命名空间:
C++语言是基于C语言的,融入了面向对象编程思想,有了很多有用的库,所以接下来我们将学习C++如何优化C语言的不足的。
在C/C++语言实践中,在全局作用域中变量,函数,类会有很多,这就导致总会有名称冲突,这时候C++就有命名空间的目的是对标识符的名称本地化(作用在一个新的作用域里),避免名称冲突或名字冲突。
命名空间的定义:用namespace关键字
namespace T
{
int j = 10;
int add(int i, int b)
{
return i + b;
}
struct STR
{
char a;
};
}一个命名空间就定义了一个新的作用域 。
命名空间的使用:
namespace T
{
int j = 10;
int add(int i, int b)
{
return i + b;
}
struct STR
{
char a;
};
}
using namespace T;//将整个命名空间的内容引入展开
using T::j;//使用using将指定命名空间的内容展开
int main()
{
int j = 20;
cout << j << endl;
cout << T::j << endl;//指定作用域去找,:: 是作用域限定符
}上述需要注意的是使用 using 将命名空间的内容展开之后,如果有同名变量存在在同一作用域中的话就会报错,所以一般为了安全我们一般会使用指定作用域限定符。原因:编译器在编译时寻找原则为:1.局部2.全局 3.如果指定了直接去指定域。如果说展开了命名空间,则还是遵循 1局部 2全局 3.指定就去指定找。
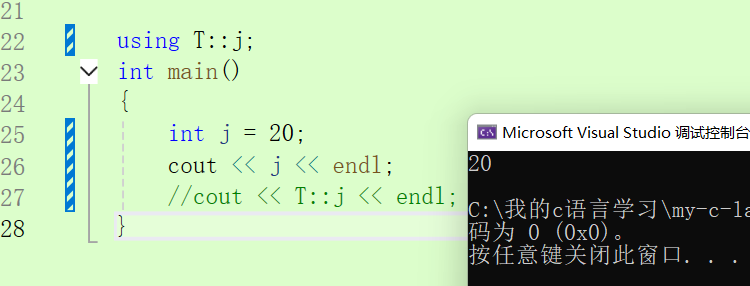
上述就是将命名空间的 j 展开了但是还是会先找局部作用域的。
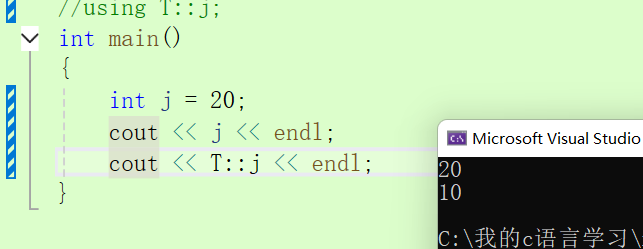
上述就是指定的找。
有时候C语言中变量名字会和库里面函数的名字冲突无法解决,C++就可以用命名空间解决,也可以解决不同程序员之间命名冲突的问题。
C++输入和输出:
#include<iostream>
using namespace std;
int main()
{
int rand = 20;
cout << rand << endl;
cin >> rand ;
cout << rand << endl;
}如图上述的代码,C++ 中一般的输入和输出 使用 cin 和 cout 包含在 #include<iostream> 头文件中,使用命名空间std。当然也可以用C语言中的,因为C++ 兼容C
这里有C++符号的复用(也叫运算符重载),<< : 1.左移操作符 2.流插入。 >> : 1.右移 2. 流提取。在C++的输入输出中比C更方便,因为会自动识别变量类型。(endl 是特殊符号表示换行相当于 “/n”)。
缺省参数:
缺省参数是声明或定义函数时为函数的参数指定一个缺省值,调用函数时如果没有实参,则使用缺省值,有实参就用实参。
//全缺省参数
void Func(int a = 10,int b = 2, int c = 3)
{
cout << a + b + c << endl;
}
int main()
{
Func();
}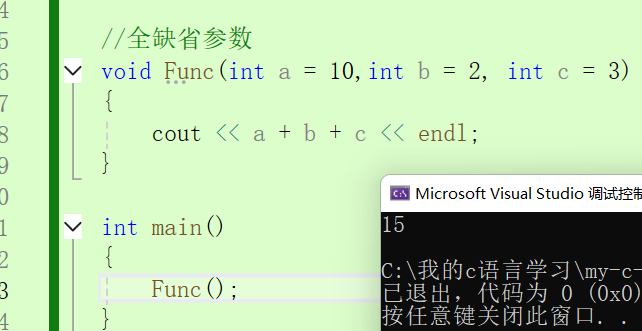 使用了缺省参数。
使用了缺省参数。
还有半缺省参数:
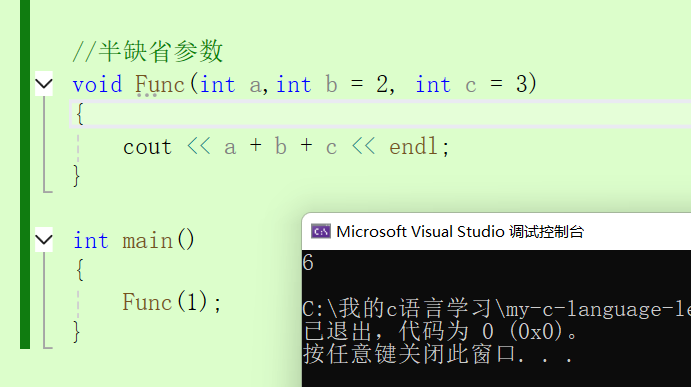
注意:1.半缺省参数只能从右往左依次来给,不能有间隔。2.缺省参数不能同时在声明和定义中同时存在。3.缺省值必须是常量活着全局变量。4. C语言不支持
函数重载:
C++允许在同一个作用域中声明几个功能类似的同名函数,这些函数的区别为他们的形参列表(参数个数,参数类型,或者类型顺序)不同。常用来解决功能类似,类型不同的函数问题。
//参数类型不同
int add(int a, int b)
{
cout << "int add(int a, int b) :" << a + b << endl;
return 0;
}
double add(double a, double b)
{
cout << "double add(double a, double b) :" << a + b << endl;
return 0;
}
//参数个数不同
void F(int i, int j)
{
cout << "void F(int i, int j) :" << i << " " << j << endl;
}
void F(int i)
{
cout << "void F(int i) :" << i << endl;
}
//参数类型顺序不同
void F(int a, char b)
{
cout << "void F(int a, char b) :" << a << " " << b << endl;
}
void F(char a, int b)
{
cout << "void F(char a, int b) :" << a << " " << b << endl;
}
int main()
{
//参数类型不同
add(10,20);
add(1.1, 2.2);
//参数个数不同
F(10, 20);
F(10);
//参数类型顺序不同
F(10, 'I');
F('I', 10);
} 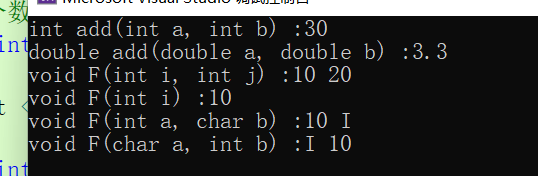
这就是函数重载。很方便。
注意:返回值不同不能构成函数重载,编译器无法识别。
为什么可以函数重载------原理:名字修饰
首先我们了解到一个程序走起来,需要四个阶段:1.预处理 2.编译 3.汇编 4.链接
在实践中,声明和定义一般是分开的,编译器编译时会拿到函数的声明这时没有定义就没有函数的地址,但是会先过掉,因为有声明在。之后就是汇编形成符号表。
最后链接时,看到调用了某个函数但是没有函数的地址,就会在其他文件的符号表中去找函数的地址,那链接器根据什么去找呢?
在C语言中:链接时,直接用函数名去找地址,如果有同名函数,编译器区分不开,就会报错。
C++支持函数重载:会有一套函数名字修饰规则,在函数名字中引入参数类型之类的填入符号表,这样子编译器寻找时就可以精确找到对应函数地址。
所以只要参数不同,修饰的名字就不同,就支持了重载。