一、算力需求建模的理论基础
1.1 理论FLOPs计算模型
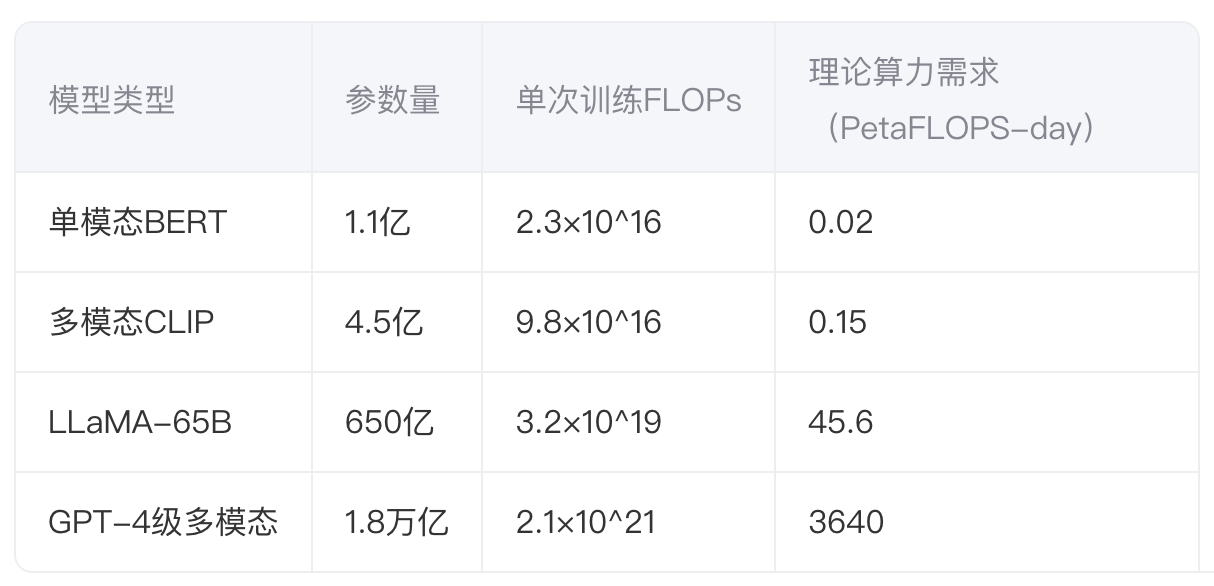
多模态大模型的算力需求可通过参数规模-计算量映射关系进行量化评估。对于包含N个参数的Transformer架构模型,其单次迭代计算量满足:

其中L为层数,h为注意力头数,d为隐层维度。该公式揭示了模型规模与计算资源的指数级增长关系
典型模型算力需求对比:
1.2 实际算力损耗因子
理论FLOPs需叠加三类现实损耗因子:
- 通信损耗:分布式训练中梯度同步产生的额外开销(通常占15-30%)
- 内存瓶颈:显存带宽不足导致的算力利用率下降(最高可达40%)
- 调度损耗:任务排队、故障恢复等非计算耗时(约5-10%)
修正后的实际算力需求公式:
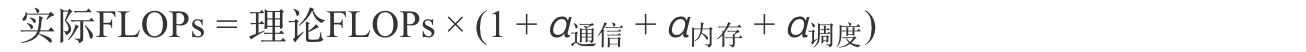
二、集群配置的工程化建模
2.1 硬件选型矩阵
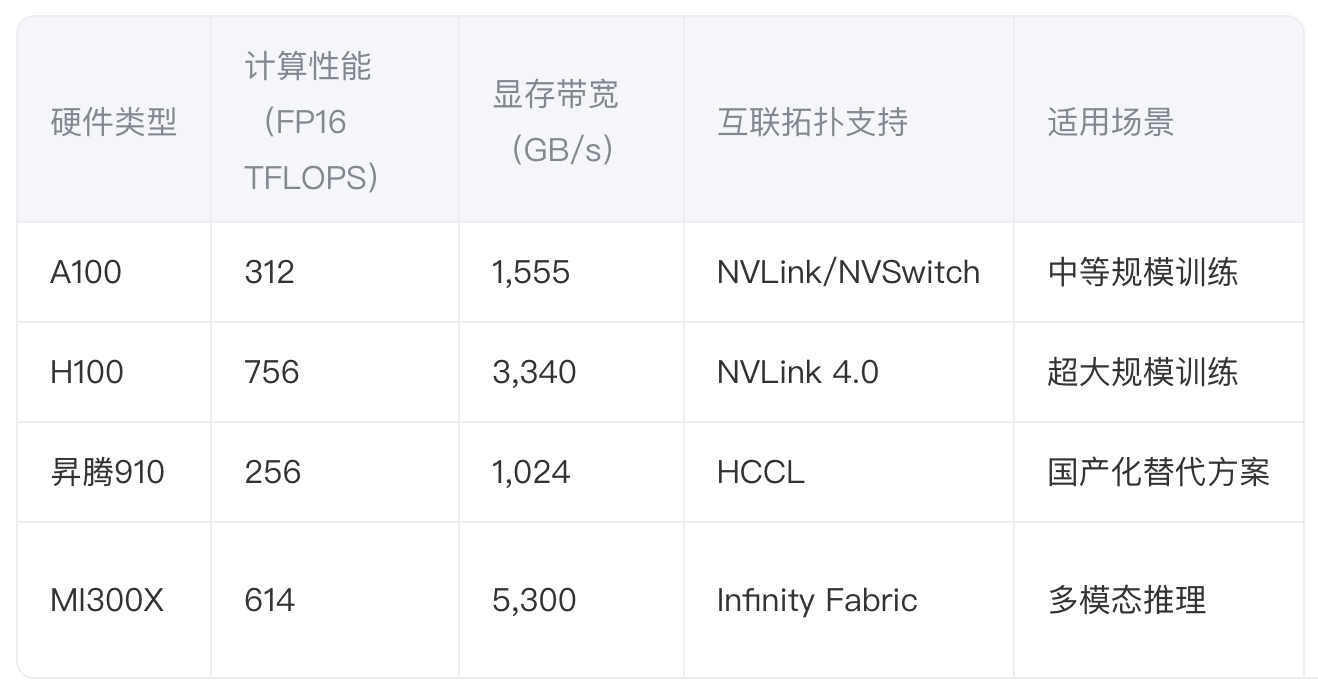
2.2 集群拓扑设计原则
- 计算岛架构:
- 单个计算岛内采用全连接拓扑(Fat-Tree)保障低延迟
- 岛间通过RDMA网络连接,带宽不低于400Gbps
- 存储分离策略:
- 分布式文件系统(如Ceph)与计算节点解耦
- 数据预处理专用节点与训练节点比例建议1:8
- 容错机制:
- 采用Checkpoint+权重复制的双保险机制
- 单节点故障恢复时间控制在5分钟以内
三、成本评估模型构建
3.1 成本构成要素

其中各分项的计算方法:
硬件折旧:

(Pi 为设备价格,T 寿命按5年计算)电力消耗:

(H100典型功耗700W,负载率85%)网络成本:
-跨区域数据传输费用按$0.05/GB计算
3.2 典型案例分析
某10万H100集群的运营成本测算:
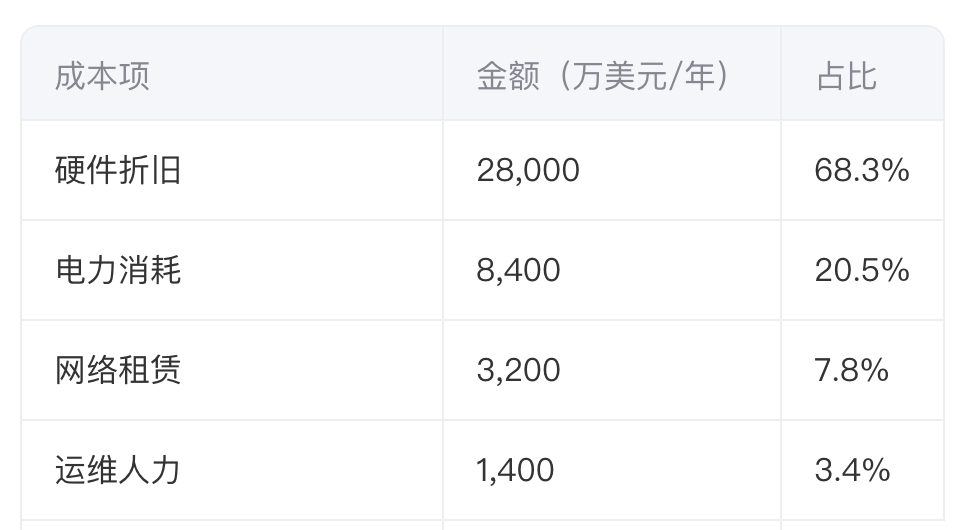
(数据来源:超大规模AI集群建设白皮书)
四、优化策略与实践建议
4.1 算力利用率提升
- 混合精度训练:
- 采用FP8+FP16混合精度策略降低显存占用40%57
- 动态损失缩放技术减少精度损失至<0.5%6
- 动态资源调度:
# 弹性资源调度算法伪代码
def schedule_resources():
while True:
load = monitor_cluster_load()
if load > 85%:
activate_standby_nodes()
elif load < 30%:
release_idle_nodes()
该策略可使集群利用率稳定在75%以上
4.2 成本控制路径

五、未来演进方向
- 量子-经典混合计算:
- 用量子退火算法加速优化器计算
- 预期减少参数更新耗时50%
- 绿色算力认证:
- 构建碳排放感知的调度系统
- 通过可再生能源采购降低碳强度
- 算力-算法协同设计:
- 开发硬件感知的NAS(神经架构搜索)工具
- 实现集群配置与模型架构的联合优化