这篇论文主要围绕利用深度学习模型检测地下水位异常以识别地震前兆展开。
[1] Chen X, Yang L, Liao X, et al. Groundwater level prediction and earthquake precursor anomaly analysis based on TCN-LSTM-attention network[J]. IEEE Access, 2024, 12: 176696-176718.
期刊
IEEE Access
👨🔬 作者信息(Author Information)
Xinfang Chen(IEEE 会员)
- 单位:
- 中国地震局防灾科技学院 信息工程学院
- 河北省高校智慧应急应用技术研发中心
- 所在地:河北省三河市 065201
- 单位:
Lijia Yang(通讯作者 ✉️)
- 单位:同上
- 邮箱:23661627@st.cidp.edu.cn
核心内容可以概括为以下几个方面:
🌍 研究背景
- 地震前,地下岩层在应力积累作用下会发生微裂或变形,影响地下水系统(如水压、水位、水流和化学成分)。
- 因此,地下水位的异常波动可以作为地震前兆的潜在指示信号。
🧠 研究方法
- 使用多种深度学习模型(如 LSTM、TCN、TCN-LSTM-Attention 等)来预测地下水位。
- 通过将模型预测值与真实测量值进行对比,发现显著偏差的时段即被认为是异常时期(SA period)。
- 并结合统计方法(如 EWMA 控制图)对残差进一步分析,精准识别异常开始时间。
🔬 关键实验
- 分析了唐山地震(2020) 和建水地震(2015) 两个典型案例的地下水井(赵各庄井、玉田集 03 井、建水井)的水位数据。
- 对比不同模型的表现后发现:
- TCN-LSTM-Attention 模型最敏感,最早识别出异常。
- 相比于无监督的 Isolation Forest 方法,它能更早检测出地震前的地下水异常。
- 进行了模型的可迁移性测试(将模型应用到不同地理区域)和5 折交叉验证(验证模型的泛化能力)。
✅ 主要结论
- 地震前地下水位确实存在异常波动,且提前数天即可被检测到。
- TCN-LSTM-Attention 模型表现最优,对异常波动最敏感,且能提前预警。
- 模型具有良好的可迁移性和泛化能力,可适用于不同区域和不同地震事件。
- 将深度学习模型与统计分析方法结合,可以显著提升地震前兆识别的准确率与可靠性。
- 目前仅聚焦于地下水位,未来计划引入更多指标(如水温、氡浓度、电磁信号等)提升实用性。
📌 总体而言:
这是一个地震预测预警研究的交叉学科案例,结合地球物理学、地震学、水文学与人工智能,展示了用深度学习模型检测地震前兆的前沿探索与实际价值。
摘要
地下水位的异常变化是地震前兆的重要指示之一。在地震发生前,地下水位通常会出现不同程度的异常,这些异常通常表现为地下水位的突然上升或下降,并持续一段时间。2020年7月12日6时38分,中国河北省唐山市古冶区(纬度39.78°N,经度118.44°E)发生了一次5.1级地震。本文以该地震为研究案例,分析了赵各庄井和玉田基03井两个观测井的地下水位数据。为准确识别地震前兆异常,将地下水位数据划分为地震活跃期(SA)与地震非活跃期(non-SA),作为数据集划分的依据。本文提出了一种TCN-LSTM-Attention模型,该模型结合了TCN在特征提取方面的优势与LSTM在捕捉复杂时间依赖性方面的能力。实验结果表明,所设计的模型在地下水位预测和地震前兆异常识别方面表现出较强的能力。为了进一步提高异常检测的准确性,本文引入了指数加权移动平均(EWMA)控制图,精确定位异常的起始时间点。通过对中国云南省建水县地震的验证,模型在不同地质条件下依然能有效识别地下水位异常,验证了其泛化能力和实用性。最后,本文对所设计模型进行了交叉验证,进一步提升了其在实际应用中的可靠性。本研究在地震前兆分析方面具有一定的科学创新性和实践价值,为地震预警技术的发展及防灾减灾工作提供了新的技术支持和分析手段。
关键词
地震异常前兆,EWMA控制图,地下水位预测,地震活跃期,TCN-LSTM-Attention
Ⅰ、引言
地震是一种常见的自然灾害,对人类社会产生了深远影响。地震前兆异常是地震发生前出现的异常现象,对于地震预测至关重要。地下水位是地震前兆异常中的关键因素之一 [1],其对地震前兆的影响一直是地震学研究的重点。井水位观测是监测地下流体地震前兆的重要手段之一 [2]。井水位的异常变化能够客观而敏感地反映地壳介质的应力-应变变化。由于地下水具有分布广泛、流动性强和不可压缩的特性,当其形成封闭承压系统时,井水位的变化可以客观、灵敏地指示地壳的应变状态。对于承压含水层,如图1所示,观测井在含水层系统中可以作为高灵敏度的体积应变计 [3]。含水层岩体中由于应力应变变化而引发的地下水微小波动,为了解地下应力状态、当前构造运动以及地震活动和前兆提供了关键信息。
在地震孕育与发生过程中,局部应力的加载与卸载或大规模断层活动会导致岩体变形。这种变形会改变含水层的孔隙压力,进而改变地壳介质的渗透场,导致井水位发生动态波动,且水位变化的最大幅度与地震震级呈相关性 [4]。Sato 等人的观测表明,确实存在地震前的井水位异常变化 [5]。例如,在鲁甸地震发生前六个月,震中附近的地下水位就出现了显著变化:2014年6月和7月,位于昭通和会泽测站的井水位显著上升 [6]。这些变化为地震预测提供了关键的预警信息,表明地下水异常可以作为重要的地震前兆指标。研究地震孕育与发生过程中井水位的各种异常变化,对于理解地震的发生与发展过程具有重要的物理意义,也在地震前兆监测与预测实践中发挥着重要作用 [7]。
在过去的几十年中,地下水位预测常使用数值模拟和物理建模方法,其中MODFLOW是应用最广泛的模型之一 [8]。这些模型的开发通常需要详细的含水层特征信息,并考虑气象、地形、水文地质和人类活动等多种因素的综合影响 [9]。若对地下水系统的物理过程理解不充分,或参数选择不当,模型结果可能会受到影响。此外,这些模型对计算资源要求较高,且数据不准确也会影响预测精度 [10]。因此,这类建模过程充满不确定性和挑战。
相比之下,数据驱动方法在应对复杂、不确定或难以建模的地下水系统方面通常更为适用。数学建模方法如ARMA、ARIMA 和 GM(1,1) 等,常用于利用历史地下水位数据预测未来变化,在实时地下水位预测中提供了有效框架 [11]。但这些方法在处理非线性数据时难以实现高精度预测。近年来,随着大数据和机器学习技术的发展,基于数据驱动的地下水位预测方法逐渐兴起。通过采集和分析大量实时数据,机器学习方法可以基于历史数据构建非线性模型,用以预测地下水位变化,使预测模型更智能、更精确。在许多场景下,机器学习方法的预测性能优于基于物理的模型 [12]–[14]。这种方法的优势在于无需显式定义环境所需的物理关系和参数,而是通过迭代学习过程近似输入与输出之间的关系 [15]。典型的方法包括支持向量回归(SVR)和人工神经网络(ANN) [16]–[19]。但这类方法往往难以有效处理变量间的依赖关系,限制了其预测精度。
深度学习是当前热门的数据驱动算法,研究表明其性能优于传统过程模型 [20]。卷积神经网络(CNN)[21] 和长短期记忆网络(LSTM)[22] 是水文研究中应用最广泛的深度学习算法,能够有效捕捉空间和时间依赖性。Wunsch 等人使用1D-CNN对德国118个监测井的地下水位趋势进行了预测 [23],为响应措施的制定提供了重要参考。另一项研究发现,当将过去的地下水位作为输入时,LSTM 和 CNN 模型的表现更佳 [24]。Hopfield 曾提出一种用于序列数据的循环神经网络(RNN)[25],为后来的深度学习模型奠定了基础,这些模型被广泛认为是时间序列预测最有效的方法之一。尽管RNN已被成功应用于地下水建模 [26],但它在反向传播中存在梯度消失和爆炸问题,难以记住长序列信息 [27]。为解决这些问题,Hochreiter 和 Schmidhuber 提出了LSTM网络,增强了记忆能力 [28],目前被认为是时间序列预测中最先进的方法之一。LSTM网络通过过滤掉无关信息,仅保留关键历史事件的记忆,有效避免训练过程中的问题。Zhang 等人利用LSTM网络预测中国干旱的河套地区地下水位 [29],即便在数据稀缺的区域也表现良好。Bowes 等人研究了地下水位在周期性沿海洪水中的作用 [30],并探讨了LSTM和RNN模型在风暴响应预测中的潜力。
在注意力机制提出后,其被广泛应用于各类任务中。Noor 评估了深度学习与基于注意力机制的模型在洪水时空预测中的潜力 [31]。研究结果显示,将注意力机制引入LSTM模型能显著提升其性能。Babak Alizadeh 等人提出了一种结合注意力机制和贝叶斯优化的改进型LSTM模型,用于提升流量预测的精度 [32]。该LSTM-Attention模型通过聚焦关键时间点提升了处理复杂时间序列数据的能力,在流量预测任务中表现出色。
TCN 是一种用于时间序列预测的新型算法,由Lea等人于2016年首次提出 [33]。TCN通过一维卷积层从输入序列中提取特征,已被证明在多种任务中效果良好 [34]。每种模型都有其优缺点,将不同模型结合以取长补短,形成集成模型,是近年来研究的一个热点方向。多种模型组合在不同领域已被广泛探讨 [35]–[38]。LSTM适合处理时间依赖性强的序列数据,但存在梯度消失/爆炸问题,不擅长提取空间特征,且计算复杂度高;而TCN则在提取空间特征和并行计算方面更有优势,训练和推理效率高,但在捕捉长序列的时间依赖性方面略逊一筹 [39]。注意力机制的引入,使模型能够聚焦于输入序列中最相关的信息,弥补了LSTM和TCN在特征选择方面的不足。本文提出的TCN-LSTM-Attention模型融合了三者的优点 [40],具备更强的表达能力与更高的预测精度,在复杂地下水位预测中展现出优异的性能。
为了更好地识别地震前兆异常,本文将时间序列划分为地震活跃期(SA)与非活跃期(non-SA)[41]。模型首先学习非活跃期的正常数据,再对其他时期的地下水位进行预测,并比较模型预测值与实际观测值之间的差异。若差异显著,可能表明地震活动影响了监测数据,导致地下水位异常 [42]。为了检测异常及其起始时间,本文引入了指数加权移动平均(EWMA)控制图。此外,许多学者也采用无监督学习方法进行异常检测。例如,Liu等人提出了基于分类思想的孤立森林算法 [43],被广泛应用于数据异常检测中。其他无监督方法,如一类支持向量机(One-Class SVM)和局部离群因子(LOF)也被用于异常检测 [44]。Jamshidi 等人成功将无监督异常检测技术应用于地下水及监测井异常检测领域 [45]。因此,除了监督学习模型,本文还利用无监督学习的孤立森林算法来检测地震引起的地下水位异常。
本文结构安排如下:第一部分简要介绍研究背景与研究目标;第二部分阐述机器学习基本原理,并细化不同类型的机器学习模型;第三部分介绍数据处理与实验方法;第四部分展示并分析具体预测结果;第五部分总结研究的主要发现与结论。
II. 机器学习原理
A. LSTM
LSTM 是 RNN 的一种变体,专门用于解决长期依赖问题。相比 RNN,LSTM 引入了门控机制,有助于缓解梯度消失或爆炸的问题,从而更有效地捕捉长期记忆与依赖关系。LSTM 的结构由一系列重复的神经网络模块组成,如图 2 所示。
LSTM 包含三个门控单元:遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate)。这些门接收来自当前时刻的输入信息以及上一个时刻的隐藏状态。
遗忘门 控制前一时刻的记忆单元状态 C t − 1 C_{t-1} Ct−1 中需要被遗忘的信息量,其计算方式如公式(1)所示。输出值在 0 0 0 到 1 1 1 之间, f t f_t ft 趋近于 1 1 1 表示保留的信息更多,趋近于 0 0 0 表示遗忘的信息更多。
输入门 决定当前时刻的输入信息 x t x_t xt 中有多少应被加入到记忆单元状态中,计算方式如公式(2)所示。 i t i_t it 趋近于 1 1 1 表示加入的信息较多,趋近于 0 0 0 表示较少。
输出门 控制当前记忆单元状态 C t C_t Ct 中有多少信息作为隐藏状态 h t h_t ht 输出,见公式(3)。 o t o_t ot 趋近于 1 1 1 表示输出较多,趋近于 0 0 0 表示输出较少。
记忆单元状态( C t C_t Ct):结合遗忘门和输入门的输出更新。将上一个时刻的记忆状态乘以遗忘门的输出,再加上输入门的输出与生成的新候选记忆状态的乘积。候选记忆状态的计算如公式(4),记忆单元状态的更新如公式(5)。
隐藏状态( h t h_t ht):通过输出门和当前记忆状态生成。 C t C_t Ct 包含当前时刻的重要信息,而 o t o_t ot 决定从 C t C_t Ct 中输出哪些信息到 h t h_t ht,从而形成一个被过滤并转换后的特征表示,见公式(6)。
f t = σ ( W f x t + U f h t − 1 + b f ) (1) f_t = \sigma(W_f x_t + U_f h_{t-1} + b_f) \tag{1} ft=σ(Wfxt+Ufht−1+bf)(1)
[ i t = σ ( W i x t + U i h t − 1 + b i ) (2) [ i_t = \sigma(W_i x_t + U_i h_{t-1} + b_i) \tag{2} [it=σ(Wixt+Uiht−1+bi)(2)
o t = σ ( W o x t + U o h t − 1 + b o ) (3) o_t = \sigma(W_o x_t + U_o h_{t-1} + b_o) \tag{3} ot=σ(Woxt+Uoht−1+bo)(3)
c ~ t = tanh ( W c x t + U c h t − 1 + b c ) (4) \tilde{c}_t = \tanh(W_c x_t + U_c h_{t-1} + b_c) \tag{4} c~t=tanh(Wcxt+Ucht−1+bc)(4)
C t = C t − 1 ⋅ f t + i t ⋅ c ~ t (5) C_t = C_{t-1} \cdot f_t + i_t \cdot \tilde{c}_t \tag{5} Ct=Ct−1⋅ft+it⋅c~t(5)
h t = o t ⋅ tanh ( C t ) (6) h_t = o_t \cdot \tanh(C_t) \tag{6} ht=ot⋅tanh(Ct)(6)
其中, σ \sigma σ 表示 Sigmoid 函数, x t x_t xt 是当前时刻的输入, h t − 1 h_{t-1} ht−1 是前一时刻的隐藏状态, C t C_t Ct 为当前记忆单元状态, c ~ t \tilde{c}_t c~t 是候选记忆状态, W W W、 U U U、 b b b 是各门控的可训练参数。
B. CNN
CNN 由卷积层、激活函数、池化层和全连接层组成。卷积层通过卷积操作对输入特征进行提取,激活函数引入非线性因素,池化层用于降维,全连接层用于最终的分类处理。输出层通常使用 softmax 激活函数将全连接层的输出转换为类别概率分布。
本研究中,针对时间序列数据分析,使用了一维卷积层。一维卷积通过滑动窗口方式对输入序列执行卷积操作,能够捕捉输入序列中的局部模式和特征。
C. TCN
TCN 模型是一种针对时间序列问题设计的简单而高效的 CNN 架构,主要包括膨胀因果卷积和堆叠残差单元。其优势包括并行计算、参数共享和时序卷积,有助于提升对长时间依赖与长序列的建模能力。
1)因果卷积(Causal Convolutions)
因果卷积确保当前卷积的输出仅依赖于当前及之前的输入值,维护数据的时序因果关系。对输入序列 x = { x 1 , x 2 , … , x T } x = \{x_1, x_2, \dots, x_T\} x={x1,x2,…,xT},其输出 y t y_t yt 的计算公式如下:
y t = ∑ i = 0 k − 1 w i ⋅ x t − i (7) y_t = \sum_{i=0}^{k-1} w_i \cdot x_{t-i} \tag{7} yt=i=0∑k−1wi⋅xt−i(7)
其中, k k k 是卷积核大小, w i w_i wi 是卷积核的权重, x t − i x_{t-i} xt−i 是输入序列中的值。
2)膨胀卷积(Dilated Convolutions)
膨胀卷积引入一个膨胀因子 d d d,在卷积核每两个元素间插入 d − 1 d-1 d−1 个零,从而扩大感受野而不增加参数量。其公式如下:
y t = ∑ i = 0 k − 1 w i ⋅ x t − d ⋅ i (8) y_t = \sum_{i=0}^{k-1} w_i \cdot x_{t - d \cdot i} \tag{8} yt=i=0∑k−1wi⋅xt−d⋅i(8)
其中, d d d 是膨胀因子, t − d ⋅ i t - d \cdot i t−d⋅i 表示在时序上的回溯位置。
结合因果卷积与膨胀卷积可构成膨胀因果卷积,兼具因果性与更大感受野的优点。
3)残差模块(Residual Block)
残差模块由两个卷积单元和一个非线性映射单元组成,如图 5 所示。每个卷积单元包含一维膨胀因果卷积、权重归一化、ReLU 激活函数和 Dropout 操作。其操作公式如下:
h ( x ) = conv 1 × 1 ( x ) + f ( x ) (9) h(x) = \text{conv}_{1 \times 1}(x) + f(x) \tag{9} h(x)=conv1×1(x)+f(x)(9)
其中, h ( x ) h(x) h(x) 为该层输出并作为下一个残差模块的输入, f ( x ) f(x) f(x) 为残差映射。
D. 注意力机制(Attention Mechanism)
时间序列中的注意力机制指对不同时间步动态分配权重,以更好地捕捉序列中的关键信息,常用于预测、异常检测和序列对齐等任务。引入注意力机制增强了神经网络模型的灵活性和适应性。
本研究采用加权求和注意力机制对 LSTM 的输出特征进行增强,如图 6 所示。具体包括三个步骤:
通过全连接层计算每个时间步的注意力得分:
e t = tanh ( W t ⋅ h t + b ) (10) e_t = \tanh(W_t \cdot h_t + b) \tag{10} et=tanh(Wt⋅ht+b)(10)使用 softmax 函数将注意力得分归一化为注意力权重:
α t = exp ( e t ) ∑ k = 1 T exp ( e k ) (11) \alpha_t = \frac{\exp(e_t)}{\sum_{k=1}^{T} \exp(e_k)} \tag{11} αt=∑k=1Texp(ek)exp(et)(11)计算上下文向量 c c c:
c = ∑ t = 1 T α t ⋅ h t (12) c = \sum_{t=1}^{T} \alpha_t \cdot h_t \tag{12} c=t=1∑Tαt⋅ht(12)
其中, W t W_t Wt 和 b b b 为可学习参数, α t \alpha_t αt 表示第 t t t 个时间步的重要性。
E. TCN-LSTM-Attention 混合模型
TCN-LSTM-Attention 混合模型融合了各自的优势:
- TCN 通过局部感受野和多层卷积结构,提取时间序列的时空特征。
- LSTM 的门控机制有助于建模长期依赖信息。
- 注意力机制能够动态聚焦于关键时间步,提高模型对序列中重要信息的识别能力。
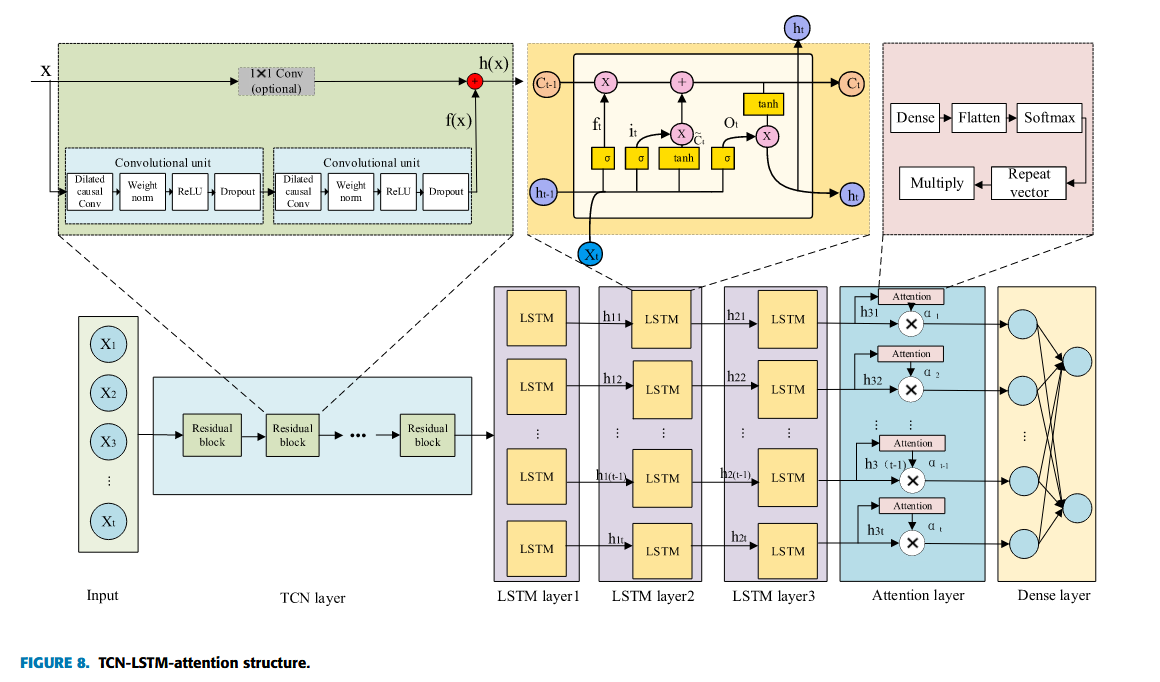
该模型由五层组成:输入层、TCN 层、LSTM 层、注意力层和全连接输出层,如图 8 所示。
- 输入层:数据维度为 ( None , 10 , 1 ) (\text{None}, 10, 1) (None,10,1),每个样本包含 10 个时间步,每个时间步 1 个特征。
- TCN 层:包含多个残差块,每个块含两个卷积单元(Dropout、ReLU、权重归一化、膨胀因果卷积),输出维度为 ( None , 10 , 64 ) (\text{None}, 10, 64) (None,10,64)。
- LSTM 层:包括三层 LSTM,每层输出维度为 ( None , 10 , 50 ) (\text{None}, 10, 50) (None,10,50)。
- 注意力层:输出维度为 ( None , 10 , 50 ) (\text{None}, 10, 50) (None,10,50)。
- 全连接层:输出维度为 ( None , 1 ) (\text{None}, 1) (None,1)。
该模型训练轮数为 100,学习率为 0.0001,优化器为 Adam。
F. 隔离森林(Isolation Forest)
隔离森林是一种常用于异常检测的无监督学习算法,其核心思想是:异常点因远离正常样本而更容易被隔离。
该方法通过构造多个随机决策树对数据进行分割,最终为样本分配异常得分,得分越高表明越可能是异常点。如图 7 所示,其异常得分计算公式如下:
Isolation Score ( x ) = 2 − E ( h ( x ) ) c ( n ) (13) \text{Isolation Score}(x) = 2^{-\frac{E(h(x))}{c(n)}} \tag{13} Isolation Score(x)=2−c(n)E(h(x))(13)
其中, E ( h ( x ) ) E(h(x)) E(h(x)) 表示样本 x x x 在多棵随机树中的平均隔离深度, c ( n ) c(n) c(n) 是与样本数量 n n n 有关的常数。
III. 数据处理
A. 地震与观测井介绍
根据中国地震台网中心(CENC),2020年7月12日6时38分,河北省唐山市古冶区( 39.7 8 ∘ 39.78^\circ 39.78∘N, 118.4 4 ∘ 118.44^\circ 118.44∘E)发生 5.1 5.1 5.1级地震,震源深度为 10 km 10\,\text{km} 10km。此次 5.1 5.1 5.1级地震位于1976年 7.8 7.8 7.8级唐山地震的余震带中部,距离1976年 7.8 7.8 7.8级唐山地震震中约 57 km 57\,\text{km} 57km,距1976年 7.1 7.1 7.1级滦州地震震中约 11 km 11\,\text{km} 11km。2020年5月至7月的全国地震概率预测结果表明,此次地震发生在地震活动相对高概率区。该地震是自1995年10月6日唐山 5.0 5.0 5.0级地震以来,唐山地震序列中24.8年来最大的一次 5.0 5.0 5.0级及以上地震。
赵各庄井位于北京市平谷区城关镇赵各庄村,地理坐标为 117.0 1 ∘ 117.01^\circ 117.01∘E, 40.1 3 ∘ 40.13^\circ 40.13∘N,海拔 26.2 m 26.2\,\text{m} 26.2m。其观测井剖面如图9所示,井周地表大部分覆盖第四系松散堆积物。监测含水层为第四系承压孔隙水,主要包括:
- 深度为 171.00 ∼ 254.00 m 171.00\sim254.00\,\text{m} 171.00∼254.00m的第四系砾石及卵石与黏性砂混合层;
- 深度为 556.81 ∼ 557.26 m 556.81\sim557.26\,\text{m} 556.81∼557.26m的第四系石英砂岩层。
井中还包括 257.59 ∼ 479.00 m 257.59\sim479.00\,\text{m} 257.59∼479.00m的砾石和卵石夹黏性岩层以及 479.00 ∼ 556.81 m 479.00\sim556.81\,\text{m} 479.00∼556.81m的砾石和巨砾夹黏性岩层,均具有良好的渗透性。自2001年9月起开展了水位和水温的数字化监测。长期观测数据显示,该井对周边 4.0 4.0 4.0级以上地震具有良好的响应能力。
玉田基03井观测台站位于 117.7 8 ∘ 117.78^\circ 117.78∘E, 39.8 2 ∘ 39.82^\circ 39.82∘N,井深 456.42 m 456.42\,\text{m} 456.42m,观测段深度为 317.00 ∼ 456.42 m 317.00\sim456.42\,\text{m} 317.00∼456.42m,含水层岩性为奥陶系灰岩,地下水类型为岩溶裂隙承压水。其水位观测数据连续可靠,脉冲少,基础资料完备。观测井表现出明显的年变化规律,水位高峰通常出现在9月到11月之间,低谷多出现在6月。当水位年变化规律不与降雨相关并出现异常时,常伴随中强地震的发生。例如1989年6月,水位上升异常后出现下降异常,不久后即在1989年10月19日发生了山西大同 M 6.1 M6.1 M6.1地震。
图10显示了震中位置与两个监测井的位置。赵各庄井位于夏垫断裂带北端,其水温和水位的异常变化与夏垫断裂活动有关;玉田基03井则位于镇子镇断裂带附近。位于地震断裂带上的监测井更容易在地震前出现水位异常,这是由于断裂带地质活动可导致地下水流动和压力发生变化,从而引起水位的变化。此外,这两口井均采集自承压含水层,相比其他类型的地下水,其对地壳应变状态变化更具客观性和敏感性。
B. 实验流程与配置
本实验包括三个主要步骤:数据预处理、训练方法选择与异常分析,如图11所示。
在数据预处理阶段,首先对采集的原始数据进行了缺失值处理,然后划分为 S A SA SA和非 S A SA SA期,并进行了数据标准化。处理后的数据划分为训练集、验证集和预测集。
实验中采用了七种模型:LSTM、LSTM-Attention、CNN-LSTM、CNN-LSTM-Attention、TCN、TCN-LSTM 和 TCN-LSTM-Attention。其中包含LSTM的模型又进一步分为一层与三层两种结构进行比较分析。训练后模型用于对地下水水位数据进行预测分析,并通过 M S E MSE MSE、 M A E MAE MAE、 R M S E RMSE RMSE 和决定系数 R 2 R^2 R2等指标进行评估。
在异常分析阶段,通过评估发现模型 TCN-LSTM(3层)-Attention 在异常检测方面表现更优。该模型用于预测实际值与预测值之间的残差,并进一步结合 E W M A EWMA EWMA控制图分析,以确定最早的异常时间。实验配置详见表1。
C. 缺失值处理
本研究使用的数据集由中国地震台网中心国家地震数据中心提供(http://data.earthquake.cn)。实验中收集了地震发生前18个月和地震后10天内两个井的分钟级水位数据。数据集中缺失值以 999999.0 999999.0 999999.0表示。将 999999.0 999999.0 999999.0替换为 N a N NaN NaN后,发现赵各庄井有 4522 4522 4522个缺失值,玉田基03井有 2076 2076 2076个缺失值。采用线性插值法对缺失值进行填补。填补后的数据如图12和图13所示。图中红色虚线表示 S A SA SA期和非 S A SA SA期的分界,红线左侧为 S A SA SA期,右侧直至地震发生为非 S A SA SA期,黑色虚线表示地震发生时刻。
D. SA与非SA期的划分
为更准确识别前兆异常,将时间序列划分为 S A SA SA期和非 S A SA SA期。当实际值与预测值出现显著偏差时,说明可能存在地震活动对监测数据产生影响。因此,关键在于寻找合适的规则划分非 S A SA SA期与 S A SA SA期的时间区间。
实验中采用如下经验公式来确定该时间区间,如公式14所示:
log R T = 0.63 M ± 0.15 (14) \log R T = 0.63 M \pm 0.15 \tag{14} logRT=0.63M±0.15(14)
其中, R ( km ) R\,(\text{km}) R(km)表示震中距, T ( days ) T\,(\text{days}) T(days)为前兆异常与后续地震之间的时间间隔, M M M为地震震级, log \log log表示以 10 10 10为底的对数。
从 T T T天前至地震时刻为 S A SA SA期,其余时间为非 S A SA SA期。根据公式计算,震中距赵各庄井约为 127.95 km 127.95\,\text{km} 127.95km,对应 T T T为 9.0356 ∼ 18.0285 9.0356\sim18.0285 9.0356∼18.0285天;震中距玉田基03井约 56.5 km 56.5\,\text{km} 56.5km,对应 T T T为 20.4621 ∼ 40.8 20.4621\sim40.8 20.4621∼40.8天。为便于实验,取最长的前兆时间,分别为玉田基03井的 41 41 41天和赵各庄井的 19 19 19天。
因此,赵各庄井的 S A SA SA期为 2020 2020 2020年 6 6 6月 23 23 23日至 7 7 7月 12 12 12日,其余为非 S A SA SA期;玉田基03井的 S A SA SA期为 2020 2020 2020年 6 6 6月 1 1 1日至 7 7 7月 12 12 12日,其余为非 S A SA SA期。
E. 数据集划分
为提升模型检测潜在前兆异常的能力,根据前人研究及非 S A SA SA期数据,将训练集和验证集排除 S A SA SA期,仅选用非 S A SA SA期数据。将两口井地震前18个月的数据分别划分为训练集( 80 % 80\% 80%)、验证集( 10 % 10\% 10%)和预测集( 10 % 10\% 10%),以确保训练与验证阶段不包含异常期数据。预测集中部分数据也来自非 S A SA SA期。图14和图15中,红色竖线表示 2020 2020 2020年 6 6 6月 23 23 23日与 6 6 6月 1 1 1日,分别为赵各庄井和玉田基03井的 S A SA SA与非 S A SA SA期分界线。蓝色段为训练集,绿色段为验证集,红色段为预测集。
F. 数据归一化
数据归一化有助于加快模型收敛速度。当时间序列数据数值较大时,模型可能需要更多迭代才能达到最优解。通过缩放数据范围,模型能更快学习有效参数。归一化可增强模型稳定性,减少特征间数值差异对性能的影响。
本研究采用最小-最大归一化方法,如公式15所示:
X i ∗ = X i − X min X max − X min (15) X_i^* = \frac{X_i - X_{\min}}{X_{\max} - X_{\min}} \tag{15} Xi∗=Xmax−XminXi−Xmin(15)
其中, X i X_i Xi为第 i i i个样本点的原始观测数据, X i ∗ X_i^* Xi∗为归一化后的值, X max X_{\max} Xmax与 X min X_{\min} Xmin分别为原始数据中的最大值与最小值。
G. 模型评价指标
本文采用时间序列分析中常用的 M S E MSE MSE、 R M S E RMSE RMSE、 M A E MAE MAE与决定系数 R 2 R^2 R2来评估模型预测性能,具体计算公式如下:
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 (16) MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 \tag{16} MSE=n1i=1∑n(yi−y^i)2(16)
R M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 (17) RMSE = \sqrt{ \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 } \tag{17} RMSE=n1i=1∑n(yi−y^i)2(17)
M A E = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ (18) MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| \tag{18} MAE=n1i=1∑n∣yi−y^i∣(18)
R 2 = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 (19) R^2 = 1 - \frac{ \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 }{ \sum_{i=1}^{n} (y_i - \bar{y})^2 } \tag{19} R2=1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2(19)
其中, n n n为样本数, y i y_i yi为第 i i i个观测值, y ^ i \hat{y}_i y^i为第 i i i个预测值, y ˉ \bar{y} yˉ为观测值的平均值。
H. EWMA控制图
EWMA控制图是一种用于监测和检测过程微小变化或趋势的统计过程控制图。通过对数据施加指数加权,EWMA图能更敏感地捕捉过程中的微小偏差。公式如下:
Z t = λ X t + ( 1 − λ ) Z t − 1 (20) Z_t = \lambda X_t + (1 - \lambda) Z_{t-1} \tag{20} Zt=λXt+(1−λ)Zt−1(20)
U C L t = μ + L σ λ 2 − λ ( 1 − ( 1 − λ ) 2 t ) (21) UCL_t = \mu + L \sigma \sqrt{ \frac{ \lambda }{ 2 - \lambda } (1 - (1 - \lambda)^{2t} ) } \tag{21} UCLt=μ+Lσ2−λλ(1−(1−λ)2t)(21)
L C L t = μ − L σ λ 2 − λ ( 1 − ( 1 − λ ) 2 t ) (22) LCL_t = \mu - L \sigma \sqrt{ \frac{ \lambda }{ 2 - \lambda } (1 - (1 - \lambda)^{2t} ) } \tag{22} LCLt=μ−Lσ2−λλ(1−(1−λ)2t)(22)
其中, Z t Z_t Zt为 t t t时刻的EWMA值, X t X_t Xt为 t t t时刻观测值, λ \lambda λ为平滑系数( 0 < λ ≤ 1 0 < \lambda \leq 1 0<λ≤1),控制权重衰减速率, Z t − 1 Z_{t-1} Zt−1为 t − 1 t-1 t−1时刻的EWMA值,初始值 Z 0 = μ Z_0 = \mu Z0=μ, μ \mu μ为过程均值, σ \sigma σ为标准差。
本实验中,取 L = 3 L=3 L=3, λ = 0.3 \lambda=0.3 λ=0.3,即控制界限设置为均值上下三个标准差,符合正态分布经验法则,理论上 99.73 % 99.73\% 99.73%的数据应落在此区间内。
IV. 实例分析
A. 模型预测分析
1)赵各庄井水位预测结果分析
图16展示了各个包含1层LSTM模型对赵各庄井水位的预测结果。在训练集、验证集以及预测集的早期阶段(即非SA期间),所有模型的拟合效果都较好,表明各模型未发生过拟合。值得注意的是,在2020年6月23日至2020年7月12日的SA期间,所有模型均开始出现明显的拟合不良,预测值与真实值之间出现较大偏差,可能表明地下水位出现了异常。为更好地检测此类异常,应选择在SA期间预测值与真实值偏差最大的模型。TCN-LSTM-Attention模型表现最为明显,其次是TCN-LSTM模型。
表2给出了地震发生前十天早上6:38的预测值及残差。LSTM的残差范围为 − 0.0012 -0.0012 −0.0012 至 0.0024 0.0024 0.0024,而TCN的残差范围为 − 0.0254 -0.0254 −0.0254 至 − 0.0353 -0.0353 −0.0353。相比之下,TCN模型的残差约为LSTM模型的20倍,表明TCN模型更适合用于识别地下水异常作为地震前兆信号。CNN-LSTM模型的残差范围为 0.0089 0.0089 0.0089 到 0.0102 0.0102 0.0102,TCN-LSTM模型的残差范围为 0.0726 0.0726 0.0726 到 0.0933 0.0933 0.0933,约为CNN-LSTM模型的10倍,说明TCN和LSTM的组合比CNN和LSTM更适合识别本实验中的地下水异常。而TCN-LSTM-Attention模型的残差范围为 0.2102 0.2102 0.2102 到 0.2444 0.2444 0.2444,为所有模型中残差最大,说明TCN-LSTM-Attention模型在识别水位异常方面表现最佳。
图16、17、18中,灰色背景为训练集数据,黄色背景为验证集数据,绿色背景为测试集数据。红色虚线为SA与非SA期间的时间分界线,黑色虚线为地震发生时刻。实线黑线表示实际值,其他颜色实线为各模型的预测值。
图17展示了包含3层LSTM的各模型对赵各庄井水位的预测结果。在监督学习模型中,各模型在非SA期间表现良好,但在SA期间均出现拟合不良现象,反映地下水位的异常。其中,TCN-LSTM-Attention模型异常识别最为明显,其次是TCN-LSTM模型。
如表3所示,TCN-LSTM模型的残差在 0.1633 0.1633 0.1633 至 0.2037 0.2037 0.2037 之间,TCN-LSTM-Attention模型的残差在 0.9415 0.9415 0.9415 至 1.0617 1.0617 1.0617 之间,后者的残差最大,进一步说明其在识别井水位异常数据方面的优越性。
此外,作为无监督学习方法,Isolation Forest模型也成功识别出赵各庄井的水位异常(见图17),表明监督学习与无监督学习方法均可有效检测地下水异常。但结果显示,Isolation Forest模型识别异常的时间晚于TCN-LSTM-Attention模型。
同时,表2与表3显示,TCN-LSTM(1层)-Attention模型的残差为 0.2102 0.2102 0.2102 到 0.2444 0.2444 0.2444,而TCN-LSTM(3层)-Attention模型的残差为 0.9415 0.9415 0.9415 到 1.0617 1.0617 1.0617,后者约为前者的5倍。因此,TCN-LSTM(3层)-Attention模型是检测地下水位异常的最优模型。随后,所有包含3层LSTM的模型被用于预测玉田集03井的水位。
2)玉田集03井水位预测结果分析
图18展示了各个包含3层LSTM模型对玉田集03井水位的预测结果。在非SA期间,各模型表现良好,但在SA期间均表现出明显的拟合异常,TCN-LSTM-Attention模型表现最为突出。
表4显示了地震发生前第十天早上6:38的各模型预测值与残差,其中TCN-LSTM-Attention模型的残差最大。这说明该模型能够在不同井位、同一地震事件中识别出水位异常,表明其具有良好的适用性和迁移能力。
同样,我们也对玉田集03井水位数据采用Isolation Forest方法进行异常检测(见图18),在SA期间也成功识别出水位异常,证明其识别地下水异常的有效性。但不难发现,其识别时间仍晚于TCN-LSTM-Attention模型。
D. 综合分析
地下水位的异常波动可以作为地震前兆的潜在指标。尤其在地震临近时,地壳应力逐渐积累,可能导致地下岩层出现微小裂缝或变形。这些应力变化会影响地下水系统,特别是水压、流速、水位以及化学成分等参数。因此,通过监测特定区域地下水位的异常波动,可以捕捉潜在的地震前兆信号,为地震预测提供关键的数据支持。
此次地震的震中位于唐山断裂带北段 [49],强震影响区约为 47 平方千米。然而,出现明显地下水异常的区域却延伸至 400 至 500 千米范围。震前,靠近震中的流体观测井显示出高孔隙压力,表明唐山古冶地区处于应力积累状态。震前压缩带大致呈东西走向,特征为应力积累,井水位普遍呈现异常上升趋势。
在本实验中,位于震中西侧的赵各庄井与玉田集03井均处于震前压缩带,其水位也表现出异常上升。对这些水位变化的监测可为地震预警提供重要信息。
根据美国地质调查局(USGS)的全球地震目录,我们选取了在验证与预测阶段,震中距监测点500千米范围内所有震级大于 M w > 5 M_w > 5 Mw>5 的地震事件。研究发现该时段附近并无其他震级大于5的地震,因此可以判定,此次水文异常为唐山地震引起。
阶段预测结果分析: 对于两口井,在水文时间序列的非SA(异常)期间,各模型的预测结果均与实际值高度拟合。然而在SA期间,所有模型的预测结果与实际值均出现明显偏差,说明该阶段地下水位存在异常波动。
模型预测结果分析: 在非SA期间,各模型表现良好;但在SA期间,包括无监督方法Isolation Forest在内,所有模型均检测到地下水位异常。其中,TCN-LSTM-Attention模型识别异常的时间早于Isolation Forest,具备更强的地震前兆预测优势。与其他模型相比,TCN-LSTM-Attention模型在预测值与实际值之间存在最大的偏差,表明其更适合用于识别地下水异常。
TCN-LSTM-Attention模型的深层结构使其能够更有效地捕捉地下水位时间序列中的复杂模式和长期依赖关系。其多层架构提升了模型的表达能力,使其能从数据中提取更多特征,从而提高对地下水异常的检测准确性。
异常期分析: 通过EWMA控制图识别到的最早异常时刻为:
- 赵各庄井:2020年6月16日 14:12:00;
- 玉田集03井:2020年6月28日 18:17:00。
这些异常的早期识别时间为灾害预防、减灾和救援提供了关键参考,使管理人员能够及时采取措施防范潜在灾害。
E. 模型的可迁移性
近年来,许多学者对迁移学习展开了研究。迁移学习的目标是将模型在源领域中学习到的知识迁移至目标领域,尤其在源领域与目标领域存在一定相关性但数据分布不同的情况下,如图27所示。
图27. 迁移学习的基本思想。
我们选取了2015年4月13日10:28发生于中国云南省建水县的一次震级为4.7的地震作为研究对象。该地震的震中位于北纬23.96度、东经102.84度。我们使用TCN-LSTM-Attention模型对建水井的地下水位数据进行分析。该井距离震中约35.68千米。
根据公式10,本次地震的SA期约为震前37天。我们使用LSTM模型与TCN-LSTM-Attention模型分别对建水井的水位进行预测,如图28所示。在非SA期,两个模型的拟合效果都较好;而在震前14天左右,预测值与实际值之间开始出现明显差异,说明两个模型均检测到了地下水异常,但TCN-LSTM-Attention模型检测到的异常更为明显。
表8显示,在地震前10天,TCN-LSTM-Attention模型的残差大约是LSTM模型的8倍,表明其对地下水异常更敏感,异常检测能力更强。
表9显示,两种模型在测试集上的均方误差(MSE)、均方根误差(RMSE)和平均绝对误差(MAE)均高于训练集与验证集,说明模型在测试集预测中成功检测到了异常。
通过EWMA控制图,我们识别到的最早异常时刻为2015年4月1日12:57:00。此次地震的前兆特征与唐山地震高度相似。
这一结果说明,本文提出的模型不仅适用于华北地区的唐山地下水数据分析,还可以迁移至地质结构不同的中国西南地区,有效识别其它地区的地下水异常。因此,对建水地震事件的分析进一步验证了TCN-LSTM-Attention模型的泛化能力与可迁移性,展示出良好的适应性与鲁棒性。这些结果为该模型在更广泛的地震预测应用中提供了有力支持。
F. 模型精度验证
交叉验证是一种用于评估模型性能与泛化能力的统计方法 [50]。它将数据集划分为多个称为“折(fold)”的子集,并在不同的子集组合上多次训练模型。
最常见的交叉验证方法是 k k k 折交叉验证( k k k-fold cross-validation),即将数据划分为 k k k 个不重叠子集,每轮迭代使用 k − 1 k - 1 k−1 个子集进行训练,剩下的一个子集用于验证。经过 k k k 次迭代后,计算所有验证结果的平均值,以估计模型的稳健性与泛化能力。
在本实验中,我们采用了5折交叉验证,如图30所示。我们使用赵各庄井的地下水位数据进行交叉验证以验证模型精度,结果见图31。
训练集与验证集包含正常的地下水波动,拟合效果良好。然而在测试集中,当地下水位显著偏离正常范围时,模型未强行拟合真实值,从而导致预测值与实际值之间出现明显差异。该差异反映了模型对异常检测的有效性,成功识别出可能由地震活动引起的异常。
通过交叉验证,我们观察到本文提出的模型在不同训练-验证划分组合下均表现出良好的异常检测效果,表明其具有强泛化能力与对地下水异常变化的高敏感性。
综上所述,交叉验证不仅验证了模型的稳定性与准确性,也进一步证明其在地震前兆监测中的潜力。
V. 结论
地下水水位的微小动态为地球动力学和地震监测提供了理论基础。研究表明,地震与区域应力场的调整密切相关,应力场的变化会引起承压含水层中的应力-应变变化。因此,地下水位异常常被视为地震前兆的指标。
本研究通过模型预测地下水位数据,并通过对比预测数据与实测数据识别异常点。研究结论如下:
1)根据经验公式将数据集划分为非震前活跃期(non-SA period)和震前活跃期(SA period)。对于玉田集 03 井,震前 41 天被视为 SA period,其余时间为 non-SA period;而赵各庄井的 SA period 为震前 19 天,其余为非活跃期。依据此方法对数据进行分段,有助于深入分析地震活动对地下水位的影响,不仅有助于识别地震前兆,还为未来地震预测与灾害防控提供了关键的时间参考。
2)与其他模型相比,TCN-LSTM-Attention 模型在地震前期的预测结果与实际值偏差最大,表现出对异常数据的高灵敏性,且能早于无监督的 Isolation Forest 方法识别异常。该模型能有效捕捉地震前地下水位的显著波动,清晰地反映 SA period 内的异常,为地震预测与防灾减灾提供了重要信息。
3)本研究利用 TCN-LSTM-Attention 模型的残差并结合 EWMA 控制图(Exponentially Weighted Moving Average)进行异常检测,确定异常变化的起始时间。结果显示,玉田集 03 井的最早异常检测时间为 2020 年 6 月 28 日 18:55:00,赵各庄井为 2020 年 6 月 20 日 17:03:00,建水井为 2015 年 4 月 1 日 12:57:00。该方法不仅能够有效识别地下水位的异常变化,还能精确定位其发生时间,表明将神经网络模型与统计分析方法结合能显著提升地下水异常检测的准确性和及时性,为地震预测提供更可靠的参考依据。
4)本研究验证了模型的可迁移性与准确性。将 TCN-LSTM-Attention 模型应用于同一次地震事件中的不同观测井以及另一地震事件中的建水井,均能检测出异常,说明该模型具有良好的泛化能力与迁移性。通过交叉验证,模型在不同训练-测试划分下均表现出一致性,进一步验证了其稳健性和对地下水异常的高敏感性。成功识别地下水异常为模型在更广泛地震预测中的应用提供了有力支撑。
本研究提升了模型的预测能力与异常检测灵敏度,增强了地震预警的准确性与效率,从而有效降低了地震灾害风险,最大限度减少生命财产损失。然而,地震前兆异常表现形式多样,包括地下水水位、水温、氡浓度、电磁信号、地热异常等多种因素。本研究仅聚焦于地下水水位异常,未来将进一步研究多种类型的数据,以提升地震异常检测的准确性与实用性。