本期关键词:Conditional DDPM、Class Embedding、Label Control、CIFAR-10 条件生成
什么是条件生成(Conditional Generation)?
在标准的 DDPM 中,我们只是“随机生成”图像。
如果我想让模型生成「小狗」怎么办?
这就要给模型添加“引导”——标签或文字,这种方式就叫 条件生成(Conditional Generation)。
条件扩散的原理是什么?
我们要将类别信息 y 加入到模型中,使预测的噪声满足条件:
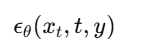
也就是说,模型要知道当前是“第几类”的图像,从而引导去噪方向。
实现思路:
将标签
y进行嵌入(embedding);将其与时间步编码、图像特征一起送入网络中。
修改 UNet 支持条件标签
我们对 UNet 加一点“料”——标签 embedding。
class ConditionalUNet(nn.Module):
def __init__(self, num_classes, time_dim=256):
super().__init__()
self.time_embed = nn.Sequential(
SinusoidalPositionEmbeddings(time_dim),
nn.Linear(time_dim, time_dim),
nn.ReLU()
)
self.label_embed = nn.Embedding(num_classes, time_dim)
self.conv0 = nn.Conv2d(3, 64, 3, padding=1)
self.down1 = Block(64, 128, time_dim)
self.down2 = Block(128, 256, time_dim)
self.bot = Block(256, 256, time_dim)
self.up1 = Block(512, 128, time_dim)
self.up2 = Block(256, 64, time_dim)
self.final = nn.Conv2d(64, 3, 1)
def forward(self, x, t, y):
t_embed = self.time_embed(t)
y_embed = self.label_embed(y)
cond = t_embed + y_embed # 条件融合
x0 = self.conv0(x)
x1 = self.down1(x0, cond)
x2 = self.down2(x1, cond)
x3 = self.bot(x2, cond)
x = self.up1(torch.cat([x3, x2], 1), cond)
x = self.up2(torch.cat([x, x1], 1), cond)
return self.final(x)
我们为标签添加了一个 nn.Embedding,并与时间编码相加作为“条件向量”注入。
修改训练函数支持 label
def get_conditional_loss(model, x_0, t, y):
noise = torch.randn_like(x_0)
x_t = q_sample(x_0, t, noise)
pred = model(x_t, t, y)
return F.mse_loss(pred, noise)
训练主循环如下:
for epoch in range(epochs):
for x, y in dataloader:
x = x.to(device)
y = y.to(device)
t = torch.randint(0, T, (x.size(0),), device=device).long()
loss = get_conditional_loss(model, x, t, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
条件生成代码:指定类别生成图像!
@torch.no_grad()
def sample_with_labels(model, label, num_samples=16, img_size=32, device='cuda'):
model.eval()
x = torch.randn(num_samples, 3, img_size, img_size).to(device)
y = torch.tensor([label] * num_samples).to(device)
for i in reversed(range(T)):
t = torch.full((num_samples,), i, device=device, dtype=torch.long)
noise_pred = model(x, t, y)
alpha = alphas_cumprod[t][:, None, None, None]
sqrt_alpha = torch.sqrt(alpha)
sqrt_one_minus_alpha = torch.sqrt(1 - alpha)
x_0_pred = (x - sqrt_one_minus_alpha * noise_pred) / sqrt_alpha
x_0_pred = x_0_pred.clamp(-1, 1)
if i > 0:
noise = torch.randn_like(x)
beta_t = betas[t][:, None, None, None]
x = sqrt_alpha * x_0_pred + torch.sqrt(beta_t) * noise
else:
x = x_0_pred
return x
可视化指定类别的生成图像
samples = sample_with_labels(model, label=3, num_samples=16) # e.g., cat
samples = (samples.clamp(-1, 1) + 1) / 2
grid = torchvision.utils.make_grid(samples, nrow=4)
plt.figure(figsize=(6, 6))
plt.imshow(grid.permute(1, 2, 0).cpu().numpy())
plt.axis('off')
plt.title("Generated Class 3 (Cat)")
plt.show()
CIFAR-10 类别索引(参考)
| 类别编号 | 类别名称 |
|---|---|
| 0 | airplane |
| 1 | automobile |
| 2 | bird |
| 3 | cat |
| 4 | deer |
| 5 | dog |
| 6 | frog |
| 7 | horse |
| 8 | ship |
| 9 | truck |
总结
在本期中,我们学习了如何:
✅ 在 UNet 中添加类嵌入;
✅ 修改损失函数以支持标签;
✅ 实现条件采样生成指定类别图像;
✅ 可视化生成效果。
第 9 期预告:「CLIP + Diffusion」文本条件扩散!
下一期我们将解锁 文字引导生成图像 的能力,用一句话生成图像!
“一只戴着墨镜冲浪的柴犬”将成为现实!