文章目录
ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接
1.问题描述
在进行爬虫开发时,频繁遇到以下报错:
Connection aborted: ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。')
这是由于目标服务器将爬虫行为识别为异常或恶意访问,触发了安全机制(如防火墙、WAF),从而强制关闭连接。
2.尝试的解决方法(均未生效)
2.1 请求重试机制
对 requests.get(url) 添加重试逻辑,如失败最多尝试 20 次。
for i in range(20):
try:
response = requests.get(url)
break
except Exception as e:
time.sleep(1)
2.2 模拟浏览器请求头
在请求中添加常见的 headers,如 User-Agent、Referer、Accept-Language 等。
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
"Accept-Language": "zh-CN,zh;q=0.9"
}
2.3 关闭连接资源
在请求后调用 response.close() 主动释放连接资源,防止连接堆积。
2.4 延迟访问
控制访问频率,如通过 time.sleep() 降低请求频率,依旧无效。
3.解决方案:使用 proxy_pool IP 代理池
最终通过引入 IP 代理池 解决了问题,避免了目标服务器根据 IP 频率封锁爬虫请求。
- GitHub 地址:https://github.com/jhao104/proxy_pool
- 项目名称:proxy_pool
配置步骤:
1、克隆项目并安装依赖
git clone https://github.com/jhao104/proxy_pool.git
cd proxy_pool
pip install -r requirements.txt
2、Redis本地配置一下
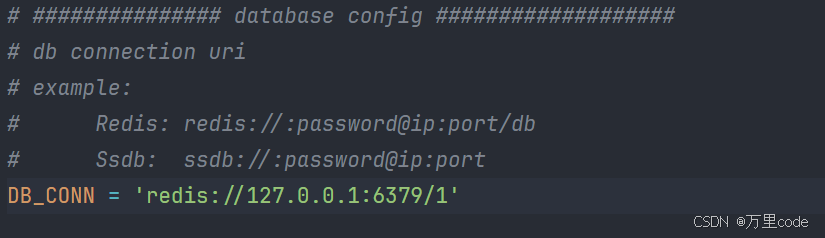
3、启动代理池服务
# 启动调度程序
python proxyPool.py schedule
# 启动webApi服务
python proxyPool.py server
4、代码中应用
封装两个功能,分别是获取IP和删除池子中的IP。
# proxypool ip池代理
PROXY_POOL_URL = "http://127.0.0.1:5010/get/"
def get_proxy():
try:
return requests.get("http://127.0.0.1:5010/get/").json().get("proxy")
except Exception as e:
print(f"[代理获取失败] {repr(e)}")
return None
def delete_proxy(proxy):
try:
requests.get(f"http://127.0.0.1:5010/delete/?proxy={proxy}")
except Exception as e:
print(f"[代理删除失败] {repr(e)}")
实际应用,解决获取问题(代码仅保留逻辑信息,相关私密数据不保留):
def down_img(img_url, retry_count=30):
ext = os.path.splitext(parse.urlparse(img_url).path)[1].lower().lstrip(".")
if ext not in ["jpg", "jpeg", "png", "gif", "svg", "webp"]:
ext = "jpg"
image_dir = os.path.join(current_dir, "x", "x", "x", "x")
os.makedirs(image_dir, exist_ok=True)
image_name = (
f"xxx"
)
image_path = os.path.join(image_dir, image_name)
while retry_count > 0:
proxy = get_proxy() # 1.获取proxy ip
if not proxy:
print("Error:无可用代理,无法下载")
return None
proxies = {"http": f"http://{proxy}", "https": f"http://{proxy}"}
try:
with requests.get(
img_url, proxies=proxies, timeout=10, stream=True
) as response: # 2.获取链接相关数据
response.raise_for_status()
with open(image_path, "wb") as f: # 3.图片本地化
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"[成功] 下载图片到:{image_path}")
return xxxx
except Exception as e:
retry_count -= 1
delete_proxy(proxy)
print(f"[最终失败] 无法下载图片:{img_url}")
实现成果:redis proxy_pool ip 存储 和 终端完成打印
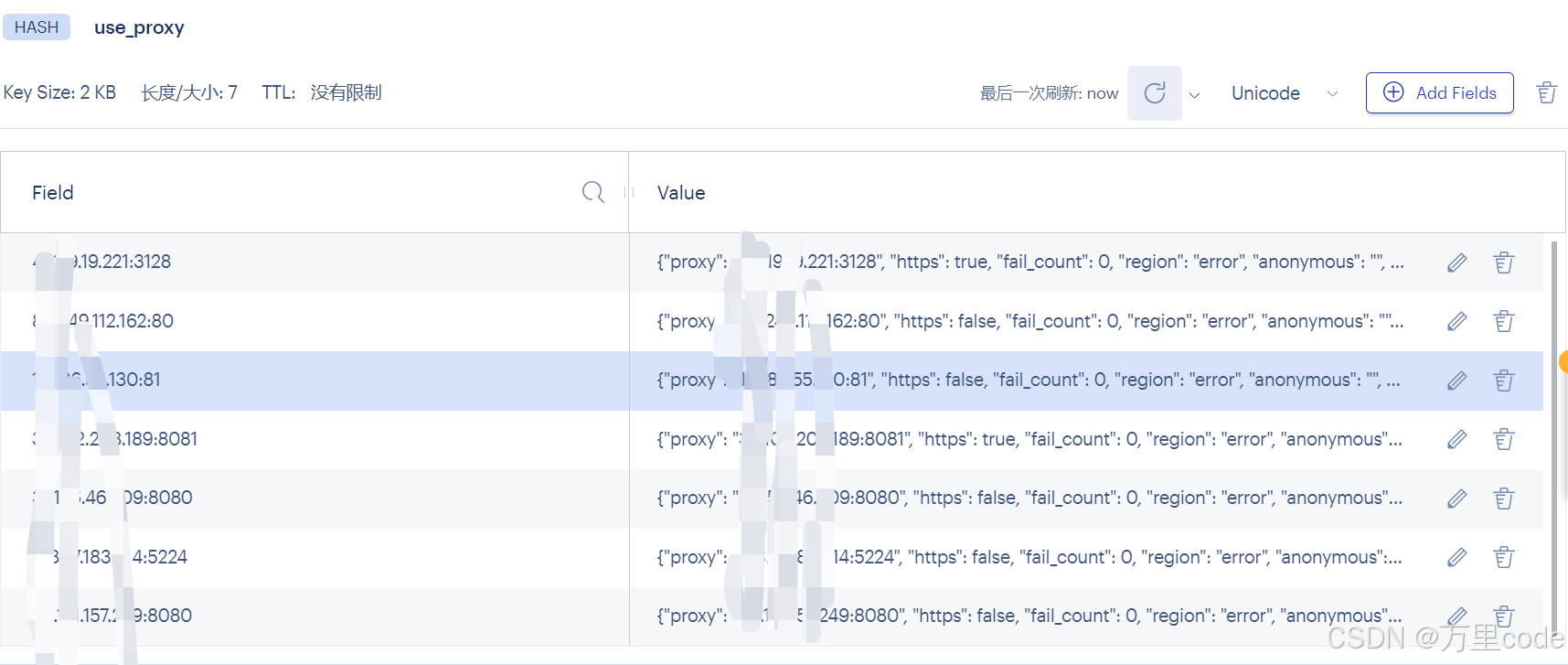
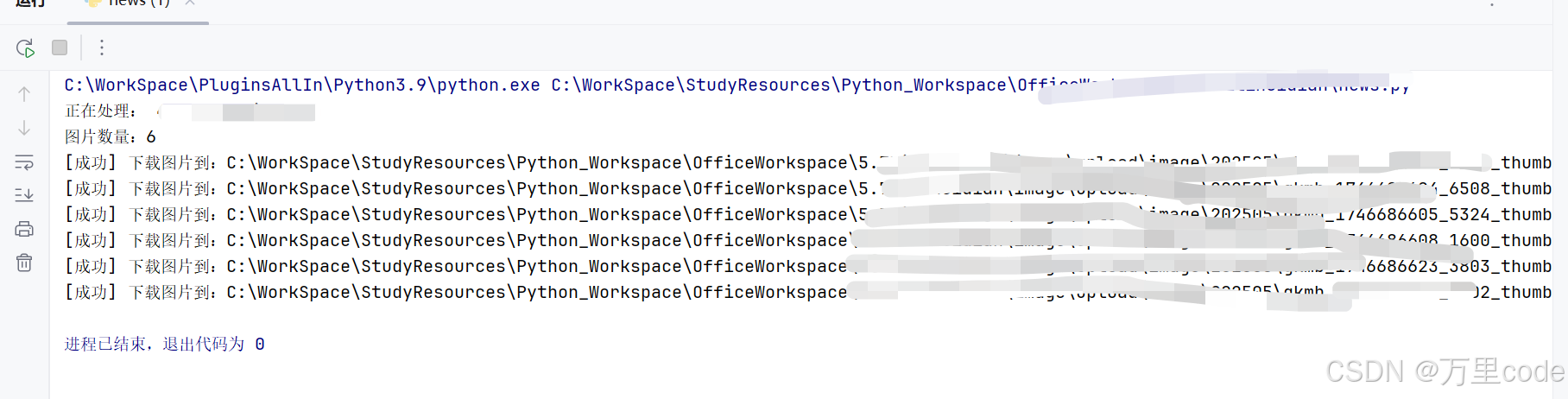
Successful! 成功解决问题。
最后
- 该类连接被重置的错误,单纯通过重试、伪装 UA 或请求头等手段已不足以绕过限制。
- 使用高质量的 IP 代理池最有效,配合随机代理策略可提高爬虫的稳定性和成功率。
参考文章
1、https://blog.csdn.net/xunxue1523/article/details/104662965
2、https://www.cnblogs.com/AubeLiang/p/17756844.html
3、https://github.com/jhao104/proxy_pool