路径问题
相对路径与绝对路径:建议使用绝对路径,避免复制粘贴导致的错误,必要时将斜杠改为双反斜杠。
数据处理与展示
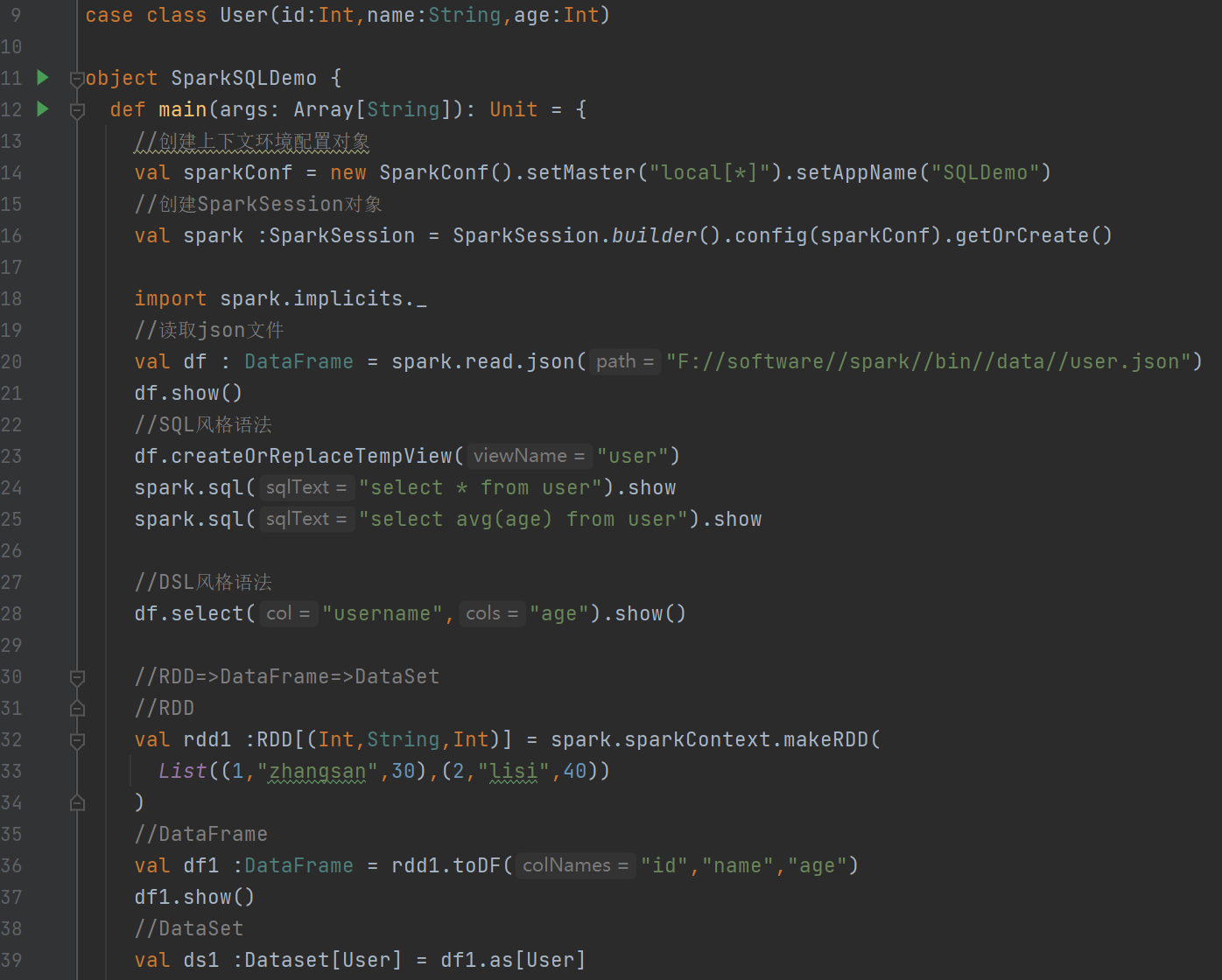
SQL 风格语法:创建临时视图并使用 SQL 风格语法查询数据。
DSL 风格语法:使用 DSL 风格语法查询 user 表中的 user name 和 age 列。
(我的博客文章 spark-SQL核心编程 目录中能找到 )
利用IDEA开发Spark-SQL
导入的包
下面的代码 (
val df : DataFrame后面的地址是自己放的文档的地址
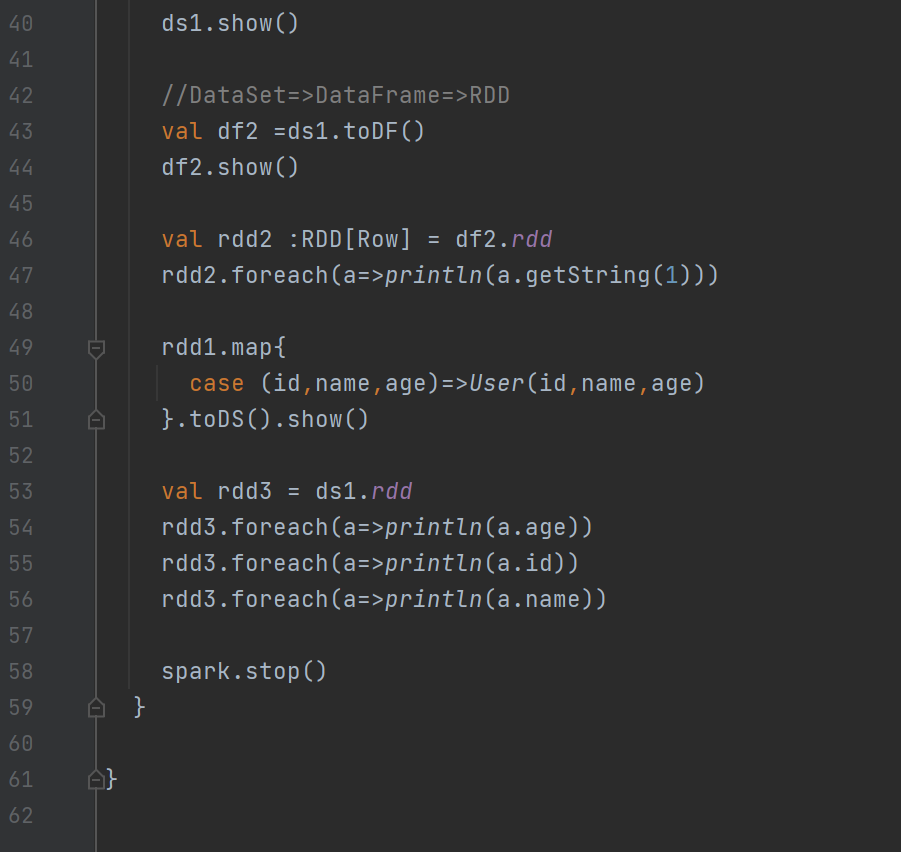
)
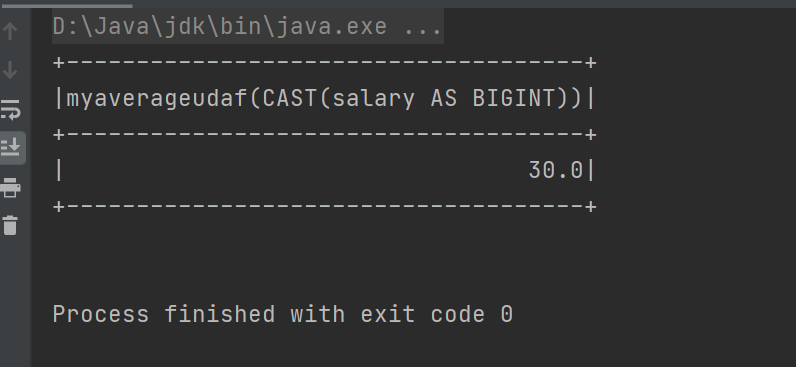
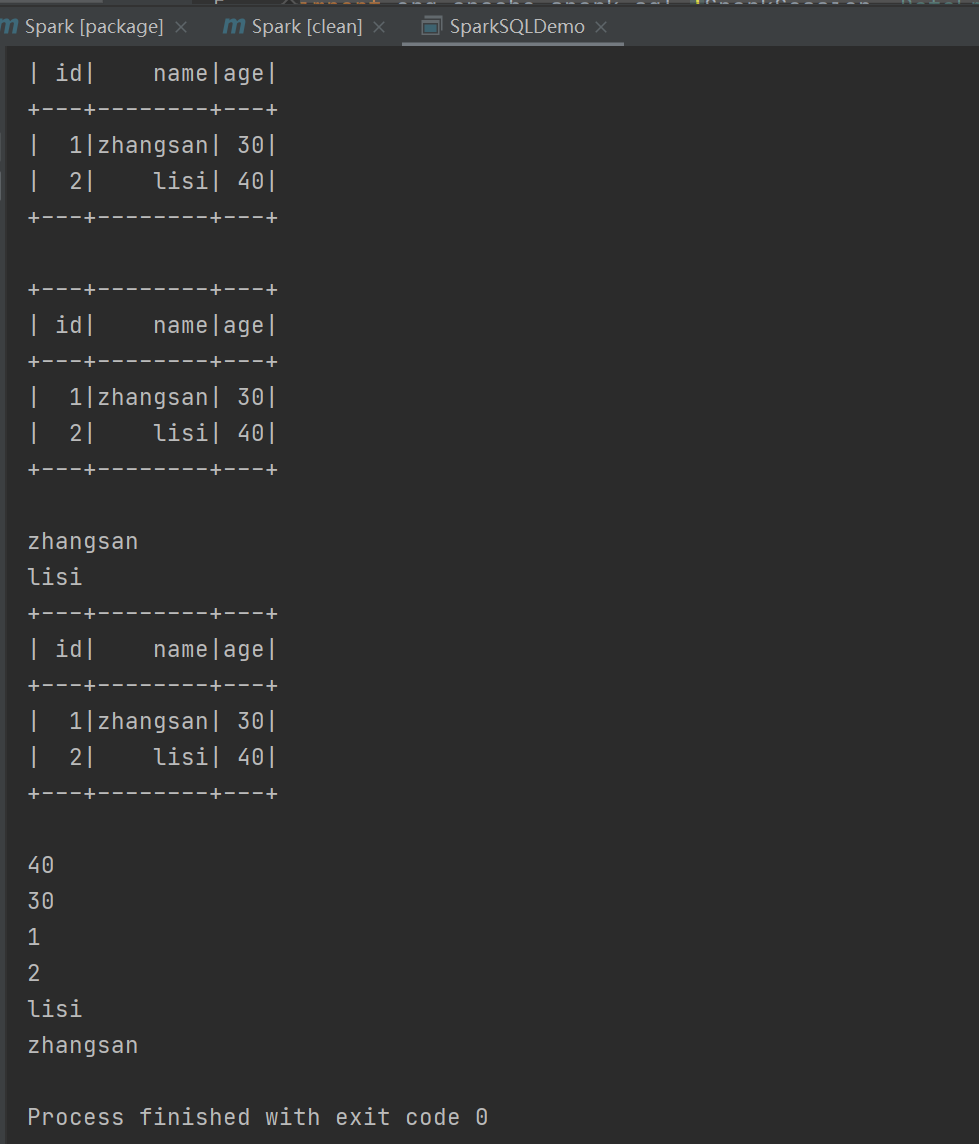
 运行结果:
运行结果:
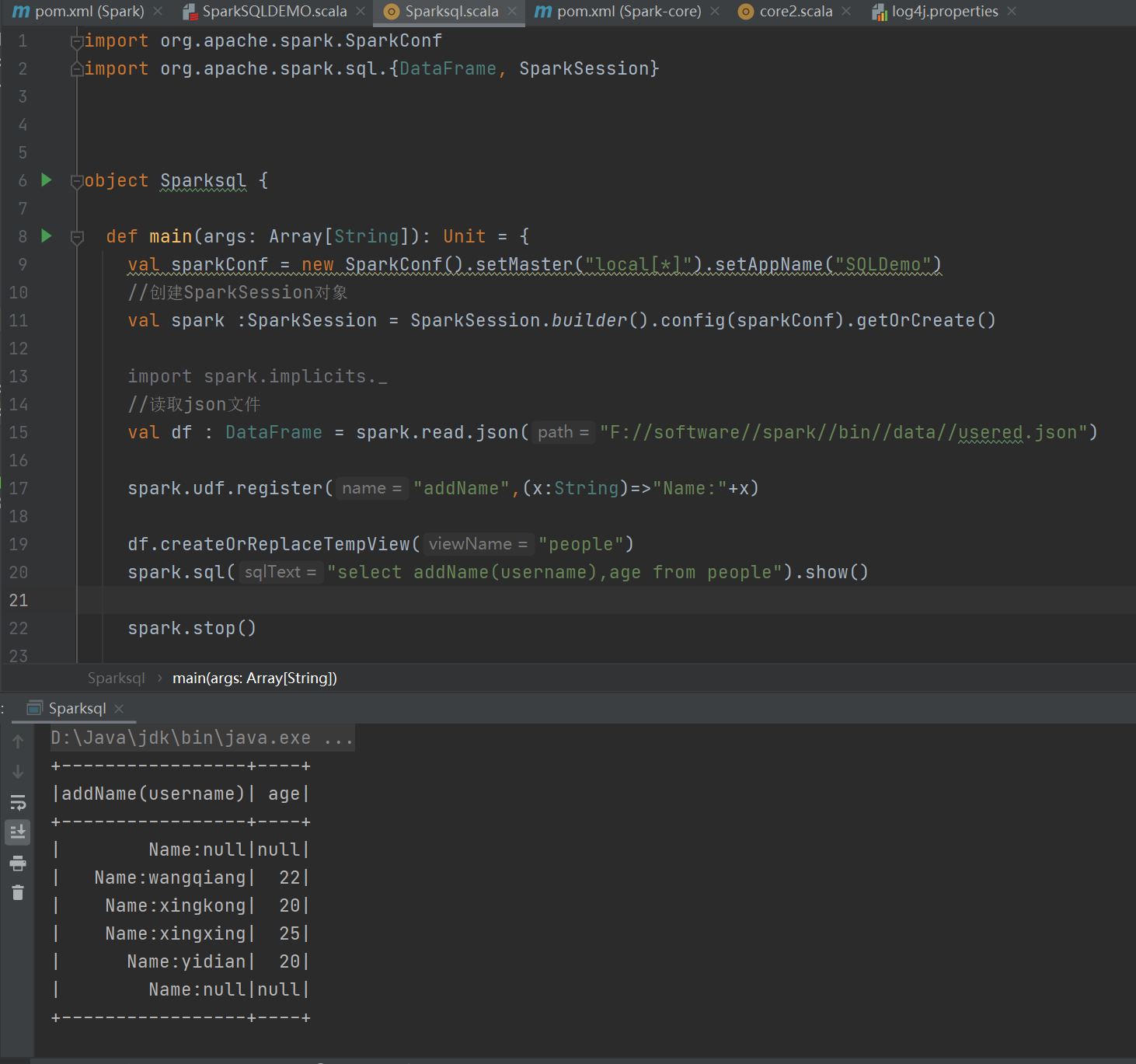
自定义函数:
UDF
UDAF(自定义聚合函数)
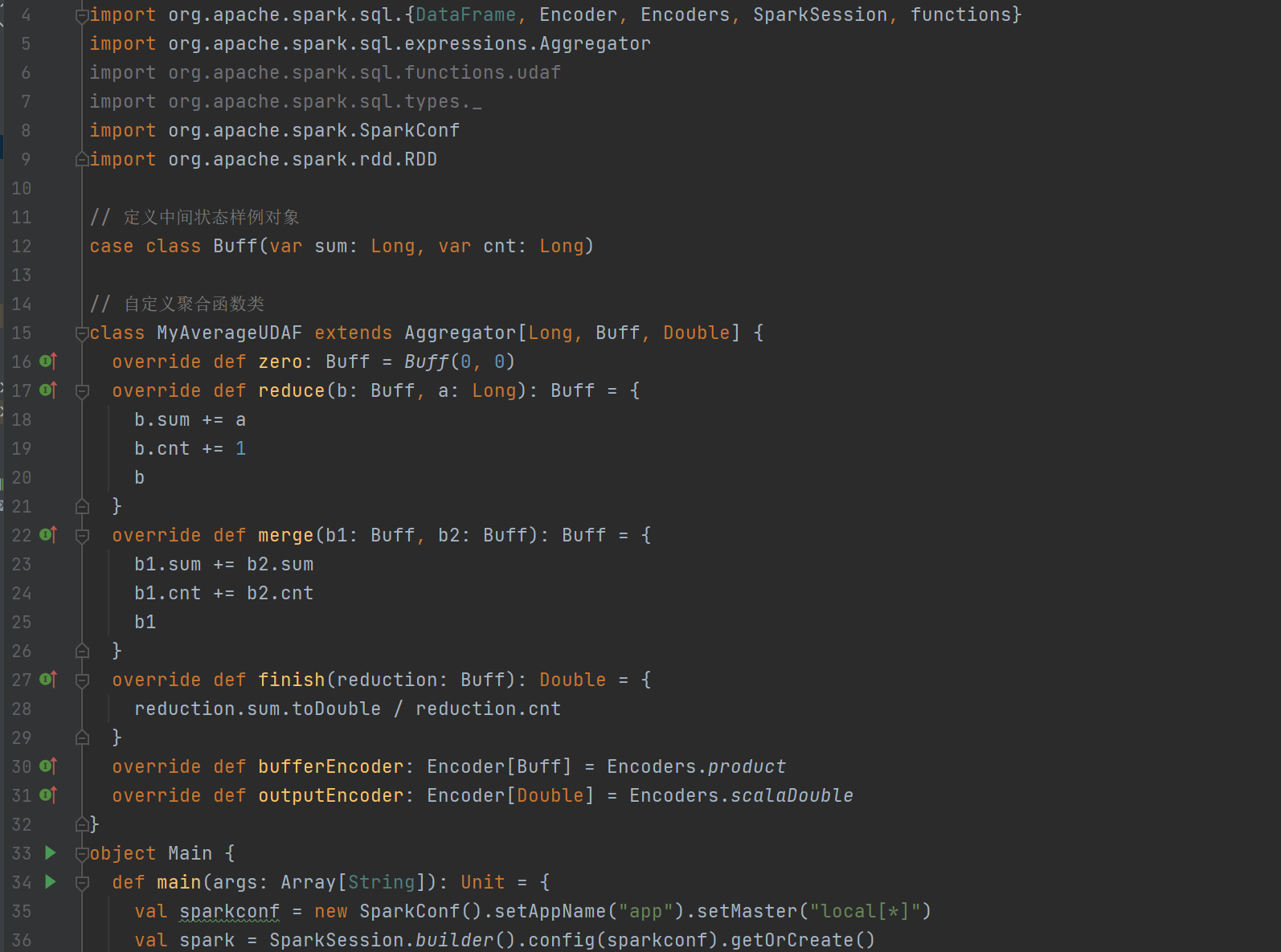
强类型的 Dataset 和弱类型的 DataFrame 都提供了相关的聚合函数, 如 count(),countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。Spark3.0之前我们使用的是UserDefinedAggregateFunction作为自定义聚合函数,从 Spark3.0 版本后可以统一采用强类型聚合函数 Aggregator
实验需求:计算平均工资
实现方式一:RDD
RDD 实现:通过 RDD 进行薪资数据的映射和聚合,计算平均工资。
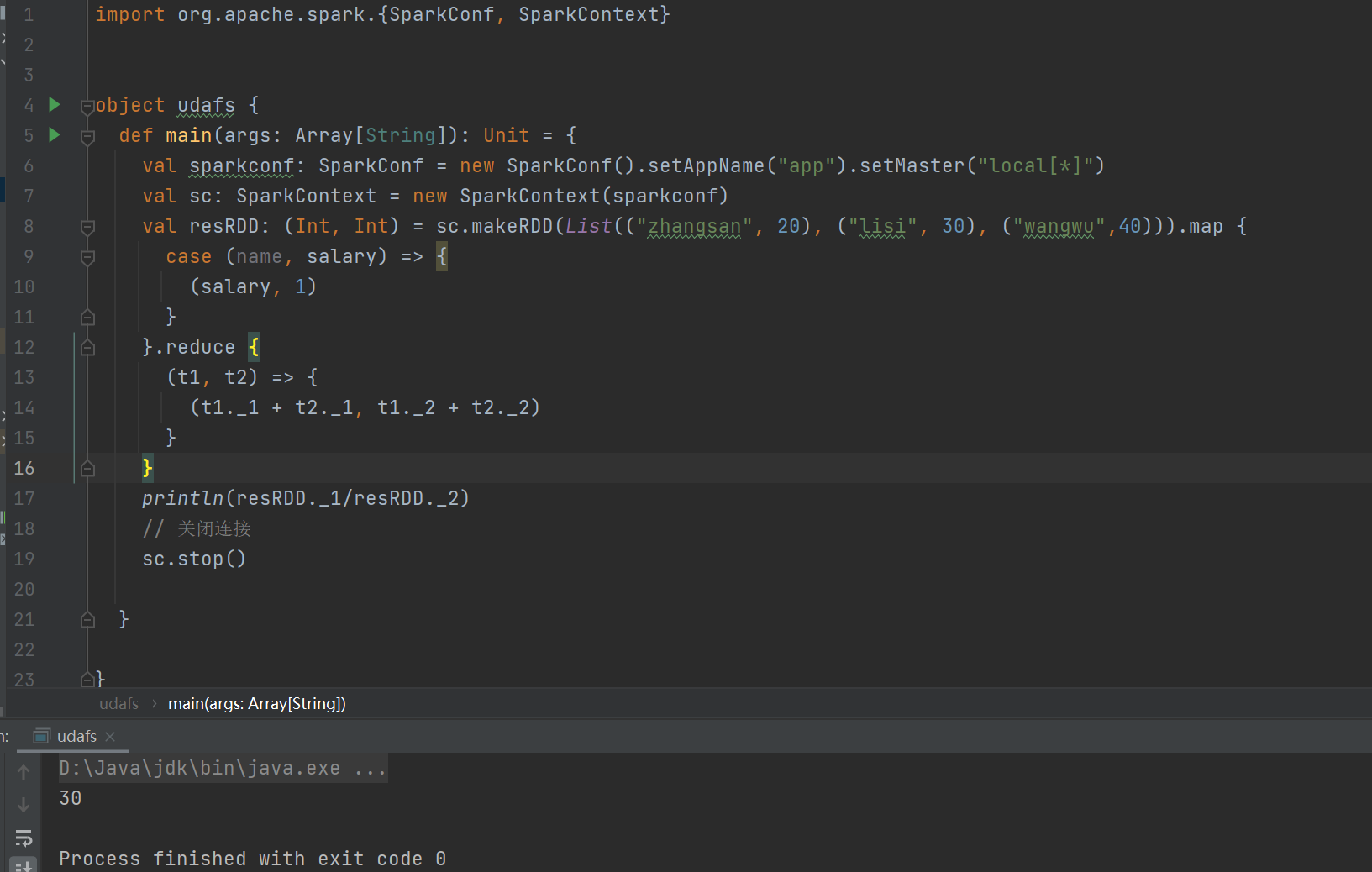
case (name, salary) => {
(salary, 1)
}
这个代码是为了弱化没有关系的东西,比如这个平均薪资中名字不重要
实现方式二:弱类型 UDAF 实现:
通过创建类和函数,封装并调用自定义聚合函数,计算平均工资。
class MyAverageUDAF extends UserDefinedAggregateFunction{
def inputSchema: StructType =
StructType(Array(StructField("salary",IntegerType)))
// 聚合函数缓冲区中值的数据类型(salary,count)
def bufferSchema: StructType = {
StructType(Array(StructField("sum",LongType),StructField("count",LongType)))
}
// 函数返回值的数据类型
def dataType: DataType = DoubleType
// 稳定性:对于相同的输入是否一直返回相同的输出。
def deterministic: Boolean = true
// 函数缓冲区初始化
def initialize(buffer: MutableAggregationBuffer): Unit = {
// 存薪资的总和
buffer(0) = 0L
// 存薪资的个数
buffer(1) = 0L
}
// 更新缓冲区中的数据
def update(buffer: MutableAggregationBuffer,input: Row): Unit = {
if (!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0) + input.getInt(0)
buffer(1) = buffer.getLong(1) + 1
}
}
// 合并缓冲区
def merge(buffer1: MutableAggregationBuffer,buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
// 计算最终结果
def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble /
buffer.getLong(1)
}
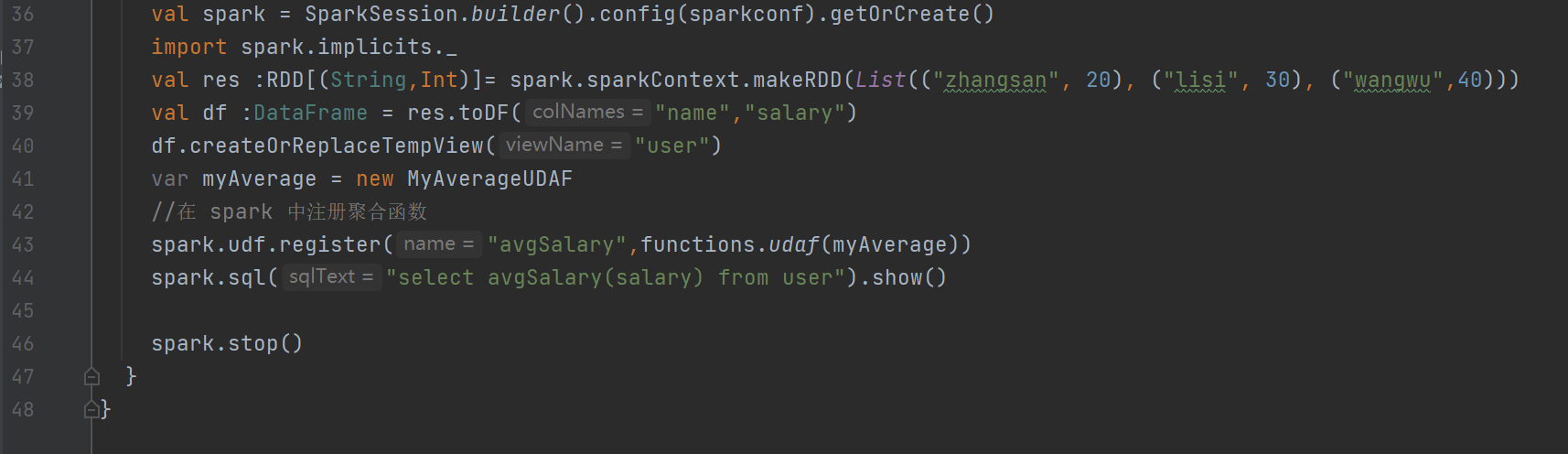
val sparkconf: SparkConf = new SparkConf().setAppName("app").setMaster("local[*]")
val spark:SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val res :RDD[(String,Int)]= spark.sparkContext.makeRDD(List(("zhangsan", 20), ("lisi", 30), ("wangwu",40)))
val df :DataFrame = res.toDF("name","salary")
df.createOrReplaceTempView("user")
var myAverage = new MyAverageUDAF
//在 spark 中注册聚合函数
spark.udf.register("avgSalary",myAverage)
spark.sql("select avgSalary(salary) from user").show()
// 关闭连接
spark.stop()
注意:
第一行带下划线的如果运用代码出现删除线,这个能用,只是提醒你有别的最新的法
实现方式三:强类型UDAF