PyTorch 是一个基于 Python 的开源机器学习框架,由 Facebook 的 AI 研究团队(现 Meta AI)于 2016 年推出。它专为深度学习设计,但也可用于传统的机器学习任务。PyTorch 的核心优势在于灵活性、动态计算图和易用性,使其成为学术界和工业界广泛使用的工具。
PyTorch 的核心特性
动态计算图(Dynamic Computation Graph)
PyTorch 使用动态图(Define-by-Run),允许用户在运行时动态构建和修改计算图。这与 TensorFlow 早期的静态图(需先定义再执行)形成对比,使得调试模型更直观,适合快速实验和复杂模型。张量(Tensor)计算
PyTorch 的核心数据结构是torch.Tensor,类似于 NumPy 的多维数组,但支持 GPU 加速计算。通过简单的代码即可将张量移动到 GPU 上,大幅提升运算速度。自动微分(Autograd)
PyTorch 的autograd模块能自动计算梯度,无需手动实现反向传播。用户只需设置requires_grad=True,框架会自动追踪相关操作并计算梯度。神经网络模块(
torch.nn)
提供构建神经网络的预定义层(如卷积层、循环神经网络层)、损失函数(如交叉熵、均方误差)和优化器(如 SGD、Adam),简化模型搭建流程。与 Python 生态无缝集成
PyTorch 与 Python 科学计算库(如 NumPy、SciPy)兼容,可轻松与 Jupyter Notebook、Pandas 等工具结合使用。
PyTorch 的主要组件
torch
基础库,提供张量操作、数学函数和硬件加速(CPU/GPU)支持。
torch.autograd
实现自动微分,支持自定义反向传播逻辑。
torch.nn
包含神经网络层、损失函数和模型容器(如Sequential、Module)。
torch.optim
提供优化算法(如 SGD、Adam、RMSProp)用于参数更新。
torch.utils.data
数据处理工具,包括数据集加载(Dataset)和数据批处理(DataLoader)。
torchvision(扩展库)
提供计算机视觉相关的数据集(如 CIFAR-10)、模型(如 ResNet)和数据增强工具。
PyTorch 的典型应用场景
- 学术研究:动态图的灵活性使其成为论文实现和原型设计的首选。
- 生产部署:通过
TorchScript和TorchServe可将模型导出为独立于 Python 的格式,支持高性能部署。 - 自然语言处理(NLP):与 Transformers 库(如 Hugging Face)深度集成。
- 计算机视觉(CV):通过
torchvision实现图像分类、目标检测等任务。
PyTorch 的优势
- 易用性:Python 风格的 API 设计,学习曲线平缓。
- 调试友好:动态图允许使用 Python 原生调试工具(如 pdb)。
- 社区支持:活跃的社区和丰富的教程资源(如官方文档、PyTorch Lightning)。
- 跨平台:支持 Linux、Windows、macOS,并可在云平台(如 AWS、GCP)运行。
示例代码:简单神经网络
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型
class SimpleNN(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(10, 1) # 输入维度10,输出维度1
def forward(self, x):
return self.fc(x)
# 初始化模型、损失函数和优化器
model = SimpleNN()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 模拟数据
inputs = torch.randn(5, 10) # 5个样本,每个样本10维
labels = torch.randn(5, 1)
# 训练步骤
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
optimizer.zero_grad() # 清空梯度以下从多个维度深入解析其具体实现和核心机制:
1. 核心设计哲学
PyTorch 的核心理念是 “Define-by-Run”(运行时定义),即计算图在代码执行过程中动态构建。这种设计允许:
- 直观调试:可直接使用 Python 原生调试工具(如
pdb)追踪每一步计算。 - 灵活控制流:支持在模型运行时根据条件(如
if-else、循环)动态调整计算路径。 - 快速迭代:无需预先定义完整计算图,适合需要频繁修改模型结构的研究场景。
对比静态图框架(如 TensorFlow 1.x)
| 特性 | PyTorch(动态图) | TensorFlow 1.x(静态图) |
|---|---|---|
| 计算图构建时机 | 运行时动态构建 | 预先定义静态图,再执行 |
| 调试难度 | 低(直接调试 Python 代码) | 高(需使用 tf.Session) |
| 灵活性 | 高(支持动态控制流) | 低(需用 tf.cond 等特殊操作符) |
2. 关键组件与技术细节
(1) 张量(Tensor)
- GPU 加速:通过
torch.cuda模块,张量可一键转移到 GPU(tensor.to('cuda'))。 - 内存共享:通过
torch.from_numpy()创建的张量与 NumPy 数组共享内存,避免数据复制开销。 - 自动微分支持:设置
tensor.requires_grad=True后,PyTorch 自动追踪所有相关操作,构建计算图。
(2) 自动微分(Autograd)
- 计算图构建:每次张量操作会生成一个
Function节点,记录操作类型和输入输出。 - 反向传播:调用
loss.backward()时,从损失张量出发,沿计算图反向遍历,计算每个参数的梯度。 - 梯度管理:通过
optimizer.zero_grad()清空梯度,防止梯度累积。
(3) 神经网络模块(torch.nn)
- 模块化设计:所有层(如
nn.Linear)和模型均继承自nn.Module,可通过组合快速构建复杂结构。 - 参数管理:
nn.Module.parameters()自动收集所有可训练参数,便于优化器统一更新。 - 模型序列化:使用
torch.save(model.state_dict(), 'model.pth')保存模型参数,支持跨设备加载。
(4) 分布式训练
- 多GPU并行:通过
DataParallel或DistributedDataParallel实现数据并行。 - RPC 框架:支持模型并行、参数服务器等复杂分布式训练模式。
3. 工作流程详解
PyTorch 的典型使用流程分为以下步骤:
数据准备
- 使用
Dataset和DataLoader加载数据,支持并行加载和预处理。
from torch.utils.data import Dataset, DataLoader class CustomDataset(Dataset): def __len__(self): ... def __getitem__(self, idx): ... dataset = CustomDataset() dataloader = DataLoader(dataset, batch_size=32, shuffle=True)- 使用
模型定义
- 继承
nn.Module定义网络结构,并在forward方法中实现前向逻辑。
class MyModel(nn.Module): def __init__(self): super().__init__() self.layers = nn.Sequential( nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10) ) def forward(self, x): return self.layers(x)- 继承
训练循环
- 前向计算、损失计算、反向传播、参数更新。
model = MyModel() optimizer = optim.Adam(model.parameters()) criterion = nn.CrossEntropyLoss() for epoch in range(10): for inputs, labels in dataloader: outputs = model(inputs) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step()模型部署
- 通过
TorchScript导出模型为独立于 Python 的格式(.pt或.onnx),支持 C++ 或移动端部署。
scripted_model = torch.jit.script(model) scripted_model.save("model.pt")- 通过
4. 核心优势与适用场景
| 优势 | 具体表现 |
|---|---|
| 灵活性 | 动态图支持实时修改模型结构,适合研究中的快速实验(如强化学习、元学习)。 |
| 易用性 | Pythonic 的 API 设计,与 NumPy 无缝交互,降低学习门槛。 |
| 生态系统 | 丰富的扩展库(如 TorchVision、TorchText、Hugging Face Transformers)。 |
| 生产就绪 | 支持通过 TorchServe 部署模型,或导出为 ONNX 格式兼容 TensorRT 等推理引擎。 |
典型应用场景
- 学术研究:动态图特性便于实现非标准模型(如图神经网络、概率模型)。
- 工业级训练:分布式训练支持千亿参数模型的并行优化。
- 边缘计算:通过
Torch Mobile在移动端部署轻量级模型。
5. 与 TensorFlow 的对比
| 维度 | PyTorch | TensorFlow (2.x) |
|---|---|---|
| 计算图 | 动态图(即时执行模式) | 默认动态图,支持静态图(tf.function) |
| API 设计 | 更 Pythonic,面向对象 | 函数式 API 与 Keras 高层 API 并存 |
| 社区与资源 | 学术界主导,论文复现首选 | 工业界更广泛,生产部署工具链成熟 |
| 部署能力 | 需依赖 TorchScript/ONNX | 原生支持 TensorFlow Serving、TFLite |
6. 扩展工具链
- PyTorch Lightning:简化训练流程,自动化分布式训练和日志管理。
- TorchX:用于大规模作业调度的工具(如 Kubernetes 集成)。
- Captum:模型可解释性工具,支持梯度、显著性图等分析方法。
PyTorch 的官方论文和相关文献主要集中在框架设计、核心机制(如动态计算图、自动微分)以及其生态系统工具上。以下是关键论文和参考资料,适合学术引用或深入理解其技术实现:
1. PyTorch 核心论文
- 标题:PyTorch: An Imperative Style, High-Performance Deep Learning Library
作者:Adam Paszke et al. (PyTorch 核心开发团队)
会议/年份:NeurIPS 2019
链接:arXiv:1912.01703
内容:- 系统性地介绍了 PyTorch 的设计哲学(动态图、Python 优先)。
- 详细解释了张量计算、自动微分、分布式训练等核心模块的实现。
- 对比了 PyTorch 与其他框架(如 TensorFlow)的性能和灵活性。
2. 动态计算图与自动微分
- 标题:Automatic Differentiation in PyTorch
作者:Adam Paszke et al.
会议/年份:NIPS-W 2017 (Workshop)
链接:PDF
内容:- 深入解析 PyTorch 的
autograd系统如何实现动态计算图和梯度计算。 - 讨论反向传播中的梯度计算优化和内存管理策略。
- 深入解析 PyTorch 的
3. 分布式训练与优化
- 标题:PyTorch Distributed: Experiences on Accelerating Data Parallel Training
作者:Shen Li et al. (Meta/Facebook 团队)
会议/年份:VLDB 2020
链接:arXiv:2006.15704
内容:- 分析了 PyTorch 分布式训练(如
DistributedDataParallel)的设计与性能优化。 - 提供了大规模训练任务中的通信优化和容错机制。
- 分析了 PyTorch 分布式训练(如
4. PyTorch 生态系统工具
(1) TorchScript(模型部署)
- 标题:TorchScript: A Seamless Path from Eager Training to Deployable Models
作者:James Reed et al.
会议/年份:MLSys 2022
链接:MLSys 2022 Proceedings(需检索具体章节)
内容:- 讨论如何通过 TorchScript 将动态图模型转换为静态图以支持生产部署。
(2) PyTorch Lightning(训练流程简化)
- 标题:PyTorch Lightning: The Lightweight PyTorch Wrapper for High-Performance AI Research
作者:William Falcon et al.
链接:GitHub Docs
内容:- 非论文,但官方文档详细介绍了如何通过 Lightning 标准化训练流程。
5. 其他重要资源
PyTorch 官方文档
https://pytorch.org/docs/stable/index.htmlPyTorch 教程与案例
https://pytorch.org/tutorials/Meta Research 博客
https://research.facebook.com/blog/
PyTorch实战
核心模块与技术要点
1. 数据增强(Data Augmentation)
- 目标:解决数据不足问题,提升数据利用率。
- 方法:通过图像变换(如旋转、裁剪、缩放)生成多样化数据。

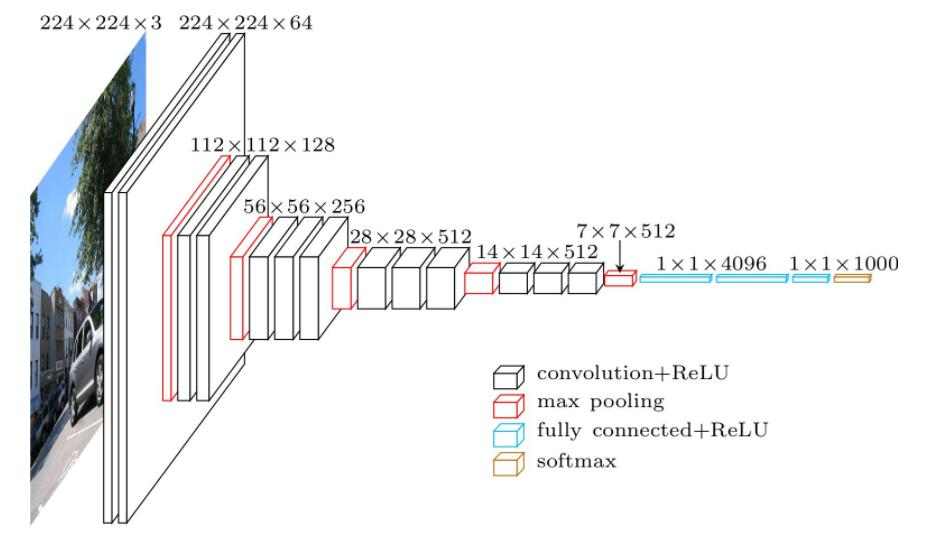
2. 迁移学习
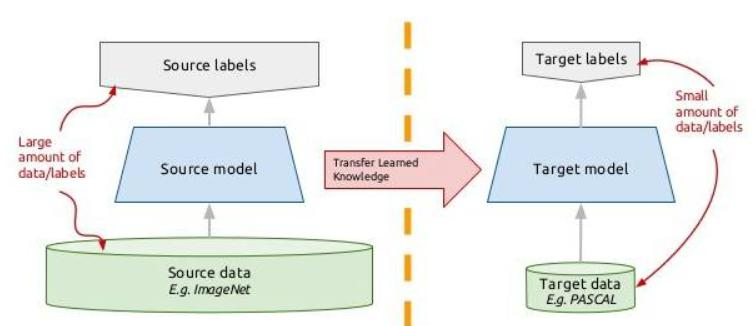
- 核心思想:复用预训练模型(如VGG)的特征提取能力。
- 关键技术:
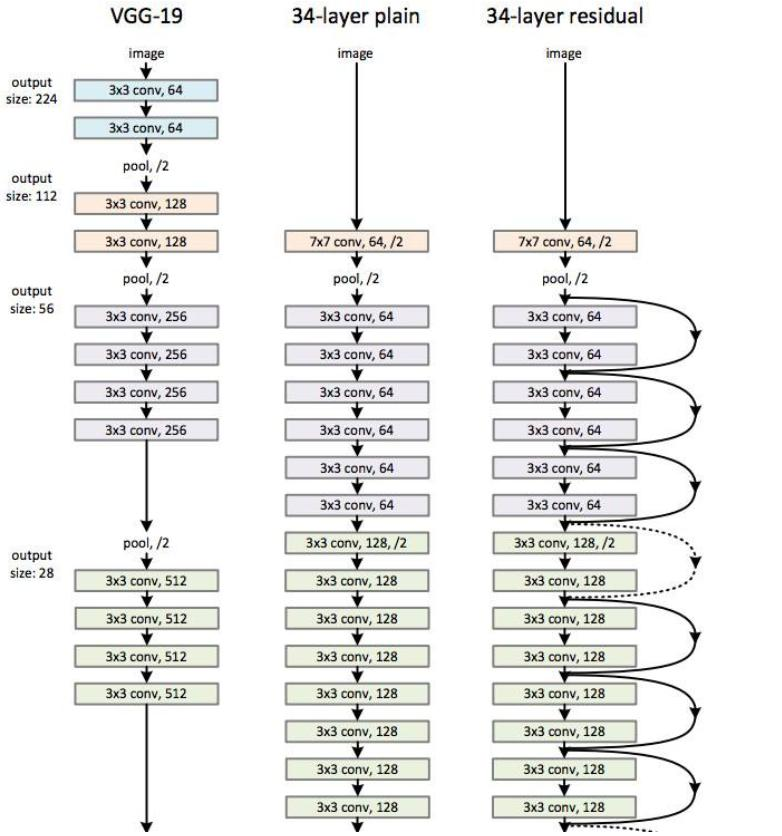
- BiLSTM:双向长短时记忆网络,捕获序列前后依赖。
- Text-CNN:将CNN应用于文本分类,需构造输入为词向量矩阵,卷积核覆盖不同词窗。

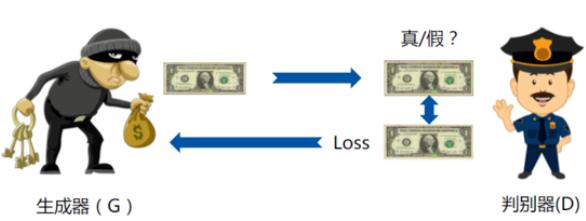
3. 对抗生成网络(GANs)
- CycleGAN:
- 特点:无需配对数据(如马→斑马),通过循环一致性损失(Cycle Loss)和身份损失(Identity Loss)实现图像风格迁移。

网络架构: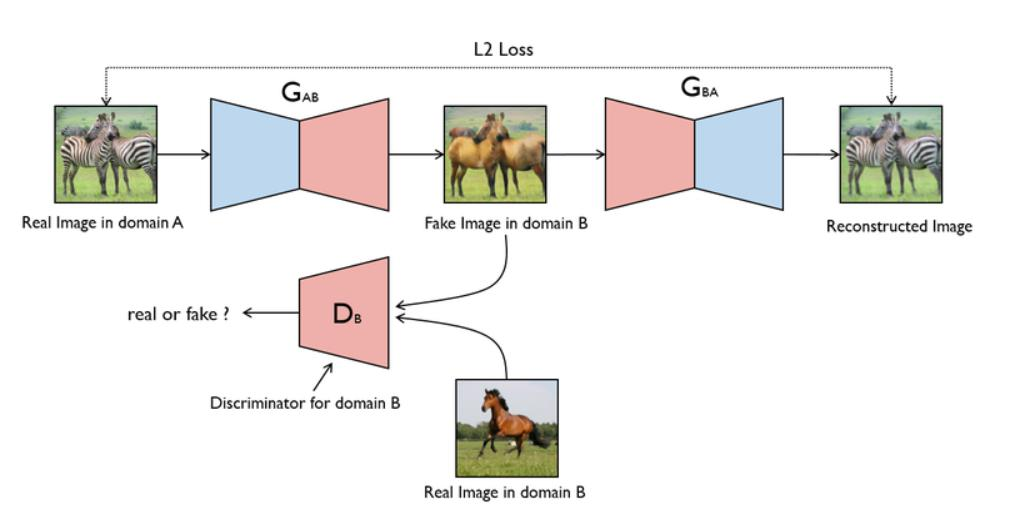
- 包含2个生成器(G)和2个判别器(D)。
- PatchGAN:局部感受野判别,输出N×N矩阵预测真实性,提升细节生成质量。
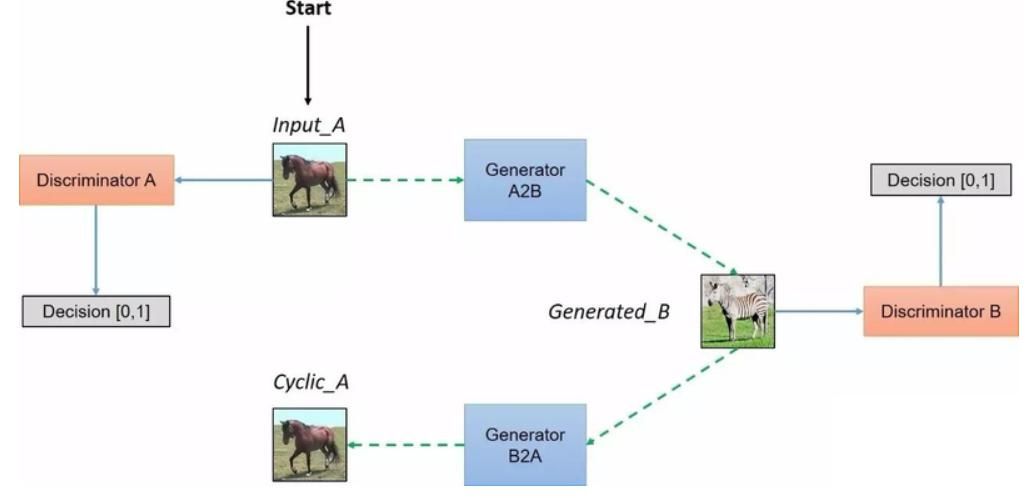
损失函数:4种损失(生成对抗损失、循环一致性损失、身份损失)。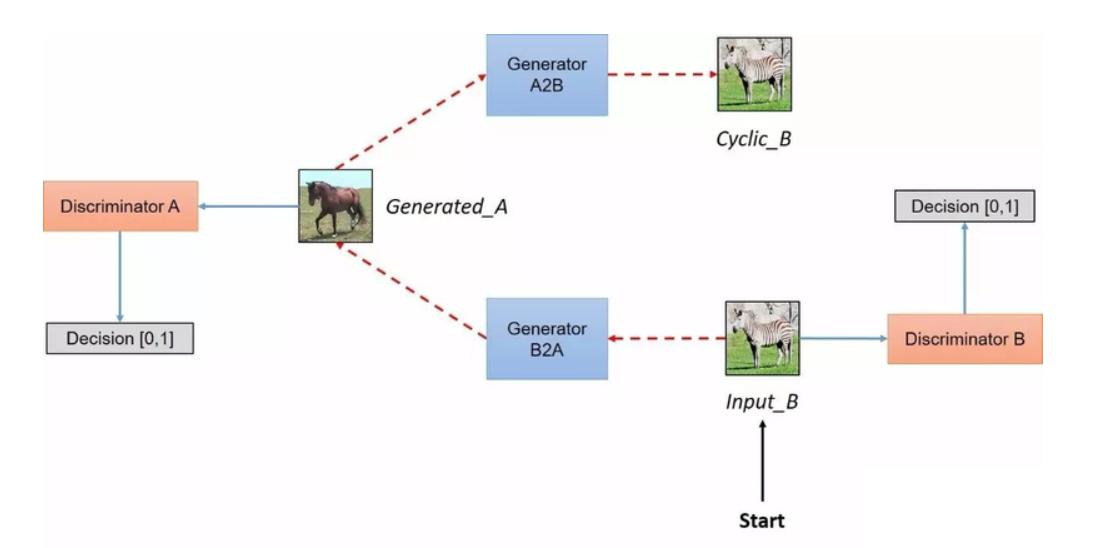
- 特点:无需配对数据(如马→斑马),通过循环一致性损失(Cycle Loss)和身份损失(Identity Loss)实现图像风格迁移。
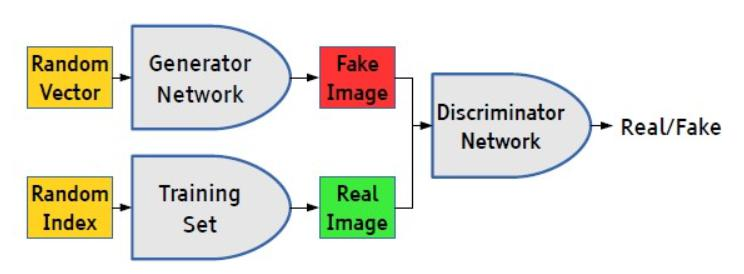
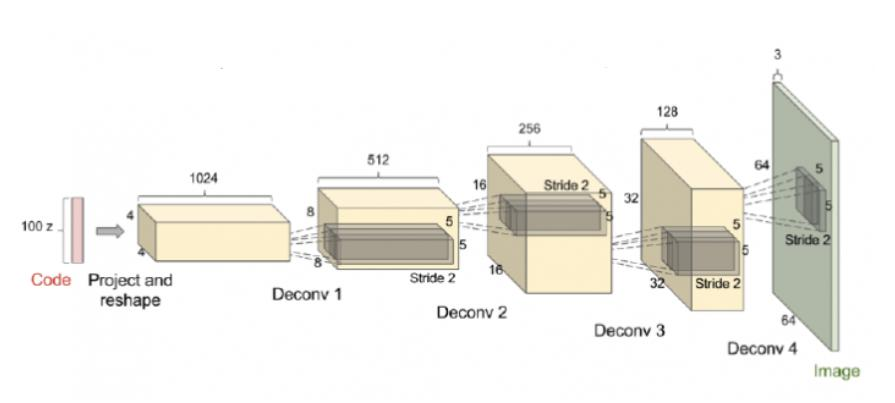
DCGAN
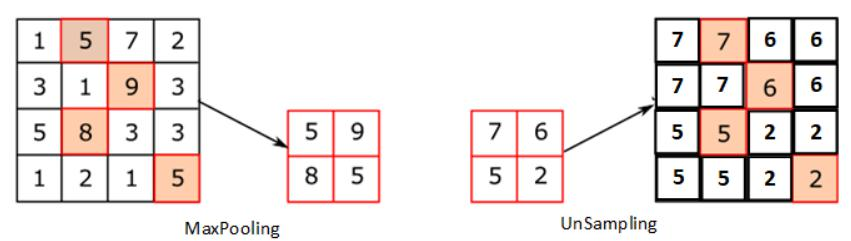
4. OCR(光学字符识别)

- 流程:
文本检测(CTPN算法):
- 基于改进的Faster R-CNN,检测水平文本区域。
- 关键改进:
- 预定义文本高度(10种),回归宽度调整。
- 序列合并规则:基于重合度(0.7)和位置距离(50像素)拼接候选框。
- 关键改进:


文本识别(CRNN算法):
- 网络架构:CNN(特征提取)+ BiLSTM(序列建模)+ CTC(对齐输入输出序列)。
- CTC模块:解决字符分割对齐问题,直接输出文本序列。

5. 视频分析与3D卷积
- 3D卷积:在2D卷积基础上增加时间维度,捕捉视频时序特征。
- 应用场景:动作识别、视频分类等。
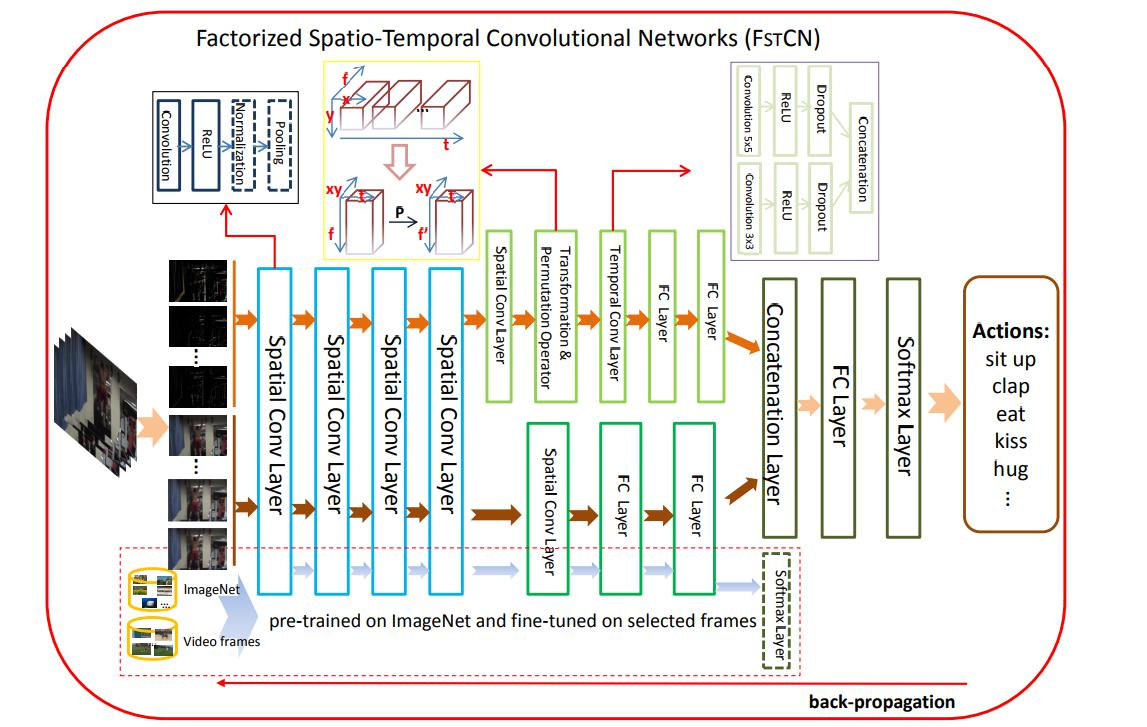
关键模型与算法
| 技术 | 核心思想 | 应用场景 |
|---|---|---|
| BiLSTM | 双向捕获序列上下文 | 文本分类、序列标注 |
| Text-CNN | 多尺度卷积核提取文本局部特征 | 文本分类 |
| CycleGAN | 无监督图像风格迁移 | 图像生成、风格转换 |
| CTPN | 文本区域检测与合并 | OCR文本定位 |
| CRNN | CNN+RNN+CTC端到端识别 | 文本识别 |