本地部署大模型最简单的一种方案 - 使用ollama
一:什么是Ollama
Ollama 是一个用于本地运行大型语言模型(LLM)的开源工具或平台,主要用于让用户在自己的设备上(尤其是个人电脑)方便地加载和运行类似 ChatGPT、LLaMA、Mistral、Gemma 等语言模型。
Ollama 提供了一套工具和命令行接口,使你可以像使用 Docker 一样简单地拉取、运行、管理本地语言模型。
它支持 Apple Silicon (M1/M2)、Linux 和 Windows(WSL)。
可运行的模型包括 Meta 的 LLaMA、Mistral、Gemma、Phi 等等。
官网地址:Ollama
二:安装使用
2.1:安装
直接点击Download下载对应的安装包
我使用的是macOS
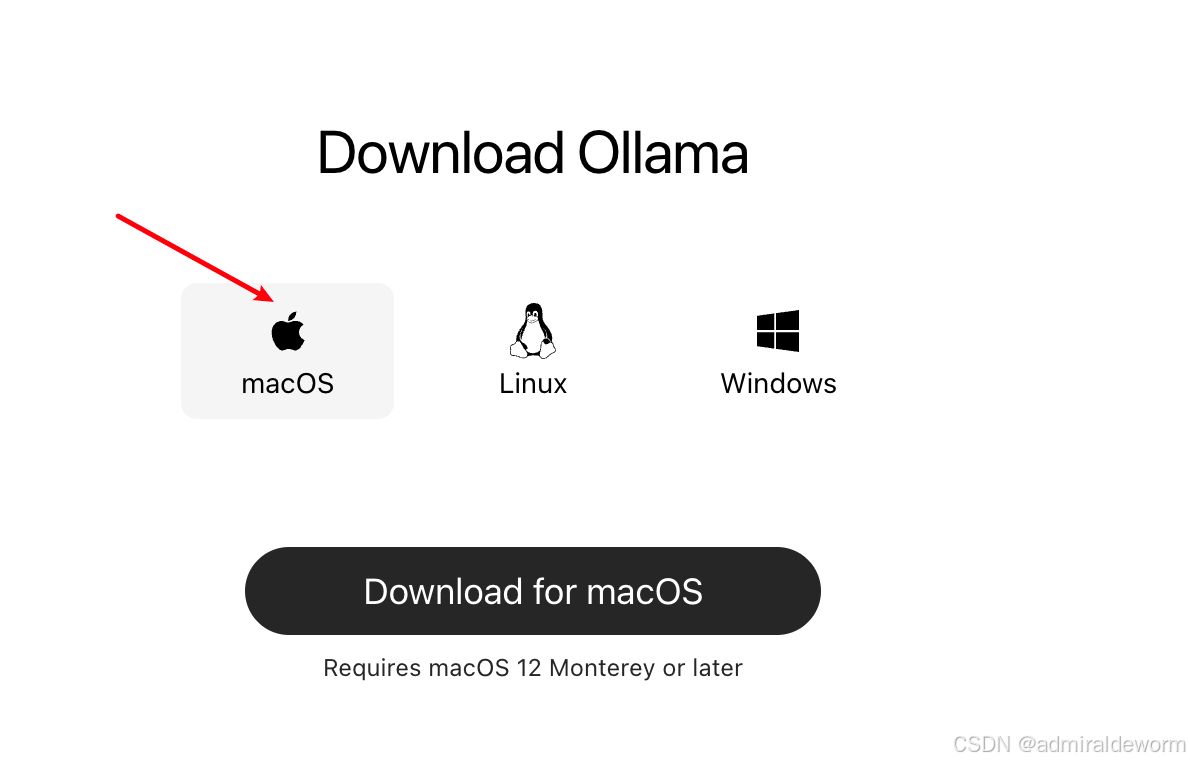
安装成功后会多一个羊驼标识的应用,

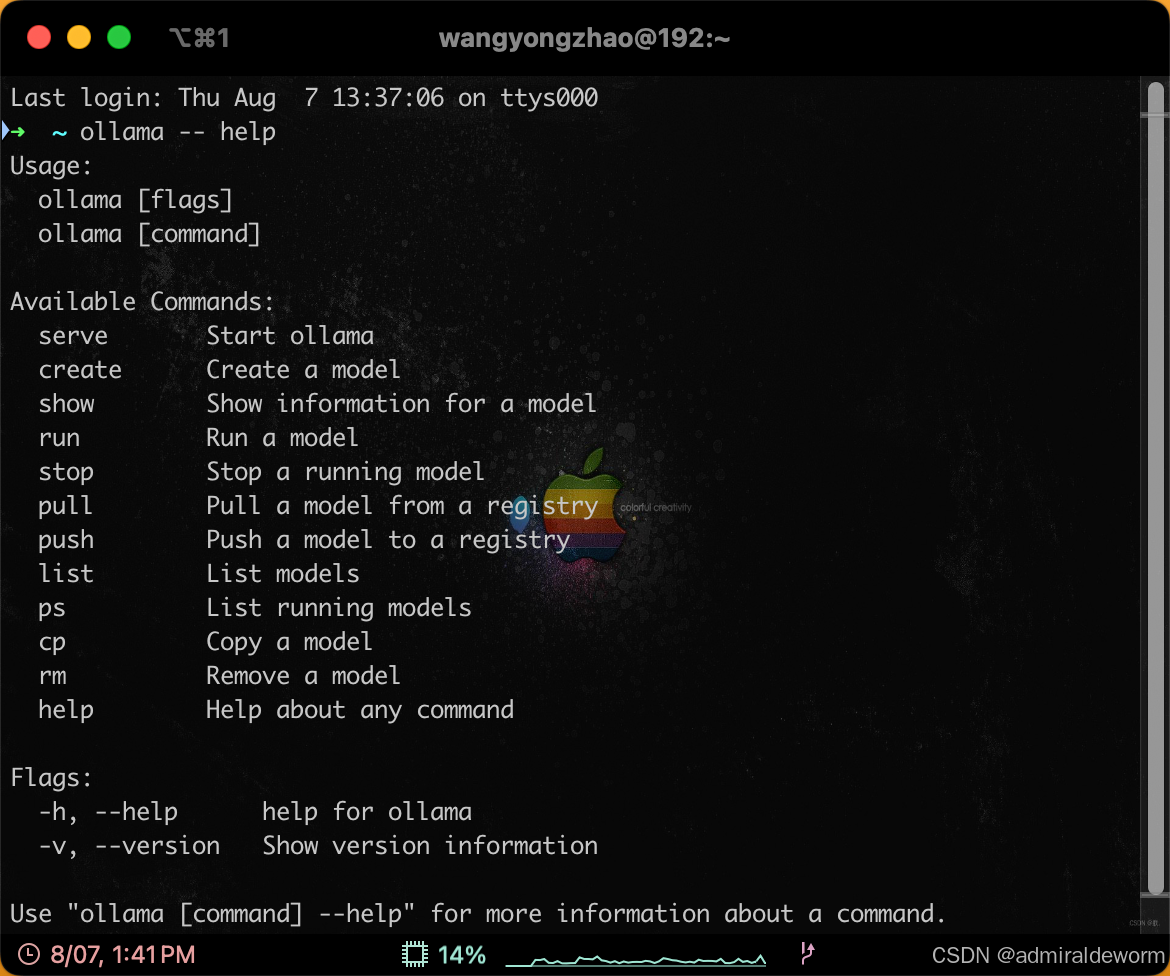
2.2:打开终端
ollama -- help查看支持的命令:
三:部署模型
3.1:选择模型
在ollama官网点击左上角Models可以看到Ollama支持的模型列表,类似于Docker的镜像列表
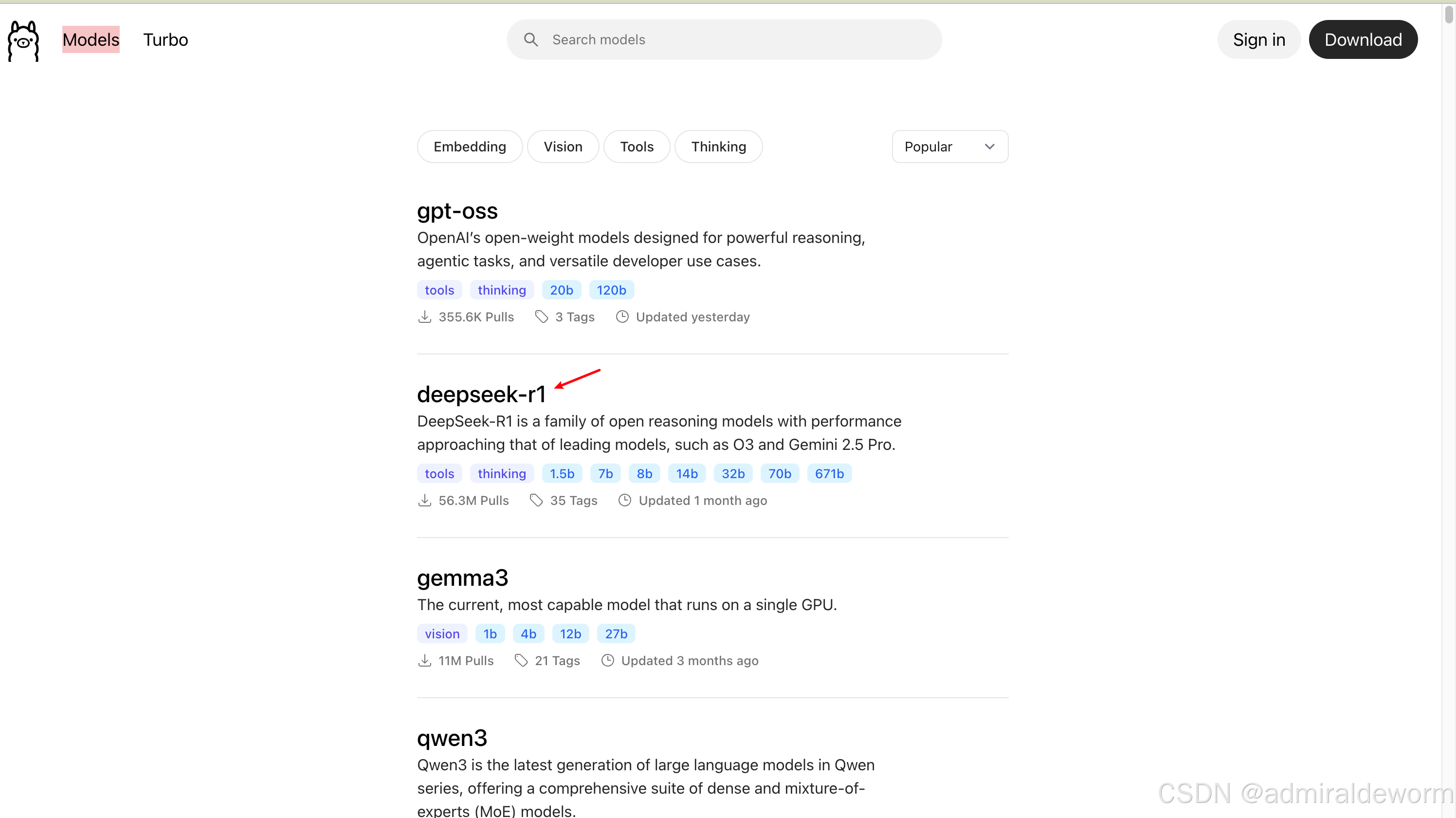
可以看到它是安装下载热度排列的,我们现在要部署deepseek,所以选择deepseek-r1;
点击进入可以看到很多版本:
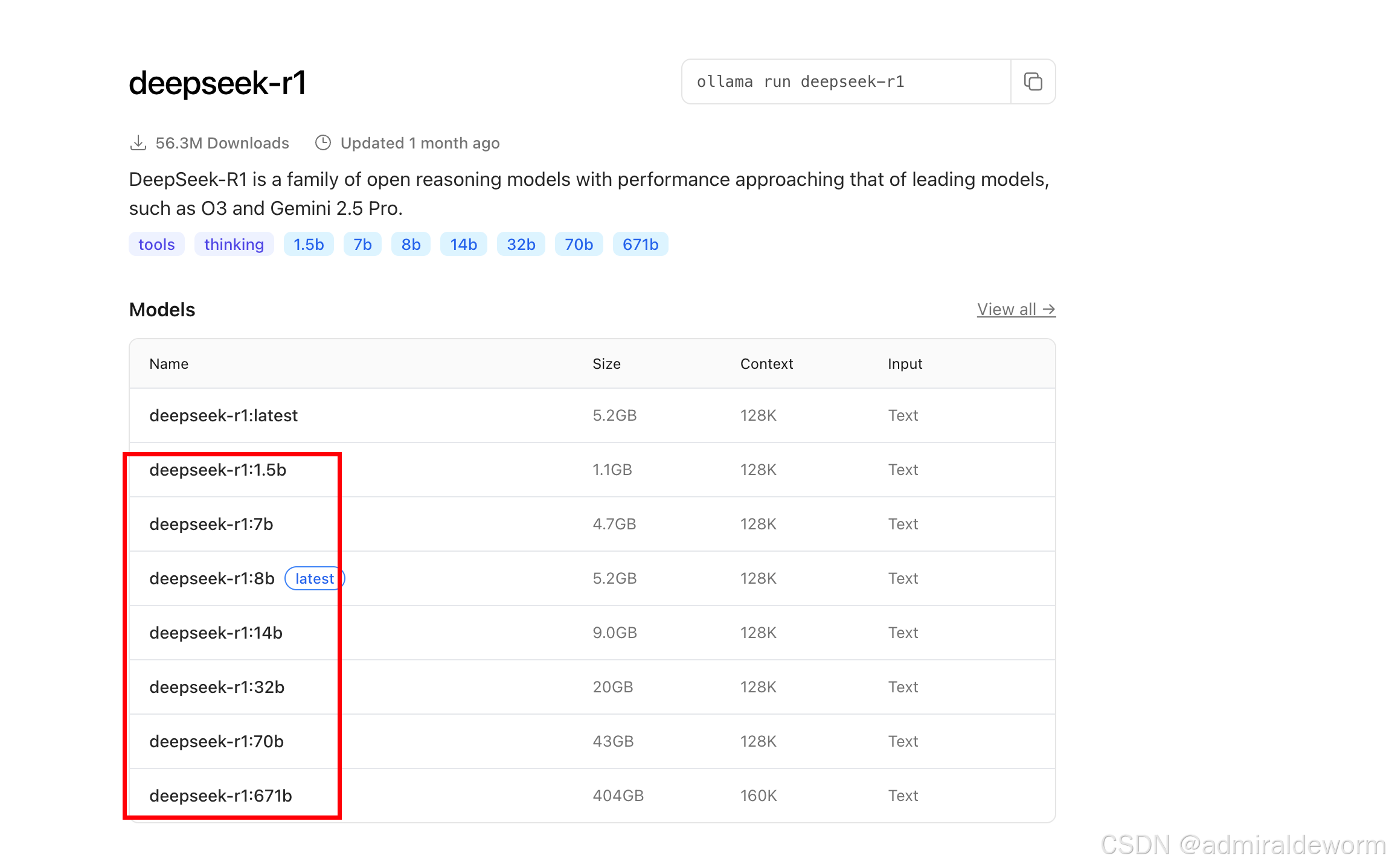 像
像 deepseek-r1:1.5b、7b、14b、70b 等这些后缀中的 **b**,指的是模型的参数规模(参数数量),单位是 “billion(十亿)”。这是衡量一个大型语言模型规模的重要指标之一。
更多参数 通常代表模型更复杂,理解能力更强,生成内容更自然,但也更大更慢。
| 模型 |
参数量 | 特点与适用场景 |
|---|---|---|
1.5b |
15亿 | 超轻量,适合边缘设备、快速测试 |
7b |
70亿 | 平衡性能与资源消耗,适合日常用 |
14b~32b |
中型模型 | 需要更多内存和显存,推理效果更好 |
70b+ |
大型模型 | 非常强大,需高端 GPU(如 A100)、适合研究和高端生成任务 |
671b |
巨型模型 | 多用于研究机构,极高的计算需求 |
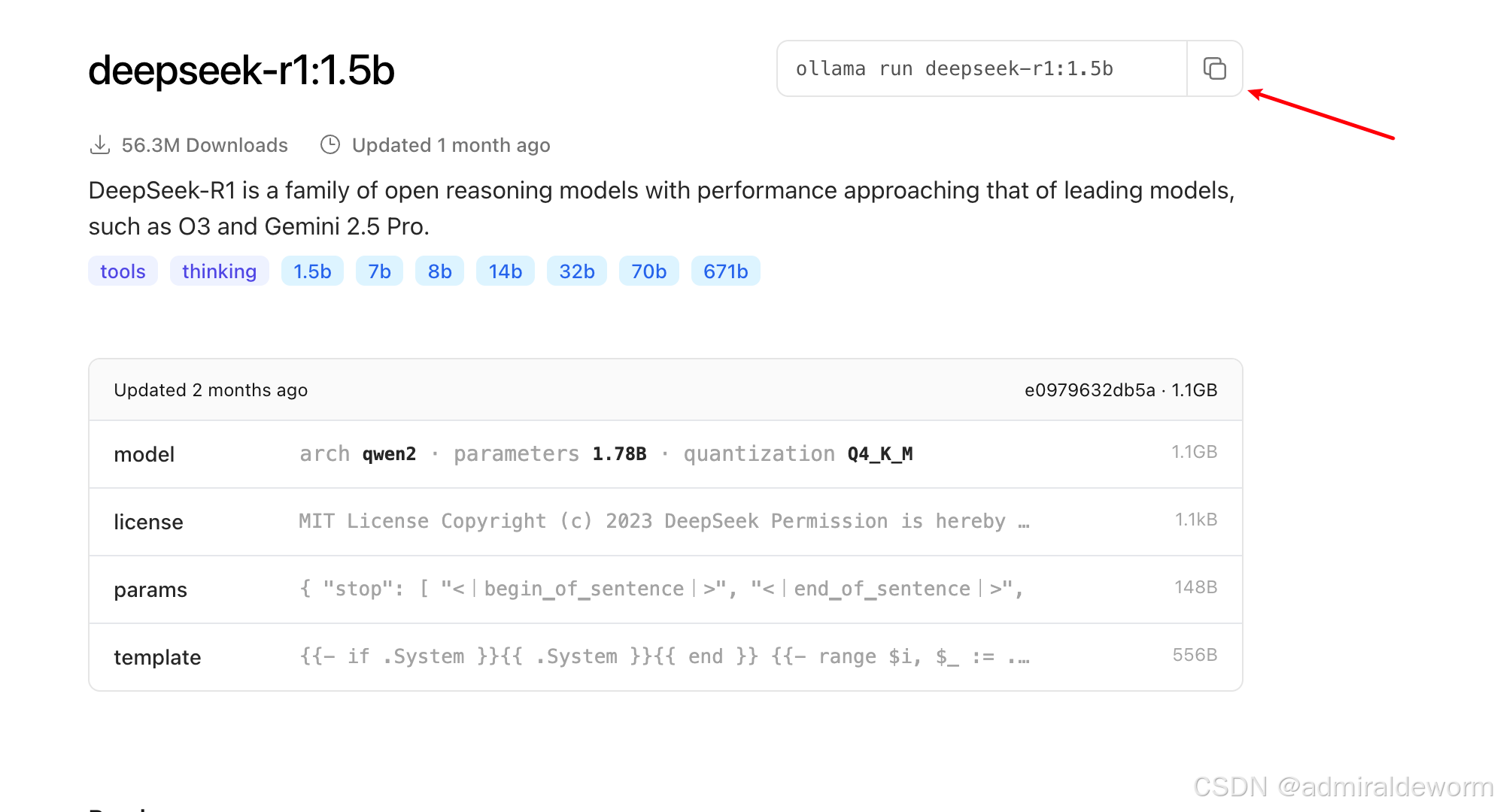
3.2:复制命令
选择自己需要且合适的版本点击,然后复制命令:
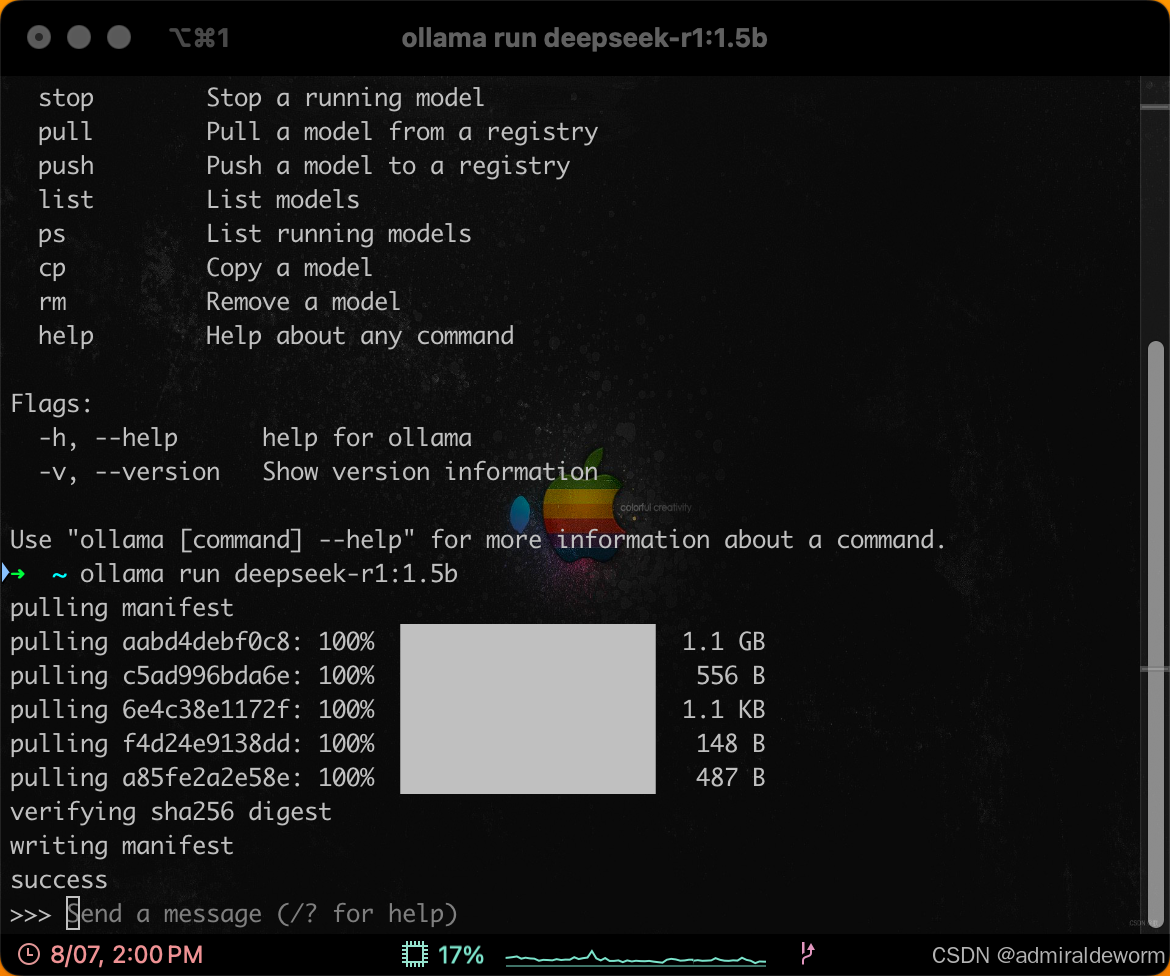
3.3:终端执行
第一次执行会去下载镜像,下载成功后会运行,然后打开一个控制台:
四:使用大模型
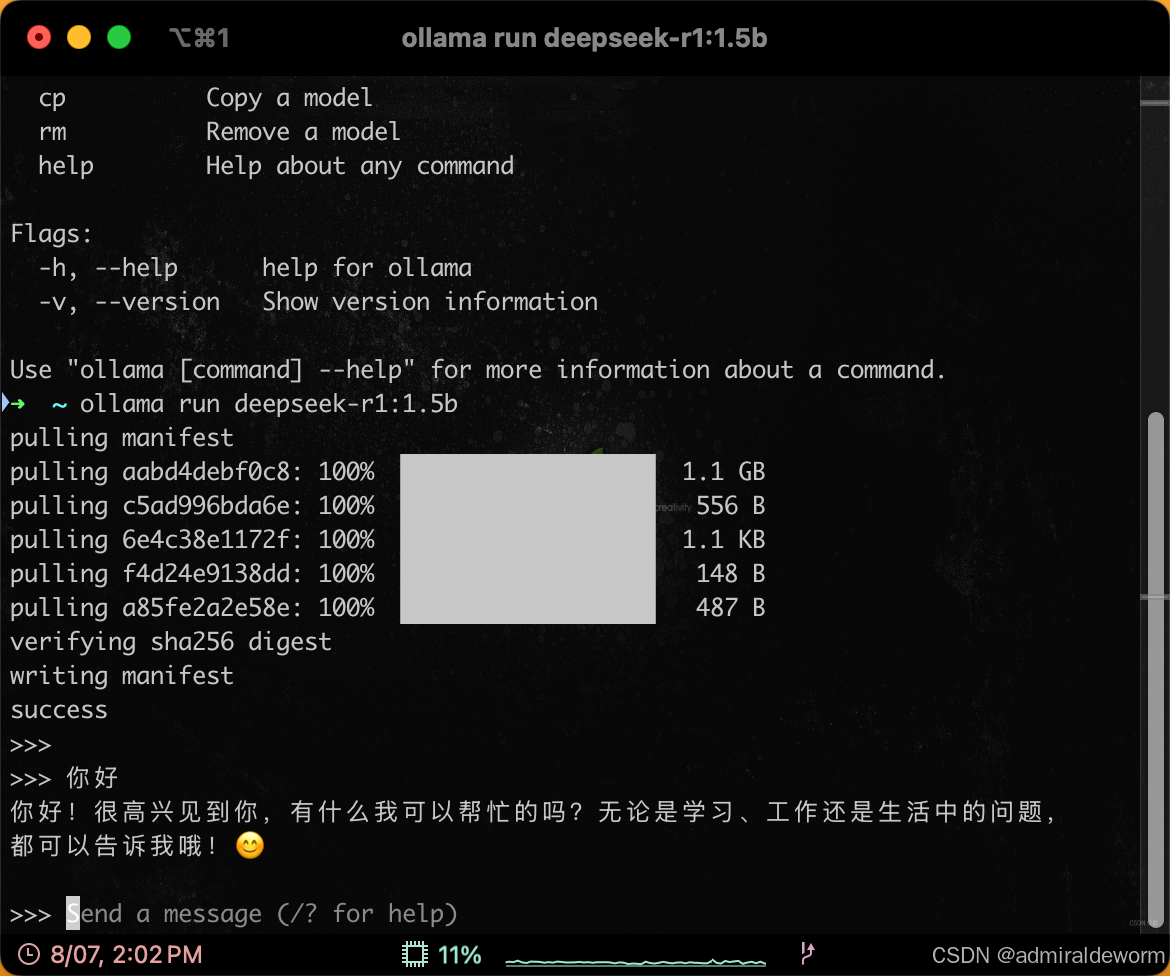
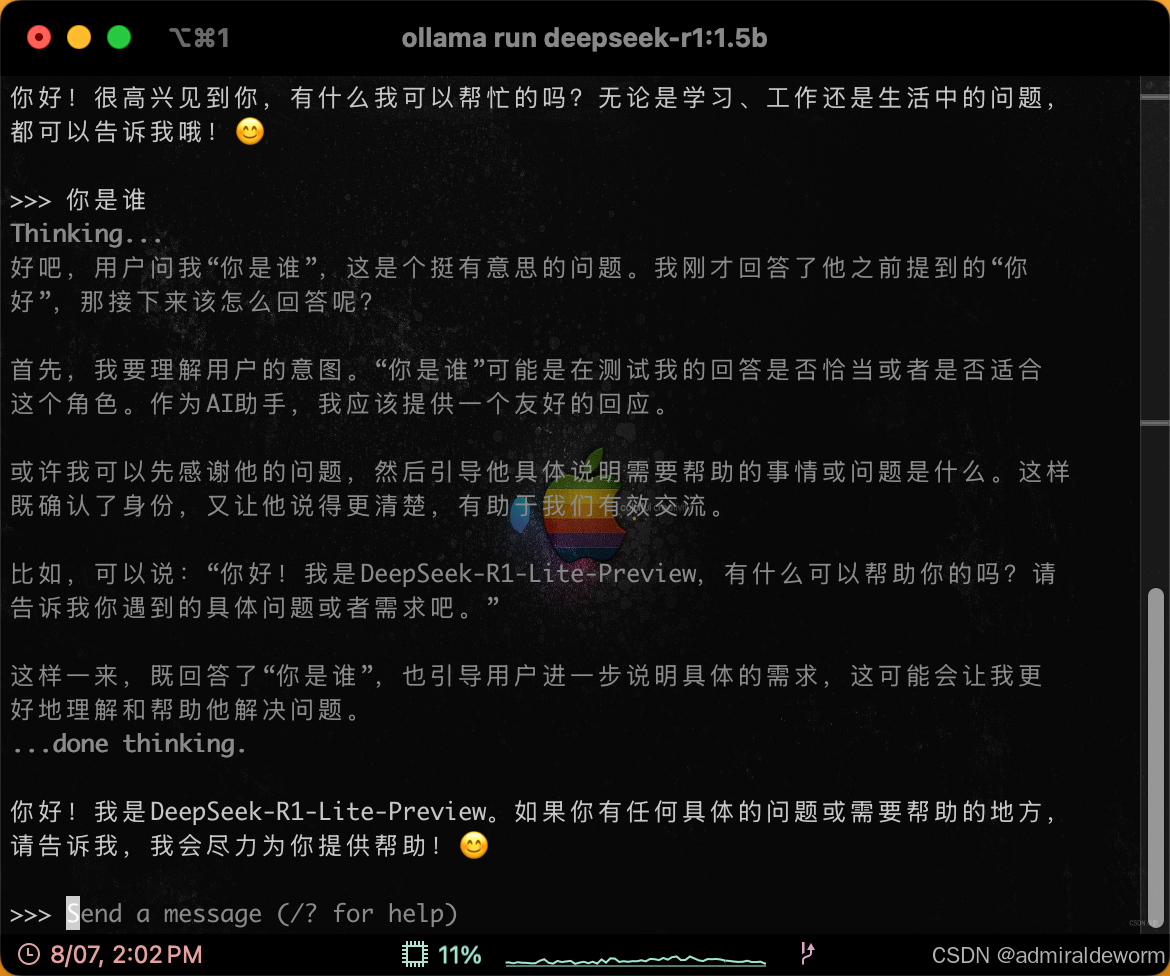
4.1:终端对话
这个控制的就是我们平常使用的会话平台,可以和它聊天了,例子:
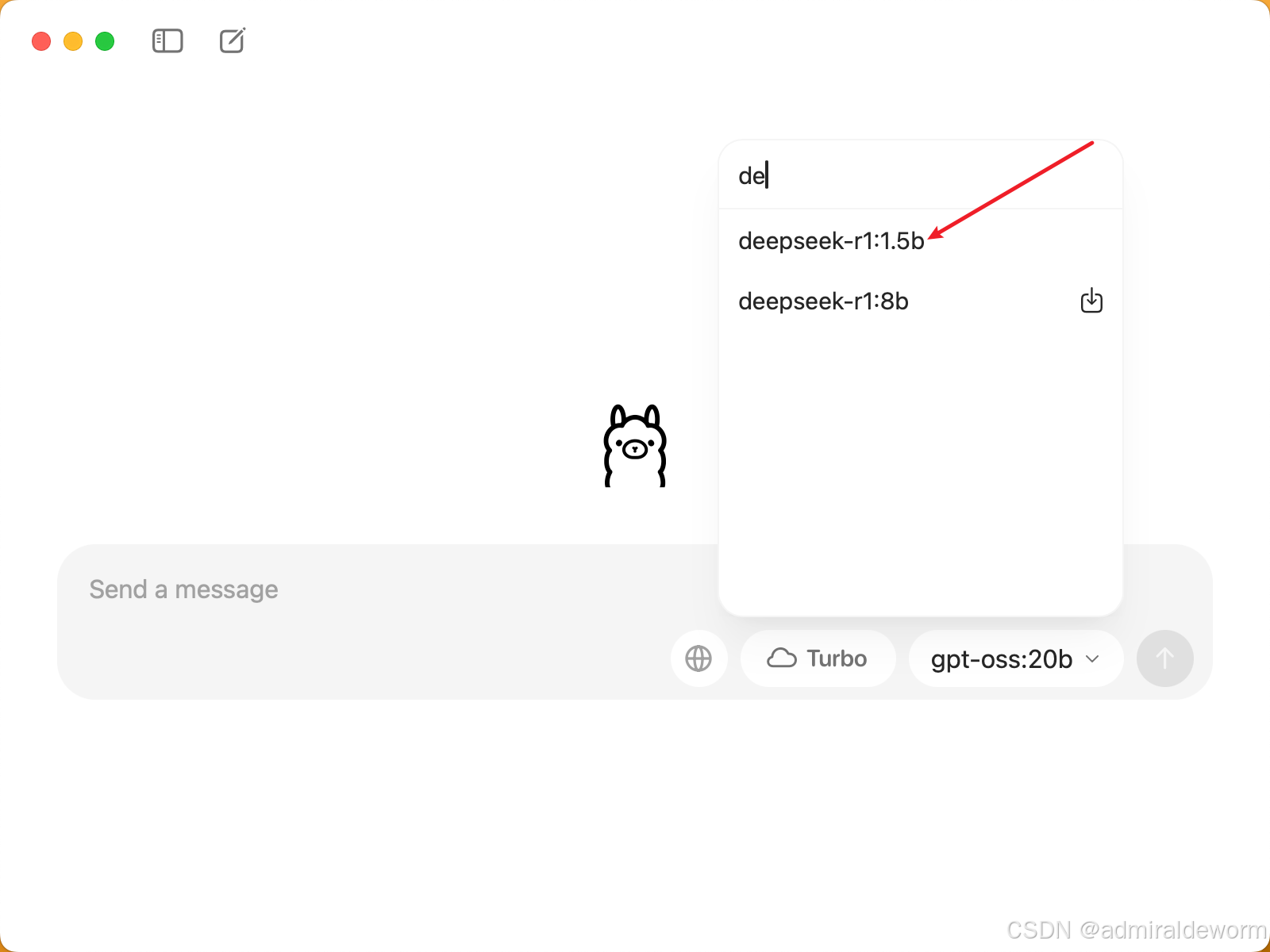
4.2:使用ollama对话
打开ollama,可以选择安装好的终端,可以看到deepseek-r1:1.5b已经下载安装好了,当然上面安装的操作也可以通过ollama界面进行操作:
同理可以安装上面的方式本地部署Models列表里的其他大模型