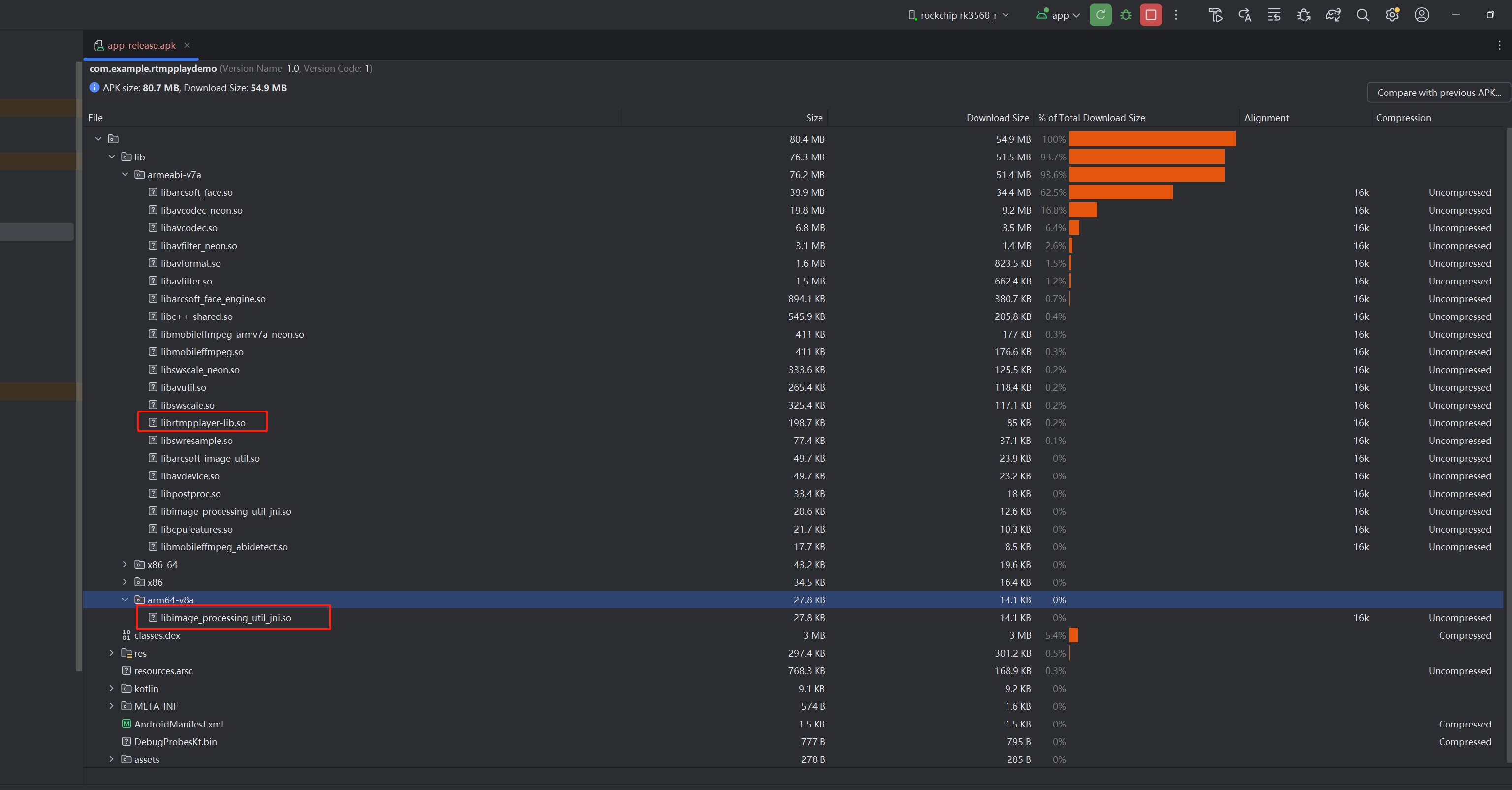
确实有cpp生成的so库,但是怎么有多出来了x86,arm64-v8a这些库呢?在lib模块里面指定了一个armeabi-v7a架构,在app里面也没有其它编译so的cmake文件。
只能猜测是在app第三方依赖库里面,然后直接把依赖库丢到gpt排查,经过测试果然是
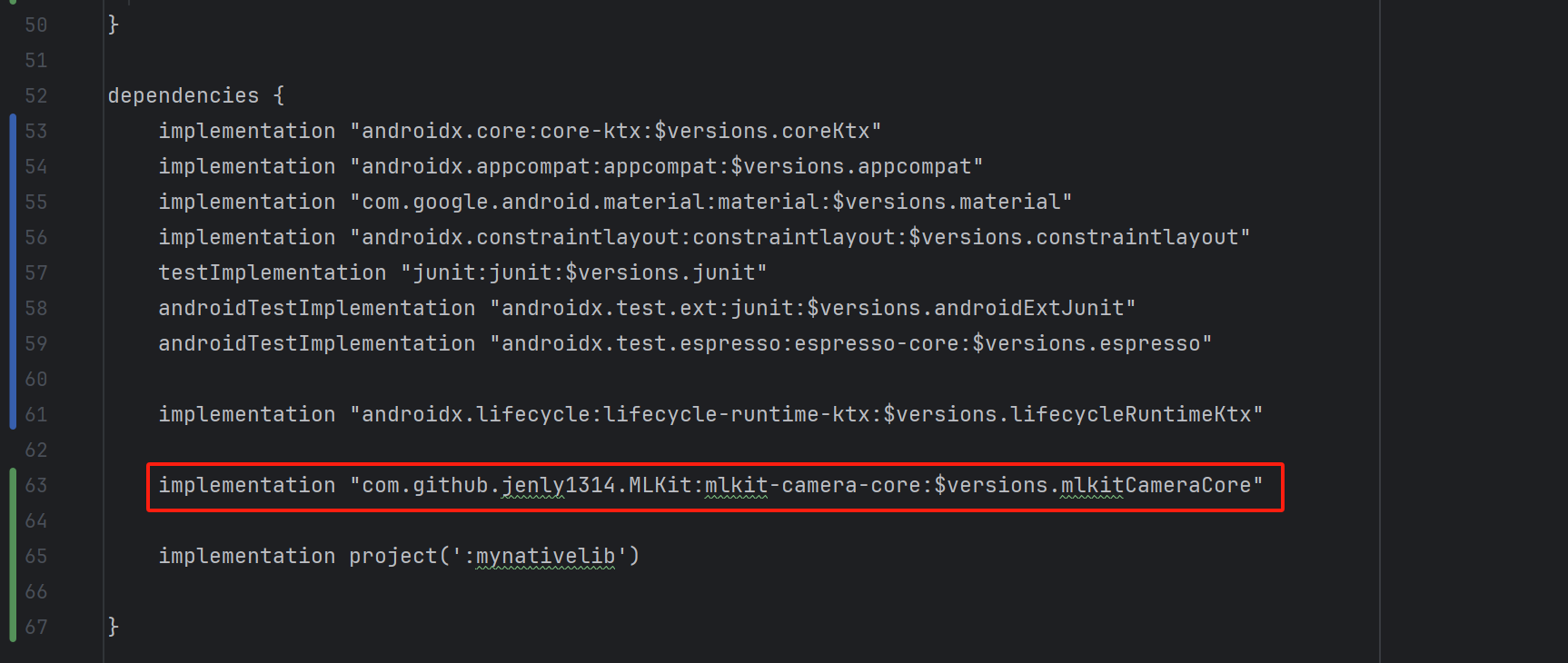
上面这个第三方依赖生成的 libimage_processing_util jni.so库
问题找到了,那就好解决了
方案一
在app内同步指定 ndk 为 armeabi-v7a 架构
方案二
去掉或替换生成多余的第三方依赖库
附demo连接: Demo